概念 day27
网络架构
C/S :qq 微信 浏览器 英雄联盟 穿越火线 王者荣耀 安装
C:client 客户端
S:server 服务端
B/S :百度 淘宝 码云 只要在浏览器输入网址就可以直接使用了
B:browser 浏览器
S:server 服务端
B/S更好: 更节省资源 不用更新 不依赖环境
统一了所有web程序的入口
C/S架构: 安全性 程序比较庞大
移动端
app
微信小程序 : 统一了所有web程序的入口
支付宝 : 统一了所有和钱相关的事儿
mac
是一个物理地址
唯一的标识你的网络设备
ip 地址
是一个逻辑地址
是可以根据你的位置变化发生改变的
能够在广域网中快速的定位你
ipv4地址:
4为点分十进制
0.0.0.0-255.255.255.255
2**32
公网和内网:
公网 0.0.0.0-255.255.255.255(不包含保留字段的ip) 你能够在任意一 个地方去访问的ip地址
内网 所有的内网ip都要使用保留字段 只能在一个区域内使用,出了 这个区域就用不了了 192.168.0.0 - 192.168.255.255 10.0.0.0 - 10.255.255.255 172.16.0.0 - 172.32.255.255
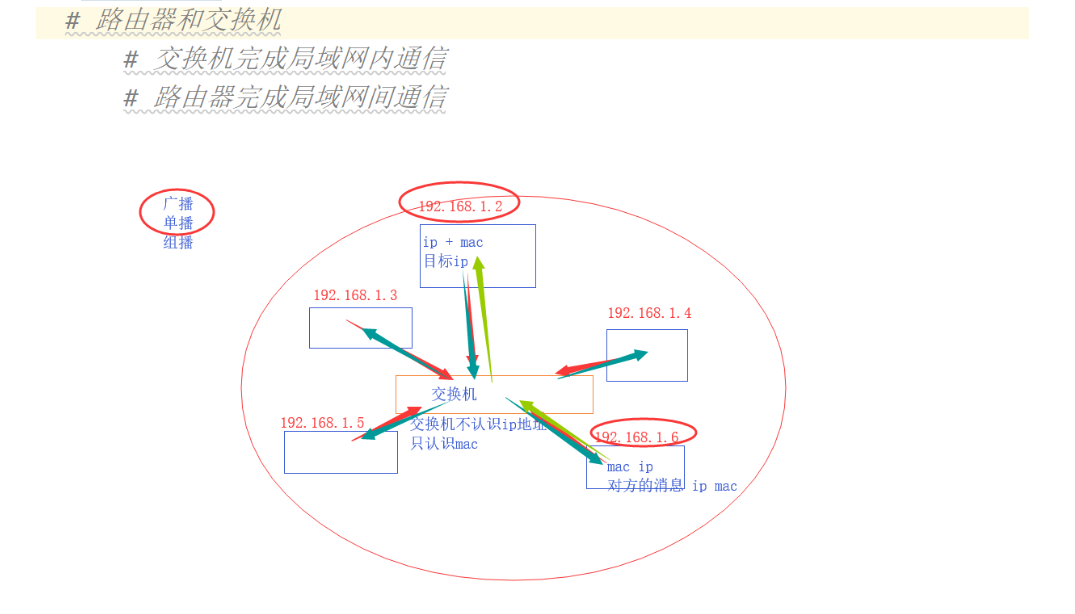
路由器和交换机:
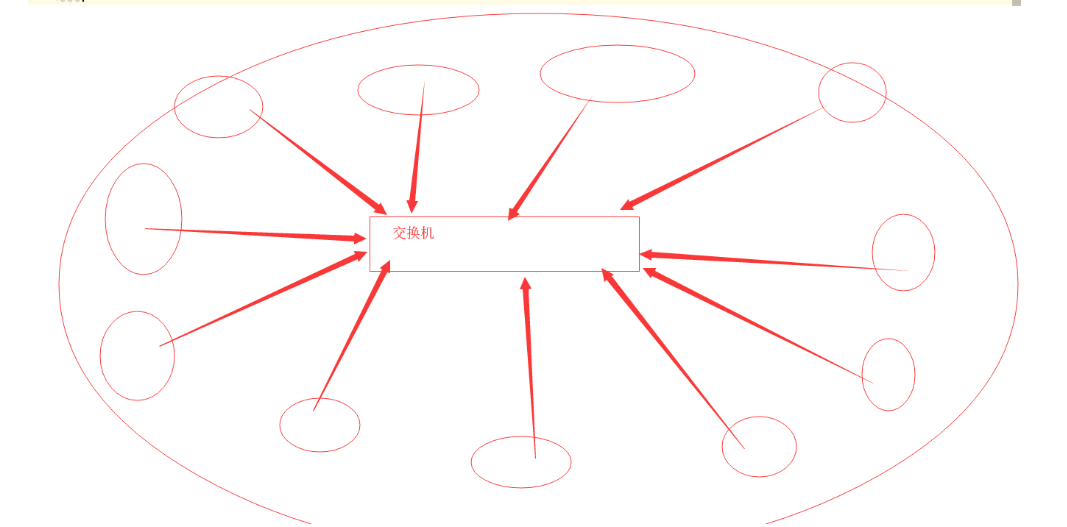

交换机完成局域网内的通信
通过ip找mac地址 : arp协议
单播 广播 组播
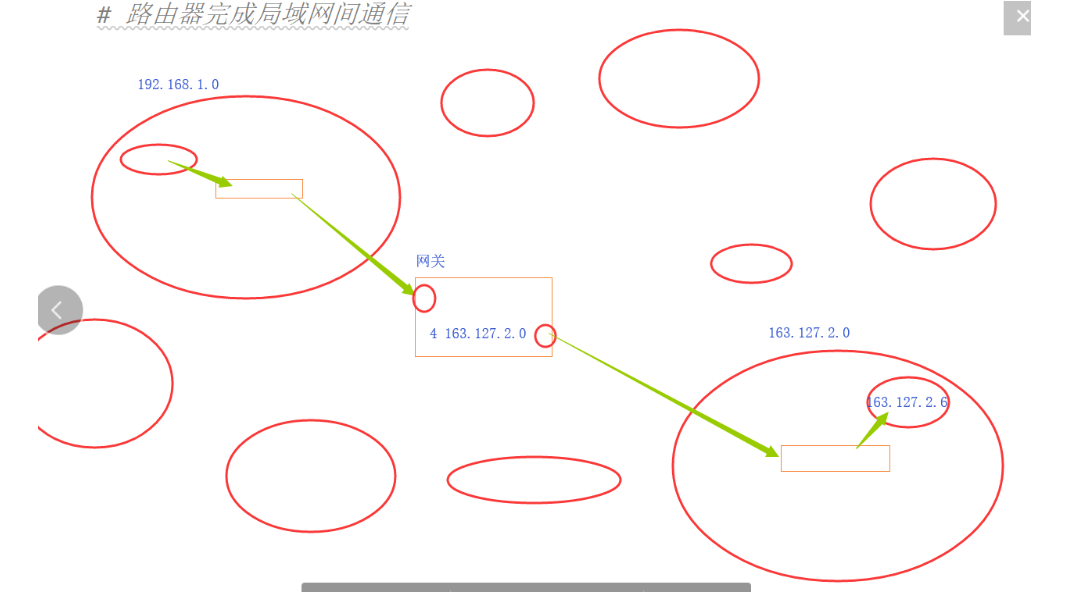
路由器完成局域网间通信
arp协议:通过你的ip地址 ,获取(解析)你的Mac地址
网关:所有与局域网外部通信的时候所有的关口,所有的请求都会在这里换上网关ip对面
网关ip
子网掩码(了解):可以判断要寻找的机器是不是在同一个局域网中
255.0.0.0
255.255.0.0
255.255.255.0
ip 和子网掩码 按位与运算
192.168.13.26 # 255.255.0.0
11000000.10101000.00001101.00011010
11111111.11111111.00000000.00000000
11000000.10101000.00000000.00000000 = 192.168.0.0
192.168.12.134
255.255.0.0
11000000.10101000.00001100.10000110
11111111.11111111.00000000.00000000
11000000.10101000.00000000.00000000 = 192.168.0.0
ipv6
6位冒分十六进制
0:0:0:0:0:0 - FFFF:FFFF:FFFF:FFFF:FFFF:FFFF
mac ip 定位到一台机器
port 端口
0-65535
ip + port能够唯一的确认网络上的一台机器上的一个服务
代表本机: 127.0.0.1
简单的socket通信 (套接字
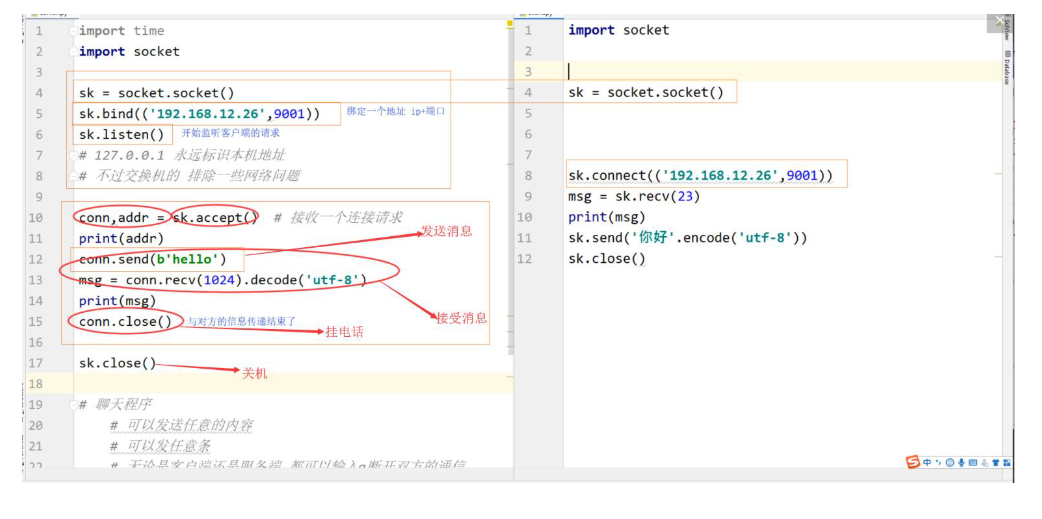
conn <socket.socket fd=420, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.168.12.65', 9001), raddr=('127.0.0.1', 63789)>
addr ('127.0.0.1', 63789)
socket
bind ()绑定 listen()监听 accept() 接收 send() 发送 recv() 接收 close()关闭 connect() 连接
arp协议: 地址解析 通过一台机器的ip地址找到mac地址
#交换机 广播 单播
端口:0-65535 用来标识一台机器上的服务

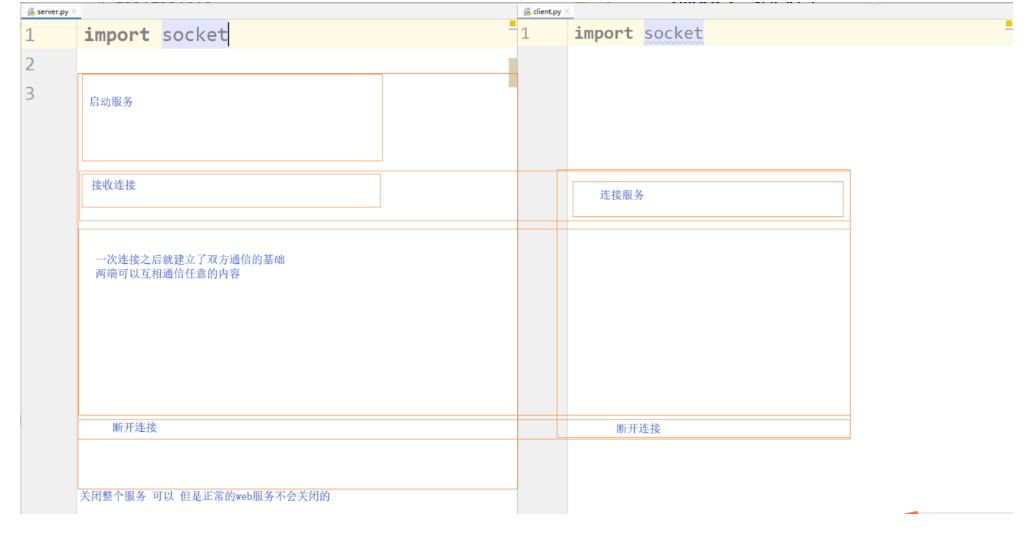
day28
socket 套接字过程
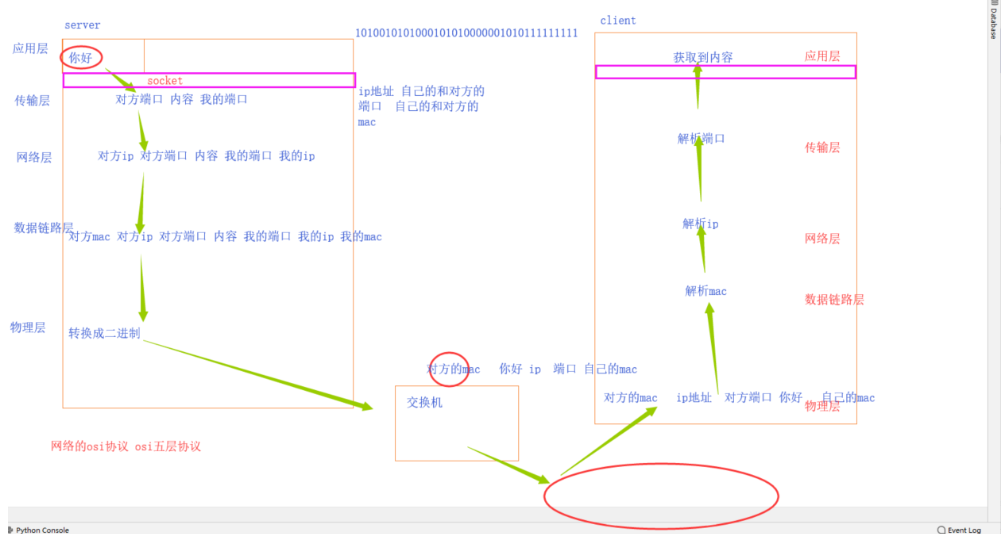
# osi七层协议
# 应用层
# 表示层
# 会话层
# 传输层
# 网络层
# 数据链路层
# 物理层
# osi五层协议
# 应用层(五层)
# 传输层(四层) 端口 UDP TCP 四层交换机 四层路由器
# 网络层(三层) ipv4 ipv6协议 路由器 三层交换机
# 数据链路层(二层) mac arp协议 网卡 (二层)交换机
# 物理层(一层)

# TCP/IP
# 网络层 arp
# TCP协议 上传下载发邮件 可靠 面向连接 速度慢 能传递的数据长度不限
# 建立连接 三次握手
# 消息传递 可靠传输
# 断开连接 四次挥手
# UDP协议 即时通讯工具 不可靠 面向数据报 速度快 能传递的数据长度有限
# 不管对方在不在 直接发送
# 不占连接
# 随时可以收发消息
TCP:https://baike.baidu.com/item/TCP/33012?fromtitle=TCP协议&fromid=8988699&fr=aladdin
UDP:https://baike.baidu.com/item/UDP?fromtitle=UDP协议&fromid=421768
飞秋通信
# from socket import socket,SOCK_DGRAM
# sk = socket(type=SOCK_DGRAM)
# server = ('192.168.12.156',2425)
# sk.sendto('1:111:eva:eva:32:你好'.encode('gbk'),server)
sercer 服务端
# import socket
# sk = socket.socket(type=socket.SOCK_DGRAM)
from socket import socket,SOCK_DGRAM
sk = socket(type=SOCK_DGRAM)
sk.bind(('127.0.0.1',9001))
while True:
msg,cli_addr = sk.recvfrom(1024)
print(msg.decode('utf-8'))
msg = input('>>>')
if msg.upper() == 'Q':continue
sk.sendto(msg.encode('utf-8'),cli_addr)
# 1.udp协议调通
# 2.可以根据用户输入的内容任意发送
# 3.可以根据用户的意愿发送多次消息
# 4.可以多人通信
cleint 客户端
from socket import socket,SOCK_DGRAM
sk = socket(type=SOCK_DGRAM)
server_addr = ('127.0.0.1',9001)
while True:
msg = input('>>>')
if msg.upper() == 'Q':
break
sk.sendto(msg.encode('utf-8'),server_addr)
msg = sk.recv(1024)
print(msg.decode('utf-8'))
day29
粘包
1.粘包现象只存在 tcp , udp 不会出现粘包
-
出现粘包的情况
1.当多条消息发送时接受变成了一条或者出现接收不准确的情况
2.粘包现象会发生在发送端
@ 两条消息间隔时间短,长度短 就会把两条消息在发送之前就拼在一起
@ 节省每一次发送消息回复的网络资源
3.粘包现象会发生在接收端
@多条消息发送到缓存端,但没有被及时接收,或者接收的长度不足一次发送的长度
@数据与数据之间没有边界
本质: 发送的每一条数据之间没有边界
3.解决粘包的方法
模块 struct
1.作用 struct模块可以将一个类型转成固定长度的bytes
import struct
ret = struct.pack("i",123) # 转换数字
print(ret)
ret = struct.unpack("i",ret) # 反转后获取的是一个元组
print(ret)
print(ret[0])
#server
import struct
import socket
def proto_send(msg):
msg = msg.encode('utf-8')
len_msg = len(msg)
proto_len = struct.pack('i', len_msg) # 把字节的长度编程4字节,i代表int
conn.send(proto_len)
conn.send(msg)
sk = socket.socket()
sk.bind(('192.168.12.26',9001))
sk.listen()
conn,addr = sk.accept()
msg1 = 'hello'
msg2 = 'world'
proto_send(msg1)
proto_send(msg2)
# 计算要发送的数据字节长度
# 把字节的长度编程4字节
# 发送4字节
# 发送数据
# 通过socket的tcp协议上传文件
#client
import struct
import socket
sk = socket.socket()
def proto_recv():
len_msg = sk.recv(4)
len_msg = struct.unpack('i', len_msg)[0]
msg = sk.recv(len_msg)
return msg
sk.connect(('192.168.12.26',9001))
for i in range(1000000):2*i
msg1 = proto_recv()
print(msg1)
msg2 = proto_recv()
print(msg2)
day31
内容回顾
# 网络
# osi五层协议
# 应用层 要发送的数据 http/https协议
# 传输层 端口 tcp/udp协议 四层路由器/四层交换机
# tcp 面向连接 可靠 速度慢 长度不受限 全双工 流式传输
# 文件传输邮件实时通信
# 三次握手 :记那张图(SYN ACK) accept connect
# 1.三次握手是tcp协议建立连接的过程
# 2.由客户端发起一个syn请求,服务端接收并回复(synack)
# 客户端收到ack和syn之后再回复一个ack
# 3.在原生的socket代码中三次握手是由accept connect
# 数据的交互 : 粘包现象 粘包成因
# 四次挥手 :记那张图(FIN ACK) close close
# udp 无连接 面向数据报 不可靠 速度快 长度受限制 一对一 一对多 多对多
# 短消息类在线观看视频
# 网络层 ip协议 路由器/三层交换机
# 数据链路层 mac地址 arp协议 网卡/交换机
# 物理层
# 局域网和广域网的区别 : 相对论
# 内网和公网的区别 : ip地址的区别
# 特殊的ip : 0.0.0.0 127.0.0.1
# 什么是交换机路由器
# 代码
# socket模块
# tcp服务
# udp服务 参数
# tcp的粘包
# 如何解决
# socketserver模块
# 固定的格式(背)
操作系统基础
