在开始之前,我们先限定下python解释器的意思。当讨论Python的时候,解释器这个词可以用在不同的地方。有的时候,解释器指的是Python Interpreter,也就是你在命令行交互界面上输入python的时候。有的时候人们或多或少的交换使用python和python解释器来表明python从执行到结束的的过程。在本章中,解释器有更加确切的意思:python执行过程中的最后一步。
在解释器完成之前,python还有三个步骤需要执行:词法分析,语法解释,编译。最后这些步骤讲项目的源代码从文本转换成代码对象,其中包含编译器可以理解的指令。解释器的工作就是让这些代码对象按照执行工作。
你可能很奇怪执行python也包含编译这一步。Python通常和ruby以及perl一样被称为解释型语言,它们和C,Rust这样的编译语言不一样。尽管如此,这个术语并不像看起来那样精确。多数解释型语言,包括python,也有编译的步骤。python被称为解释型语言的原因在于相对于编译语言,编译做了很少的工作,而解释的工作更多。在后面的章节中能看到,Python解释器比C语言编译期需要更少的关于程序行为的信息。
Python的Python解释器:
Byterun是一个用python写的Python解释器。这点可能会让你感到奇怪,但是没有什么比C语言写C编译器更奇怪的了(广泛使用的C编译器GCC就是用C语言写的)。你可以用任务语言写Python解释器。
用Python写Python解释器有缺点也有优点。最大的缺点就是运行速度:在Byterun中执行代码比在CPython中要慢得多。CPython就是用C语言写的并且CPython做了认真的优化。尽管如此,Byterun被设计用于学习项目。所以速度对我们来说并不重要。最大的好处就是可以仅仅实现解释器,而不用担心云信时部分,特别是对象系统。比如Byterun需要创建类时就会回退到真正的python.另外一个优点就是Byterun容易理解,特别是用高级别语言来实现,这使得很多人阅读起来都很简单。
构建一个解释器:
在我们开始考察Byterun代码前,我们需要在高层次上对解释器的架构进行了解。python解释器是如何工作的?
Python解释器是一个虚拟机,是一个模拟真实计算机的软件。这个虚拟机是一个栈机器;它操作几个栈来实现操作(这和寄存器机器从内存位置去读和写不同)
Python解释器是一个字节解释器,它的输入是被称作为字节码的指令集。当你写Python的时候,词法分析器,语法分析器和编译器会生成代码对象让解释器去工作。每一个代码对象包含了待操作的指令集也就是字节码,再加上解释器需要的其他信息。字节码是Python代码的一个中间层:它表示了你按照解释器能够理解的方式来写源代码。这和汇编语言在C语言以及硬件之间作为中间表示的方式是类同的。
一个轻型的解释器:
为了说明更具体,让我们从一个小解释器开始。这个解释器只能做加法运算,并且只能理解3个指令。所有代码的执行都包含了这3个指令的不同组合方式。3个指令如下:
LOAD_VALUE
-
ADD_TWO_VALUES -
PRINT_ANSWER
假设7+5生成这样的指令集:
what_to_execute = {"instructions": [("LOAD_VALUE", 0), # the first number("LOAD_VALUE", 1), # the second number("ADD_TWO_VALUES", None),("PRINT_ANSWER", None)],"numbers": [7, 5] }
Python解释器是一个栈机器,所以必须操作栈去完成2个数的加法。解释器将从第一个指令LOAD_VALUE开始,然后将第一个数进栈。接下来第二个数字进栈。对于第三个指令:ADD_TWO_VALUES 将会让2个数字出栈并且相加,然后将结果进栈。最后将结果出栈打印出来。
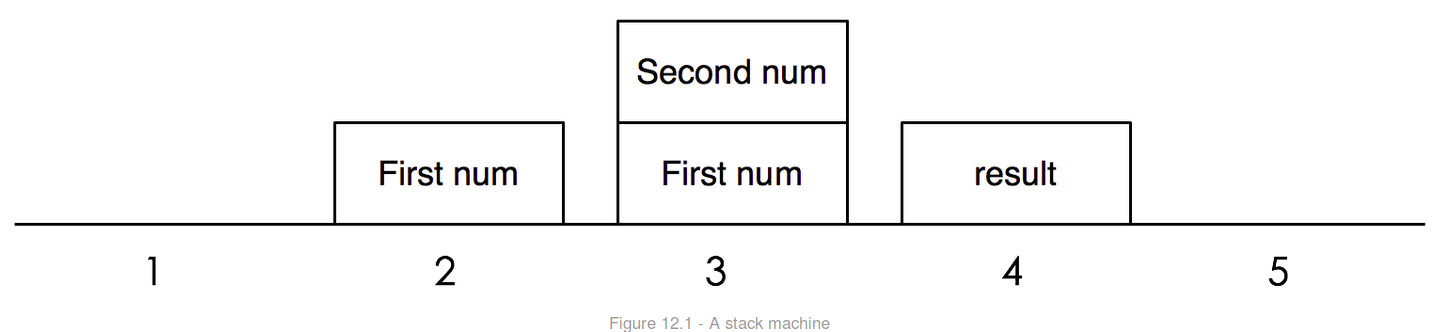
LOAD_VALUE指令告诉解释器将一个数字进栈,但是单靠指令指出是哪一个数字。每一个指令都需要额外的信息来告诉解释器去哪装载数字。所以我们的指令集有两部分:指令本身,加上指令需要的信息,告诉解释器从哪里去找到数字装载。
为什么不直接把数字放在指令里面呢?加入我们正在进行两个字符串相加而不是2个数字。我们不太愿意看到指令中充满字符串,因为字符串占的空间都很大。这种设计也意味着我们只需要对象的一份拷贝。比如加法7+7,常量numbers只需要存储7.
