案例要爬取的网站是:http://www.quanshuwang.com/book/44/44683
步骤:
1、获取小说主页源代码
2、在主页源代码中找到每个章节的超链接
3、获取每个章节超链接的源代码
4、获取章节的内容
5、保存内容到本地
首先导入模板
import re import urllib.request
然后定义一个函数,专门用来爬取网站小说的
import re import urllib.request #定义一个爬取网络小说的函数 def get_novel(): html = urllib.request.urlopen("http://www.quanshuwang.com/book/44/44683").read()
最后一行我们调用了urllib库的方法,urlopen方法中我们传进一个网址作为参数表示我们需要爬取的网站,.read()方法表示获取源代码。那我们现在打印html是否能成功在控制台把页面的代码给输出了呢?答案是否定的,现在获取的源码是一个乱码,我们还需要对该代码进行转码,于是要在下面加多一行转码的。
import re import urllib.request #定义一个爬取网络小说的函数 def get_novel(): html = urllib.request.urlopen("http://www.quanshuwang.com/book/44/44683").read() html = html.decode("gbk") #转成该网址的格式
由上面我们可知代码已经转成了‘gbk’格式,并且也已经将它存在html这个变量上了,那我们怎么知道转成什么格式呢?
前面我说过我要爬取的网站是:http://www.quanshuwang.com/book/44/44683
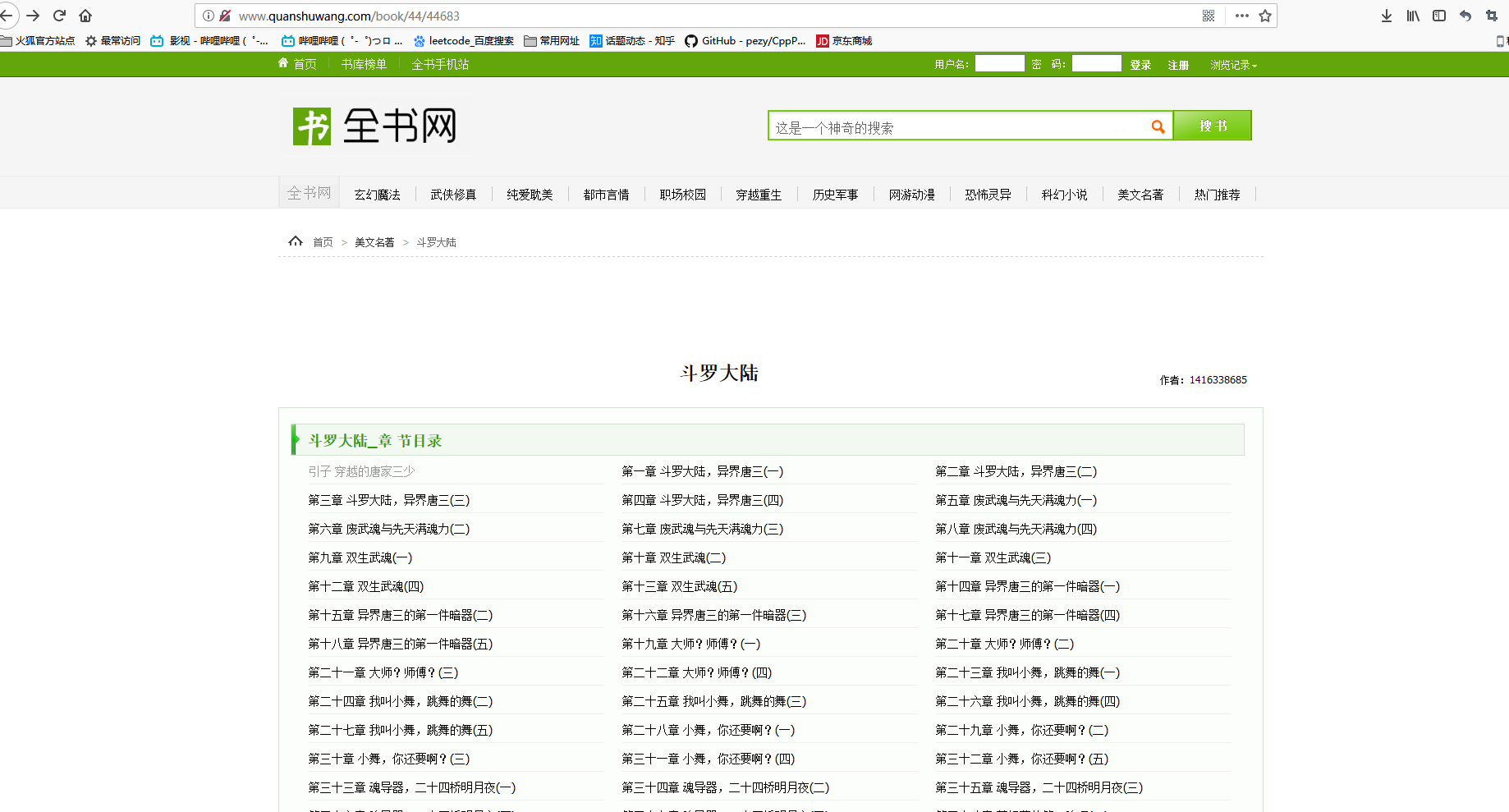
我建议小伙伴们在获取该网页源代码的时候先在浏览器中查看分析一下该网页源代码的大概结构,分析清楚了好方便后面代码的编写。查看页面源代码有两种方式,1:按住F12。2:鼠标指向页面空白处点击右键,选择“查看页面源代码”。
我们先用第二种方法打开源代码找到<meta>标签便可知道该网站的格式了

接下来我另一种方式打开源代码,按F12
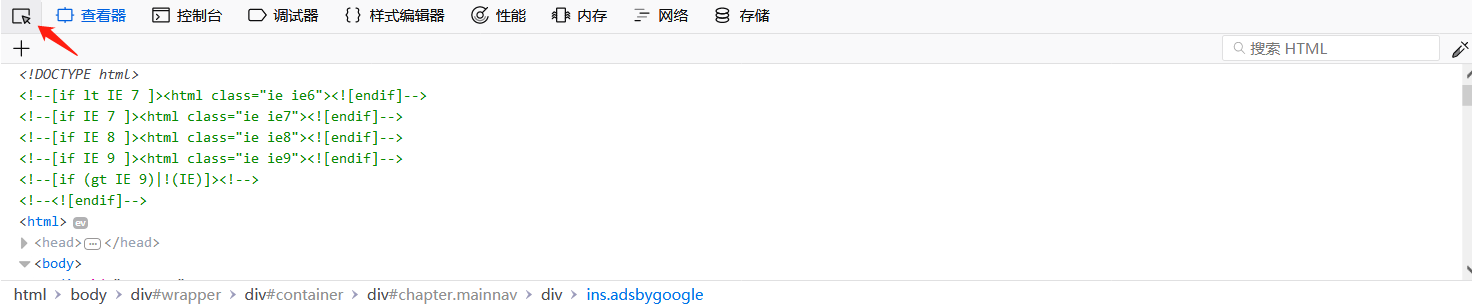
鼠标点击左上角的箭头,再把鼠标指向网页中的任何一部分内容,查看器马上就能定位到该内容的源代码位置。
因为我们要获取整本小说,所以让我们先获取章节目录吧,把鼠标指向其中一章并选中,下面就自动定位到该章节标签位置了
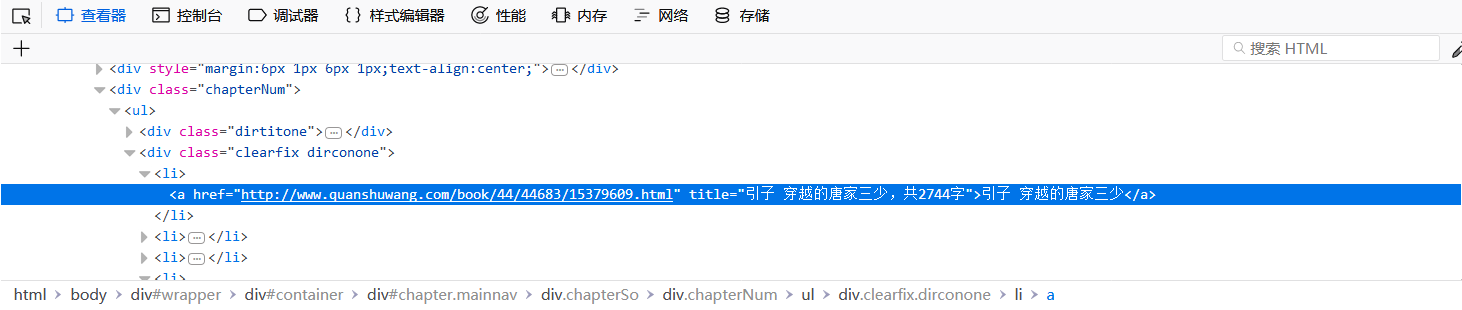
我们对这行右击鼠标->编辑HTML,然后把这一行都复制下来
回到编辑器这边把刚才的代码粘贴过来并打上注释,作为一个参考的模板