# 穿孔卡片
# 高速磁带
# -- 操作系统
# 多道操作系统
# 第一次提出了多个程序可以同时在计算机中被计算
# 1.遇到IO就让出CPU
# 2.把CPU让给其他程序,让其他程序能够使用CPU
# 3.CPU的让出这件事 占用时间
# 4.两个程序来回在CPU上切换,不会
# 每个程序有独立的内存空间
# 每个程序在切换的前后会把当前程序的状态记录下来
# CPU计算和不计算(IO)操作
# IO操作(网络操作文件操作) : 输入输出:相对内存
# 阻塞: sleepinput
ecvaccept
ecvfrom是不需要cpu参与的
# 对文件的读取 : 对硬盘的操作一次读取相当于90w条代码
# Input : 向内存输入数据
# 读loadinput
ecv
ecvfromacceptconnectclose
# Output : 从内存输出数据
# 写dumpprintsendsendtoacceptconnectclose
# 所有的IO操作本质都是文件操作
# inputprint input是写入文件,然后通过读取文件把输入的内容加载到内存
# print是直接写入文件,然后通过文件展示给用户看
# socket中的交互方法 : 都是文件操作
# send 是向缓存文件中写
# recv 是从缓存文件中读
# 也就是说只要涉及到IO操作 至少就是一个0.009s=就是CPU执行90w条python代码的时间
# 0.009s
# 500000000条指令/s /5 = 100000000条python代码/s
# 0.009s * 100000000 = 900000条python代码
# import dis
# a = 1
# def func():
# global a
# a+=1
# dis.dis(func)
# 1.老教授和研究生
# 研究生 5min 没有IO操作 先来先服务(FIFS)
# 老教授 24h 没有IO操作
# 研究生 3min 没有IO操作 短作业优先算法
# 2.时间片轮转算法 -- 分时操作系统
# 1w = 0.00005s
# 1.时间片到了才让出CPU
# 2.CPU的让出这件事 占用时间
# 3.减低工作效率,提高了用户体验
进程概念
# 程序与进程(计算机中最小的资源分配单位)
# 运行中的程序 就是 进程
# 进程与进程之间的数据是隔离的
# 线程(计算机中能被操作系统调度的最小单位)
# 每个程序执行到哪个位置是被记录下来的
# 在进程中 有一条线程是负责具体的执行程序的
# 进程的调度(由操作系统完成的) :
# 被操作系统调度的,每个进程中至少有一个线程
# 短作业优先算法
# 先来先服务算法
# 时间片轮转算法
# 多级反馈算法
# 进程的启动 销毁
# 进程的启动 : 交互(双击) 在一个进程中启动另一个 开机自启动
# 负责启动一个进程的程序 被称为一个父进程
# 被启动的进程 被成为一个子进程
# 销毁 : 交互 被其他进程杀死(在父进程结束子进程) 出错进程结束
# 父子进程
# 父进程开启子进程
# 父进程还要负责对结束的子进程进行资源的回收
# 进程id --> processid --> pid
# 在同一台机器上 同一个时刻 不可能有两个重复的进程id
# 进程id不能设置 是操作系统随机分配的
# 进程id随着多次运行一个程序可能会被多次分配 每一次都不一样
# 进程的三状态图
# 就绪ready 运行run 阻塞block
# import os
# import time
#
# print(os.getpid())
# print(os.getppid()) # parent process id
# time.sleep(100)
# 2.模块multiprocessing模块 :内置模块
# multiple 多元化的
# processing 进程
# 把所有和进程相关的机制都封装在multiprocessing模块中了
# 3.学习这个模块
import os
import time
from multiprocessing import Process
def func():
'''
在子进程中执行的func
:return:
'''
print('子进程 :',os.getpid(),os.getppid())
time.sleep(3)
if __name__ == '__main__':
p = Process(target=func)
p.start()
print('主进程 :',os.getpid())
# 并行 : 多个程序同时被CPU执行
# 并发 : 多个程序看起来在同时运行
# 同步 : 一个程序执行完了再调用另一个 并且在调用的过程中还要等待这个程序执行完毕
# 异步 : 一个程序在执行中调用了另一个 但是不等待这个任务完毕 就继续执行 start
# 阻塞 : CPU不工作
# 非阻塞 : CPU工作

day32
from multiprocessing import Process
Process 模块
进程
-
什么是进程
运行中的程序就是正在运行的程序,进程是资源单位
-
开启一个进程发送了什么
在内存中开启一个进程空间,将主进程的资源复制一份,进程之间空间是隔离的,数据不共享】
-
进程的状态
- 运行一个进程首先会进入就绪状态,拿到cpu后进入运行状态
-
运行:运行中遇到IO进入阻塞状态
- 阻塞:阻塞结束后重新进入就绪状态,等待cpu资源
-
就绪:拿到cpu资源后进入运行状态
-
进程的理论
- 串行
- 逐个完成任务
- 并发
- 一个cpu完成多个任务(cpu快速切换),看起来像同时完成
- 并行
- 多个cpu执行多个任务,真正的同时完成
- 阻塞
- 当cpu在遇到IO就是阻塞
- 非阻塞
- 程序没有IO,就是非阻塞
- 串行
创建进程
-
windows系统下必须创建进程必须在mian中
args的参数必须是元祖类型
from multiprocessing import Process def a(name): print(name) if __name__ == '__main__': p = Process(target=a,args=("张三",)) p.start() # 开启进程from multiprocessing import Process class A(Process): def __init__(self,name): super().__init__() # 继承父类init self.name = name def run(self): # 开启进程自动执行run方法 print(self.name) if __name__ == '__main__': a = A("张三") a.start() # 开启进程
5.进程的pid
每个进程都有一个唯一的pid
cmd中可以通过:pid tasklist获取进程pid
python获取进程pid需要导入os模块
from multiprocessing import Process
import os
def a():
print(os.getpid()) # 获取当前线程pid
print(os.getppid()) # 获取父线程的pid
if __name__ == '__main__':
p = Process(target=a)
p.start()
6.join
join是一种阻塞,主进程要等待设置join的子进程执行完毕后再执行
from multiprocessing import Process
import time
def A(num):
print(num)
time.sleep(num)
if __name__ == '__main__':
a = Process(target=A,args=(1,))
ti = time.time()
a.start()
a.join()
print(time.time()-ti)
7.进程对象其他属性
from multiprocessing import Process
def a():
pass
if __name__ == '__main__':
p = Process(target=a)
p.start() # 进程名:Process-1
print(p.name)
print(Process.is_alive(p))# 获取进程状态
Process.terminate(p) # 杀死进程
print(Process.is_alive(p))
8.守护进程daemon
设置为守护进程的子进程,会在主进程结束后马上结束,设置守护进程需要在开启进程前设置
守护进程
# 守护进程不会守护除了主进程代码之外的其他子进程
# 守护进程会随着父进程的代码结束而结束
# import time
# def son():
# while True:
# time.sleep(1)
# print('in son')
#
#
# if __name__ == '__main__':
# p = Process(target=son)
# p.daemon = True # 将当前的子进程设置为守护进程
# p.start()
# time.sleep(5)
# 正常情况下 父进程永远会等着子进程结束
# 如果设置了守护进程 父进程的代码结束之后 守护进程也跟着结束
# 子进程结束之后,父进程才会结束
# 代码结束和进程结束是两回事儿
# 没设置守护进程
# 1.子进程的代码和主进程的代码自己执行自己的,互相之间没关系
# 2.如果主进程的代码先结束,主进程不结束,等子进程代码结束,回收子进程的资源,主进程才结束
# 3.如果子进程的代码先结束,主进程边回收子进程的资源边执行自己的代码,当代码和资源都回收结束,主进程才结束
# 设置了守护进程
# 1.子进程的代码和主进程的代码自己执行自己的,互相之间没关系
# 2.一旦主进程的代码先结束,主进程会先结束掉子进程,然后回收资源,然后主进程才结束
9.僵尸进程
在开启进程后,父进程监视子进程运行状态,当子进程运行结束后一段时间内,将子进程回收,父进程和子进程是异步关系,不能在子进程结束后马上捕捉子进程的状态,如果子进程立即释放内存,父进程就无法再检测子进程的状态了,unix提供了一种机制,子进程在结束后会释放大部分内存,但会保留进程号、结束时间、运行状态,供主进程检测和回收
-
什么僵尸进程
子进程在结束后被父进程回收前的状态就是僵尸进程
-
危害
如果父进程由于某些原因一直未对子进程回收,这时子进程就会一直占用内存和进程号
-
解决方式
将父进程杀死,使子进程成为孤儿进程,等待init进行回收
-
孤儿进程
父进程已经结束了,但是子进程还在运行,这时子进程就是孤儿进程,孤儿进程由init回收,
锁
# 数据安全(锁) :用来保证数据安全
# 如果多个进程同时对一个文件进行操作会出现什么问题
# 1.读数据 : 可以同时读
# 2.写数据 : 但不能同时写
from multiprocessing import Process,Lock