你可能会疑惑为什么会需要除了ADD_TWO_VALUES之外的所有指令。的确,对于两个数相加的例子,有点人为制作的意思。但是这个指令却可以制造更复杂的项目。比如,就目前我们定义的指令来说,只要给出正确的指令集合,我们可以进行3个数字的相加或者任意数字。同时栈提供了清晰的方法来追踪解释器的状态,这会支持我们后续进行更复杂的应用。
现在我们开始自己写解释器。解释器对象都有一个用列表表示的栈。对象有一个方法来描述如何执行指令。比如LOAD_VALUE,解释器就会将数字入栈。
class Interpreter:def __init__(self):self.stack = []def LOAD_VALUE(self, number):self.stack.append(number)def PRINT_ANSWER(self):answer = self.stack.pop()print(answer)def ADD_TWO_VALUES(self):first_num = self.stack.pop()second_num = self.stack.pop()total = first_num + second_numself.stack.append(total)
这3个函数实现了解释器可以理解的3个指令。解释器还需要一点:一个能把东西集合在一起并执行的方法。
这个方法就是run_code,它将前面定义的what_to_execute字典作为一个参数。循环所有的指令,处理传给指令的参数,并且在解释器对象里调用对应的方法。
def run_code(self, what_to_execute):instructions = what_to_execute["instructions"]numbers = what_to_execute["numbers"]for each_step in instructions:instruction, argument = each_stepif instruction == "LOAD_VALUE":number = numbers[argument]self.LOAD_VALUE(number)elif instruction == "ADD_TWO_VALUES":self.ADD_TWO_VALUES()elif instruction == "PRINT_ANSWER":self.PRINT_ANSWER()
为了测试,我们可以创建一个对象实例然后用前面定义的7+5的指令集来调用run_code.
interpreter = Interpreter()interpreter.run_code(what_to_execute)
可以肯定的是,打印结果为12。
虽然这个解释器的功能有限,但是这确实是真正的Python解释器做加法的过程。即使在这个小例子里面依然有许多东西需要特别提示
第一,一些指令需要参数。在真正的python的字节码中,大约有一半的指令有参数。像我们的例子一样,参数都是和指令打包在一起。值得注意的是指令的参数和被调用函数的参数是不一样的。
第二,ADD_TWO_VALUES没有要求任何参数。代替的是相加的参数从解释器的栈中出栈。这就是基于栈解释器的特点
记住使用正确的指令集合,不要对我们的解释器做任何改变,我们可以一次性对超过2个的数字进行加法运算。假设指令集如下,你期待发生什么?如果你有一个友好的编译器,你会写什么样的代码来产生这个指令集。
what_to_execute = {"instructions": [("LOAD_VALUE", 0),("LOAD_VALUE", 1),("ADD_TWO_VALUES", None),("LOAD_VALUE", 2),("ADD_TWO_VALUES", None),("PRINT_ANSWER", None)],"numbers": [7, 5, 8] }
从这点开始,我们看到这个结构体的扩展性:我们可以向解释器对象增加方法来描述更多的操作(只要我们有一个编译器组织好指令集)
变量
让我们给解释器来添加变量。我们需要一个指令来存储变量值,STORE_NAME; 一个指令来获取变量,LOAD_VALUE; 并且将变量名映射到值上。现在我们忽略命令空间和作用域,我们可以将变量名和映射直接存储在解释器对象上。最后,我们将保证what_to_execute有一个变量名列表和一个常量名列表。
>>> def s():... a = 1... b = 2... print(a + b)# a friendly compiler transforms `s` into:what_to_execute = {"instructions": [("LOAD_VALUE", 0),("STORE_NAME", 0),("LOAD_VALUE", 1),("STORE_NAME", 1),("LOAD_NAME", 0),("LOAD_NAME", 1),("ADD_TWO_VALUES", None),("PRINT_ANSWER", None)],"numbers": [1, 2],"names": ["a", "b"] }
我们的新实现如下。为了跟踪名字和数值之间的绑定关系,我们将在__init__方法中添加一个environmen字典。我们还会添加STORE_NAME和LOAD_NAME。 这些方法首先查找变量名称然后使用字典去取出或者设置这个值。
现在指令参数就有2个不同的意思:它可以是numbers列表的索引,也可以是names列表的索引。通过检查正在执行的指令,解释器就可以知道是哪种参数。我们打破这个逻辑,将指令和参数的映射关系放入一个单独的方法中去
class Interpreter:def __init__(self):self.stack = []self.environment = {}def STORE_NAME(self, name):val = self.stack.pop()self.environment[name] = valdef LOAD_NAME(self, name):val = self.environment[name]self.stack.append(val)def parse_argument(self, instruction, argument, what_to_execute):""" Understand what the argument to each instruction means."""numbers = ["LOAD_VALUE"]names = ["LOAD_NAME", "STORE_NAME"]if instruction in numbers:argument = what_to_execute["numbers"][argument]elif instruction in names:argument = what_to_execute["names"][argument]return argumentdef run_code(self, what_to_execute):instructions = what_to_execute["instructions"]for each_step in instructions:instruction, argument = each_stepargument = self.parse_argument(instruction, argument, what_to_execute)if instruction == "LOAD_VALUE":self.LOAD_VALUE(argument)elif instruction == "ADD_TWO_VALUES":self.ADD_TWO_VALUES()elif instruction == "PRINT_ANSWER":self.PRINT_ANSWER()elif instruction == "STORE_NAME":self.STORE_NAME(argument)elif instruction == "LOAD_NAME":self.LOAD_NAME(argument)
仅仅有5个指令,run_code已经开始变得冗长了。如果我们保持这个结构,对于每条指令都需要增减一个if声明。这里我们可以使用Python的动态查找。我们总会给一个FOO指令定义一个FOO方法,所以我们使用Python的getattr功能去查找对应的函数而不是使用if声明。run_code方法如下:
def execute(self, what_to_execute):instructions = what_to_execute["instructions"]for each_step in instructions:instruction, argument = each_stepargument = self.parse_argument(instruction, argument, what_to_execute)bytecode_method = getattr(self, instruction)if argument is None:bytecode_method()else:
bytecode_method(argument)
真正的python字节码:现在,我们将抛弃小的指令集,去看看真真的Python字节码。字节码的结构和解释器的指令集有点类似,不同的是字节码使用一个字节而不是一个长的名字去识别指令。我们通过一个简短的函数来理解这种结构。>>> def cond():... x = 3... if x < 5:... return 'yes'... else:... return 'no'...Python在运行的时候暴露很多内部信息,我们可以通过REPL来得到这些内部信息。对于函数对象cond,cond.__code__是对应的代码对象,cond.__code__.co_code就是对应的字节码。在你写python代码的时候,你觉得不想去用这些属性。但是可以让我们搞些恶作剧并且了解内部的结构。>>> cond.__code__.co_code # the bytecode as raw bytesb'dx01x00}x00x00|x00x00dx02x00kx00x00rx16x00dx03x00Sdx04x00Sdx00x00S'>>> list(cond.__code__.co_code) # the bytecode as numbers[100, 1, 0, 125, 0, 0, 124, 0, 0, 100, 2, 0, 107, 0, 0, 114, 22, 0, 100, 3, 0, 83,100, 4, 0, 83, 100, 0, 0, 83]当我们直接打印这些字节码的时候,它看起来完全无法理解。我们唯一了解的就是一串字节码。幸运的是我们有个强有力的工具来理解这些字节码:Python标准库的dis模块dis是一个字节码反汇编器。反汇编以给机器写的底层代码为输入,像汇编语言和字节码,然后以让人可以理解的方式打印出来。当我们运行dis.dis的时候,会输出每个字节码的解释。>>> dis.dis(cond)2 0 LOAD_CONST 1 (3)3 STORE_FAST 0 (x)3 6 LOAD_FAST 0 (x)9 LOAD_CONST 2 (5)12 COMPARE_OP 0 (<)15 POP_JUMP_IF_FALSE 224 18 LOAD_CONST 3 ('yes')21 RETURN_VALUE6 >> 22 LOAD_CONST 4 ('no')25 RETURN_VALUE26 LOAD_CONST 0 (None)29 RETURN_VALUE这些都是什么意思?让我们来看第一个指令LOAD_CONST,第一列中的数字2代表了Python源代码中的行号。第二列是字节码的索引,表示LOAD_CONST指令出现在位置0.第三列就是可以供我们理解的指令本身。第四列如果有的话,就是指令的参数。第五列,如果存在的话就是关于参数是什么的指示。现在来看下字节码的前几个字节[100,1,0,125,0,0]。 这6个字节代表了2个带参数的指令。我们可以使用dis.opname将它们从字节映射到字符串上来看下100和125分别对应的的指令。>>> dis.opname[100]'LOAD_CONST'>>> dis.opname[125]'STORE_FAST'第二和第三个字节1,0是LOAD_CONST的参数,第4个和第5个字节,0,0是STORE_FAST的参数。就像在你的小程序例子里面的一样,LOAD_CONST需要知道到哪里去装载常量,STORE_FAST需要知道需要找到存储的名字。(Python的LOAD_CONST就像是我们小例子中的LOAD_VALUE,LOAD_FAST和LOAD_NAME一样)。所以这6个字节代表了第一行,x=3。(为什么每个参数使用2个字节?如果Python使用一个字节来定位变量名而不是2个,那么一个代码对象只能有256个名字/常量,使用2个字节,可以使用256或者65536)条件语句和循环语句:到目前为止,解释器根据指令一条一条的执行了代码。这里有个问题;一般我们希望执行某条指令很多次,或者在特定条件下跳过它们。为了在代码中写循环,解释器必须能在指令集中进行跳转。Python在字节码中使用GOTO声明来处理条件语句和循环语句。再来看下cond功能的反汇编代码>>> dis.dis(cond)2 0 LOAD_CONST 1 (3)3 STORE_FAST 0 (x)3 6 LOAD_FAST 0 (x)9 LOAD_CONST 2 (5)12 COMPARE_OP 0 (<)15 POP_JUMP_IF_FALSE 224 18 LOAD_CONST 3 ('yes')21 RETURN_VALUE6 >> 22 LOAD_CONST 4 ('no')25 RETURN_VALUE26 LOAD_CONST 0 (None)29 RETURN_VALUE第3行的条件if x<5被汇编成了4条指令:LOAD_FAST,LOAD_CONST,COMPARE_OP以及POP_JUMP_IF_FALSE. x<5生成代码去装载x然后比较2个数字。POP_JUMP_IF_FALSE指令负责实现If.这个指令会将解释器的栈顶元素出栈。如果这个值为真,那么什么都不会发生。如果这个值为False,解释器将会跳转到其他的指令。这个将被加载的命令称为跳转目标,并且当做参数提供给POP_JUMP指令。在这里跳转目标是22.索引22的指令是在第6行的LOAD_CONST(dis通过>>来标记跳转目标)。如果if x<5的结果是False,那么解释器将会直接跳转到第6行返回”no”,跳过第4行(返回“yes”)。所以,解释器使用跳转指令来选择跳过部分指令集。Python的循环也是依赖与跳转。在下面的字节码中,注意到while x<5行生成了几乎和if x<10一样的代码。
在这两个例子中,计算比较结果然后POP_JUMP_IF_FALSE来控制下一步去要执行的指令。在第4行的结尾,也就是循环的结尾。指令JUMP_ABSOLUTE总是让解释器回到循环顶部的指令9.当if x<5变成false,POP_JUMP_IF_FALSE会让解释器跳转到循环的结尾的地方也就是指令34.
>>> def loop():... x = 1... while x < 5:... x = x + 1... return x...>>> dis.dis(loop)2 0 LOAD_CONST 1 (1)3 STORE_FAST 0 (x)3 6 SETUP_LOOP 26 (to 35)>> 9 LOAD_FAST 0 (x)12 LOAD_CONST 2 (5)15 COMPARE_OP 0 (<)18 POP_JUMP_IF_FALSE 344 21 LOAD_FAST 0 (x)24 LOAD_CONST 1 (1)27 BINARY_ADD28 STORE_FAST 0 (x)31 JUMP_ABSOLUTE 9>> 34 POP_BLOCK5 >> 35 LOAD_FAST 0 (x)38 RETURN_VALUE
探索字节码
我建议你在自己写的函数上运行dis.dis。一些问题值得探索:
1 对解释器而言,for循环和while循环有什么不同
2 如何写不同的函数但是产生同样的字节码
3 elif是如何工作的?列表推导呢
帧
目前为止,我们学习到了Python虚拟机是一个栈机器。它能顺序的执行指令或者在指令集中跳转,从栈中将元素出栈或出栈。但是和我们期望的还有很大的距离。在前面的例子中,最后一个指令是RETURN_VALUE对应到代码中的return语句。但是这个返回值返回到哪去呢。
为了回答这个问题,我们必须再增加一层复杂性:帧。一个栈是信息的集合以及代码的上下文。帧在Python代码执行的过程中创建和释放。每个帧对应一次函数调用-所以一个帧只有一个对应的代码对象,但是一个代码对象有多个帧。如果你将一个函数自我调用10次,你将有11个帧-每层调用对应一个帧,另外一个就是你开始的模块。总的来说,Python的每个作用域都有一个帧。比如,每个模块,每个函数调用和类定义都有一个帧。
帧存在于调用栈中,一个和我们之前讨论的不同且复杂的栈(你最熟悉的就是调用栈-就是你经常看到的异常回溯。每个以“File ‘programm.py”开始的回溯对应一个帧)目前我们用到过的栈-解释器在执行字节码时操作的栈-我们称为数据栈。其实还有第三个栈叫做块栈。块被用于特定的控制流,特别是循环和异常处理。调用栈上的每个帧都有属于自己的数据栈和块栈。
让我们用一个具体的例子来说明下。加入Python解释器执行下面标记到3的地方。解释器正处于函数foo的调用中,接下来正在调用bar。下面这个是帧调用栈,数据栈的结构图。我们感兴趣的是解释器从底部的foo开始执行,接着执行foo,然后到bar
>>> def bar(y):... z = y + 3 # <--- (3) ... and the interpreter is here.... return z...>>> def foo():... a = 1... b = 2... return a + bar(b) # <--- (2) ... which is returning a call to bar ......>>> foo() # <--- (1) We're in the middle of a call to foo ...3
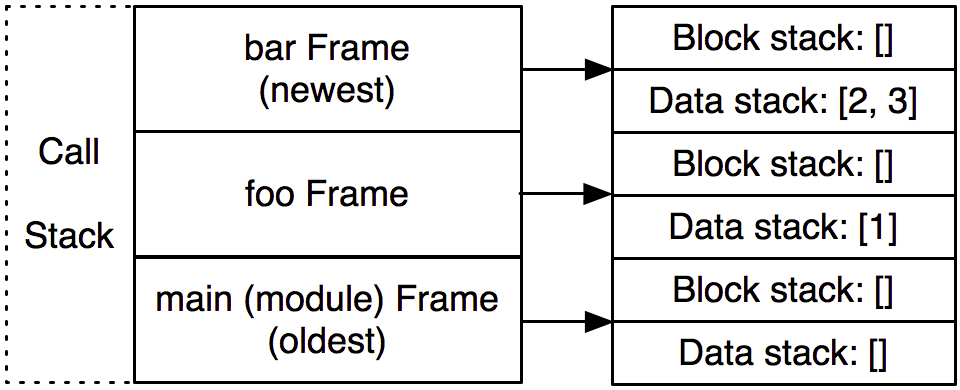
现在,解释器处于函数bar的调用中。在调用栈中有3个帧:一个对应于模块层,一个用于函数foo,一个用于函数bar。一旦bar 返回值,对应的帧就从调用栈中出栈并且丢弃。
字节码指令RETURN_VALUE告诉解释器在帧之间传递值。首先将会将调用栈顶部的帧的数据栈顶部数值出栈。然后将整个帧从调用栈中出栈并且丢弃。最后这个值在下一个帧的数据栈中入栈。
当我在写Byterun实现的时候,很长一段时间我们的代码一直存在一个错误。和每个帧有一个数据栈不同的是,我们在整个虚拟机上只有一个数据栈。我们写了很多测试代码并且在Byterun和真正的Python解释器上去执行,期望得到同样的结果。几乎所有的测试都通过了。唯一不能工作的就是生成器。最后,仔细阅读CPython的代码,我们意思到了错误。将数据栈移到每个帧上解决了这个问题。
回头看下这个bug,我们惊讶的发现Python其实很少依赖每个帧上有 一个数据栈的特性。Python解释器中几乎所有的操作都仔细的清理数据栈,所以在帧之间共享同样的栈不会有太大的影响。在上面的例子中,当bar完成执行,它将会使自己的调用栈清空。即使foo共享这个栈,它的值也不会受影响。尽管如此,在使用生成器的时候,一个关键的特性就是在帧之间暂停,返回值到其他帧,过段时间又能返回到原来的帧。并以离开时相同的状态执行。
Byterun
现在我们对Python解释器有足够的知识,我们可以开始来看下ByteRun的运行。
在ByteRun中有4种类型的对象:
虚拟机对象:用于控制最高层次的结构,特别是帧的调用栈,并且包含了指令到操作的映射。这是一个比之前解释器更复杂的版本
帧对象:每个帧实例都有一个代码对象并且管理一些其他必要的状态位,特别是全局和本地命名空间,调用帧的引用,以及指令执行的最后一个字节码
函数类:被用于真正的Python函数中。回想一下,调用一个函数会在解释器上创建一个新的帧。我们实现Function来控制创建新的帧
块类:它只是包装了块的3个属性。(块的具体实现不是Python解释器的重点,所以我们不会在这上面花太多的时间,但它们被包含在内所以ByteRun可以运行真正的Python代码)
虚拟机类:
程序运行的时候只有一个虚拟机类实例被创建,这是因为我们只有一个Python解释器。虚拟机存储调用栈,异常状态,以及在帧之间传递的返回值。执行代码的入口点是run_code函数,这个函数采用编译的代码对象作为参数。以创建帧开始然后运行。这个帧有可能创建其他的帧;调用栈随着程序的运行增长和缩短。当第一个帧返回,执行就结束。
class VirtualMachineError(Exception):passclass VirtualMachine(object):def __init__(self):self.frames = [] # The call stack of frames.self.frame = None # The current frame.self.return_value = Noneself.last_exception = Nonedef run_code(self, code, global_names=None, local_names=None):""" An entry point to execute code using the virtual machine."""frame = self.make_frame(code, global_names=global_names,local_names=local_names)self.run_frame(frame)
帧类:
接下来我们将写帧对象。帧是一个属性的集合,但是没有方法。就像上面提到的,这些属性包括编译器创建的代码对象;本地的,全局的以及命名空间;之前帧的引用;数据栈;块栈;以及最后一个执行的指令。
class Frame(object):def __init__(self, code_obj, global_names, local_names, prev_frame):self.code_obj = code_objself.global_names = global_namesself.local_names = local_namesself.prev_frame = prev_frameself.stack = []if prev_frame:self.builtin_names = prev_frame.builtin_nameselse:self.builtin_names = local_names['__builtins__']if hasattr(self.builtin_names, '__dict__'):self.builtin_names = self.builtin_names.__dict__self.last_instruction = 0self.block_stack = []
接下来,我们将在虚拟机上增加帧操作。这有3个帮助函数:创建新帧(负责为新帧寻找命令空间)和压栈出栈的方法。第四个方法,run_frame, 完成执行帧的主要工作。我们待会来讨论这个。
class VirtualMachine(object):[... snip ...]# Frame manipulationdef make_frame(self, code, callargs={}, global_names=None, local_names=None):if global_names is not None and local_names is not None:local_names = global_nameselif self.frames:global_names = self.frame.global_nameslocal_names = {}else:global_names = local_names = {'__builtins__': __builtins__,'__name__': '__main__','__doc__': None,'__package__': None,}local_names.update(callargs)frame = Frame(code, global_names, local_names, self.frame)return framedef push_frame(self, frame):self.frames.append(frame)self.frame = framedef pop_frame(self):self.frames.pop()if self.frames:self.frame = self.frames[-1]else:self.frame = Nonedef run_frame(self):pass# we'll come back to this shortly
Function类
Function的实现有点曲折,但是大部分的细节对于理解解释器并不重要。最值得注意的是解释器调用方法的时候,会用到__call__方法—创建一个新的帧对象并且开始运行。
class Function(object):"""Create a realistic function object, defining the things the interpreter expects."""__slots__ = ['func_code', 'func_name', 'func_defaults', 'func_globals','func_locals', 'func_dict', 'func_closure','__name__', '__dict__', '__doc__','_vm', '_func',]def __init__(self, name, code, globs, defaults, closure, vm):"""You don't need to follow this closely to understand the interpreter."""self._vm = vmself.func_code = codeself.func_name = self.__name__ = name or code.co_nameself.func_defaults = tuple(defaults)self.func_globals = globsself.func_locals = self._vm.frame.f_localsself.__dict__ = {}self.func_closure = closureself.__doc__ = code.co_consts[0] if code.co_consts else None# Sometimes, we need a real Python function. This is for that.kw = {'argdefs': self.func_defaults,}if closure:kw['closure'] = tuple(make_cell(0) for _ in closure)self._func = types.FunctionType(code, globs, **kw)def __call__(self, *args, **kwargs):"""When calling a Function, make a new frame and run it."""callargs = inspect.getcallargs(self._func, *args, **kwargs)# Use callargs to provide a mapping of arguments: values to pass into the new# frame.frame = self._vm.make_frame(self.func_code, callargs, self.func_globals, {})return self._vm.run_frame(frame)def make_cell(value):"""Create a real Python closure and grab a cell."""# Thanks to Alex Gaynor for help with this bit of twistiness.fn = (lambda x: lambda: x)(value)return fn.__closure__[0]
接下来,回到VirtualMachine对象,我们将针对数据栈操作增加一些帮助方法。操作栈的字节码总是在当前帧的数据栈上。这使得POP_TOP,LOAD_FAST以及其他操作栈的指令实现更加可读
class VirtualMachine(object):[... snip ...]# Data stack manipulationdef top(self):return self.frame.stack[-1]def pop(self):return self.frame.stack.pop()def push(self, *vals):self.frame.stack.extend(vals)def popn(self, n):"""Pop a number of values from the value stack.A list of `n` values is returned, the deepest value first."""if n:ret = self.frame.stack[-n:]self.frame.stack[-n:] = []return retelse:return []