def get_novel(): html = urllib.request.urlopen("http://www.quanshuwang.com/book/44/44683").read() html = html.decode("gbk") #转成该网址的格式 #<li><a href="http://www.quanshuwang.com/book/44/44683/15379609.html" title="引子 穿越的唐家三少,共2744字">引子 穿越的唐家三少</a></li> #参考
因为我们需要抓取的是全部章节而不仅仅只是这一个章节,所以我们要用到正则表达式来进行匹配,先把通用的部分用(.*?)替代,(.*?)可以匹配所有东西
#定义一个爬取网络小说的函数 def get_novel(): html = urllib.request.urlopen("http://www.quanshuwang.com/book/44/44683").read() html = html.decode("gbk") #转成该网址的格式 #<li><a href="http://www.quanshuwang.com/book/44/44683/15379609.html" title="引子 穿越的唐家三少,共2744字">引子 穿越的唐家三少</a></li> #参考 reg = r'<li><a href="(.*?)" title=".*?">(.*?)</a></li>' #正则表达的匹配 reg = re.compile(reg) #可添加可不添加,增加效率 urls = re.findall(reg,html)
print(urls)
get_novel()
仔细的小伙伴就发现有些地方的.*?加括号,有些地方又不加,这是因为加了括号的都是我们要匹配的,不加括号是我们不需要匹配的。接下来一行调用re.compiled()方法是增加匹配的效率,建议习惯加上,最后一行开始与我们一开始获取的整个网页的源代码进行匹配。到这步我们已经能把代码所有章节以及章节链接的代码都获取了,打印在控制台上看一下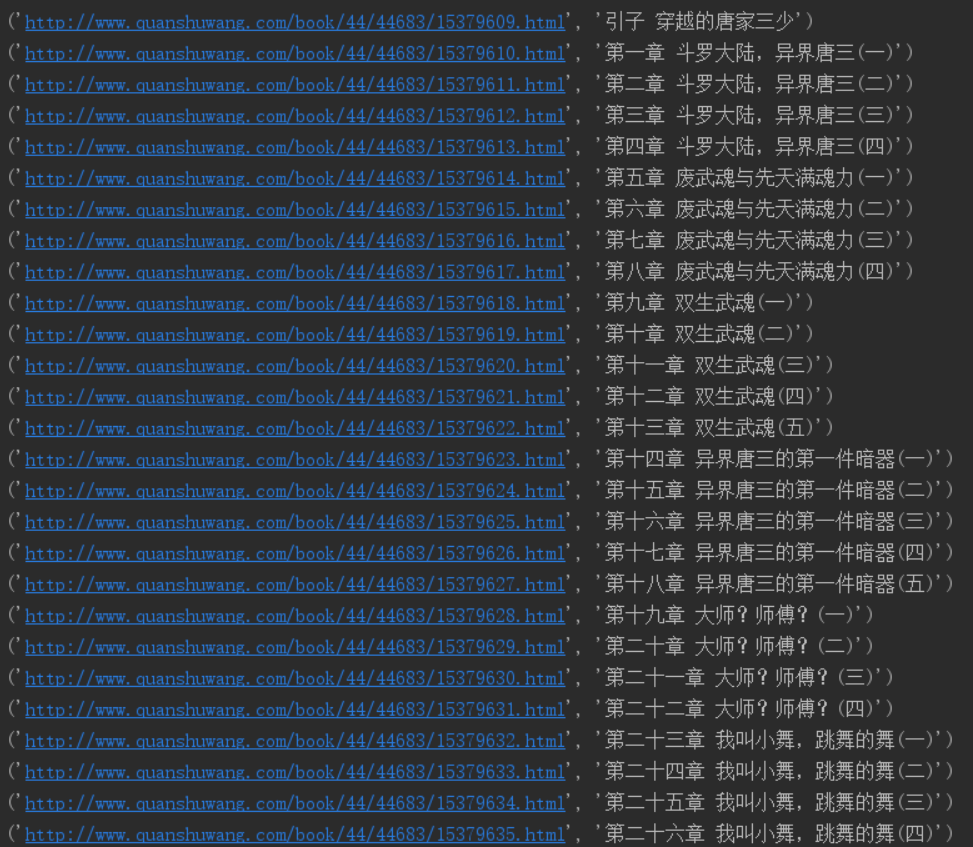
从结果我们可以知道对于每个循环出来的结果为一个元祖,有两个索引,0和1,0为章节的超链接,1为章节的名字。
既然我们获取到了每个章节的超链接那我们是不是就可以像上面的操作步骤一样获取这个链接里面的内容啦?答案是肯定的。
于是我们继续写以下的代码获取每个章节的代码(跟上面获取主页代码的步骤类似)
#定义一个爬取网络小说的函数 def getNovelContent(): html = urllib.request.urlopen("http://www.quanshuwang.com/book/44/44683").read() html = html.decode("gbk") #转成该网址的格式 #<li><a href="http://www.quanshuwang.com/book/44/44683/15379609.html" title="引子 穿越的唐家三少,共2744字">引子 穿越的唐家三少</a></li> #参考 reg = r'<li><a href="(.*?)" title=".*?">(.*?)</a></li>' #正则表达的匹配 reg = re.compile(reg) #可添加可不添加,增加效率 urls = re.findall(reg,html) # print(urls) for url in urls: #print(url) chapter_url = url[0] #章节的超链接 chapter_title = url[1] #章节的名字 print(chapter_title) chapter_html = urllib.request.urlopen(chapter_url).read() #正文内容源代码 chapter_html = chapter_html.decode("gbk")
get_novel()
至此我们已经可以得到每个章节的内容了,但是还有一个问题,就是我们只想获取正文内容,正文以外的东西我们统统不要。
所以我们可以在网页中打开其中一章并查看源代码,例如我打开的是第一章,查找正文的内容在哪个标签中。
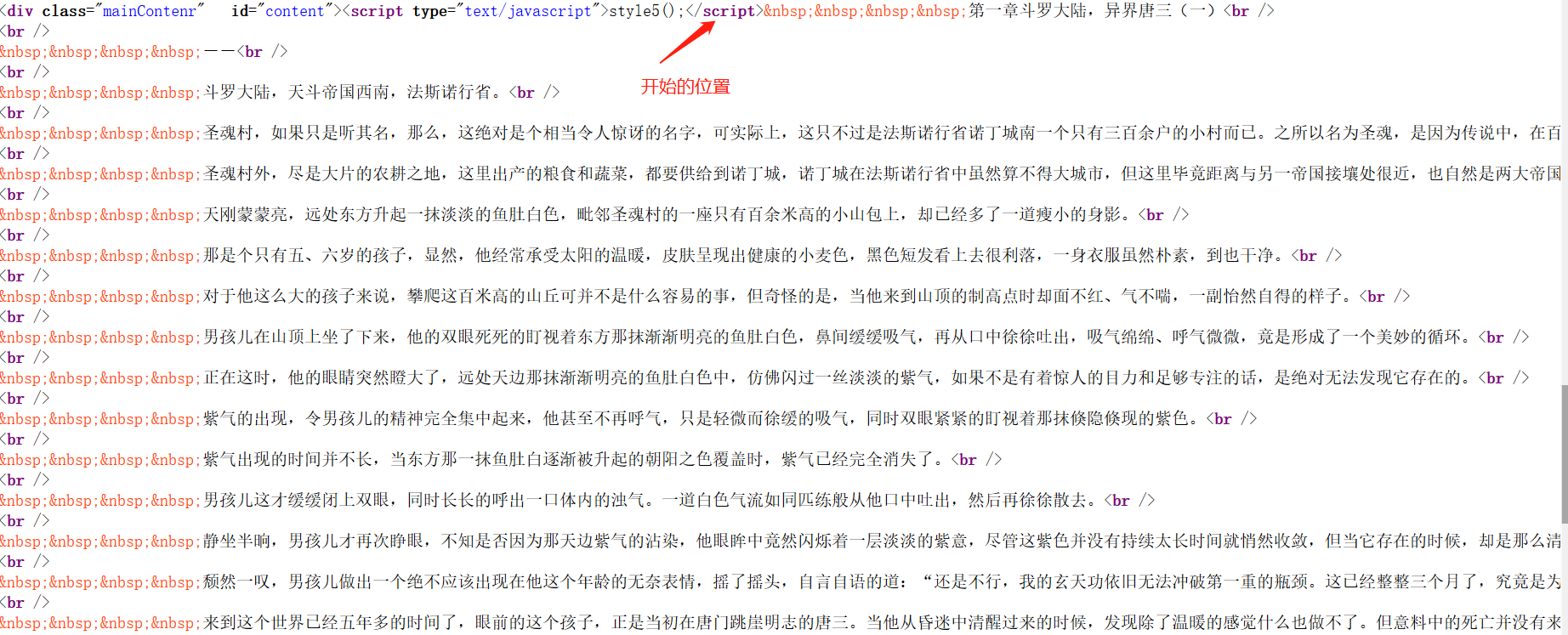
上面两张图标识了我找到的正文内容开始与结束标签的位置,标签为<script>
于是我们在代码中又可以通过正则表达式来匹配内容了
#定义一个爬取网络小说的函数 def get_novel(): html = urllib.request.urlopen("http://www.quanshuwang.com/book/44/44683").read() html = html.decode("gbk") #转成该网址的格式 #<li><a href="http://www.quanshuwang.com/book/44/44683/15379609.html" title="引子 穿越的唐家三少,共2744字">引子 穿越的唐家三少</a></li> #参考 reg = r'<li><a href="(.*?)" title=".*?">(.*?)</a></li>' #正则表达的匹配 reg = re.compile(reg) #可添加可不添加,增加效率 urls = re.findall(reg,html) # print(urls) for url in urls: chapter_url = url[0] #章节的超链接 chapter_title = url[1] #章节的名字 print(chapter_title) chapter_html = urllib.request.urlopen(chapter_url).read() #正文内容源代码 chapter_html = chapter_html.decode("gbk") chapter_reg = r'</script> .*?<br />(.*?)<script type="text/javascript">' chapter_reg = re.compile(chapter_reg,re.S) chapter_content = re.findall(chapter_reg,chapter_html)