def change(lock):
print('一部分并发的代码,多个进程之间互相不干扰的执行着')
lock.acquire() # 给这段代码上锁
with open('file','r') as f:
content = f.read()
num = int(content)
num += 1
for i in range(1000000):i+=1
with open('file','w') as f:
f.write(str(num))
lock.release() # 给这段代码解锁
print('另一部分并发的代码,多个进程之间互相不干扰的执行着')
if __name__ == '__main__':
lock = Lock()
for i in range(10):
Process(target=change,args=(lock,)).start()
# 当多个进程同时操作文件/共享的一些数据的时候就会出现数据不安全
# 开启多进程 同时执行100000行代码
# 其中20行涉及到了操作同一个文件
# 只给这20行代码枷锁,来保证数据的安全
进程与进程之间的通信
# 进程之间通信 IPC
# Inter Process Communication
from multiprocessing import Queue,Process
# def son(q):
# print(q.get())
#
# if __name__ == '__main__':
# q = Queue()
# p = Process(target=son,args=(q,))
# p.start()
# q.put(123)
# 在进程之间维护数据的安全 -- 进程安全
# 队列是进程安全的(进程队列保证了进程的数据安全)
# 队列都是先进先出的
# 队列是基于文件 + 锁实现的
# 队列一共提供两个方法:get put
# q = Queue()
# q.put({1,2,3})
# num = q.get() # get是一个同步阻塞方法,会阻塞直到数据来
# print(num)
# q = Queue(2)
# q.put({1,2,3})
# q.put({1,2,3})
# q.put({1,2,3}) # put是一个同步阻塞方法,会阻塞直到队列不满
import queue
# q = Queue(2)
# try:
# for i in range(4):
# q.put_nowait(i) # put_nowait 同步非阻塞方法
# except queue.Full:
# print(i)
# q2 = Queue(2)
# try:
# print(q2.get_nowait())
# except queue.Empty:pass
# q = Queue(5)
# ret = q.qsize() # 查看当前队列有多少值
# print(q.empty())
# print(q.full())
# 生产者消费者模型
# 队列Queue = 管道Pipe + 锁
# Pipe 基于文件实现的(socket+pickle) = 数据不安全
# Queue 基于文件(socket+pickle)+锁(lock)实现的 = 数据安全
# 基于pipe+锁(lock)实现的
# IPC:
# 内置的模块实现的机制 :队列管道
# 第三方工具 : redis rabbitMQ memcache
day33
-
今日概要
- 爬虫
- 线程的概念及与进程的区别
- 多线程的引用
- 线程安全(单例模式)
- GIL(全局解释器锁
-
内容回顾&补充
-
面向对象继承
class Thread(object): def __init__(self): pass def start(self): self.run() def run(self): print('thread.run') obj = Thread() obj.start() ----------------------------------- class MyThread(Thread): def run(): print('mythread.run') obj = MyThread() obj.start() -
面向对象的上下文管理
含有__enter__和__exit__方法的对象就是上下文管理器。 class FOO(): def __init__(self): print('实例化一个对象') def __enter__(self): print('进入') def__exit__(self,exc_type,exc_val,exc_tb) print('退出') obj = F00() with obj: print('正在执行')-
阉割版的单例模式
class Foo: instance = None def __init__(self, name): self.name = name def __new__(cls, *args, **kwargs): # 返回空对象 if cls.instance: return cls.instance cls.instance = object.__new__(cls) #借助父类object实例化一个对象 return cls.instance ## obj == __init__() obj1 = Foo('日魔') obj2 = Foo('SB') print(obj1,obj2) -
socketserver的实现原理
-
内部创建进程或线程实现并发.
.socketserver本质 import socket import threading def task(connect,address): pass server = socket.socket() server.bind(('127.0.0.1',9000)) server.listen(5) while True: conn,addr = server.accept() # 处理用户请求 t = threading.Thread(target=task,args=(conn,addr,)) t.start().socketserver源码 import socketserver class MyRequestHandler(socketserver.BaseRequestHandler): def handle(self): data = self.request.recv(1024) print(data) obj = socketserver.ThreadingTCPServer(('127.0.0.1',9000),MyRequestHandler) obj.serve_forever()
-
-
3. 今日详细
3.1爬虫下载图片的案例
- ##### 安装和使用1. 安装第三方模块 pip3 install requests 2. 使用 import requests url = 'https://www3.autoimg.cn/newsdfs/g26/M02/35/A9/120x90_0_autohomecar__ChsEe12AXQ6AOOH_AAFocMs8nzU621.jpg' # python伪造浏览器向地址发送请求 rep = requests.get(url) # 请求返回回来的字节 # print(rep.content) with open('xxxxxx.jpg',mode='wb') as f: f.write(rep.content)-
爬虫下载照片
""" 1. 安装第三方模块 pip3 install requests 2. 使用 import requests url = 'https://www3.autoimg.cn/newsdfs/g26/M02/35/A9/120x90_0_autohomecar__ChsEe12AXQ6AOOH_AAFocMs8nzU621.jpg' # python伪造浏览器向地址发送请求 rep = requests.get(url) # 请求返回回来的字节 # print(rep.content) with open('xxxxxx.jpg',mode='wb') as f: f.write(rep.content) """ import requests url_list = [ 'https://www3.autoimg.cn/newsdfs/g26/M02/35/A9/120x90_0_autohomecar__ChsEe12AXQ6AOOH_AAFocMs8nzU621.jpg', 'https://www2.autoimg.cn/newsdfs/g30/M01/3C/E2/120x90_0_autohomecar__ChcCSV2BBICAUntfAADjJFd6800429.jpg', 'https://www3.autoimg.cn/newsdfs/g26/M0B/3C/65/120x90_0_autohomecar__ChcCP12BFCmAIO83AAGq7vK0sGY193.jpg' ] for url in url_list: ret = requests.get(url) file_name = url.rsplit('/',maxsplit=1)[-1] with open(file_name,mode='wb') as f: # 下载小文件 # f.write(ret.content) # 下载大文件 for chunk in ret.iter_content(): f.write(chunk) -
多线程爬虫
import requests url_list = [ 'https://www3.autoimg.cn/newsdfs/g26/M02/35/A9/120x90_0_autohomecar__ChsEe12AXQ6AOOH_AAFocMs8nzU621.jpg', 'https://www2.autoimg.cn/newsdfs/g30/M01/3C/E2/120x90_0_autohomecar__ChcCSV2BBICAUntfAADjJFd6800429.jpg', 'https://www3.autoimg.cn/newsdfs/g26/M0B/3C/65/120x90_0_autohomecar__ChcCP12BFCmAIO83AAGq7vK0sGY193.jpg' ] # 串行示例 # for url in url_list: # ret = requests.get(url) # file_name = url.rsplit('/',maxsplit=1)[-1] # with open(file_name,mode='wb') as f: # f.write(ret.content) # 基于多线程 import threading def task(arg): ret = requests.get(arg) file_name = arg.rsplit('/', maxsplit=1)[-1] with open(file_name, mode='wb') as f: f.write(ret.content) for url in url_list: # 实例化一个线程对象 t = threading.Thread(target=task,args=(url,)) # 将线程提交给cpu t.start()
-
3.2 线程的概念&与进程的区别?
进程(Process)和线程(Thread)是操作系统的基本概念,
形象的关系
- 工厂 -> 应用程序
- 车间 -> 进程
- 工人 -> 线程
进程和线程的区别?
进程是计算机资源分配的最小单位.
线程是计算机中可以被cpu调度的最小单位.
一个进程中可以有多个线程,同一个进程中的线程可以共享此进程中的资源,一个进程中至少有一个线程(一个应用程序中至少有一个进程)
在Python中因为有GIL锁,他同一时刻保证一个进程中只有一个线程可以被cpu调度,所以在使用Python开发时要注意:
计算密集型,用多进程.
IO密集型,用多线程.
默认进程之间无法进行资源共享,如果主要想要通讯可以基于:文件/网络/Queue.
