一,字典:
1.定义方式:{}内用逗号分隔开多个元素,每一个元素都是key:value的形式,value可以是任意数据类型,而key通常应该是字符串类型,但是key必须为不可变类型。否则会报错。
三种方式:
# 1.一般使用的字典方式 d1 = {'name':'jason','password':123} # 2.关键字(键值对)方式 d2 = dict(name='jason',password=123,age=18) # 3.列表(for循环) l = [ ['name','jason'], ['age',18], ['hobby','read'] ] d={} for k ,v in l: d[k]=v print(d) # 或者直接强转 print(dict(l))
2.用途:存多个值,但每一个值都有一个key与之对应,key对值有描述功能。多用于存的值表示的是不同的状态时,例如存的值有姓名、年龄、身高、体重、爱好。
3.特点:
1) .存一个值or多个值:多个值,值可以是多个类型,key必须是不可变类型,通常应该是不可变类型中的字符串类型
2) 有序or无序:Python 3.6 改写了 dict 的内部算法,因此 3.6 的 dict 是有序的,在此版本之前皆是无序
3) 可变or不可变:可变数据类型
4.常用操作和内置方法:
1)按key存取值:可存可取
2)长度len
3)成员运算in 或not in
4)删除del(可以删除字典,也可以删除字典中的元素)、pop(通过key删除值)、popitem(随机从字典中删除一个键值对)
5)键keys、值values、键值对items
6)for循环
7)get() 根据键从字典中取值
8)update() 合并两个列表
9)fromkeys() 快速生成字典
10)setdefault()
11)clear() 、copy()
1)按key存取值:可存可取
# dic之按key存取值 dic = {'a': 1, 'b': 2} print(f"first dic['a']: {dic['a']}") dic['a'] = 3 print(f"second dic['a']: {dic['a']}") ''' first dic['a']: 1 second dic['a']: 3 '''
2) 长度len
# dic之长度len dic = {'a': 1, 'b': 2} print(f"len(dic): {len(dic)}") ''' len(dic): 2 '''
3) 成员运算in 或not in
# dic之成员运算in和not in dic = {'a': 1, 'b': 2} print(f"'a' in dic: {'a' in dic}") print(f"1 in dic: {1 in dic}") ''' 'a' in dic: True 1 in dic: False '''
4) 删除del
# del,pop,popitem dic={'name':'zhang','age':18,'gender':'male','hobby':'reading','province':'wan'} res=dic.pop('age') print(res) print(dic) res1=dic.popitem() #随机删除一个键值对,一般删除尾部的键值对 print(res1) print(dic) del(dic['name']) print(dic) #del(dic) # 会报错 #print(dic) # 会报错 ''' 18 {'name': 'zhang', 'gender': 'male', 'hobby': 'reading', 'province': 'wan'} ('province', 'wan') {'name': 'zhang', 'gender': 'male', 'hobby': 'reading'} {'gender': 'male', 'hobby': 'reading'} '''
5)键keys、值values、键值对items
# dic之键keys()、值values()、键值对items(),python2中取出的是列表(鸡蛋);python3中取出的是元组(鸡),需要用for循环取值 dic = {'a': 1, 'b': 2} print(f"dic.keys(): {dic.keys()}") print(f"dic.values(): {dic.values()}") print(f"dic.items(): {dic.items()}") ''' dic.keys(): dict_keys(['a', 'b']) dic.values(): dict_values([1, 2]) dic.items(): dict_items([('a', 1), ('b', 2)]) '''
6) for 循环
# dic之循环 # dic是无序的,但是python3采用了底层优化算法,所以看起来是有序的,但是python2中的字典是无序 dic = {'a': 1, 'b': 2, 'c': 3, 'd': 4} for k, v in dic.items(): # items可以换成keys()、values() print(k, v) ''' a 1 b 2 c 3 d 4 '''
7) get (根据键从字典中取值)
