http 协议介绍
http:Hyper Text Transfer Protocol 超文本传输协议,是互联网应用最为广泛的一种网络协议,主要用于 Web 服务。通过计算机处理文本信息,格式为 HTML(Hyper Text Mark Language)超文本标记语言来实现。
http 协议的版本
-
http 0.9:仅于用户传输 html 文档
-
http 1.0
-
引入了 MIME(Multipurpose Internet Mail Extesions)机制:多用途互联网邮件扩展,引入这个技术之后,http 可以发送多媒体(比如视频、音频等)信息。此机制让 http 不在单单只支持 html 格式,还可以支持其他格式来进行发送了。
-
引入了 keep-alive 机制,支持持久连接的功能(但这个 keep-alive 原理是在首部添加了某个字段而形成的,并非原生就支持此功能)
-
引入支持缓存功能
-
http 1.1
支持更多的请求方法,更加精细的缓存控制,原生直接支持持久连接功能(presistent)。 -
http 2.0
提供了 HTTP 语义优化的传输 -
spdy : google 引入了的一个技术,能够加速 http 数据交互,尤其是使用 ssl 加速机制,但是 spdy 现在用的还不多。
目前常用的版本就是 http 1.0 版本和 http 1.1 版本。
html 文本介绍
html 文本架构
<html> <head> <title>TITLE</title> </head> <body> <h1>H1</h1> <p></p> <h2>H2</h2> <p><a href="admin.html">ToGoogle</a> </p> </body> </html>
html 文档的生成方式
-
静态
事先就编辑并定义完成的 -
动态
通过编译语言编写的程序后输出 html 格式的结果
动态语言有:php,jsp,asp,.net
备注:这些脚本都必须有相应的解释器,比如说 php 需要有 php 解释器等等
静态和动态的方式
静态

1、Web 服务器向内核注册 socket
2、客户端通过浏览器,向 Web 服务器发起 request 请求
3、Web 服务器收到客户端的 request 信息
4、如果用户请求的资源在服务器本地的话,http 服务会向系统内核申请调用
5、内核调用本地磁盘里的数据,并将数据发给 http 服务
6、http 将用户请求的资源通过 response 报文,最终响应给客户端
动态
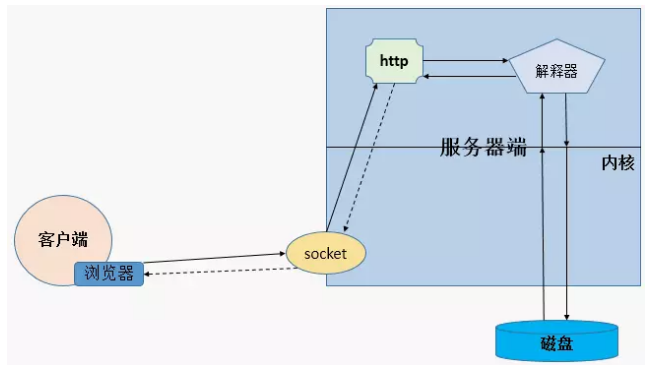
与静态不同的是,如果用户请求的是动态内容,那么此时 http 服务会调用后端的解析器,由动态语言去处理用户的请求,如果需要请求数据的时候,会向内核申请调用,从而向磁盘中获取用户指定的数据,通过解释器运行,运行的结果通常会生成 html 格式的文件。然后构建成响应报文,最终发回给客户端。
http 协议
http 协议的报文
HTTP 报文中存在着很多行的内容,一般是由 ASCII 码串组成,各字段长度是不确定的。HTTP 的报文可分为两种:请求报文与响应报文
-
request Message(请求报文)
客户端 → 服务器端
由客户端向服务器端发出请求,不同的网站用于请求不同的资源(html文档) -
response Message(响应报文)
服务器端 → 客户端
是服务器予以响应客户端的请求
请求报文格式介绍
请求行 + 请求首部 + 空白行 + 请求实体

<method> 这次请求的方式是什么,也就是请求方法 <request-URL> 请求的是哪个资源,哪个URL。可以是相对路径,如/images/log.jpg,也可以是绝对路径,如http://www.magedu.com/images.banner.jpg <version> 请求的协议版本是什么,http协议版本,格式HTTP/<major>.<minor>,例如:HTTP/1.0,HTTP/1.1<HEADERS> 首部,首部可能不止一个。各种所可以使用的首部信息 <entity-body> 请求实体,你到底请求的内容是什么
-
请求行
由 请求方法字段<method>+请求URL字段<request-URL>+HTTP 协议版本<version> 组成,用来标识客户端请求的资源时使用的请求方法,请求的资源,请求的协议版本是什么,它们直接使用“空格”进行分隔! -
请求首部
由关键字+关键字的值组成,之间使用“:”进行分隔,格式 Name:Value,请求首部的作用是通过客户端将请求的相关内容告知服务器端,首部可以不止一个。 -
空白行
请求首部之后会有一个空白行,通过发送回车字符和换行符,用于通知服务器端一下的内容将不会再出现请求首部的信息。 -
请求实体
你需要请求的内容到底是什么
例如: <method> <request-URL> <version> <HEADERS> # 这里一定要是一个空白行 <entity-body>
响应报文格式介绍
起始行 + 响应首部 + 空白行 + 响应实体

<version> 响应时客户端请求的是什么版本,服务器端就需要响应什么版本 <status> 请求的状态码是什么 202,403等 <reason-phrase> 响应的状态码的信息是什么,原因短语,这个状态码所响应的意义,易读信息 <HEADERS> 一大堆的响应首部 <entity-body> 响应体
-
起始行
也称之为状态行,用于服务器端响应客户端请求的状态信息,由版本号<version>+ 状态码<status>+ 原因短语<reason-phrase>组成,例如“ HTTP/1.1 200 OK” -
响应首部
类似请求报文,起始行后面一般有若干个头部字段。每个头部字段都包含一个名字和一个值,两者之间用冒号分割。格式Name:Value。
例如:
Content-Type: test/html; charset=utf-8
Content-Length: 78 -
空白行
最后一个响应首部信息之后就是一个空行,通过发送回车符和换行符,通知客户端空行下无首部信息 -
响应实体
响应实体中装载了要返回给客户端的数据。这些数据可以是文本,也可以是二进制(例如图片,视频)
例如: <version> <status> <reason-phrase> <HEADERS> # 这里一定要是一个空白行 <entity-body>
HTTP 请求方法
在 HTTP 通信过程中,每个 HTTP 请求报文中都会包含一个 HTTP 请求方法,用于告知客户端向服务器端请求执行某些具体的操作,下面列举几项常用的 HTTP 请求方法。
| HTTP 请求方法 | 描述 |
| GET | 用于客户端请求指定资源信息,并返回指定资源实体 |
| HEAD | 跟 GET 相似,但其不需要服务器响应请求的资源,而返回响应首部(只需要响应首部即可,就是告诉我有或者没有,不需要缓存界面给我) |
| POST | 基于 HTML 表单向服务器提交数据,服务器通常需要存储此数据,通常存放在 mysql 这种关系型数据库中 |
| PUT | 与 GET 相反,是向服务器发送资源的,服务器通常需要存储此资源(存放的位置通常是文件系统) |
| DELETE | 请求服务器端删除URL指定的资源 |
| MOVE | 请求服务器将指定的页面移至另一个网络地址 |
| OPTIONOS | 探测服务器端对请求的URL所支持使用的请求方法 |
| TRACE | 跟一次请求中间所经历的代理服务器、防火墙或网关等。 |
常用的 HTTP 请求方式是 GET, POST, HEAD
HTTP 的状态码
| 状态码 | 说明 |
| 1XX | 信息性状态码,用于指定客户端相应的某些操作 |
| 2XX | 成功状态码,我请求一个资源,这个资源在,这就表示请求成功了。 |
| 3XX | 重定向的状态码,有时会返回的是一个新地址,而非结果 |
| 4XX | 客户端类错误,你请求的资源不存在,或者你请求的时候,我们这个资源拒绝你访问,你没有权限 |
| 5XX |
服务器类的错误信息。向服务器发起请求,服务器发现需要运行一个脚本,从而调用解析库。如果在调用过程中出错就会出现这种情况。 或者你的脚本有语法错误,也可能会导致这个问题。 |
常用状态码说明:
| 状态码 | 说明 |
| 200 | 服务器成功返回网页,这是成功的 HTTP 请求返回的标准状态码 |
| 201 | CREATED 上传文件成功后显示 |
| 301 | Move Permanently 永久重定向,会返回一个新地址,并告诉我们你所请求的地址将永久挪到那个新地址去了 |
| 302 | Fonud 临时重定向,临时放到某个地方,会在响应报文中使用“Location:新位置” |
| 304 | Not Modified 资源没有做任何修改 |
| 403 | Forbidden 请求被拒绝 |
| 404 | Not Found 请求的资源不存在 |
| 405 | Method Not Allowed 你使用的方法不被允许,不支持 |
| 500 | Internal Server Error 服务器内部错误 |
| 502 | Bad Gateway 代理服务器从上游服务器收到一条伪响应;上一层服务器返回了一个无法理解的报文,所以代理服务器就会表示错误。 |
| 503 | Service Unavailable 服务暂时不可用 |
HTTP 首部介绍
-
通用首部
-
请求首部
-
响应首部
-
实体首部:专门用来表示实体中资源内部的类型、长度、编码格式等
-
扩展首部:非标准首部,可有程序员自行创建
通用首部
Connection:定义 C/S 之间关于请求、响应的有关选项。在 http1.0 的时候,如果他想使用持久连接,那么他所设置的选项即为
Connection:keep-alive
Cache-Control:缓存控制,实现更精细的缓存控制方式。在 http 1.1 上比较常见
请求首部
-
Client-IP :客户端 IP 地址
-
Host :请求的主机,这在实现基于主机名的虚拟主机时很有用
-
Referer :指明了请求当前资源原始资源的 URL,使用 referer 是可以防盗链
-
User-Agent:用户代理,一般而言是浏览器
-
Accept首部:指客户端可以接受哪些编码的类型
-
Accept:服务端能够发送的媒体的类型
-
Accetp-Charset:接收的字符集
-
Accept-Encoding:编码格式
-
Accept-Lanage:所能接受的语言编码格式
-
条件式请求首部:(在 http1.1 中才会用到)
当发送请求时,先问问对方是否满足条件,如果满足条件就请求,不满足就不请求 -
跟安全相关的请求:
-
Authorization
-
Cookie
响应首部
-
Age:资源响应给你之后可以使用的时长
-
Server:向客户端说明自己用到的程序名称和版本
-
协商类的首部:
-
Vary:首部列表,服务器会根据此列表挑选最适合的版本发给客户端
-
跟安全相关:
-
WWW-Authentication
-
Set-Cookie
实体首部
-
Location:指明资源的新位置,实现 302 响应码时通常会用到
-
Allow:允许对此资源使用的请求方法
-
内容相关的首部
-
Content-Encoding
-
Content-Language
-
Content-Length
-
Content-Location:内容所在的位置
-
Content-Type
-
缓存相关:
-
ETag:扩展标签/标记
-
Expires:过期时间
-
Last-Modified:删除修改时间
HTTP 的事务
包含了一个 HTTP 请求,和对应请求的响应就叫做一个 http 事务,也可以理解 http 事务就是一个完整的 HTTP 请求和 HTTP 响应的过程。
http 协议默认情况下每个事务都会打开和关闭一个新的连接,所以会相当耗费时间和带宽,由于 TCP 慢启动特性,所以每条新的连接的性能本身就会有所降低,所以可打开的并行连接的数量上限是有限的。所以使用持久连接这种模式比默认情况下不使用持久连接的方式会好一点,他的好处表现在其请求和 tcp 断开的过程所消耗的时间会被减少。
HTTP资源
资源就是通过 HTTP 协议可以让用户通过浏览器或用户代理能够通过基于 http 协议向服务器端请求并获取的内容,像 html 文档,一张图片等等。
资源类型:是通过 MIME 进行标记
格式:major/minor 主标记和次标记
常用的 MIME 类型:
| MIME 类型 | 文件类型 |
| test/html | html、htm 文本类型 |
| text/plain | text 文本类型 |
| image/jpeg | jpeg 图像类型 |
| image/gif | gif图像类型 |
| vedio/mpeg4 | 音频标记类型 |
| application/vnd.ms-powerpoint | 动态资源的标记方式 |
URI 和 URL
-
URI(Uniform Resource Identifier)同一资源标示符
用于标识某一互联网资源名称的字符串,通过这种标识来允许你用户对资源可通过特定的协议进行交互操作。在 Web 上可用的每种资源,包括 HTML 文档、图像、视频片段、程序等, 由一个通用资源标识符进行定位。所以我们可以使用 URI 来标识每个资源的名称 -
URL(Uniform Resource Locator)统一资源定位符
用于描述一个特定服务器上某资源的特定位置。
例如:http://www.magedu.com:80/download/bash-4.3.1-1.rpm
URL 的格式分为三个部分 -
scheme(方案)(也叫协议):http://
-
Internet 地址:一般这个地址指的是服务器:www.magedu.com:8080
-
特定服务器上的资源:download/bash-4.3.1-1.rpm
CGI
Common Gateway Interface 通用网关接口
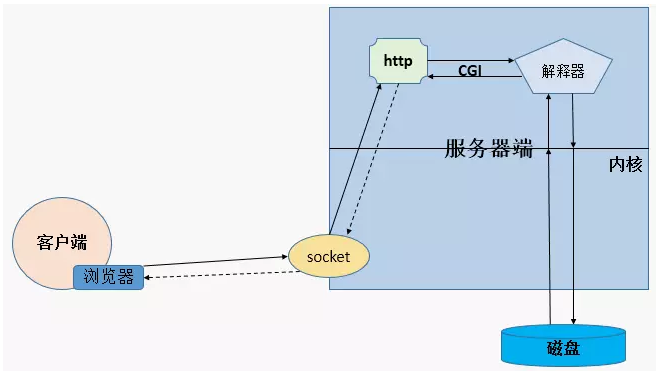
web 服务器发现需要执行脚本了,就通过 CGI 协议跟后端的应用程序打交道,把用户的请求动态交给服务器,这个服务器的结果通过 CGI 协议返回给 http 服务器。
其他需要了解的知识
一次 Web 资源请求的具体过程
-
客户端在 Web 浏览器输入需要访问的地址
-
Web 浏览器会请求 DNS 服务器,查询解析到指定域名和 Web 服务器的地址
-
客户端与请求的 Web 服务器端建立连接(TCP 三次握手)
-
TCP 建立成功之后,发起 HTTP 请求
-
服务器端收到客户端 HTTP 请求之后,会处理该请求
-
处理客户端指定请求的资源
-
服务器构建响应报文,响应给客户端
-
服务器端将此信息记录到日志中
http 如何并发的接收多个用户请求
因为 http 默认是工作在阻塞模型下的,默认一次只接收一个请求,处理完请求后再去接收下一个请求,所以只能一个一个来。
所以我们希望并发响应用户请求,需要多进程模型。web 服务器自己会生成多个子进程响应用户请求,也就是说,当一个用户请求发到 Web 服务器,Web 主进程不会直接响应用户请求,而是生成一个子进程响应这个用户请求,这样当子进程和此用户建立连接之后。Web 的主进程就会再等待另一个用户的请求,当第二个用户请求过来之后,在生成一个子进程响应第二个用户请求。以此类推。所以每一个用户请求都由一个子进程来处理。
连接套接字
Client IP,cport ↔ server IP , sport
一个主进程会生成 N 个子进程来响应用户请求,而实际上还是主进程来响应客户端的请求。连接套接字不是真正响应用户请求的,而仅仅会是用来标记用户请求。Web 服务器真正建立连接的不是 80 端口,而是使用一个其他的临时端口。会有人奇怪,明明我请求的是 80 端口,而你却使用临时端口响应我,其实不是这样,这个临时端口只是用来标记这么个客户端请求的,而不是真正去响应客户端请求。真正响应还是要主进程的 80 端口向外响应。
监听套接字:只有主服务才监听的。也就是使用 80 端口
web 服务器的 I/O 结构
-
单进程模型:一次只响应一个请求
-
多进程模型:每个进程响应一个用户请求而实现并发的效果
-
复用的 I/O 机制:一个进程生成多个线程,每个线程响应一个用户请求
-
复用的 I/O 机制:启用多个线程,但每个线程响应多个请求
我们使用的是单个线程,而不是进程
进程复用(多进程模型)
我们知道,当 Web 服务器需要响应用户请求,会生成一个子进程去响应该用户的请求,但一般用户请求完成之后,Web 服务器需要销毁这个子进程。那么来来去去,我们需要不断的创建子进程、销毁子进程…,这样会消耗系统资源。为了解决这样的问题,我们可以创建一个进程池,里面存放着一些空闲的子进程,那么当用户请求过来的时候,我们可以从进程池里取出一个空闲的子进程去响应用户请求。若请求结束之后,我们又将子进程返回到进程池中,这样就能省去系统创建、销毁子进程所带来的没必要的系统资源浪费。
而这个进程池有多大呢?是根据你服务器上的资源以及你服务器用户需求到到底有多大来创建的。而创建这个进程池也有一个好处,能定义我们最多使用多少个子进程,这样能免得一旦大量的请求涌进来,直接击垮我们的服务器。有了进程池就能避免这个问题。当我们的进程池里的子进程全用完了,如果此时还有请求进来,那么你就只能在外面排队等待了。所以使用进程池还能做到控制并发请求量的。
网站流量度量及并发量概念及计算
IP
IP(Internet Protocol)指独立的 IP 地址,用于衡量网站流量的一个重要指标。当客户端使用独立不同的 IP 地址访问网站,都将会被记录,被记录的总数就是为一个衡量指标。一般一天内,相同的 IP 地址访问网站只会被记录一次。
但是使用独立的 IP 地址来衡量网站的访问量会缺点,就是我们知道 ADS L和 NAT 的关系,所以获取到的 IP 总数和实际访问情况将不是完全匹配。
PV
PV(Page View)页面浏览访问量,通常衡量一个网络新闻频道和网站甚至一条网络新闻的主要指标。网页浏览数是评价网站流量的最常用的指标之一。无论客户端是否不同、IP 是否不同,只要你使用浏览器向服务器发起一次请求(页面浏览量和单击量),那么当服务器端接收到请求后会响应客户端,而这些都会被记录在 PV 中。
所以 PV 的数量大体反映浏览网站的页面数量,但是也有一定的缺点,那就是刷新网页也会被计数在 PV,所以 PV 数并不是真正页面来访者的数量,因为一个来访者可以产生多个 PV。
UV
UV(Unique Visitor)网站独立访客,同一个客户端访问网站都会被将认为是统一独立访客。一天内使用相同的客户端访问同一个网站都将只会计算一次 UV。
使用 UV 来计算会有一个缺点,那就是比如在学校里,一台客户端计算可能存在多个人使用的情况,这样就会产生数值误差。
并发连接
网站服务器在单位时间内能够处理的最大连接数
IP、PV、UV、并发量的计算
对 IP 计算
1. 分析网站的访问日志,去除相同的 IP 地址
2. 使用第三方统计工具
3. 在网页后添加多一个程序代码统计字段,然后使用日志分析工具对程序代码字段进行统计。
对 PV 的计算
1. 分析网站的访问日志,计算 HTML 及动态语言等网页的数量
2. 使用第三方统计工具
3. 在网页后添加多一个程序代码统计字段,然后使用日志分析工具对程序代码字段进行统计。
对 UV 的计算
1. 分析客户端的 HTTP 请求报文,将客户端特有的信息记录下来进行分析。若能满足共同的特征将会被认为是同一个客户端,那么此时将记录为一个 UV。
2. 通过 cookie
当客户端访问一个网站时,服务器会向该客户端发送一个 Cookie,Cookie 具有独一性,所以当客户端再次使用 cookie 访问网站时,会附带此 Cookie,那么此时服务器就会认为是同一个客户端,那么只会记录一次的 UV
缺点:使用 Cookie 方法比分析客户端 HTTP 请求头部信息更为精准,但是会有缺点,那就是用户可能会关闭了 Cookie 功能。或者自动删除了 cookie 等操作,所以获取的指标也不能说是完全准确。
对并发量计算
每秒请求数(吞吐量) + 并发浏览连接数 + 平均用户考虑时间 = 网站并发用户总数
原文出自马哥教育微信
http://mp.weixin.qq.com/s?__biz=MzA3OTgyMDcwNg==&mid=2650625807&idx=1&sn=73eaeb0c164dec33f5031bbf4cd0d7b1&scene=0#wechat_redirect