3.3 多线程的应用
-
快速应用
import threading def task(arg): pass # 实例化一个线程对象 t = threading.Thread(target=task,args=('xxx',)) # 将线程提交给cpu t.start()import threading def task(arg): ret = requests.get(arg) file_name = arg.rsplit('/', maxsplit=1)[-1] with open(file_name, mode='wb') as f: f.write(ret.content) for url in url_list: # 实例化一个线程对象 t = threading.Thread(target=task,args=(url,)) # 将线程提交给cpu t.start() -
常见方法
-
t.start(),将线程提交给cpu,由cpu来进行调度
-
t.join(),等待
import threading # 示例1 """ loop = 10000000 number = 0 def _add(count): global number for i in range(count): number += 1 t = threading.Thread(target=_add,args=(loop,)) t.start() t.join() print(number) """ # 示例2 """ loop = 10000000 number = 0 def _add(count): global number for i in range(count): number += 1 def _sub(count): global number for i in range(count): number -= 1 t1 = threading.Thread(target=_add,args=(loop,)) t2 = threading.Thread(target=_sub,args=(loop,)) t1.start() t2.start() print(number) """ # 示例3 """ loop = 10000000 number = 0 def _add(count): global number for i in range(count): number += 1 def _sub(count): global number for i in range(count): number -= 1 t1 = threading.Thread(target=_add,args=(loop,)) t2 = threading.Thread(target=_sub,args=(loop,)) t1.start() t2.start() t1.join() # t1线程执行完毕,才继续往后走 t2.join() # t2线程执行完毕,才继续往后走 print(number) """ # 示例4 """ loop = 10000000 number = 0 def _add(count): global number for i in range(count): number += 1 def _sub(count): global number for i in range(count): number -= 1 t1 = threading.Thread(target=_add,args=(loop,)) t2 = threading.Thread(target=_sub,args=(loop,)) t1.start() t1.join() # t1线程执行完毕,才继续往后走 t2.start() t2.join() # t2线程执行完毕,才继续往后走 print(number) """-
t.setDaemon() ,设置成为守护线程
import threading import time def task(arg): time.sleep(5) print('任务') t = threading.Thread(target=task,args=(11,)) t.setDaemon(True) t.start() print('END') -
线程名称的设置和获取
import threading def task(arg): # 获取当前执行此代码的线程 name = threading.current_thread().getName() print(name) for i in range(10): t = threading.Thread(target=task,args=(11,)) t.setName('日魔-%s' %i ) t.start() -
run() , 自定义线程时,cpu调度执行的方法
class RiMo(threading.Thread): def run(self): print('执行此线程',self._args) obj = RiMo(args=(100,)) obj.start()
-
-
练习题: 基于socket 和 多线程实现类似于socketserver模块的功能.
import socket
import threading
def task(connect,address):
pass
server = socket.socket()
server.bind(('127.0.0.1',9000))
server.listen(5)
while True:
conn,addr = server.accept()
# 处理用户请求
t = threading.Thread(target=task,args=(conn,addr,))
t.start()
3.4 线程安全
多个线程同时去操作一个"东西",不要存在数据混乱.
线程安全: logging模块 / 列表
线程不安全: 自己做文件操作 / 同时修改一个数字
使用锁来保证数据安全,来了多个线程,使用锁让他们排队,逐一执行.
-
Lock
import threading import time num = 0 # 线程锁 lock = threading.Lock() def task(): global num # # 申请锁 # lock.acquire() # num += 1 # time.sleep(0.2) # print(num) # # 释放锁 # lock.release() with lock: num += 1 time.sleep(0.2) print(num) for i in range(10): t = threading.Thread(target=task) t.start() -
RLock,递归锁支持上多次锁
import threading import time num = 0 # 线程锁 lock = threading.RLock() def task(): global num # 申请锁 lock.acquire() num += 1 lock.acquire() time.sleep(0.2) print(num) # 释放锁 lock.release() lock.release() for i in range(10): t = threading.Thread(target=task) t.start()
练习题: 基于线程锁完成一个单例模式.
import threading
import time
class Singleton:
instance = None
lock = threading.RLock()
def __init__(self, name):
self.name = name
def __new__(cls, *args, **kwargs):
if cls.instance:
return cls.instance
with cls.lock:
if cls.instance:
return cls.instance
time.sleep(0.1)
cls.instance = object.__new__(cls)
return cls.instance
def task():
obj = Singleton('x')
print(obj)
for i in range(10):
t = threading.Thread(target=task)
t.start()
# 执行1000行代码
data = Singleton('asdfasdf')
print(data
3.5 GIL
GIL,全局解释器锁.
同一时刻保证一个进程中只有一个线程可以被cpu调度,所以在使用Python开发时要注意:
计算密集型,用多进程.
IO密集型,用多线程.
-
Python中如果创建多现场无法应用计算机的多核优势.
-
4.重点总结
- 初识爬虫
- 单例模式 ,重点面试 (需要默写)
- 为什么要加锁?
- 为什么要做判断?
- 进程和线程的区别? ,重点.面试
- GIL锁, 重点面试
- 线程的常用功能: start/join , 重点
day34
-
线程池
-
线程池的作用: 控制产生线程的数量,提高性能,降低资源消耗.
-
模块from concurrent.futures import ThreadPoolExecutor
-
submit --向线程池提交线程
-
shutdown --关闭这个线程池
-
在用完一个线程池后,应该调用该线程池的shutdown()方法,该方法将启动线程池的关闭序列。
调用shutdown()方法后的线程池不再接受新任务,但会将以前所有的已提交的任务执行完成。当线程池中的所有任务都执行完成后,该线程池中的所有线程都会死亡。 -
线程池在系统启动时即创建大量空闲的线程,程序只要将一个函数提交给线程池,线程池就会启动一个空闲的线程来执行它。当该函数执行结束后,该线程并不会死亡,而是再次返回到线程池中变成空闲状态,等待执行下一个函数。
-
ThreadPoolExecutor:限制开启线程的数量 ################实例一#################### import threading import time def task(): time.sleep(2) print('任务') num = int(input('请输入要执行的任务个数:')) for i in range(num): t = threading.Thread(target=task) t.start()##############################实例二################################ ThreadPoolExecutor:限制开启线程的数量 import time from concurrent.futures import ThreadPoolExecutor def task(n1, n2): time.sleep(2) print('任务') # 创建线程池 pool = ThreadPoolExecutor(10) for i in range(100): pool.submit(task, i, 1) #向线程池提交一个线程 print('END') # 等线程池中的任务执行完毕之后,再继续往下走 pool.shutdown(True) #关闭这个线程池 print('其他操作,依赖线程池执行的结果')##############实例三################ import time from concurrent.futures import ThreadPoolExecutor def task(arg): time.sleep(2) print('任务') return 666 # 创建线程池 pool = ThreadPoolExecutor(10) ret = pool.map(task,range(1,20)) print('END',ret) pool.shutdown(True) for item in ret: print(item)##################实例四########################## import time from concurrent.futures import ThreadPoolExecutor def task(n1, n2): time.sleep(2) print('任务') return n1+n2 # 创建线程池 pool = ThreadPoolExecutor(10) future_list = [] for i in range(20): fu = pool.submit(task, i, 1) future_list.append(fu) pool.shutdown(True) for fu in future_list: print(fu.result()) #获取返回值 -
