后缀数组是真的难,我花了一个月总算有了一点比较基础的概念,然后就马上写学习笔记了QMQ。
普通后缀数组
导语
暴力基排?不不不,(O(n^2))时间,太慢了!后缀数组就是专门解决这个问题哒。
BB几句
后缀数组我分两种构建算法
- 倍增算法
- SA-IS
其实原本只打算学SA-IS,毕竟(O(n)),常数还比DC3要小,就是思想复杂了点QAQ。
于是就跟机房里一开始学倍增的一位大佬争了个“你死我活”,结果后来又发现树上后缀数组只能用倍增,QAQ,真香。

倍增算法
过程
先讲倍增吧,因为实在不想提前体验SA-IS博客的长度。
倍增,顾名思义,1,2,4,8...,后一个是前一个的两倍,那么,后缀数组跟倍增有什么关系?
首先,对所有的字母基数排序一遍。
温馨提示:倍增用基排(O(nlogn)),用快排(O(nlog^2n))
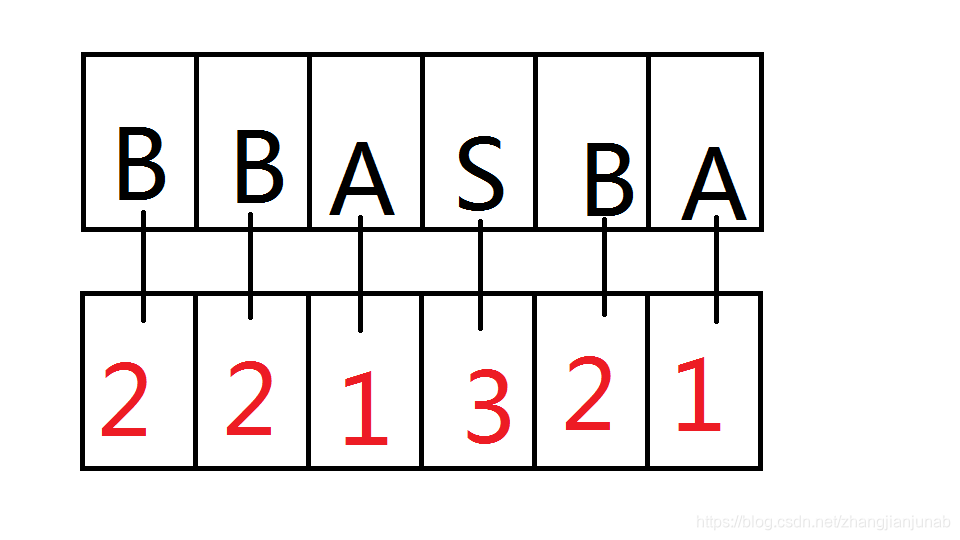
但是这里面有三个2,两个1,一个3,那么我们该怎么让他们彼此不相等呢?