在我们运行帧之前,我们还需要2个方法
第一,parse_byte_and_args 以一个字节码输入,检查是否有参数,如果有的话就解析参数。这个方法同样更新帧的属性last_instruction,它指向最后执行的指令。一个指令如果没有参数的话只有一个字节的长度,如果有参数的话就是3个字节;最后两个字节是参数。每个指令参数的意义取决与指令。比如就像上面提到的,对于POP_JUMP_IF_FALSE,指令的参数意味着跳转目标。对于BUILD_LIST,参数就表示列表中元素的个数。对于LOAD_CONST,参数表示常量列表的索引。
一些指令使用简单的数字作为参数。对于其他的指令,虚拟机还需要还要做一些工作去发现参数的意义。标准库中的dis模块有一个备用单,解释各个参数的意义,这也使得我们的代码更加简洁。比如,列表dis.hasname告诉我们LOAD_NAME、
IMPORT_NAME、LOAD_GLOBAL,以及另外的
9
个指令的参数都有同样的意义:对于这些指令,它们的参数代表了代码对象中的名字列表的索引。
class VirtualMachine(object):[... snip ...]def parse_byte_and_args(self):f = self.frameopoffset = f.last_instructionbyteCode = f.code_obj.co_code[opoffset]f.last_instruction += 1byte_name = dis.opname[byteCode]if byteCode >= dis.HAVE_ARGUMENT:# index into the bytecodearg = f.code_obj.co_code[f.last_instruction:f.last_instruction+2]f.last_instruction += 2 # advance the instruction pointerarg_val = arg[0] + (arg[1] * 256)if byteCode in dis.hasconst: # Look up a constantarg = f.code_obj.co_consts[arg_val]elif byteCode in dis.hasname: # Look up a namearg = f.code_obj.co_names[arg_val]elif byteCode in dis.haslocal: # Look up a local namearg = f.code_obj.co_varnames[arg_val]elif byteCode in dis.hasjrel: # Calculate a relative jumparg = f.last_instruction + arg_valelse:arg = arg_valargument = [arg]else:argument = []return byte_name, argument
下一个函数是dispatch,这个函数用于查找给定指令的操作并且执行。在CPython解释器中,这个函数用一个巨大的1500行的switch分之实现。幸运的是,我们在写Python,我们可以写的更简洁。我们会为每个字节名字定义一个函数然后使用getattr去查找。就像上面的迷你解释器一样,如果我们的指令被命令为FOO_BAR,对应的函数名称可以是byte_FOO_BAR.现在,我们将这些函数的具体实现看做是一个黑盒。每个字节码的函数都会返回None或者称作why的字符,有的时候解释器需要这个额外的信息。这些指令函数的返回值就作为解释器内部的状态指示,不要把他们和帧返回结果相混淆。
class VirtualMachine(object):[... snip ...]def dispatch(self, byte_name, argument):""" Dispatch by bytename to the corresponding methods.Exceptions are caught and set on the virtual machine."""# When later unwinding the block stack,# we need to keep track of why we are doing it.why = Nonetry:bytecode_fn = getattr(self, 'byte_%s' % byte_name, None)if bytecode_fn is None:if byte_name.startswith('UNARY_'):self.unaryOperator(byte_name[6:])elif byte_name.startswith('BINARY_'):self.binaryOperator(byte_name[7:])else:raise VirtualMachineError("unsupported bytecode type: %s" % byte_name)else:why = bytecode_fn(*argument)except:# deal with exceptions encountered while executing the op.self.last_exception = sys.exc_info()[:2] + (None,)why = 'exception'return whydef run_frame(self, frame):"""Run a frame until it returns (somehow).Exceptions are raised, the return value is returned."""self.push_frame(frame)while True:byte_name, arguments = self.parse_byte_and_args()why = self.dispatch(byte_name, arguments)# Deal with any block management we need to dowhile why and frame.block_stack:why = self.manage_block_stack(why)if why:breakself.pop_frame()if why == 'exception':exc, val, tb = self.last_exceptione = exc(val)e.__traceback__ = tbraise ereturn self.return_value
块类
在我们实现每个字节码的方法之前,我们先简短的讨论下块。块被用于特定的流控制,特别是异常处理以及循环。块确保当操作结束后数据栈是在正常的状态。比如,在一个循环运行过程中,一个迭代对象保持在栈上,但是当迭代结束后却出栈了。解释器必须追踪循环是结束了还是在继续运行。
为了追踪这些额外的信息,解释器设置了一个flag来标记循环的状态。我们用称作why的变量来实现这个标志位,标志位可以是None或者“continue”,”break”,”exception”,”return”之一。这个标记指示了块栈以及数据栈应该执行的操作类型。回到这个迭代器的例子,如果块栈的栈顶是loop块而且why是continue,这个迭代器必须保持在数据栈上,但是如果why是break。那么迭代器就应该出栈。
块操作的细节比这个还要繁琐,我们不会花太多的时间在这上面。感兴趣的读者可以自己下来阅读。
Block = collections.namedtuple("Block", "type, handler, stack_height")class VirtualMachine(object):[... snip ...]# Block stack manipulationdef push_block(self, b_type, handler=None):stack_height = len(self.frame.stack)self.frame.block_stack.append(Block(b_type, handler, stack_height))def pop_block(self):return self.frame.block_stack.pop()def unwind_block(self, block):"""Unwind the values on the data stack corresponding to a given block."""if block.type == 'except-handler':# The exception itself is on the stack as type, value, and traceback.offset = 3else:offset = 0while len(self.frame.stack) > block.level + offset:self.pop()if block.type == 'except-handler':traceback, value, exctype = self.popn(3)self.last_exception = exctype, value, tracebackdef manage_block_stack(self, why):""" """frame = self.frameblock = frame.block_stack[-1]if block.type == 'loop' and why == 'continue':self.jump(self.return_value)why = Nonereturn whyself.pop_block()self.unwind_block(block)if block.type == 'loop' and why == 'break':why = Noneself.jump(block.handler)return whyif (block.type in ['setup-except', 'finally'] and why == 'exception'):self.push_block('except-handler')exctype, value, tb = self.last_exceptionself.push(tb, value, exctype)self.push(tb, value, exctype) # yes, twicewhy = Noneself.jump(block.handler)return whyelif block.type == 'finally':if why in ('return', 'continue'):self.push(self.return_value)self.push(why)why = Noneself.jump(block.handler)return whyreturn why
指令
现在剩下的工作就是去实现大量的指令方法了。这些指令的实现并不有趣。所以我们只展示部分在这里。但是完整的实现在GitHub上。(这里包括的指令已经足够实现我们上面的代码了)
class VirtualMachine(object):[... snip ...]## Stack manipulationdef byte_LOAD_CONST(self, const):self.push(const)def byte_POP_TOP(self):self.pop()## Namesdef byte_LOAD_NAME(self, name):frame = self.frameif name in frame.f_locals:val = frame.f_locals[name]elif name in frame.f_globals:val = frame.f_globals[name]elif name in frame.f_builtins:val = frame.f_builtins[name]else:raise NameError("name '%s' is not defined" % name)self.push(val)def byte_STORE_NAME(self, name):self.frame.f_locals[name] = self.pop()def byte_LOAD_FAST(self, name):if name in self.frame.f_locals:val = self.frame.f_loca
def byte_STORE_FAST(self, name):
self.frame.f_locals[name] = self.pop()def byte_LOAD_GLOBAL(self, name):f = self.frameif name in f.f_globals:val = f.f_globals[name]elif name in f.f_builtins:val = f.f_builtins[name]else:raise NameError("global name '%s' is not defined" % name)self.push(val)## OperatorsBINARY_OPERATORS = {'POWER': pow,'MULTIPLY': operator.mul,'FLOOR_DIVIDE': operator.floordiv,'TRUE_DIVIDE': operator.truediv,'MODULO': operator.mod,'ADD': operator.add,'SUBTRACT': operator.sub,'SUBSCR': operator.getitem,'LSHIFT': operator.lshift,'RSHIFT': operator.rshift,'AND': operator.and_,'XOR': operator.xor,'OR': operator.or_,}def binaryOperator(self, op):x, y = self.popn(2)self.push(self.BINARY_OPERATORS[op](x, y))COMPARE_OPERATORS = [operator.lt,operator.le,operator.eq,operator.ne,operator.gt,operator.ge,lambda x, y: x in y,lambda x, y: x not in y,lambda x, y: x is y,lambda x, y: x is not y,lambda x, y: issubclass(x, Exception) and