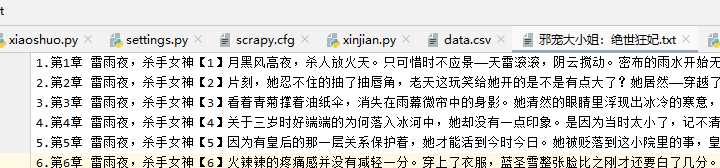
今天简单的爬取了一个小说,小说的爬虫相对来说比较简单,爬虫的网址是:http://www.92kshu.cc/69509/
主要通过正则表达式进行的简单的爬虫,获取每个章节的url地址,之后将界面中的内容获取
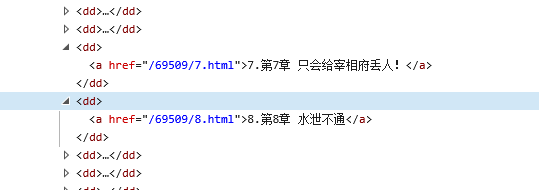
通过html可以看到每章节的网址后面都是和a标签里面的href属性内容一样的,只要获取了属性中的内容,就可以获得每个章节网页的网址,通过每个章节的网址来获取每章小说的内容

import requests
import re
url = 'http://www.92kshu.cc/69509/'
response = requests.get(url)
response.encoding = 'gbk'
html = response.text
title = re.findall(r'<meta property="og:novel:book_name" content="(.*?)"/>',html)[0]
fb = open('%s.txt' % title,'w',encoding='utf-8')
#获取每章的内容
#print(html)
dl = re.findall(r'<dl><dt><i class="icon"></i>正文</dt>(.*?)</dl>',html)[0]
print(dl)
chapter_info_list = re.findall(r'<dd><a href="(.*?)">(.*?)</a></dd>',dl)
print(chapter_info_list)
for chapter_info in chapter_info_list:
chapter_url,chapter_title = chapter_info
chapter_url = "http://www.92kshu.cc%s" %chapter_url
#print(chapter_url)
chapter_response = requests.get(chapter_url)
chapter_response.encoding = 'gbk'
chapter_html = chapter_response.text
chapter_content = re.findall(r'<div class="chapter">(.*?)><br>',chapter_html)[0]
#print(chapter_content)
chapter_content = chapter_content.replace('<p>','')
chapter_content = chapter_content.replace('</p>','')
fb.write(chapter_title)
fb.write(chapter_content)
fb.write('
')
print(chapter_url)
这是最后获取的小说的内容