# get(参数1,参数2) 取值: ''' 1.只有参数1,当字典中存在该键(key)的时候,返回对应的值(value);当字典中不存在该键(key)的时候,返回None,不会报错; 2.两个参数同时存在,当字典中存在该键(key)的时候,返回字典中对应的值(value);当字典中不存在该键(key)的时候,返回参数2(自己设定的value) ''' dic1={'name':'zhang','age':18,'gender':'male','hobby':'reading','province':'wan'} print(dic1.get('name')) print(dic1.get('name','张三')) print(dic1.get('lucky_color')) print(dic1.get('lucky_color','blue')) ''' zhang zhang None blue '''
8) update
# dic之update() 更新字典 # 原字典中没有该键值对则添加,原字典中有的键值对会被新字典中的键值对覆盖,即换掉; dic1 = {'a': 1, 'b': 2} dic2 = {'a':2,'b':5,'c': 3} dic1.update(dic2) print(dic1)print(f"dic1: {dic1}") ''' {'a': 2, 'b': 5, 'c': 3} '''
9) fromkeys
# dic之fromkeys(参数1,参数2) ''' fromkeys 可以传入两个参数,参数1可以是除了数字类型的任意数据类型,不传参数2,生成的字典的value都默认为None;指定了参数2,返回你指定的参数2(value)。 ''' l=['name', 'age', 'sex'] dic1 = dict.fromkeys(l, None) dic2 = dict.fromkeys(l, '保密') print(f"dic1: {dic1}") print(f"dic2: {dic2}") ''' dic1: {'name': None, 'age': None, 'sex': None} dic1: {'name': '保密', 'age': '保密', 'sex': '保密'} '''
10) setdefault
# setdefault() 可以给字典新增键值对 d1 = {'name':'jason','pwd':123} res1 = d1.setdefault('name','xxoo') # 当键存在的情况下 不修改值 并且将原先key对应值返回给你 res2 = d1.setdefault('age',18) # 当键不存在的情况下 新增一个键值对 并且将新增的键值对的值返回给你 print(d1,res1) print(d1,res2) ''' {'name': 'jason', 'pwd': 123} jason {'name': 'jason', 'pwd': 123, 'age': 18} 18 '''
11)clear() 、copy()
#copy() 浅拷贝 clear() 清空字典 d1 = {'name':'jason','pwd':123} print(id(d1)) d2=d1.copy() print(id(d2)) d1.clear() print(d1) ''' 31338432 31379816 {} '''
二、元组
元组是不可变的列表,即元组的值不可更改,因此元组一般只用于只存不取的需求。也因此元组可以被列表取代掉,所以元组相比较列表使用的很少。元组相比较列表的优点为:列表的值修改后,列表的结构将会发生改变,而元组只需要存储,因此列表在某种程度上而言需要占用更多的内存。
1.定义:在()内可以有多个任意类型的值,逗号分隔元素
2.用途:多个装备、多个爱好、多门课程,甚至是多个女朋友
3.元组的两种定义方式:
t1=(1,2,3,4,5) t2=tuple((1,2,3,4,5)) print('t1:',t1) print('t2:',t2) ''' t1: (1, 2, 3, 4, 5) t2: (1, 2, 3, 4, 5) '''
# 当元组中元素只有一个时,必须要加一个逗号,不然就只是一个普通元素 name_str = ('egon') # ()只是普通包含的意思 name_tuple = ('egon',) print(f"type(name_str): {type(name_str)}") print(f"type(name_tuple): {type(name_tuple)}") ''' type(name_str): <class 'str'> type(name_tuple): <class 'tuple'> '''
4.特点:
1) .存一个值or多个值:多个值
2) 有序or无序:有序
3) 可变or不可变:不可变数据类型
5.内置方法的使用
1)索引取值
2)切片(顾头不顾尾,步长)
3)长度len
4)成员运算in或者not in
5)for 循环
6) count
7) index
1)索引取值
# tuple之索引取值 name_tuple = ('nick', 'jason', 'tank', 'sean') # name_tuple[0] = 'nick handsom' # 报错 print(f"name_tuple[0]: {name_tuple[0]}") ''' name_tuple[0]: nick '''
2)切片(顾头不顾尾,步长)
# tuple之切片 name_tuple = ('nick', 'jason', 'tank', 'sean') print(f"name_tuple[1:3:2]: {name_tuple[1:3:2]}") ''' name_tuple[1:3:2]: ('jason',) '''
3)长度len
# tuple之长度 name_tuple = ('nick', 'jason', 'tank', 'sean') print(f"len(name_tuple): {len(name_tuple)}") ''' len(name_tuple): 4 '''
4)成员运算in或者not in
# tuple之成员运算 name_tuple = ('nick', 'jason', 'tank', 'sean') print(f"'nick' in name_tuple: {'nick' in name_tuple}") ''' 'nick' in name_tuple: True '''
5)for 循环
# tuple之循环 name_tuple = ('nick', 'jason', 'tank', 'sean') for name in name_tuple: print(name) ''' nick jason tank sean '''
6) count()
# tuple之count() name_tuple = ('nick', 'jason', 'tank', 'sean') print(f"name_tuple.count('nick'): {name_tuple.count('nick')}") ''' name_tuple.count('nick'): 1 '''
7) index()
# tuple之index() name_tuple = ('nick', 'jason', 'tank', 'sean') print(f"name_tuple.index('nick'): {name_tuple.index('nick')}") ''' name_tuple.index('nick'): 0 '''
三、集合
集合可以理解成一个集合体,学习Python的学生可以是一个集合体;学习Linux的学生可以是一个集合体
pythoners = ['jason', 'nick', 'tank', 'sean'] linuxers = ['nick', 'egon', 'kevin'] # 即报名pythoners又报名linux的学生 py_li_list = [] for stu in pythoners: if stu in linuxers: py_li_list.append(stu) print(f"pythoners and linuxers: {py_li_list}") ''' pythoners and linuxers: ['nick'] '''
1.用途:用于关系运算的集合体,由于集合内的元素无序且集合元素不可重复,因此集合可以去重,但是去重后的集合会打乱原来元素的顺序
2.定义:{}内用逗号分隔开多个元素,每个元素必须是不可变类型。

3.集合的元素遵循三个原则:
1) 每个元素必须是不可变类型
2) 没有重复的元素
3) 无序
4.特点:
1)存一个值or多个值:多个值,且值为不可变类型;
2)有序or无序:无序
3)可变or不可变:可变数据类型
5.常用操作+内置方法
1)长度len
2)成员运算in 或者 not in
3)|并集、union
4)&交集、intersection
5)-差集、difference
6)^对称差集、symmetric_difference
7)父集:>、>= 、issuperset
8)子集:<、<= 、issubset
9) add
10) pop、remove、discard、clear
11)update
12)copy 浅拷贝
1)长度len
# set之长度len s = {1, 2, 'a'} print(f"len(s): {len(s)}") ''' len(s): 3 '''
2)成员运算in 或者 not in
# set之成员运算in和not in s = {1, 2, 'a'} print(f"1 in s: {1 in s}") ''' 1 in s: True '''
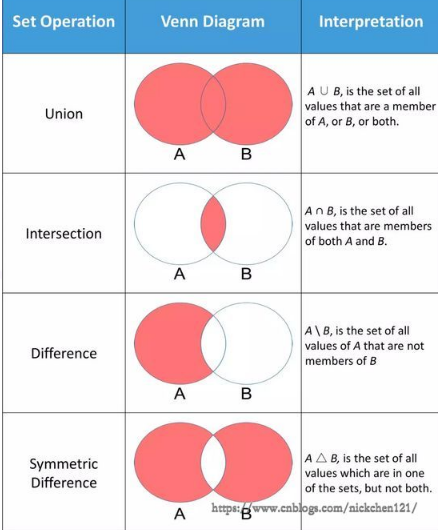
3)|并集、union
# str之|并集 pythoners = {'jason', 'nick', 'tank', 'sean'} linuxers = {'nick', 'egon', 'kevin'} print(f"pythoners|linuxers: {pythoners|linuxers}") print(f"pythoners.union(linuxers): {pythoners.union(linuxers)}") ''' pythoners|linuxers: {'egon', 'tank', 'kevin', 'jason', 'nick', 'sean'} pythoners.union(linuxers): {'egon', 'tank', 'kevin', 'jason', 'nick', 'sean'} '''
4)&交集、intersection
# str之&交集 pythoners = {'jason', 'nick', 'tank', 'sean'} linuxers = {'nick', 'egon', 'kevin'} print(f"pythoners&linuxers: {pythoners&linuxers}") print(f"pythoners.intersection(linuxers): {pythoners.intersection(linuxers)}") ''' pythoners&linuxers: {'nick'} pythoners.intersection(linuxers): {'nick'} '''
5)-差集、difference
# str之-差集 pythoners = {'jason', 'nick', 'tank', 'sean'} linuxers = {'nick', 'egon', 'kevin'} print(f"pythoners-linuxers: {pythoners-linuxers}") print(f"pythoners.difference(linuxers): {pythoners.difference(linuxers)}") ''' pythoners-linuxers: {'tank', 'jason', 'sean'} pythoners.difference(linuxers): {'tank', 'jason', 'sean'} '''
6)^对称差集、symmetric_difference
# str之^对称差集 pythoners = {'jason', 'nick', 'tank', 'sean'} linuxers = {'nick', 'egon', 'kevin'} print(f"pythoners^linuxers: {pythoners^linuxers}") print( f"pythoners.symmetric_difference(linuxers): {pythoners.symmetric_difference(linuxers)}") ''' pythoners^linuxers: {'egon', 'tank', 'kevin', 'jason', 'sean'} pythoners.symmetric_difference(linuxers): {'egon', 'tank', 'kevin', 'jason', 'sean'} '''
7) 父集:>、>= 、issuperset
# str之父集:>、>= pythoners = {'jason', 'nick', 'tank', 'sean'} linuxers = {'nick', 'egon', 'kevin'} javaers = {'jason', 'nick'} print(f"pythoners>linuxers: {pythoners>linuxers}") print(f"pythoners>=linuxers: {pythoners>=linuxers}") print(f"pythoners>=javaers: {pythoners>=javaers}") print(f"pythoners.issuperset(javaers): {pythoners.issuperset(javaers)}") ''' pythoners>linuxers: False pythoners>=linuxers: False pythoners>=javaers: True pythoners.issuperset(javaers): True '''
8)子集:<、<= 、issubset
pythoners = {'jason', 'nick', 'tank', 'sean'}
linuxers = {'nick', 'egon', 'kevin'}
javaers = {'jason', 'nick'}
print(f"pythoners<linuxers: {pythoners<linuxers}")
print(f"pythoners<=linuxers: {pythoners<=linuxers}")
print(f"javaers.issubset(pythoners): {javaers.issubset(pythoners)}")
'''
pythoners<linuxers: False
pythoners<=linuxers: False
javaers.issubset(pythoners): True
'''
9) add()
# set之add() s = {1, 2, 'a'} s.add(3) print(s) ''' {1, 2, 3, 'a'} '''
10) pop、remove、discard、clear
s1={1,2,'a'}
s1.pop() # 随机删除一个元素
s1.remove(1) # 指定要删除的元素
s1.remove('b') # 删除不存在的元素,报错
s1.discard('a') # 指定要删除的元素
s1.discard('b') # 删除没有的元素,不报错,仍然返回原集合
s1.clear() # 清空集合,返回空集合 set()
print(s1)
11)update
s1={1,2,'a'}
s2={4,'a'}
s1.update(s2)
print(s1)
'''
{1, 2, 'a', 4}
'''
12)copy
s1={1,2,'a'}
print(s1,id(s1))
s2=s1.copy()
print(s2,id(s2))
'''
s1: {1, 2, 'a'} 167312520
s2: {1, 2, 'a'} 167311400
'''