到这里我们已经完成了小说的全部爬取,在控制台打印一下吧
#定义一个爬取网络小说的函数 def get_novel(): html = urllib.request.urlopen("http://www.quanshuwang.com/book/44/44683").read() html = html.decode("gbk") #转成该网址的格式 #<li><a href="http://www.quanshuwang.com/book/44/44683/15379609.html" title="引子 穿越的唐家三少,共2744字">引子 穿越的唐家三少</a></li> #参考 reg = r'<li><a href="(.*?)" title=".*?">(.*?)</a></li>' #正则表达的匹配 reg = re.compile(reg) #可添加可不添加,增加效率 urls = re.findall(reg,html) # print(urls) for url in urls: chapter_url = url[0] #章节的超链接 chapter_title = url[1] #章节的名字 print(chapter_title) chapter_html = urllib.request.urlopen(chapter_url).read() #正文内容源代码 chapter_html = chapter_html.decode("gbk") chapter_reg = r'</script> .*?<br />(.*?)<script type="text/javascript">' chapter_reg = re.compile(chapter_reg,re.S) chapter_content = re.findall(chapter_reg,chapter_html) for content in chapter_content: #打印章节的内容 content = content.replace("  ","") #把" "字符全都替换为"" content = content.replace("<br />","") #把"<br/>"字符全部替换为"" print(content) #打印内容
get_novel()

终于来到最后一步了,我们将爬取的内容保存。保存有两种,一种是保存到本地,另一种是保存到数据库中,本次案例我们保存到本地就行了。
