序列化模块:
什么是序列化呢? 序列化的本质就是将一种数据结构(如字典、列表)等转换成一个特殊的序列(字符串或者bytes)的过程就叫做序列化。
将这个字典直接写入文件是不可以的,必须转化成字符串的形式,而且你读取出来也是字符串形式的字典(可以用代码展示)。
json序列化除了可以解决写入文件的问题,还可以解决网络传输的问题,比如你将一个list数据结构通过网络传给另个开发者,那么你不可以直接传输,之前我们说过,你要想传输出去必须用bytes类型。但是bytes类型只能与字符串类型互相转化,它不能与其他数据结构直接转化,所以,你只能将list ---> 字符串 ---> bytes 然后发送,对方收到之后,在decode() 解码成原字符串。此时这个字符串不能是我们之前学过的str那种字符串,因为它不能反解,必须要是这个特殊的字符串,他可以反解成list 这样开发者之间就可以借助网络互传数据了,不仅仅是开发者之间,你要借助网络爬取数据这些数据多半是这种特殊的字符串,你接受到之后,在反解成你需要的数据类型。
序列化模块就是将一个常见的数据结构转化成一个特殊的序列,并且这个特殊的序列还可以反解回去。它的主要用途:文件读写数据,网络传输数据。
不同语言都遵循的一种数据转化格式,即不同语言都使用的特殊字符串。(比如Python的一个列表[1, 2, 3]利用json转化成特殊的字符串,然后在编码成bytes发送给php的开发者,php的开发者就可以解码成特殊的字符串,然后在反解成原数组(列表): [1, 2, 3])
json序列化只支持部分Python数据结构:dict,list, tuple,str,int, float,True,False,None
支持Python所有的数据类型包括实例化对象。
json模块是将满足条件的数据结构转化成特殊的字符串,并且也可以反序列化还原回去。
序列化模块总共只有两种用法,要不就是用于网络传输的中间环节,要不就是文件存储的中间环节,所以json模块总共就有两对四个方法:
json模块:
用于网络传输:dumps、loads
用于文件写读:dump、load
dumps、loads:
1、将字典类型转换成字符串类型:
import json
dic = {'k1':'v1','k2':'v2','k3':'v3'}
str_dic = json.dumps(dic) #序列化:将一个字典转换成一个字符串
print(type(str_dic),str_dic)
结果:<class 'str'> {"k3": "v3", "k1": "v1", "k2": "v2"} #注意,json转换完的字符串类型的字典中的字符串是由""表示的2、将字符串类型的字典转换成字典类型用loads:
import json
dic2 = json.loads(str_dic) #反序列化:将一个字符串格式的字典转换成一个字典
#注意,要用json的loads功能处理的字符串类型的字典中的字符串必须由""表示
print(type(dic2),dic2)
结果:<class 'dict'> {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
3、还支持列表类型:
list_dic = [1,['a','b','c'],3,{'k1':'v1','k2':'v2'}]
str_dic = json.dumps(list_dic) #也可以处理嵌套的数据类型
print(type(str_dic),str_dic)
结果:<class 'str'> [1, ["a", "b", "c"], 3, {"k1": "v1", "k2": "v2"}]
list_dic2 = json.loads(str_dic)
print(type(list_dic2),list_dic2)
结果:<class 'list'> [1, ['a', 'b', 'c'], 3, {'k1': 'v1', 'k2': 'v2'}]
dump、load:
1、将对象转换成字符串写入到文件当中:
import json
f = open('json_file.json','w')
dic = {'k1':'v1','k2':'v2','k3':'v3'}
json.dump(dic,f) #dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件
f.close()
# json文件也是文件,就是专门存储json字符串的文件。
2、将文件中的字符串类型的字典转换成字典:
import json
f = open('json_file.json')
dic2 = json.load(f) #load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回
f.close()
print(type(dic2),dic2)
3、其他参数说明:
ensure_ascii:,当它为True的时候,所有非ASCII码字符显示为uXXXX序列,只需在dump时将ensure_ascii设置为False即可,此时存入json的中文即可正常显示。
separators:分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就是(,,:);这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。
sort_keys:将数据根据keys的值进行排序。 剩下的自己看源码研究
4、json序列化存储多个数据到同一个文件中:
对于json序列化,存储多个数据到一个文件中是有问题的,默认一个json文件只能存储一个json数据,但是也可以解决,举例说明:
对于json 存储多个数据到文件中:
dic1 = {'name':'oldboy1'}
dic2 = {'name':'oldboy2'}
dic3 = {'name':'oldboy3'}
f = open('序列化',encoding='utf-8',mode='a')
json.dump(dic1,f)
json.dump(dic2,f)
json.dump(dic3,f)
f.close()
f = open('序列化',encoding='utf-8')
ret = json.load(f)
ret1 = json.load(f)
ret2 = json.load(f)
print(ret)
上边的代码会报错,解决方法:
dic1 = {'name':'oldboy1'}
dic2 = {'name':'oldboy2'}
dic3 = {'name':'oldboy3'}
f = open('序列化',encoding='utf-8',mode='a')
str1 = json.dumps(dic1)
f.write(str1+'
')
str2 = json.dumps(dic2)
f.write(str2+'
')
str3 = json.dumps(dic3)
f.write(str3+'
')
f.close()f = open('序列化',encoding='utf-8')
for line in f:
print(json.loads(line))pickle模块:
只能是Python语言遵循的一种数据转化格式,只能在python语言中使用。
pickle模块是将Python所有的数据结构以及对象等转化成bytes类型,然后还可以反序列化还原回去。
刚才也跟大家提到了pickle模块,pickle模块是只能Python语言识别的序列化模块。如果把序列化模块比喻成全世界公认的一种交流语言,也就是标准的话,json就是像是英语,全世界(python,java,php,C,等等)都遵循这个标准。而pickle就是中文,只有中国人(python)作为第一交流语言。
既然只是Python语言使用,那么它支持Python所有的数据类型包括后面我们要讲的实例化对象等,它能将这些所有的数据结构序列化成特殊的bytes,然后还可以反序列化还原。使用上与json几乎差不多,也是两对四个方法。
用于网络传输:dumps、loads
用于文件写读:dump、load
dumps、loads:
import pickle
dic = {'k1':'v1','k2':'v2','k3':'v3'}
str_dic = pickle.dumps(dic)
print(str_dic) # bytes类型
dic2 = pickle.loads(str_dic)
print(dic2) #字典
# 还可以序列化对象
import pickle
def func():
print(666)
ret = pickle.dumps(func)
print(ret,type(ret)) # b'x80x03c__main__
func
qx00.' <class 'bytes'>
f1 = pickle.loads(ret) # f1得到 func函数的内存地址
f1() # 执行func函数
dump、load:
dic = {(1,2):'oldboy',1:True,'set':{1,2,3}}
f = open('pick序列化',mode='wb')
pickle.dump(dic,f)
f.close()
with open('pick序列化',mode='wb') as f1:
pickle.dump(dic,f1)
pickle序列化存储多个数据到一个文件中:
dic1 = {'name':'oldboy1'}
dic2 = {'name':'oldboy2'}
dic3 = {'name':'oldboy3'}
f = open('pick多数据',mode='wb')
pickle.dump(dic1,f)
pickle.dump(dic2,f)
pickle.dump(dic3,f)
f.close()
f = open('pick多数据',mode='rb')
while True:
try:
print(pickle.load(f))
except EOFError:
break
f.close()
这时候机智的你又要说了,既然pickle如此强大,为什么还要学json呢?这里我们要说明一下,json是一种所有的语言都可以识别的数据结构。如果我们将一个字典或者序列化成了一个json存在文件里,那么java代码或者js代码也可以拿来用。但是如果我们用pickle进行序列化,其他语言就不能读懂这是什么了~所以,如果你序列化的内容是列表或者字典,我们非常推荐你使用json模块,但如果出于某种原因你不得不序列化其他的数据类型,而未来你还会用python对这个数据进行反序列化的话,那么就可以使用pickle。
shelve模块
shelve模块:类似于字典的操作方式去操作特殊的字符串(不讲,可以课下了解)。
#1、将字典放入文本
import shelve
f = shelve.open(r"shelve")
f["stul_info"] = {"name":"alex","age":"18"}
f.close()
# dic = {}
# dic["name"] = "alvin"
# dic["info"] = {"name":"alex"}
XML模块
#1、用getroot打印根节点
import xml.etree.ElementTree as ET #as后面的ET代指前面模块的名字
tree = ET.parse("xml_lesson.xml") #用ET里面的parse方法并赋予对象tree、
root = tree.getroot()
print(root.tag)
#2、遍历xml文档
for i in root:
print(i)
#3、遍历属性tag
for i in root:
print(i.tag)
#4、双层循环遍历
for i in root:
for j in i:
print(j.tag)
#5、看值attrib属性组成键值对
for i in root :
print(i.attrib)
#6、遍历打印子元素
for i in root:
for j in i:
print(j.attrib)
#7、text
for i in root:
for j in i:
print(j.text)
re正则模块
import re
#1、找到以a开头和l结尾的
s = "hellocdalexfdsfdsfdsf"
print(s.find("alex"))
#2、371481198506143635(alex身份证号)
print(re.findall("d+","alex22ccsd45vcxvcx767bvcbcv876"))
#3、findall(匹配规则+内容)
print(re.findall("alex","afdsvcxvfsg"))
#4、a..x(代表以a开头中间任意两个字符以x结尾的
print(re.findall("a..x","affxcvcvsdf"))
#5、^尖角号代表以什么开头
print(re.findall("^a..c","acxcxacxcx"))
#6、$代表以什么结尾
print(re.findall("a..x$","acxvfsdfsdarrx"))
#7、*代表0到无穷次
print(re.findall("d*","dfdsfdsfdsadsadddddddddvcxvxc"))
#8、?
#9、{}为范围取
#10、[]中括号字符集
#11、(小括号
print(re.findall("([^()]*)","12 + (34 * 6 + 2 - 5*(2-1)"))
#12d
#13D
#14、|管道符代表或的意思
print(re.findall(r"ka|b","sdjkbsf"))
print(re.findall(r"ka|b","sdjkabsf"))
print(re.findall(r"ka|bc","sdjkabcsf"))
#15、d+
print(re.sub("d+","A","fdsfdsfjaskd4324vcxvxc"))
#16、加参数
print(re.subn("d","A","jackcxcvsdfd4343543543vcxvxcavcxvxd543534fdfds",8))
#17、
loging日志模块
#1、日志级别
import logging
#2、增加参数
# logging.basicConfig(
# level=logging.DEBUG,
# filename="logger.log",
# filename="w" #模式是追加
# )
# logging.debug("debug message")
# logging.info("info message")
# logging.warning("warning message")
# logging.error("error message")
# logging.critical("critical message")
#3、
import configparser
config = configparser.ConfigParser() #用configparser模块里面的ConfigParser类生成config对象
config["DEFAULT"] = {"ServerAliveInterval" : "45", #键值对
"Compression": "yes",
"CompressionLevel" : "9"}
config["bitbucket.org"] = {}
config["bitbucket.org"]["User"] = "hg"
config["topsecret.server.com"] = {}
topsecret = config["topsecret.server.com"]
topsecret["Host Port"] = "50022"
topsecret["ForwardXll"] = "no"
config["DEFAULT"]["ForwardXll"] = "yes"
with open("example.ini","w") as configfile:
config.write(configfile)
hashlib哈希模块:
hashlib的特征以及使用要点:
1、bytes类型数据 ---> 通过hashlib算法 ---> 固定长度的字符串
2、不同的bytes类型数据转化成的结果一定不同。
3、相同的bytes类型数据转化成的结果一定相同。
4、此转化过程不可逆。
hashlib模块就相当于一个算法的集合,这里面包含着很多的算法,算法越高,转化成的结果越复杂,安全程度越高,相应的效率就会越低。
普通加密:
我们以常见的摘要算法MD5为例,计算出一个字符串的MD5值:
import hashlib
md5 = hashlib.md5()
md5.update('123456'.encode('utf-8')) # 必须是bytes类型才能够进行加密
print(md5.hexdigest())
# 计算结果如下:
'e10adc3949ba59abbe56e057f20f883e'
# 验证:相同的bytes数据转化的结果一定相同
import hashlib
md5 = hashlib.md5()
md5.update('123456'.encode('utf-8'))
print(md5.hexdigest())
# 计算结果如下:
'e10adc3949ba59abbe56e057f20f883e'
# 验证:不相同的bytes数据转化的结果一定不相同
import hashlib
md5 = hashlib.md5()
md5.update('12345'.encode('utf-8'))
print(md5.hexdigest())
# 计算结果如下:
'827ccb0eea8a706c4c34a16891f84e7b'
固定加盐:
ret = hashlib.md5('xx教育'.encode('utf-8')) # xx教育就是固定的盐
ret.update('a'.encode('utf-8'))
print(ret.hexdigest())
结果:d9e8fff14a026ecefa7d700334279762
动态加盐:
username = '宝元666'
ret = hashlib.md5(username[::2].encode('utf-8')) # 针对于每个账户,每个账户的盐都不一样
ret.update('a'.encode('utf-8'))
print(ret.hexdigest())
sha系列:sha1,sha224,sha512等等,数字越大,加密的方法越复杂,安全性越高,但是效率就会越慢。
ret = hashlib.sha1()
ret.update('guobaoyuan'.encode('utf-8'))
print(ret.hexdigest())
#也可加盐
ret = hashlib.sha384(b'asfdsa')
