For Flink applications to run reliably at large scale, two conditions must be fulfilled:
-
The application needs to be able to take checkpoints reliably
-
The resources need to be sufficient catch up with the input data streams after a failure
The first sections discuss how to get well performing checkpoints at scale. The last section explains some best practices concerning planning how many resources to use.
Tuning Checkpointing
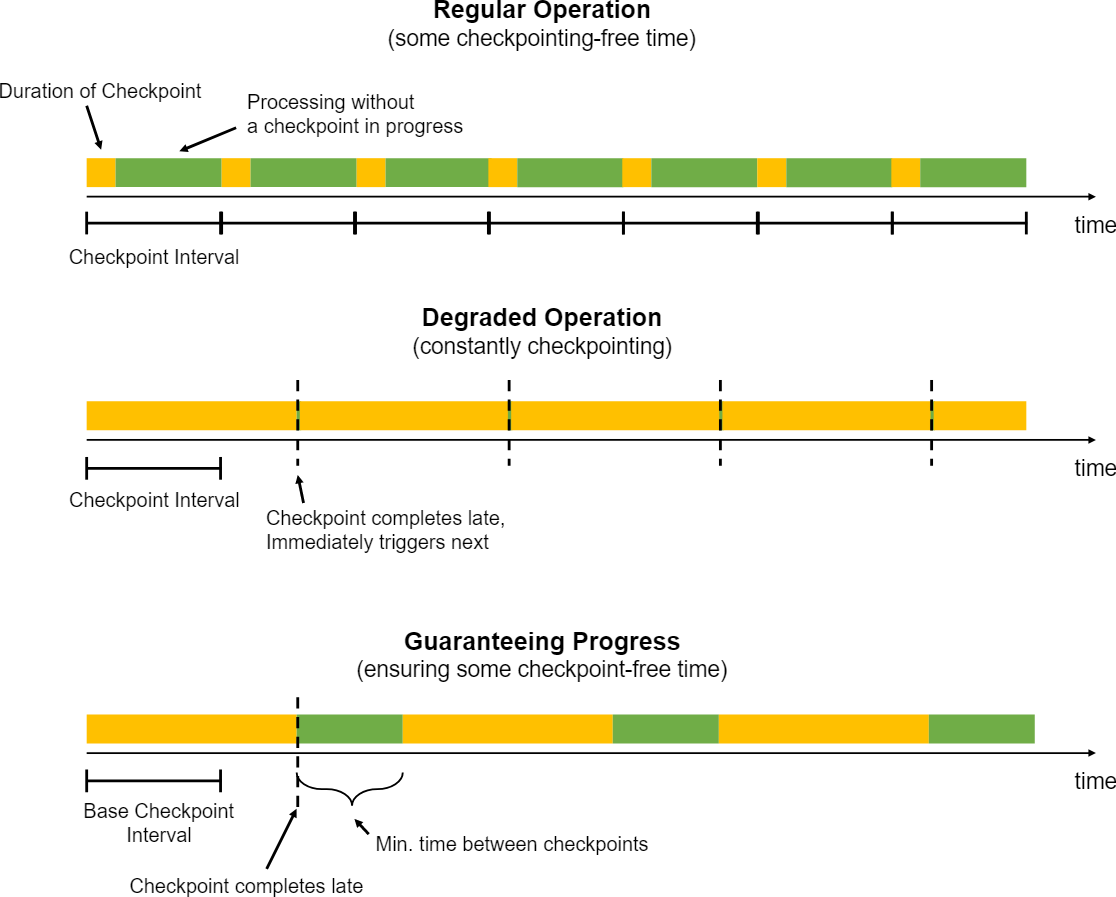
Checkpoints are triggered at regular intervals that applications can configure. When a checkpoint takes longer to complete than the checkpoint interval, the next checkpoint is not triggered before the in-progress checkpoint completes. By default the next checkpoint will then be triggered immediately once the ongoing checkpoint completes.
When checkpoints end up frequently taking longer than the base interval (for example because state grew larger than planned, or the storage where checkpoints are stored is temporarily slow), the system is constantly taking checkpoints (new ones are started immediately once ongoing once finish). That can mean that too many resources are constantly tied up in checkpointing and that the operators make too little progress. This behavior has less impact on streaming applications that use asynchronously checkpointed state, but may still have an impact on overall application performance.
To prevent such a situation, applications can define a minimum duration between checkpoints:
StreamExecutionEnvironment.getCheckpointConfig().setMinPauseBetweenCheckpoints(milliseconds)
This duration is the minimum time interval that must pass between the end of the latest checkpoint and the beginning of the next. The figure below illustrates how this impacts checkpointing.
Tuning RocksDB
Incremental Checkpoints
When it comes to reducing the time that checkpoints take, activating incremental checkpoints should be one of the first considerations. Incremental checkpoints can dramatically reduce the checkpointing time in comparison to full checkpoints, because incremental checkpoints only record the changes compared to the previous completed checkpoint, instead of producing a full, self-contained backup of the state backend.
See Incremental Checkpoints in RocksDB for more background information.
Timers in RocksDB or on JVM Heap
Timers are stored in RocksDB by default, which is the more robust and scalable choice.
When performance-tuning jobs that have few timers only (no windows, not using timers in ProcessFunction), putting those timers on the heap can increase performance. Use this feature carefully, as heap-based timers may increase checkpointing times and naturally cannot scale beyond memory.
See this section for details on how to configure heap-based timers.
Tuning RocksDB Memory
The performance of the RocksDB State Backend much depends on the amount of memory that it has available. To increase performance, adding memory can help a lot, or adjusting to which functions memory goes.
Capacity Planning
This section discusses how to decide how many resources should be used for a Flink job to run reliably. The basic rules of thumb for capacity planning are:
Compression
Flink offers optional compression (default: off) for all checkpoints and savepoints. Currently, compression always uses the snappy compression algorithm (version 1.1.4) but we are planning to support custom compression algorithms in the future. Compression works on the granularity of key-groups in keyed state, i.e. each key-group can be decompressed individually, which is important for rescaling.
Task-Local Recovery
https://www.cnblogs.com/zgq25302111/p/13186318.html
ref: