前言:
上一篇文章也简单的介绍了Logstash同步MySQL到ElasticSearch。批量同步虽说就配置文件不一样,但是实际操作的时候,也还会遇到不少的问题,比如reader不允许特殊字符(0x0)等等。下面也主要以几个问题来演示批量同步的过程,以及启动命令时如何排查报错的方法。
批量同步配置:
input {
stdin {
}
jdbc {
# mysql 数据库链接,shop为数据库名
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/rebuild?characterEncoding=UTF-8&useSSL=false"
# 用户名和密码
jdbc_user => "root"
jdbc_password => "root"
# 驱动
jdbc_driver_library => "E:/2setsoft/1dev/logstash-7.8.0/mysqletc/mysql-connector-java-5.1.7-bin.jar"
# 驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
parameters => {"number" => "200"}
# 执行的sql 文件路径+名称
#statement_filepath => "E:/2setsoft/1dev/logstash-7.8.0/mysqletc/user.sql"
statement => "SELECT * FROM `hhyp_article` WHERE delete_time = 0"
# 是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false);
lowercase_column_names => false
# Value can be any of: fatal,error,warn,info,debug,默认info;
sql_log_level => warn
# 是否记录上次执行结果,true表示会将上次执行结果的tracking_column字段的值保存到last_run_metadata_path指定的文件中;
record_last_run => true
# 需要记录查询结果某字段的值时,此字段为true,否则默认tracking_column为timestamp的值;
use_column_value => true
# 需要记录的字段,用于增量同步,需是数据库字段
tracking_column => "ModifyTime"
# Value can be any of: numeric,timestamp,Default value is "numeric"
tracking_column_type => timestamp
# record_last_run上次数据存放位置;
last_run_metadata_path => "E:/2setsoft/1dev/logstash-7.8.0/mysqletc/last_id.txt"
# 是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false;
clean_run => false
# 设置监听间隔 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => "* * * * *"
# 索引类型
type => "article"
}
jdbc {
# mysql 数据库链接,shop为数据库名
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/rebuild?characterEncoding=UTF-8&useSSL=false"
# 用户名和密码
jdbc_user => "root"
jdbc_password => "root"
# 驱动
jdbc_driver_library => "E:/2setsoft/1dev/logstash-7.8.0/mysqletc/mysql-connector-java-5.1.7-bin.jar"
# 驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
parameters => {"number" => "200"}
# 执行的sql 文件路径+名称
#statement_filepath => "E:/2setsoft/1dev/logstash-7.8.0/mysqletc/goods_class.sql"
statement => "SELECT * FROM `hhyp_article_cate` WHERE delete_time = 0"
# 是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false);
lowercase_column_names => false
# Value can be any of: fatal,error,warn,info,debug,默认info;
sql_log_level => warn
# 设置监听间隔 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => "* * * * *"
# 索引类型
type => "article_cate"
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
if[type] == "article" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "hhyp_article"
document_id => "%{id}"
}
}
if[type] == "article_cate" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "hhyp_article_cate"
document_id => "%{id}"
}
}
stdout {
codec => json_lines
}
}注意事项:
1. 索引type。
ES从6版本后一个索引下不能有多个type,所以在多张表同步时,最好一张表建立一个索引。所以在每个jdbc里type指定了一个名称。可以拿该名称在output时做判断。

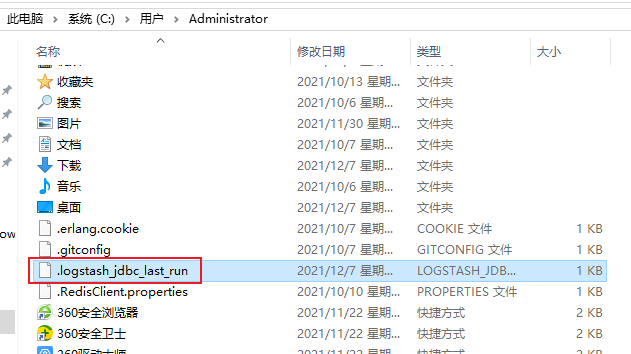
2. .logstash_jdbc_last_run储存位置。
logstash_jdbc_last_run是一个用来记录最后一次进行同步的时间节点,为了下一次增量同步的条件。如果不在配置中显式设置,默认是在系统盘的用户目录下。如果是windows,比如是我的是C:\Users\Administrator\.logstash_jdbc_last_run ,设置方式在上面代码里也有说明,如果自行设置需要在指定目录下创建一个TXT文件,执行完毕后也会储存最后同步的时间节点。
捕捉错误方式:
1. 命令面板查看。
这种方式是在命令通过bin\logstash -f mysqletc\mysql.conf启动时抛出的错误,在滚动的面板中主要查看ERROR行列。
2. 日志查看。
日志位置,logstash根目录>logs。里面不光有启动时抛出的错误日志还有运行的慢日志,可以解压一个带plain的日志,打开文件就可以查看到运行过程中的日志信息了,如下就是错误位置的提示语。

错误解决方法:
1. 'reader' unacceptable code point ' ' (0x0) special characters are not allowed
这个错误是某个文件中存在特殊字符,而在启动命令后,主要读取的除了conf配置文件和SQL执行指令就是logstash_jdbc_last_run了。排除了配置和SQL指令和之前一摸一样,所以问题就是默认在C:\Users\Administrator\下的.logstash_jdbc_last_run了,所以只需要删掉再重新启动就可以了。
2. <LogStash::ConfigurationError: Must set either :statement or :statement_filepath. Only one may be set at a time.>
这个错误就很明显了,statement和statement_filepath这两个配置项只能有一个。因为都是用于执行SQL指令的,一个是放在独立的文件中,用于繁杂的查询指令,而另一个是放在同步配置文件中。所以只需删掉或注释掉其中一项就可以了。
附加:
以上就是我在同步数据到elasticsearch中遇到问题以及解决的小小总结,希望对大家有所帮助,如果需要一起交流探讨的可以关注下面公众号,(●'◡'●)。
