感谢知乎大佬刘岩https://zhuanlan.zhihu.com/p/48508221,我的总结将主要来自于大佬文章。
英文版博客:http://jalammar.github.io/illustrated-transformer/
论文:《Attention is all you need》
为什么要使用attention,这也是本文中所以解决的问题:
1.时间片 t 的计算依赖于 t-1 时刻的计算结果,这样限制了模型的并行能力;
2.虽然LSTM在一定程度上可以缓解了长期的依赖问题,但是对于特别长期的依赖现象LSTM任然是无能为力,也可以说在encoder和decoder之间的语义向量content无法保存太过多的信息。
Transformer的提出解决了上面两个问题,首先它使用了Attention机制,将序列中的任意两个位置之间的距离是缩小为一个常量;其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。
在论文中,Transformer抛弃了传统的CNN和RNN,整个网络使用了Attention机制组成。 更准确的讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。实验中的编码器和解码器各由六层transform堆叠而成(解码器与编码器稍有不同),并在实验中取得了BLEU值的新高。
1.Transform详解
我们先看看总体的结构(我们以论文中的机器翻译为例)

Transformer由Encoder-Decoder组成
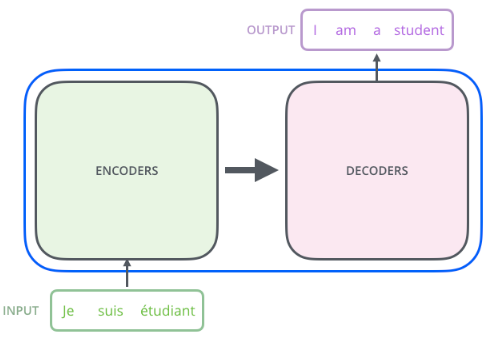
编码器和解码器都是由六个块组成,编码器的输出作为解码器的输入

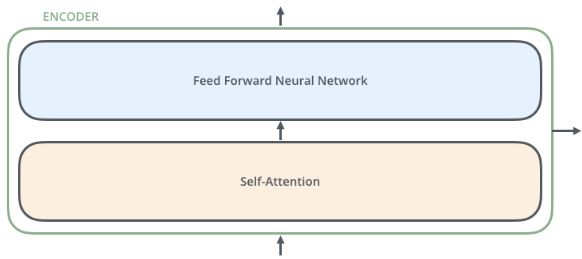
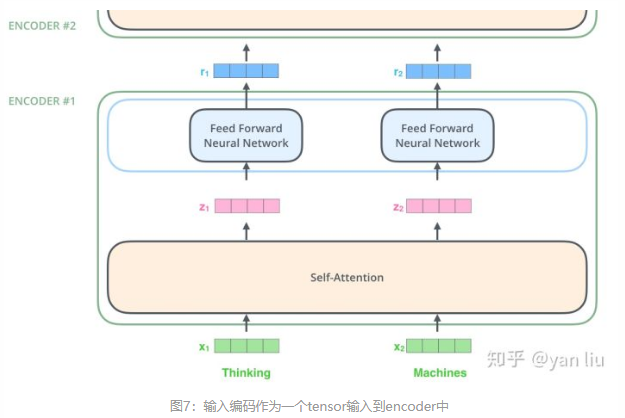
在每个encoder中有self-attention和前馈神经网络组成,数据先会经过self-attention模块,得到一个加权之后的特征向量Z,这个Z就是Attention(Q,K,V):

得到的Z之后,他会被encoder送到前馈神经网络。其中这个前馈神经网络有两层,第一层激活函数为Relu,第二层是一个线性激活函数,表示为:
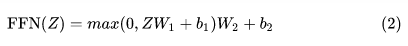
Encoder的结构如下:
Decoder的结构如下图5所示,与encoder的不同之处在于多了个Encoder-decoder Attention,两个attention分别用于计算输入和输出的权值:
-
Self-Attention:当前翻译和已经翻译的前文之间的关系;
-
Encoder-Decnoder Attention:当前翻译和编码的特征向量之间的关系。
Decoder结构如下:

1.2输入编码
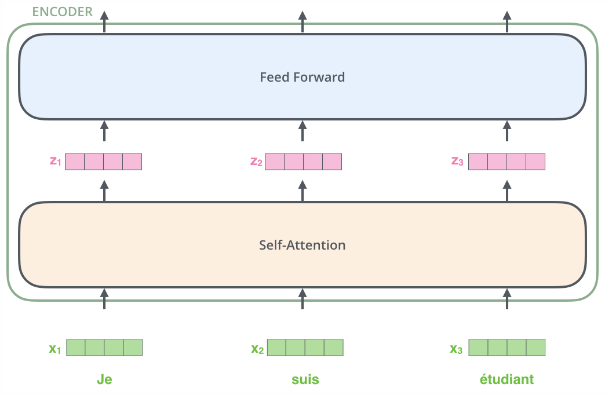
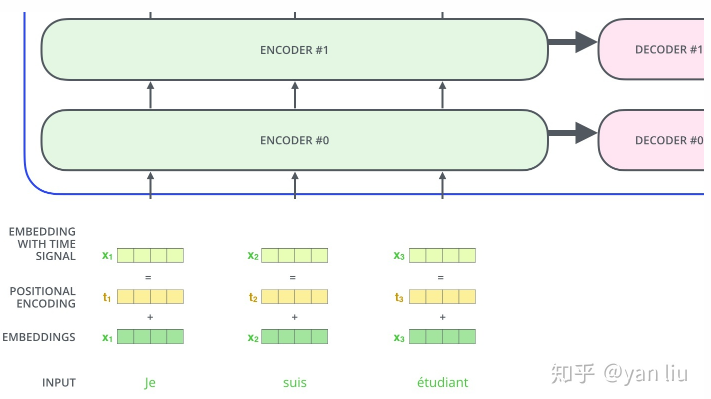
上面讲解的是主要的网络框架,现在我们介绍他的数据输入。如下图,一般的我们使用嵌入算法把每个输入字转化成向量。

嵌入只是发生在最下面一层的block中。所有的block词嵌入的维度是dmodel = 512,但是在其他层的block(有六个,说其他5个),输入直接是上个block的输出。
我们嵌入单词到输入序列,每个单词都会‘流经’每个编码器的两层。
Transform的关键属性,每个位置的单词在编码器中只经过自己的路径。self-attention中这些路径存在依赖。但是前馈层没有这些依赖,因此各种路径在流过前馈层时并行执行。
1.21 编码过程
简单过程:一个向量序列作为encoder的输入,将这些向量传到 self-attention 来处理,在进入FFNN, 然后再将输出向上传到下一个Encoder。
1.3 Self-Attention
self-attention 是Transform最核心的内容,下面就做出详细讲解。Attention其核心内容也就是:输入向量的每一个单词学习一个权重。例如:
The animal didn't cross the street because it was too tired
加权后我们可以得到类似于下面的加权情况:

当我们在编码器#5(堆栈中的顶部编码器)中对“it”进行编码时,注
意力机制的一部分集中在“animal”上,并将其表示形式的一部分融入到“it”的编码中
1.31 self-attention细节
在self-attention中,每个单词都是有3个不同的向量,它们分别是Query向量( ),Key向量(
)和Value向量(
),维度均是64。这三个不同的矩阵是由嵌入向量 X(512维)乘以三个不同的权值矩阵Wq,Wk,Wv(三矩阵尺寸相同,都是512 x 64)得到。
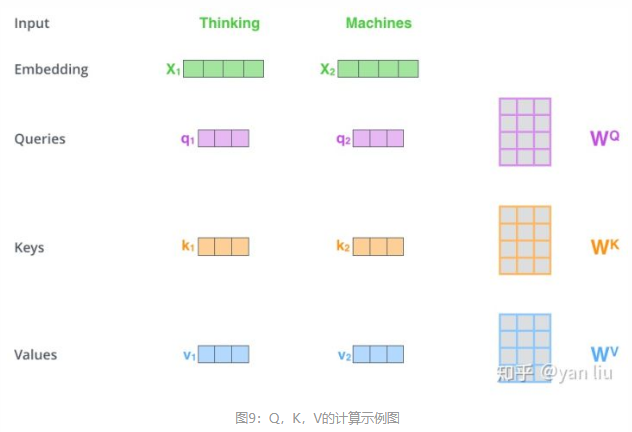
即:x1乘以WQ权重矩阵得到q1,即与该单词相关的“query”向量。我们最终为
输入语 句中的每个单词创建一个“query”、一个“key”和一个“value”投影。
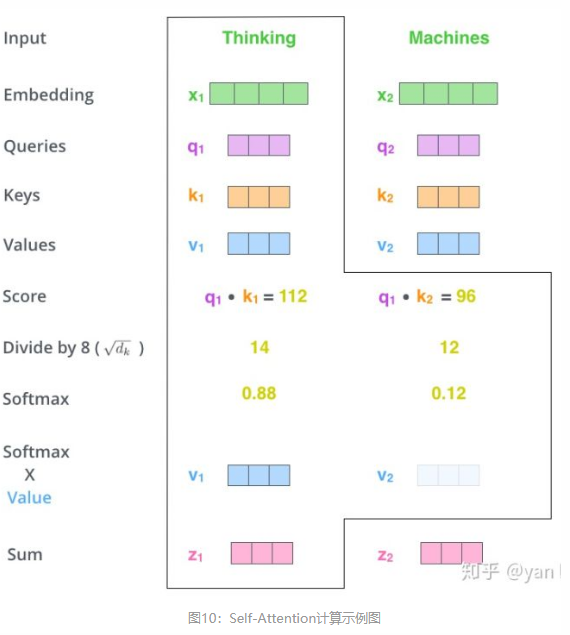
什么是Query,Key,Value呢?在Attention中扮演着什么角色呢?我们再看下Attention的计算方法,整个过程可以分为7步:
1.将单词转化为嵌入向量(Embedding)
2.根据嵌入向量得到三个输入向量 q,k,v
3.为每个向量计算一个score: (这点在论文也是有体现:如:(1x64) X (64x1)结果为一个数)
4.为了梯度的稳定,Transformer使用了score归一化,即除以 ;
5.对score施以softmax激活函数;
6.softmax点乘Value值 ,得到加权的每个输入向量的评分
;(2-6就是再讲Scaled Dot-Product Attention)
7.相加之后得到最终的输出结果 :
。
上面的步骤表示为下图所示:
实际上计算过程都是基于矩阵来计算的,那么论文中的Q,K,V计算如下所示:
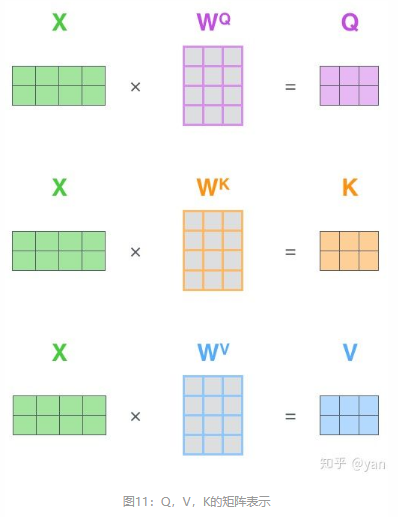
图10总结为图12所示的矩阵形式:

1.32残差
在self-attention需要强调的最后一点是其采用了残差网络 [5]中的short-cut结构,目的当然是解决深度学习中的退化问题,得到的最终结果如图13。
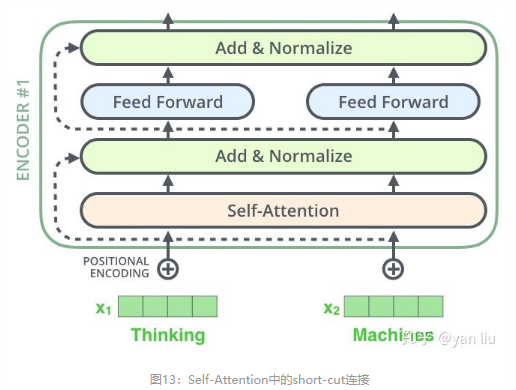
如果我们把向量和self-attention的相关图层可视化如下图:
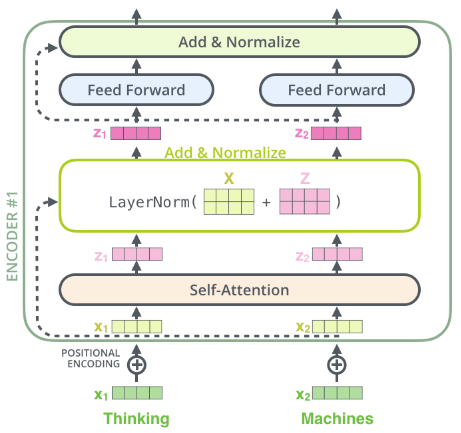
这也是适用于Encoder的子层,Transformer是由两个堆叠的encoder和decoder组成,可视化结果如下图:
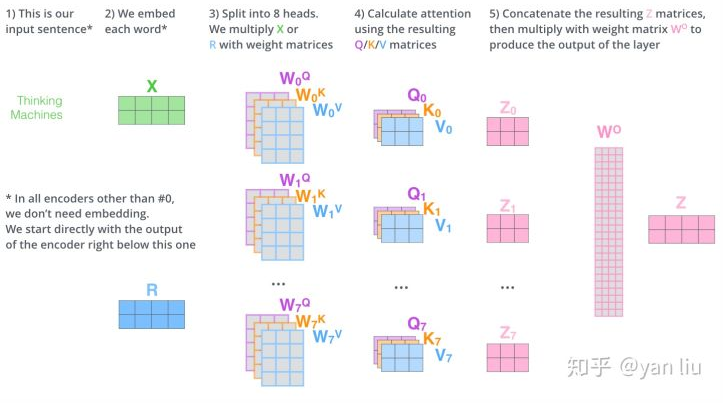
1.4 Multi-Head Attention
Multi-Head Attention相当于 个不同的self-attention的集成(ensemble),在这里我们以
举例说明。Multi-Head Attention的输出分成3步:
1.将数据 X 分别输入到图13所示的8个self-attention中,得到8个加权后的特征矩阵
2.将8个 按列拼成一个大的特征矩阵
3.特征矩阵经过一层全连接后得到输出 Z。(因为得到的是几个矩阵Zi,经过FFNN变成Z,其中Wo指的是FFNN中的权重)
整个过程如下:
同self-attention一样,multi-head attention也加入了short-cut机制。
1.5 encoder-decoder Attention
在解码器中,Transformer block比编码器中多了个encoder-cecoder attention。在encoder-decoder attention中, 来之与解码器的上一个输出,
和
则来自于与编码器的输出。其计算方式完全和图10的过程相同。
由于在机器翻译中,解码过程是一个顺序操作的过程,也就是当解码第 个特征向量时,我们只能看到第
及其之前的解码结果,论文中把这种情况下的multi-head attention叫做masked multi-head attention。
1.6 损失层
解码器解码之后,解码的特征向量经过一层激活函数为softmax的全连接层之后得到反映每个单词概率的输出向量。此时我们便可以通过CTC等损失函数训练模型了。
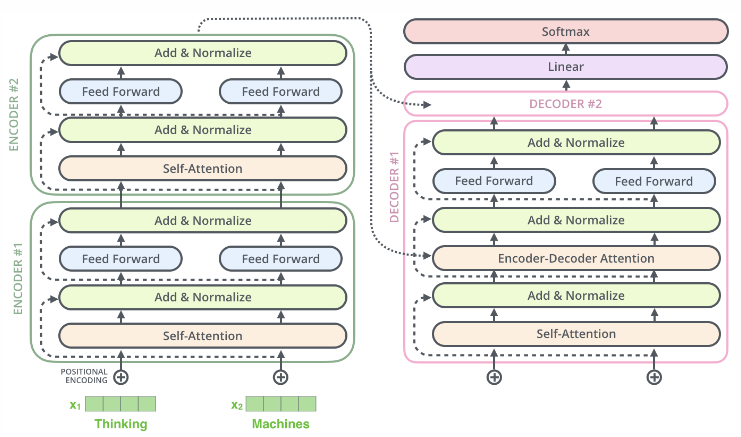
而一个完整可训练的网络结构便是encoder和decoder的堆叠(各 个,
),我们可以得到图15中的完整的Transformer的结构(即论文中的图1):

2.位置编码
我们的Transformer模型没有捕捉顺序序列的能力,也就是说无论句子怎么打乱,得到的结果都是类似的。为了解决这个问题,论文中提出了位置编码的概念。
位置编码常见模式有两种:a:根据数据学习 b:自己设计编码规则。在这里作者使用了第二种方式,通常位置编码的长度为 dmodel 的特征向量,这样便于和词向量进行单位相加(联想一下嵌入向量维度)。
论文给出下列公式:

上述公式中,pos表示单词的位置,i表示单词的维度。位置编码的实现参见:https://link.zhihu.com/?target=https%3A//github.com/tensorflow/tensor2tensor/blob/23bd23b9830059fbc349381b70d9429b5c40a139/tensor2tensor/layers/common_attention.py
作者这么设计的原因是考虑到在NLP任务重,除了单词的绝对位置,单词的相对位置也非常重要。根据公式 以及
,这表明位置
的位置向量可以表示为位置
的特征向量的线性变化,这为模型捕捉单词之间的相对位置关系提供了非常大的便利。
3.总结
使用了multi-headed self-attention 取代了encoder-decoder中的循环层。(论文)在机器翻译过程中取得了很好的效果,训练和评估代码的模型可以见: