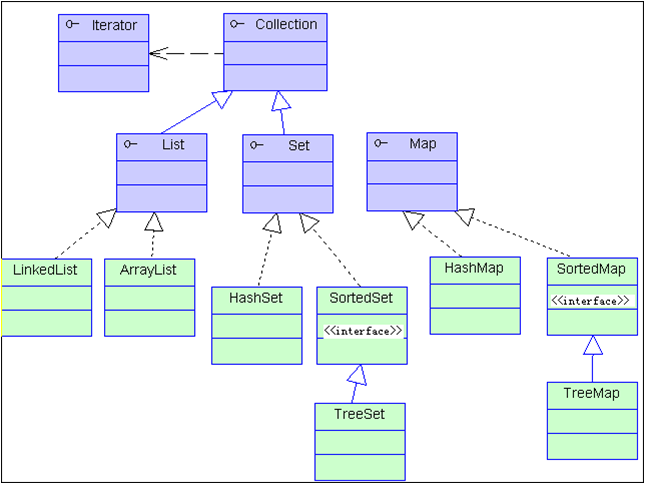
关系的介绍:
- Set(集):集合中的元素不按特定方式排序,并且没有重复对象。他的有些实现类能对集合中的对象按特定方式排序。
- List(列表):集合中的元素按索引位置排序,可以有重复对象,允许按照对象在集合中的索引位置检索对象。
- Map(映射):集合中的每一个元素包含一对键对象和值对象,集合中没有重复的键对象,值对象可以重复。他的有些实现类能对集合中的键对象进行排序。
简单的区别:Set和List都是继承与Collection,set元素无序且不重复,list有序且允许重复。map存储的是键值对。这三个都是定义了集合接口类,具体使用还是需要实现类的实例。
基本接口和类型:
Iterator接口
该接口允许遍历集合中的所有元素,一共有三个方法:
- public boolean hasNext():判断是否还有下一个元素。
- public Object next():取得下一个元素,注意返回值为 Object,可能需要类型转换。如果不再有可取元素,则抛出NoSuchElementException异常。在使用该方法之前,必须先使用hasNext()方法判断。
- public void remove():删除当前元素,很少用。
Collection接口
该接口是Set和List的父接口,主要提供了下面的方法:
- public boolean add(Object?o):往集合中添加新元素。添加成功,返回true,否则返回false。
- public Iterator iterator():返回Iterator对象,这样就可以遍历集合中的所有元素了。
- public boolean contains(Object?o):判断集合中是否包含指定的元素。
- public int size():取得集合中元素的个数。
- public void clear():删除集合中的所有元素。
Collection是最基本的集合接口,一个Collection代表一组Object,即Collection的元素(Elements)。一些Collection允许相同的元素而另一些不行。一些能排序而另一些不行。
Java SDK不提供直接继承自Collection的类,JavaSDK提供的类都是继承自Collection的“子接口”如List和Set。
所有实现Collection接口的类都必须提供两个标准的构造函数:无参数的构造函数用于创建一个空的Collection,有一个Collection参数的构造函数用于创建一个新的Collection,这个新的Collection与传入的Collection有相同的元素。后一个构造函数允许用户复制一个Collection。
遍历Collection中的每一个元素:
Iterator it = collection.iterator(); // 获得一个迭代子
while(it.hasNext()) {
Object obj = it.next(); // 得到下一个元素
}
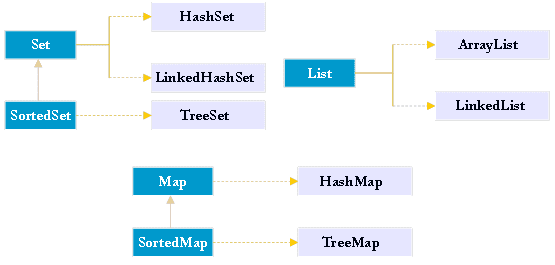
Set集合
主要有如下两个实现:HashSet和TreeSet
HashSet:按照哈希算法来存取集合中的对象,具有很好的存取性能。当HashSet向集合中加入一个对象时,会调用对象的hashCode()方法获取哈希码,然后根据这个哈希码进一步计算出对象在集合中的存放位置。(限定存放的位置其实也是为了更高效的查找对象)
LinkedHashSet:除了使用HashCode来决定元素位置之外,同时还是用了链表来维护元素的次序(Linked),因此对其插入元素时,看起来是有序的;
TreeSet:实现了SortedSet接口,可以对集合中的元素排序(支持自然排序和定制排序,实现Comparator接口的compare()方法来自定义一套比较大小的逻辑)。
List集合
List是一种有序集合,List中的元素可以根据索引(顺序号:元素在集合中处于的位置信息)进行取得/删除/插入操作。
List还提供一个listIterator()方法,返回一个ListIterator接口对象,和Iterator接口相比,ListIterator添加元素的添加,删除,和设定等方法,还能向前或向后遍历。
List接口的实现类主要有ArrayList,LinkedList,Vector,Stack等。
1 ArrayList类:
实现了可变大小的数组。ArrayList没有同步。 每个ArrayList实例都有一个容量(Capacity),即用于存储元素的数组的大小。这个容量可随着不断添加新元素而自动增加,但是增长算法并没有定义。当需要插入大量元素时,在插入前可以调用ensureCapacity方法来增加ArrayList的容量以提高插入效率。
主要方法:
- public boolean add(Object?o):添加元素
- public void add(int index, Object element):在指定位置添加元素
- public Iterator iterator():取得Iterator对象便于遍历所有元素
- public Object get(int?index):根据索引获取指定位置的元素
- public Object set(int index,Object element):替换掉指定位置的元素
排序方法:
- Collections.sort(List list):对List的元素进行自然排序(升序方式),此时list中的对象必须实现了Comparable接口
- Collections.sort(List list, Comparator comparator):对List中的元素进行客户化排序 。sort()方法只是将Comparator接口中的compare()方法比较结果为-1的放前面,0的放中间,1的放后面
2 LinkedList类
LinkedList实现了List接口,允许null元素。此外LinkedList提供额外的get,remove,insert方法在LinkedList的首部或尾部。这些操作使LinkedList可被用作堆栈(stack),队列(queue)或双向队列(deque)。
注意LinkedList没有同步方法。如果多个线程同时访问一个List,则必须自己实现访问同步。一种解决方法是在创建List时构造一个同步的List:List list = Collections.synchronizedList(new LinkedList(...));
Map
- Map是一种把键对象和值对象进行映射的集合,它的每一个元素都包含一对键对象和值对象。
- 向Map添加元素时,必须提供键对象和值对象。键对象不能重复,但值对象可以重复。
- 从Map中检索元素时,只要给出键对象,就可以返回对应的值对象。
1 HashMap
HashMap按照哈希算法来存取键对象,有很好的存取性能。和HashSet一样,要求当两个键对象通过equals()方法比较为true时,这两个键对象的hashCode()方法返回的哈希码也一样。
2 TreeMap
TreeMap实现了SortedMap接口,能对键对象进行排序。同TreeSet一样,TreeMap也支持自然排序和客户化排序两种方式。
方法列表
- public Object put(Object key, Object value):插入元素
- public Object get(Object?key):根据键对象获取值对象
- public Set keySet():取得所有键对象集合
- public Collection values():取得所有值对象集合
- public Set entrySet():取得Map.Entry对象集合,一个Map.Entry代表一个Map中的元素
总结

如果涉及到堆栈,队列等操作,应该考虑用List,对于需要快速插入,删除元素,应该使用LinkedList,如果需要快速随机访问元素,应该使用ArrayList。
尽量返回接口而非实际的类型,如返回List而非ArrayList,这样如果以后需要将ArrayList换成LinkedList时,客户端代码不用改变。这就是针对抽象编程。
参考:https://www.cnblogs.com/liqiu/p/3302607.html
-----------------------------------------------------------------------------------------------------
arraylist和linklist的对比:
- 时间:linklist不支持高效随机元素访问,对于二分这些算法效率很低,即index取值操作差;而arraylist不支持高效中间插入insert()和删除delete()元素,但对于add(),两者都是差不多的;
- 空间:linklist的entry引入了额外的开销;而arraylist开销体现在列表结尾预留的空间,通常每一次扩充会增加50%容量。