ret.update('guobaoyuan'.encode('utf-8'))
print(ret.hexdigest())
# 也可以加动态的盐
ret = hashlib.sha384(b'asfdsa'[::2])
ret.update('guobaoyuan'.encode('utf-8'))
print(ret.hexdigest())
文件的一致性校验:
hashlib模块除了可以用于密码加密之外,还有一个常用的功能,那就是文件的一致性校验。linux讲究:一切皆文件,我们普通的文件,是文件,视频,音频,图片,以及应用程序等都是文件。我们都从网上下载过资源,比如我们刚开学时让大家从网上下载Python解释器,当时你可能没有注意过,其实你下载的时候都是带一个MD5或者shax值的,为什么? 我们的网络世界是很不安全的,经常会遇到病毒,木马等,有些你是看不到的可能就植入了你的电脑中,那么他们是怎么来的? 都是通过网络传入来的,就是你在网上下载一些资源的时候,趁虚而入,当然大部分被我们的浏览器或者杀毒软件拦截了,但是还有一部分偷偷的进入你的磁盘中了。那么我们自己如何验证我们下载的资源是否有病毒呢?这就需要文件的一致性校验了。在我们下载一个软件时,往往都带有一个MD5或者shax值,当我们下载完成这个应用程序时你要是对比大小根本看不出什么问题,你应该对比他们的md5值,如果两个md5值相同,就证明这个应用程序是安全的,如果你下载的这个文件的MD5值与服务端给你提供的不同,那么就证明你这个应用程序肯定是植入病毒了(文件损坏的几率很低),那么你就应该赶紧删除,不应该安装此应用程序。
我们之前说过,md5计算的就是bytes类型的数据的转换值,同一个bytes数据用同样的加密方式转化成的结果一定相同,如果不同的bytes数据(即使一个数据只是删除了一个空格)那么用同样的加密方式转化成的结果一定是不同的。所以,hashlib也是验证文件一致性的重要工具。
校验Pyhton解释器的Md5值是否相同:
import hashlib
def file_check(file_path):
with open(file_path,mode='rb') as f1:
sha256 = hashlib.md5()
while 1:
content = f1.read(1024)
if content:
sha256.update(content)
else:
return sha256.hexdigest()
print(file_check('python-3.6.6-amd64.exe'))
socketserver模块:


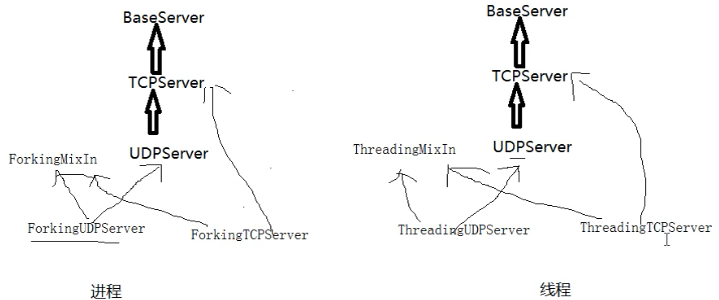
server类:处理链接包含:BaseServer、TcpServer、UdpServer、UnixStreamServer、UnixDatagramServer。
request类:处理通信包含BaseRequestHandler、StreamRequestHandler、DatagramRequestHandler。
对于tcp来说
self.request=conn
对于udp来说
self.request=(client_data_bytes,udp的套接字对象)
collections(收藏)模块:
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict以及判断什么是可迭代对象什么是迭代器
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
namedtuple:
我们知道tuple可以表示不变数据,例如,一个点的二维坐标就可以表示成:
p = (1, 2)
但是,看到(1, 2),很难看出这个tuple是用来表示一个坐标的。
这时,namedtuple就派上了用场:
from collections import namedtuple
point = namedtuple("point",["x","y"])
p = point(1,2)
print(p)
结果:point(x=1, y=2)
deque:
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
from collections import deque
q = deque(['a', 'b', 'c'])
q.append('x')
q.appendleft('y')
print(q)
结果:q deque(['y', 'a', 'b', 'c', 'x'])
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
OrderedDict:
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
from collections import OrderedDict
od = OrderedDict([("a",1),("b",2),("c",3)])
print(od)
结果:OrderedDict([('a', 1), ('b', 2), ('c', 3)])
OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
from collections import OrderedDict
od = OrderedDict([("a",1),("b",2),("c",3)])
od["z"] = 1
od["y"] = 2