import re import urllib.request import os def get_novle(): html = urllib.request.urlopen('http://www.quanshuwang.com/book/44/44683').read() # html = urllib.request.urlopen('http://www.xbiquge.la/7/7931/').read() html = html.decode('gbk') # <li><a href="http://www.quanshuwang.com/book/44/44683/15379610.html" title="第一章 斗罗大陆,异界唐三(一),共2112字">第一章 斗罗大陆,异界唐三(一)</a></li> reg = r'<li><a href="(.*?)" title=".*?">(.*?)</a></li>' reg = re.compile(reg) urls = re.findall(reg, html) # print(urls) for url in urls: # print(url) chapter_url = url[0] # print(chapter_url) chapter_title = url[1] # print(chapter_title) chapter_html = urllib.request.urlopen(chapter_url).read() chapter_html = chapter_html.decode('gbk') chapter_reg = r'</script> .*?<br />(.*?)<script type="text/javascript">' chapter_reg = re.compile(chapter_reg, re.S) chapter_content = re.findall(chapter_reg, chapter_html) # print(chapter_content) for content in chapter_content: content = content.replace(' ', '') content = content.replace('<br />', '') # print(content) base_path = '斗罗大陆' novel_path = os.path.join(base_path, chapter_title) with open(novel_path, 'w') as f: f.write(content) print('%s下载成功' % chapter_title) get_novle()
倒数第二行是我们保存文本的代码,open第一个参数需要指定保存文本格式,第二个'w'意思是文件的模式为读写模式。更多文本处理操作可百度“python文本处理操作”,最后一行代码为把章节的内容都写进对应的每个章节中。
