1.介绍
TensorFlow™ 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。TensorFlow 最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其他计算领域。它是谷歌基于DistBelief进行研发的第二代人工智能学习系统。2015年11月9日,Google发布人工智能系统TensorFlow并宣布开源。
2.tensorflow名字来源
其命名来源于本身的原理,Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算。Tensorflow运行过程就是张量从图的一端流动到另一端的计算过程。张量从图中流过的直观图像是这个工具取名为“TensorFlow”的原因。
3.什么是数据流图
数据流图用“节点”(nodes)和“线”(edges)的有向图来描述数学计算。“节点”一般用来表示施加的数学操作,但也可以表示数据输入(feed in)的起点/输出(push out)的终点,或者是读取/写入持久变量(persistent variable)的终点。“线”表示“节点”之间的输入/输出关系。这些数据“线”可以运输“size可动态调整”的多维数组,即“张量”(tensor)。一旦输入端所有张量准备好,节点将被分配到各种计算设备完成异步并行地执行计算。
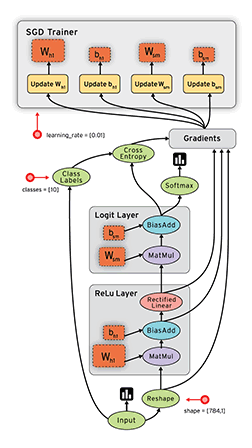
4.tensorflow的特性
高度的灵活性: TensorFlow不是一个严格的“神经网络”库。只要你可以将你的计算表示为一个数据流图,你就可以使用TensorFlow。
可移植性(Portability):Tensorflow可以运行在台式机、服务器、手机移动等等设备上。而且它可以充分使用计算资源,在多CPU和多GPU上运行。
多语言支持:Tensorflow提供了一套易用的Python使用接口来构建和执行graphs,也同样提供了一套易于C++使用的接口(目前训练神经网络只支持python,C++接口只能使用已经训练好的模型)。未来还会支持Go、Java、Lua、Javascript、R等等。
性能最优化:TensorFlow给予了线程、队列、异步操作等最佳的支持,TensorFlow可以把你手边硬件的计算潜能全部发挥出来,它可以充分利用多CPU和多GPU。
5.下载及安装
既可以直接使用二进制程序包也可以从github源码库克隆源码编译安装。
要求
TensorFlow 提供的Python API支持Python2.7和Python3.3+
GPU版本的二进制程序包只能使用Cuda Toolkit8.0 和 cuDNN v5。如果你使用的是其他版本(Cuda toolkit >= 7.0 and cuDNN >= v3),那你就必须使用源码重新编译安装。
推荐几种Linux平台的安装方式:
Pip install: 可能会升级你之前安装过的Python包,对你机器上的Python程序造成影响。
Anaconda install:把TensorFlow安装在Anaconda提供的环境中,不会影响其他Python程序。
Installing from sources:把TensorFlow源码构建成一个pip wheel 文件,使用pip工具安装它。
Pip installation
Pip是一个用来安装和管理Python软件包的包管理系统。
安装pip(如果已经安装,可以跳过)
# Ubuntu/Linux 64-bit
$ sudo apt-get install python-pip python-dev
直接使用pip安装TensorFlow
$ pip install tensorflow
如果提示找不到对应的包,使用
pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.12.0rc1-cp27-none-linux_x86_64.whl
安装GPU支持的版本:
# Requires CUDA toolkit 8.0 and CuDNN v5. 其他版本,参考下面的 “Installing from sources”
$ pip install tensorflow-gpu
如果提示找不到对应的包,使用
pip install --ignore-installed --upgrade TF_BINARY_URL=https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-0.12.0rc1-cp27-none-linux_x86_64.whl
注意:如果是从一个较老的版本(TensorFlow<0.7.1)进行升级,需要首先卸载之前的TensorFlow和protobuf使用:pip uninstall
Anaconda installation
Anaconda是一个Python发行版,包括大量的数字和科学计算包。使用“conda”来管理软件包,并且拥有自己的环境系统。安装步骤
安装Anaconda
创建conda环境
激活conda环境,在其中安装TensorFlow
每次使用TensorFlow时,激活conda环境
Anaconda具体的安装和使用可以参考:https://www.continuum.io/downloads
Installing from sources
从源码构建TensorFlow,具体的步骤参考:http://blog.csdn.net/toormi/article/details/52904551#t8
6.基本使用
基本概念
使用TensorFlow前必须明白的基本概念:
图(Graph):图描述了计算的过程,TensorFlow使用图来表示计算任务。
张量(Tensor):TensorFlow使用tensor表示数据。每个Tensor是一个类型化的多维数组。
操作(op):图中的节点被称为op(operation的缩写),一个op获得0个或多个Tensor,执行计算,产生0个或多个Tensor。
会话(Session):图必须在称之为“会话”的上下文中执行。会话将图的op分发到诸如CPU或GPU之类的设备上执行。
变量(Variable):运行过程中可以被改变,用于维护状态。
计算图
Tensorflow程序通常被组织成一个构建阶段和一个执行阶段。在构建阶段,op的执行步骤被描述成一个图。在执行阶段,使用会话执行图中的op。
构建图
构建图的第一步是创建源op(sources op)。源op不需要任何输入,例如常量(Constant)。源op的输出被传递给其他op做运算。
在TensorFlow的Python库中,op构造器的返回值代表这个op的输出。这些返回值可以作为输入传递给其他op构造器。
TensorFlow的Python库中包含了一个默认的graph,可以在上面使用添加节点。如果你的程序需要多个graph那就需要使用Graph类管理多个graph。
import tensorflow as tf
# 创建一个常量 op, 产生一个 1x2 矩阵. 这个 op 被作为一个节点
# 加到默认图中.
#
# 构造器的返回值代表该常量 op 的返回值.
matrix1 = tf.constant([[3., 3.]])
# 创建另外一个常量 op, 产生一个 2x1 矩阵.
matrix2 = tf.constant([[2.],[2.]])
# 创建一个矩阵乘法 matmul op , 把 'matrix1' 和 'matrix2' 作为输入.
# 返回值 'product' 代表矩阵乘法的结果.
product = tf.matmul(matrix1, matrix2)
默认图中包含了3个节点:两个constant() op和一个matmul() op。为了真正的执行矩阵相乘运算,并得到矩阵乘法的结果,你必须在会话中启动这个图。
启动图
构造阶段完成后,才能在会话中启动图。启动图的第一步是创建一个Session对象。如果没有任何参数,会话构造器将启动默认图。
# 启动默认图.
sess = tf.Session()
# 调用 sess 的 'run()' 方法来执行矩阵乘法 op, 传入 'product' 作为该方法的参数.
# 上面提到, 'product' 代表了矩阵乘法 op 的输出, 传入它是向方法表明, 我们希望取回
# 矩阵乘法 op 的输出.
#
# 整个执行过程是自动化的, 会话负责传递 op 所需的全部输入. op 通常是并发执行的.
#
# 函数调用 'run(product)' 触发了图中三个 op (两个常量 op 和一个矩阵乘法 op) 的执行.
#
# 返回值 'result' 是一个 numpy `ndarray` 对象.
result = sess.run(product)
print result
# ==> [[ 12.]]
# 任务完成, 关闭会话.
sess.close()
Tensorflow的实现上,会把图转换成可分布式执行的操作,以充分利用计算资源(例如CPU或GPU)。通常情况下,你不需要显示指使用CPU或者GPU。TensorFlow能自动检测,如果检测到GPU,TensorFlow会使用第一个GPU来执行操作。
如果机器上有多个GPU,除第一个GPU外的其他GPU是不参与计算的,为了使用这些GPU,你必须将op明确指派给他们执行。with…Device语句用来指派特定的CPU或GPU执行操作:
with tf.Session() as sess:
with tf.device("/gpu:1"):
matrix1 = tf.constant([[3., 3.]])
matrix2 = tf.constant([[2.],[2.]])
product = tf.matmul(matrix1, matrix2)
设备用字符串进行标识. 目前支持的设备包括:
“/cpu:0”: 机器的 CPU.
“/gpu:0”: 机器的第一个 GPU, 如果有的话.
“/gpu:1”: 机器的第二个 GPU, 以此类推.
tensor
Tensorflow使用tensor数据结构来代表所有的数据。计算图的操作之间仅能传递tensor。你可以把tensor当作多维数组或列表。每一个tensor包含有一个静态类型,一个rank和一个shape。想了解更多TensorFlow是如何操作这些概念的,参考Rank, Shape, and Type
变量
变量维持图计算过程中的状态信息。下面的例子演示了如何使用变量作为一个简单的计数器。
# Create a Variable, that will be initialized to the scalar value 0.
state = tf.Variable(0, name="counter")
# Create an Op to add one to `state`.
one = tf.constant(1)
new_value = tf.add(state, one)
update = tf.assign(state, new_value)
# Variables must be initialized by running an `init` Op after having
# launched the graph. We first have to add the `init` Op to the graph.
init_op = tf.global_variables_initializer()
# Launch the graph and run the ops.
with tf.Session() as sess:
# Run the 'init' op
sess.run(init_op)
# Print the initial value of 'state'
print(sess.run(state))
# Run the op that updates 'state' and print 'state'.
for _ in range(3):
sess.run(update)
print(sess.run(state))
通常可以将一个统计模型中的参数表示为一组变量。例如,你可以将一个神经网络的权重当作一个tensor存储在变量中。在训练图的重复运行过程中去更新这个tensor。
Fetch
为了取回操作的输出内容,在使用Session对象的run()方法执行图时,传入一些tensor,这些tensor会帮你取回结果。之前的例子中,我们只取回了state节点,但是你也可以取回多个tensor:
input1 = tf.constant(3.0)
input2 = tf.constant(2.0)
input3 = tf.constant(5.0)
intermed = tf.add(input2, input3)
mul = tf.mul(input1, intermed)
with tf.Session() as sess:
result = sess.run([mul, intermed])
print result
# 输出:
# [array([ 21.], dtype=float32), array([ 7.], dtype=float32)]
需要获取的多个 tensor 值,在 op 的一次运行中一起获得(而不是逐个去获取 tensor)。
Feed
上面的例子中展示了在计算图中引入tensor,以常量和变量的形式存储。TensorFlow还提供了feed机制,该机制可以临时替换图中的tensor。
feed使用一个tensor值临时替换一个操作的输出。可以把feed数据作为参数提供给run()方法。标记的方法是使用tf.placeholder()为这些操作创建占位符。
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
output = tf.mul(input1, input2)
with tf.Session() as sess:
print sess.run([output], feed_dict={input1:[7.], input2:[2.]})
# 输出:
# [array([ 14.], dtype=float32)]