issubclass(x, y),]def byte_COMPARE_OP(self, opnum):x, y = self.popn(2)self.push(self.COMPARE_OPERATORS[opnum](x, y))## Attributes and indexingdef byte_LOAD_ATTR(self, attr):obj = self.pop()val = getattr(obj, attr)self.push(val)def byte_STORE_ATTR(self, name):val, obj = self.popn(2)setattr(obj, name, val)## Buildingdef byte_BUILD_LIST(self, count):elts = self.popn(count)self.push(elts)def byte_BUILD_MAP(self, size):self.push({})def byte_STORE_MAP(self):the_map, val, key = self.popn(3)the_map[key] = valself.push(the_map)def byte_LIST_APPEND(self, count):val = self.pop()the_list = self.frame.stack[-count] # peekthe_list.append(val)## Jumpsdef byte_JUMP_FORWARD(self, jump):self.jump(jump)def byte_JUMP_ABSOLUTE(self, jump):self.jump(jump)def byte_POP_JUMP_IF_TRUE(self, jump):val = self.pop()if val:self.jump(jump)def byte_POP_JUMP_IF_FALSE(self, jump):val = self.pop()if not val:self.jump(jump)## Blocksdef byte_SETUP_LOOP(self, dest):self.push_block('loop', dest)def byte_GET_ITER(self):self.push(iter(self.pop()))def byte_FOR_ITER(self, jump):iterobj = self.top()try:v = next(iterobj)self.push(v)except StopIteration:self.pop()self.jump(jump)def byte_BREAK_LOOP(self):return 'break'def byte_POP_BLOCK(self):self.pop_block()## Functionsdef byte_MAKE_FUNCTION(self, argc):name = self.pop()code = self.pop()defaults = self.popn(argc)globs = self.frame.f_globalsfn = Function(name, code, globs, defaults, None, self)self.push(fn)def byte_CALL_FUNCTION(self, arg):lenKw, lenPos = divmod(arg, 256) # KWargs not supported hereposargs = self.popn(lenPos)func = self.pop()frame = self.frameretval = func(*posargs)self.push(retval)def byte_RETURN_VALUE(self):self.return_value = self.pop()return "return"
动态类型,编译器不知道它是什么
你可能听过Python是一个动态的语言,它是动态类型的。在我们构造解释器的过程中,已经透露了这样的信息。
动态的一个意思是很多工作是在运行的时候进行的。前面我们看到Python编译器没有太多代码在做什么的信息。比如,下面的mod函数。mod输入是2个参数并且返回他们的模运算值。在字节码中,我们看到变量a和b被加载,然后BINARY_MODULD进行模运算
>>> def mod(a, b):... return a % b>>> dis.dis(mod)2 0 LOAD_FAST 0 (a)3 LOAD_FAST 1 (b)6 BINARY_MODULO7 RETURN_VALUE>>> mod(19, 5)4
计算19%5生成4,——下面不要感到奇怪,如果我们调用不同的参数会发生什么
>>> mod("by%sde", "teco")'bytecode
刚才发生了什么?你可能在其他地方见过这样的语法。格式化字符串
>>> print("by%sde" % "teco")bytecode
用符号%去格式化字符串会调用字节码BUNARY_MODULO。它取栈顶的两个值求模,不管这两个值是字符串、数字或是你自己定义的类的实例。字节码在函数编译时生成(或者说,函数定义时)相同的字节码会用于不同类的参数。
Python的编译器关于字节码的功能知道得很少。一切都取决于解释器来决定BINARY_MODULD执行的对象类型并完成正确的操作。这就是Python被称为动态类型:直到你运行的时候才会知道函数参数的类型。相反的是,静态语言需要程序员告诉参数是什么类型(或者编译器自己去找出参数的类型)
解释器的无知是Python的一个挑战——比如字节码,不真正的运行代码,你都不会直到指令将会干什么。事实上,你可以定义一个类来实现__mode__方法,当你在对象上使用%的时候Python就会调用这个方法。所以BINARY_MODULD可以运行任何代码
看下下面的代码,第一个a%b简直就是浪费
def mod(a,b):a % breturn a %b
不幸的是,对这段代码做静态分析,不运行它,就不能确定第一个a%b是否真的做了事情。用 %调用__mod__可能会写一个文件,或是和程序的其他部分交互,或者其他任何可以在 Python 中完成的事。很难优化一个你不知道它会做什么的函数。在 Russell Power 和 Alex Rubinsteyn 的优秀论文中写道,“我们可以用多快的速度解释 Python?”,他们说,“在普遍缺乏类型信息下,每条指令必须被看作一个INVOKE_ARBITRARY_METHOD
总结
Byterun 是一个比 CPython 容易理解的简洁的 Python 解释器。Byterun 复制了 CPython 的主要结构:一个基于栈的解释器对称之为字节码的指令集进行操作,它们顺序执行或在指令间跳转,向栈中压入和从中弹出数据。解释器随着函数和生成器的调用和返回,动态的创建、销毁帧,并在帧之间跳转。Byterun 也有着和真正解释器一样的限制:因为 Python 使用动态类型,解释器必须在运行时决定指令的正确行为。
我鼓励你去反汇编你的程序,然后用 Byterun 来运行。你很快会发现这个缩短版的 Byterun 所没有实现的指令。完整的实现在 https://github.com/nedbat/byterun,或者你可以仔细阅读真正的 CPython 解释器ceval.c,你也可以实现自己的解释器!