开篇
天要下雨,人要吃饭,跟你说钱不是好东西的朋友都不是好东西。
安利两部老片,第一部是2010年的日剧《Gold》,中译金牌女王。女主早乙女悠里(天海佑希饰)是一位在东京经营规模巨大的健身中心,美容院的成功女性。性格迷糊可爱的新仓里佳(长泽雅美饰)被聘用为早乙女悠里新的总裁秘书,并被悠里一针见血的评论说的无地自容。剧中的一些观点有些强硬和冷酷,给我印象中最深的一幕是悠里洗脑小秘书光有爱是不足以支撑整个婚姻生活的。第二部是2007年的国产剧《蜗居》,由海清、张嘉译、文章、李念、郝平领衔主演,直面当下社会热点话题,反映在房价飙升的背景下,普通人在都市生活中历经的种种波折。而房子为什么会拥有投资属性,价格滚雪球的高涨不下,具体原因可以自己思考。但无论如何,这是摆在我们面前的赤裸裸的社会现实,每个不是含着金钥匙出生的孩子都要跨越的大山。
打工不是你实现财富自由的唯一手段,但却是风险较小的一个路子。
企业是逐利的,废话,不赚钱不如回家卖红薯,打工者依靠自身的身体素质、工作能力和学习能力出售个人时间换取酬劳,努力达成双赢、老板吃肉你喝汤的局面。
企业培养你是需要成本的,培养你肯定是因为你的产出能远大于投入,因此绝大多数的情况下,你的提升不要过于期待企业培训、内部经验交流,而更多在于下班后的自律提升。
有些人用一年的经验,工作十年,有些人,每年的经验是真的在见长。
话又说回来,既然工是一定要打的,钱是一定要赚的,个体能力是一定要提高的,槽是肯定会跳的,那么在离开温暖的大学校园进入社会的不同时期,如何找到一份适应自己的好工作,在为企业创收以便糊口的同时还能不断磨砺自我,三分天注定,七分靠准备。
确定就职优先级
程序员选公司的标准,公司离职员工对于公司的匿名评价,公司的面试题分享之类的,用搜索引擎可以搜索到许多你想要的,这里不再赘述。
回顾一下我现在的情况,第一份工作是三年某三甲医院信息中心研发,虽然有专门的测试、项目和运维小组,研发人员也需要时不时客串下测试运维客服,电脑死机了,打印机坏了也得动手上;第二份工作是2年某大型医疗器械集团产品研发,从最初的程序设计到1.0版本交付实施,从两家灯塔客户到其他医院,均属于软件小作坊式作业。软件从需求变更到测试发布再到现场实施工具,一路磕磕碰碰,都在摸索中前进,虽然现在想起来当时很多处理方式很是稚嫩,但还是很充实很开心的。
下一步的计划是寻求一家合适的公司,能在软件管理和流程规范上进行学习,虽然囫囵吞枣看了一些理论,但基本记不住,想亲身去感受整个过程,再两相印证。
那么对于我理想中的工作优先级大概像是这样子的:企业管理(CMMI或ISO认证)行业地位(工信部近3年100强软件公司排名)研发团队规模(精英团队好过滥竽充数)福利待遇。
采集岗位需求
招聘网站不在少数,招聘岗位更是成千上百,岗位需求更是各有特色,光靠手工复制粘贴再进行目测统计怕是要花不少时间,而大多数人一生并不会只跳一次槽,更有跳脱的人半年一年跳一次槽,作为一个程序员,怎么更有效率更快的获取到相应的岗位信息并进行统计,避免重复劳动呢?
网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。示例: Python爬虫爬取拉勾网职业信息 | 微软PowerBI/Excel爬虫实战,分分钟采集智联招聘100页 | 神箭手云爬虫平台
这里我们用神箭手云爬虫平台爬取51job的信息,不需要任何安装部署,也不需要学Python或者R语言,仅仅需要你会正则表达式或者XPath,会Javascript的话就更好了。注册成为神箭手的用户后,会有一个免费的节点可以使用,点击首页右上角的控制台,跳转之后,在个人页面左下方处有一个新建应用,点击它,弹出应用创建窗口,选择数据应用中的Javascript爬虫,点击下一步,选择自己开发,起一个自己喜欢的名字,点击创建,就创建完毕了,如果不太好理解,可以参考LeachZhou的这篇博客:神箭手云爬虫平台 如何在1小时内编写简单爬虫。接下来我们可以在页面下方找到刚刚新建的这个应用,点击开发按钮,进入代码界面。
这里我们以搜寻51job上广州地区的.NET工程师岗位为例来演示如何编写代码,在51job上点击搜索按钮后,如下所示,共3688条:
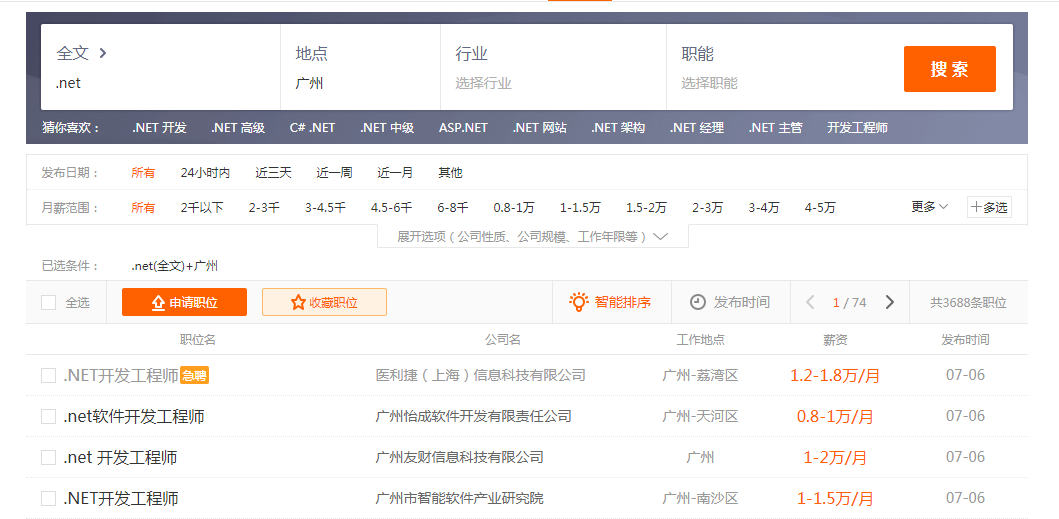
记录下此时的Url,切换下面的页码,找出不同页码之间的Url规律,如下图:
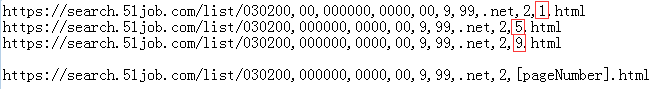
点击下面任意职位信息,取出Url,观察职位明细页面的Url路径规则,如下图所示:

做好这些准备工作之后,我们是时候开始解释下面代码的含义:
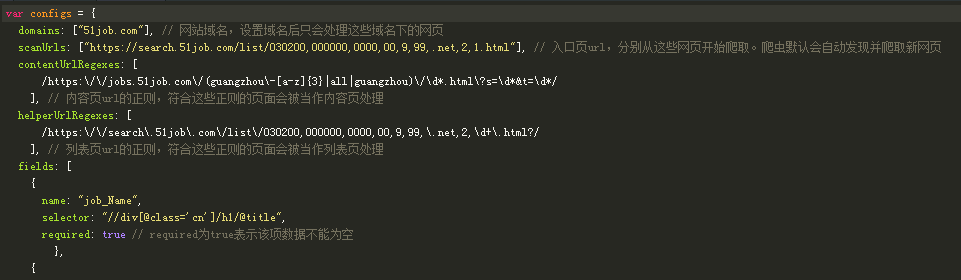
domains:51job的域名。
scanUrls:开始搜寻的Url路径,通常是网站的搜索页,这里我直接用搜索结果第一页的Url作为起始路径。
contentUrlRegexes:内容页的Url,这里我们用的是职位明细页面的正则。
helperUrlRegexes:所有列表页的Url,这里我们用的是列表页的正则。
fields:导出数据的列集合,name是自定义的名称,取个自己明白的含义即可,selector中是要用XPath写的,标识网页源代码的标签中你想存储哪块的内容,如图所示的是岗位名称,required为true表示要读到值,不允许为空。想要读取多少内容,就自己定义多少field即可。
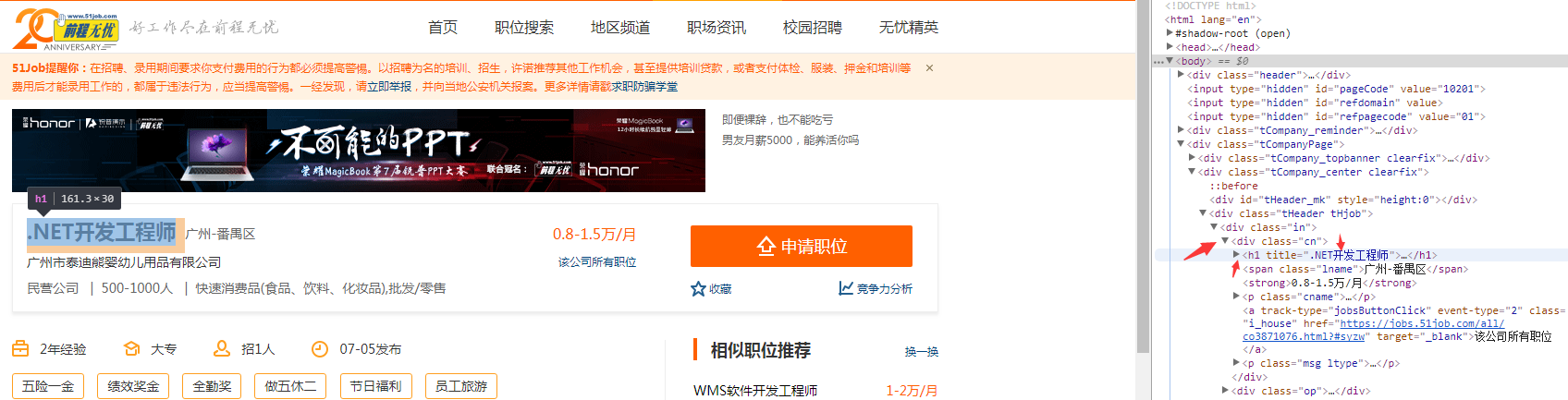
完成代码后点击代码页面左上角的保存按钮,右下方的测试界面可以尝试爬取30条Url的内容,借此验证自己的代码是否有误,测试无误后,点击左侧菜单栏中的总览,回到控制台界面,点击右上角的启动爬虫,开始爬取数据,需要一点时间。
爬取完数据后,可以导出成SQL或者Excel,也可以发布到网上,这里我们把数据导出到本地Excel文件,没爬满3688条是因为后面那200条在去重的比较上每一条都要比较半天,实在懒得等了,再说3000+的样本量也足够了,试着导成SQL往SQLServer里运行,有点小问题,还是写个小程序再处理一下好了,至此,样本数据采集完毕。

分词并统计
在统计的时候,发现了一点点小问题:
- 样本取的不是特别好,有些企业在岗位需求中粘贴上了自己公司网址,有些HR粘贴上了自己邮箱地址,这些URL带.net或者com字样,因此被爬虫也一块取出来了。
- 一些比较长的技术名敲错了,字母顺序错乱或者缺失,也给我们的统计带来了一定的困难,总不能像模糊拼音那样也建立一个庞大的库吧,嗯,有商业需求的话可以考虑一下。
- 受见识所限,字典只能维护上自己知道的部分技术点,另外随机抽取了5,60份样本人工提取了部分关键字,难免有漏掉的。
好吧,好在我们只是为了看个大概趋势,大体上的数据应该还是有效的。
自己写了个简单的小程序进行统计,代码链接在本节最后部分,点这里。
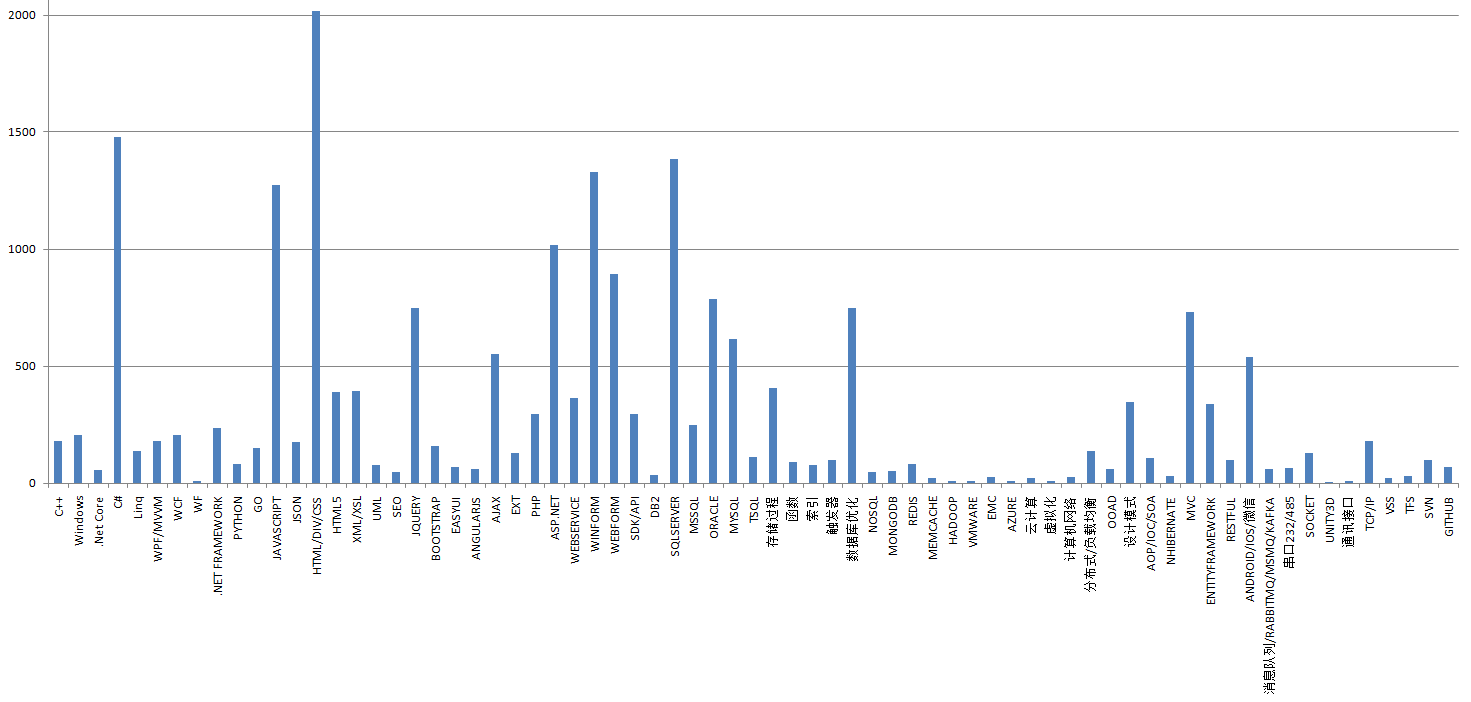
跑完了将数据导出到Excel,去掉.net,com之类的无效值,去掉数量极少的技术点,合并html、css之类的同义词,初步得出以下图表:
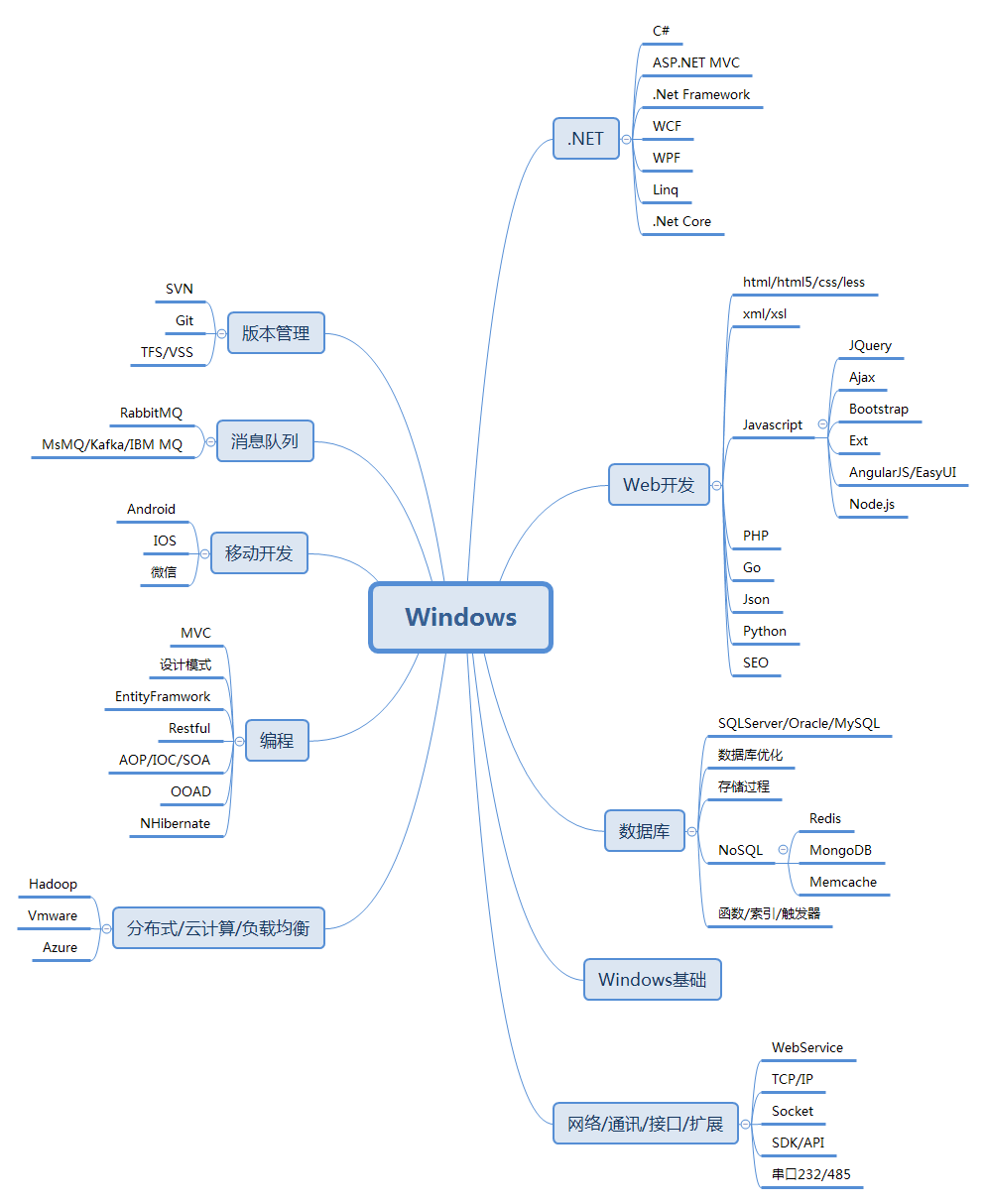
以下是用Xmind8画的思维导图,按照统计的数据从右到左、从上到下进行了整理,个别极低频次的词再次人工过滤,分类可能对也可能不对,这图可能有用也可能没用,大家看了笑笑就好,不用往心里去:
最后就是对比自己掌握的技术进行查漏补缺了。本文涉及到的文件和程序可以到我的Github上下载:点击这里跳转下载。
结束语
人什么苦都能吃,就是不能吃学习的苦。
你假装努力的样子真让人心疼。
做两个小时的计划学10分钟。