进程池
python 2中没有线程池只有进程池 python 3中线程池和进程池都有 ####################实例######################### import time from concurrent.futures import ProcessPoolExecutor def task(n1, n2): time.sleep(2) print('任务') if __name__ == '__main__': # 创建线程池 pool = ProcessPoolExecutor(10) for i in range(20): pool.submit(task, i, 1) print('END') -
协程
-
进程,协程,线程的区别:三个都可以提高并发
进程是计算机中资源分配的最小单位,线程是计算机中cpu可调度的最小单位:
协程 又称为 '微线程' 是基于认为创造的,而进程和线程是真是存在的,一个进程可以有多个线程,一个线程可以创建多个协程
-
计算密集型------使用多进程
-
IO密集型-------使用多线程/协程+IO切换
-
单纯的协程是没有办法提高并发的,只是代码之间的来回切换,加上 IO 自动切换才有意思,有IO操作使用协程
#############协程实例############ from greenlet import greenleet def test1(): print('11') gr2.swith() print('33') def test2(): print('22') gr1.swith() print('44') gr1 = greenlent(test1) gr2 = greenlent(test2) gr1.swith() gevent是基于greenlet开发的 -
-
协程+IO切换
gevent 遇到IO自动切换 from gevent import monkey monkey.patch_all() #使用猴子补丁褒贬不一,但是官网上还是建议使用”patch_all()”,而且在程序的第一行就执行。 import gevent import time def eat(): print('eat food 1') time.sleep(3) print('eat food 2') def play(): print('play 1') time.sleep(3) print('play 2') g1 = gevent.spawn(eat) g2 = gevent.spawn(play) gevent.joinall([g1, g2])-
greenlet
from greenlet import greenlet import time def a(name): print(name+"A1") g2.switch("这是") time.sleep(2) print(name+"A2") g2.switch() def b(name): print(name+"B1") g1.switch() print(name+"B2") g1 = greenlet(a) g2 = greenlet(b) g1.switch("这是")import gevent import time from gevent import monkey monkey.patch_all() # 打补丁,将下面所有的任务阻塞都打上标记 def a(name): print(name + "A1") time.sleep(2) print(name + "A2") def b(name): print(name + "B1") time.sleep(1) print(name + "B2") g1 = gevent.spawn(a, "这是") g2 = gevent.spawn(b, "这是") # g1.join() # g2.join() gevent.joinall([g1,g2])
-
-
协程+IO切换 爬虫示例
from gevent import monkey monkey.patch_all() import gevent import requests def f1(url): print('GET: %s' % url) data = requests.get(url) print('%d bytes received from %s.' % (len(data.content), url)) def f2(url): print('GET: %s' % url) data = requests.get(url) print('%d bytes received from %s.' % (len(data.content), url)) def f3(url): print('GET: %s' % url) data = requests.get(url) print('%d bytes received from %s.' % (len(data.content), url)) gevent.joinall([ gevent.spawn(f1, 'https://www.python.org/'), gevent.spawn(f2, 'https://www.yahoo.com/'), gevent.spawn(f3, 'https://github.com/'), ])
-
6. 队列Queue
-
队列Queue的概念相信大家都知道,我们可以用它的put和get方法来存取队列中的元素。gevent的队列对象可以让greenlet协程之间安全的访问。运行下面的程序,你会看到3个消费者会分别消费队列中的产品,且消费过的产品不会被另一个消费者再取到:
-
注意:协程队列跟线程队列是一样的,put和get方法都是阻塞式的
""" 队列: Queue redis中的列表 rabbitMQ """ from queue import Queue q = Queue() """ q.put('123') q.put(456) v1 = q.get() v2 = q.get() print(v1,v2) """ # 默认阻塞 v1 = q.get() print(v1) -
发送邮件实例
""" 1. 申请126或163邮箱 2. 开启服务+授权码 3. 通过代码发送 """ import smtplib from email.mime.text import MIMEText from email.utils import formataddr # 写邮件的内容 msg = MIMEText('老板,我想演男一号,你想怎么着都行。', 'plain', 'utf-8') msg['From'] = formataddr(["炮手", 'zh309603@163.com']) msg['To'] = formataddr(["老板", '424662508@qq.com']) msg['Subject'] = "情爱的导演" server = smtplib.SMTP_SSL("smtp.163.com", 465) server.login("zh309603", "zhzzhz123") # 授权码 server.sendmail('zh309603@163.com', ['424662508@qq.com', ], msg.as_string()) server.quit() -
生产者和消费者模型
- 三要素
- 生产者:产生数据
- 消费者:接受数据,进行处理
- 容器:队列,缓冲作用,平衡生产力和消费力
- 三要素
#############实例发邮件#################
import threading
from queue import Queue
import time
q = Queue()
def send(to,subject,text):
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
# 写邮件的内容
msg = MIMEText(text, 'plain', 'utf-8')
msg['From'] = formataddr(["人人", '1614655582@qq.com']) #我的邮件号
msg['To'] = formataddr(["兽兽", to]) # 别人的邮件号
msg['Subject'] = subject
server = smtplib.SMTP_SSL("smtp.qq.com", 465)
server.login("1614655582", "vxyklhhuhbqdeecd") # 授权码自己的
server.sendmail('1614655582@qq.com', [to, ], msg.as_string()) #我自己的 to代表是他的
server.quit()
def producer(i):
"""
生产者
:return:
"""
print('生产者往队列中放了10个任务',i)
info = {'to':'865295648@qq.com', 'text':'你好我是你大爷速速回复','subject':'好友请求'}
q.put(info)
def consumer():
"""
消费者
:return:
"""
while True:
print('消费者去队列中取了任务')
info = q.get()
print(info)
time.sleep(10)
send(info['to'],info['subject'],info['text'])
for i in range(10):
t = threading.Thread(target=producer,args=(i,))
t.start()
for j in range(5):
t = threading.Thread(target=consumer)
t.start()
发邮件实例2
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
for i in range(20):
# 写邮件的内容
msg = MIMEText('天凉了,注意保暖!暖暖暖', 'plain', 'utf-8')
msg['From'] = formataddr(["最好友", '1614655582@qq.com'])
msg['To'] = formataddr(["好友", '1612552152@qq.com'])
msg['Subject'] = "温馨提示"
server = smtplib.SMTP_SSL("smtp.qq.com", 465)
server.login("1614655582", "vxyklhhuhbqdeecd") # 授权码
server.sendmail('1614655582@qq.com', ['1612552152@qq.com', ], msg.as_string())
server.quit()