od["x"] = 3
print(od.keys())
结果:odict_keys(['a', 'b', 'c', 'z', 'y', 'x'])
defaultdict:
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
即: {'k1': 大于66 , 'k2': 小于66}
from collections import defaultdict
values = [11,22,33,44,55,66,77,88,99,90]
my_dict = defaultdict(list)
for value in values:
if value > 66:
my_dict["k1"].append(value)
else:
my_dict["k2"].append(value)
print(my_dict)
结果:defaultdict(<class 'list'>, {'k2': [11, 22, 33, 44, 55, 66], 'k1': [77, 88, 99, 90]})
Counter:
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。
from collections import Counter
c = Counter("dsadasdsfdafsdsfds")
print(c)
结果:Counter({'d': 6, 's': 6, 'a': 3, 'f': 3})
isinstance:
判断当前数据类型,返回的是一个布尔值
from collections import Iterable,Iterator
lst = [1,2,3,4]
print(isinstance(lst,list)) # 判断lst是不是列表类型 返回的是True
print(isinstance(lst,Iterator)) # 判断lst是不是迭代器 返回的是False
print(isinstance(lst,Iterable)) # 判断lst是不是可迭代对象 返回的是True
软件开发规范:
你现在包括之前写的一些程序,所谓的'项目',都是在一个py文件下完成的,代码量撑死也就几百行,你认为没问题,挺好。但是真正的后端开发的项目,系统等,少则几万行代码,多则十几万,几十万行代码,你全都放在一个py文件中行么?当然你可以说,只要能实现功能即可。咱们举个例子,如果你的衣物只有三四件,那么你随便堆在橱柜里,没问题,咋都能找到,也不显得特别乱,但是如果你的衣物,有三四十件的时候,你在都堆在橱柜里,可想而知,你找你穿过三天的袜子,最终从你的大衣口袋里翻出来了,这是什么感觉和心情......
软件开发,规范你的项目目录结构,代码规范,遵循PEP8规范等等,让你更加清晰滴,合理滴开发。
那么接下来我们以博客园系统的作业举例,将我们之前在一个py文件中的所有代码,整合成规范的开发。
首先我们看一下,这个是我们之前的目录结构(简化版):

py文件的具体代码如下:
status_dic = {
'username': None,
'status': False,
}
flag = True
def login():
i = 0
with open('register', encoding='utf-8') as f1:
dic = {i.strip().split('|')[0]: i.strip().split('|')[1] for i in f1}
while i < 3:
username = input('请输入用户名:').strip()
password = input('请输入密码:').strip()
if username in dic and dic[username] == password:
print('登录成功')
return True
else:
print('用户名密码错误,请重新登录')
i += 1
def register():
with open('register', encoding='utf-8') as f1:
dic = {i.strip().split('|')[0]: i.strip().split('|')[1] for i in f1}
while 1:
print('�33[1;45m 欢迎来到注册页面 �33[0m')
username = input('请输入用户名:').strip()
if not username.isalnum():
print('�33[1;31;0m 用户名有非法字符,请重新输入 �33[0m')
continue
if username in dic:
print('�33[1;31;0m 用户名已经存在,请重新输入 �33[0m')
continue
password = input('请输入密码:').strip()
if 6 <= len(password) <= 14:
with open('register', encoding='utf-8', mode='a') as f1:
f1.write(f'
{username}|{password}')
status_dic['username'] = str(username)
status_dic['status'] = True
print('�33[1;32;0m 恭喜您,注册成功!已帮您成功登录~ �33[0m')
return True
else:
print('�33[1;31;0m 密码长度超出范围,请重新输入 �33[0m')
def auth(func)