回想普通暴力基排时,排序完了第一个字母,就排序第二个字母,那么,倍增也一样,将每个字母的后面一个字母的排名合并到这个字母上,没有字母就当后面字母的排名为0。
合并方式见图片:
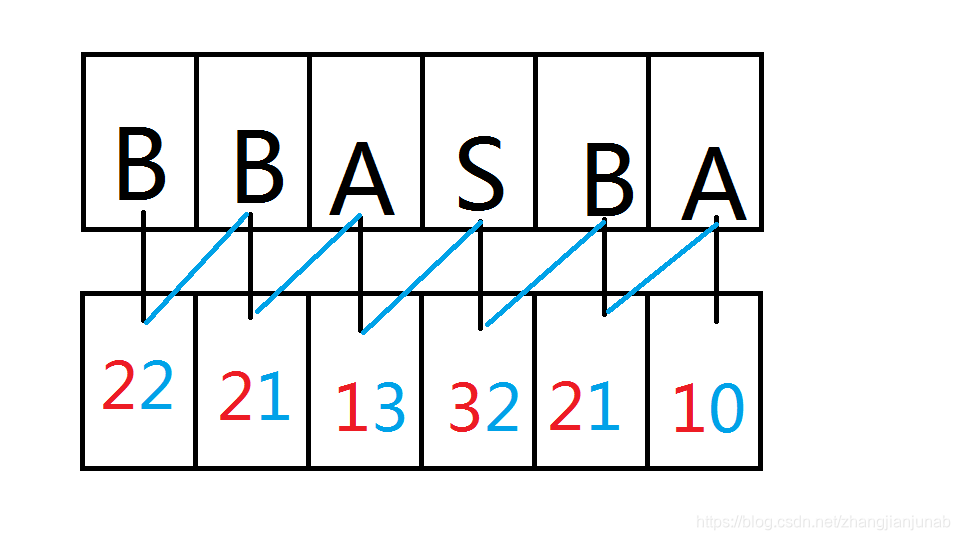
那么我们只要对合并后的两位基数排序就行了,正确性显而易见,就是排序每个字母开始的两个字符。
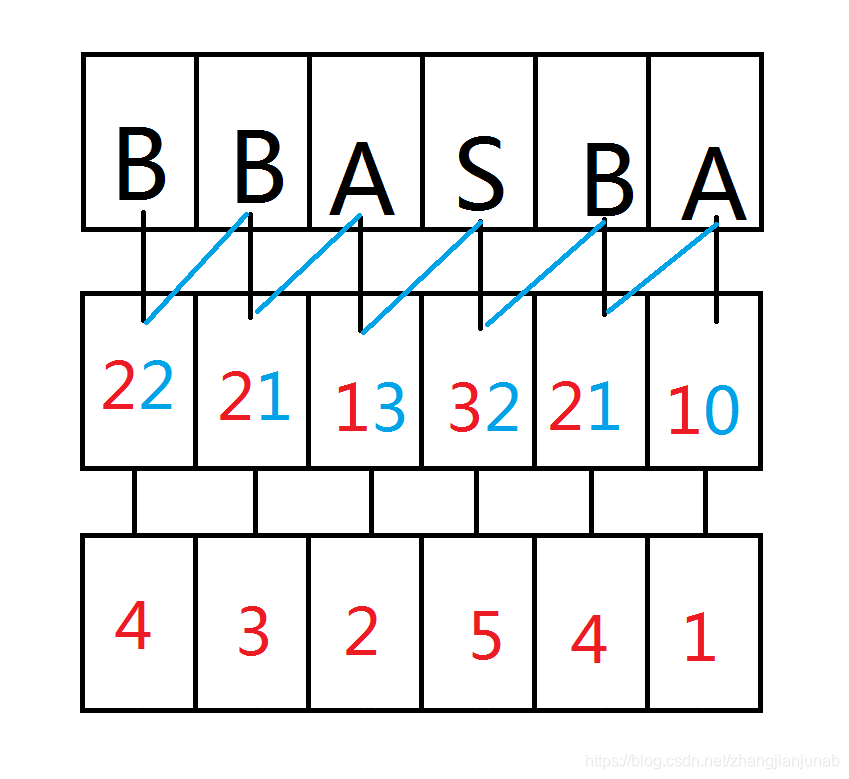
但是还是有两个4,那么我们是不是继续基排第三个字符?不行,不然跟暴力差不了多少,那怎么做?
回想一下,我们已经排序了每个后缀的前两个字符,那么每个后缀的第三位与第四位是不是就是这个后缀的下下个后缀的第一位与第二位?
那么,每个后缀只需要再把他后两个的后缀的排名合并起来,基排一遍。
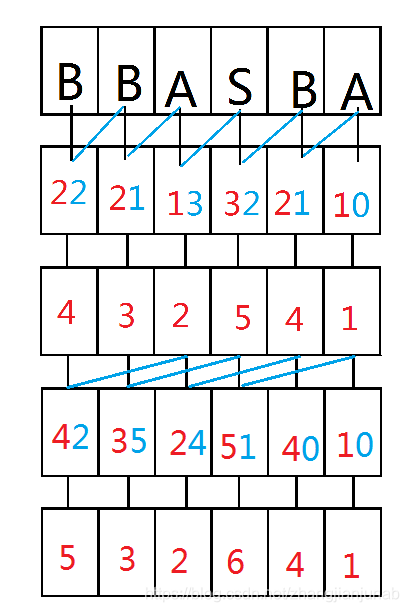
至此,没有一个相似的,就结束。
总结
- 过程总结
倍增的过程总结一下,首先排序每个后缀第一个字符。
然后合并前2个,基排,再合并前4个,基排,再合并前8个,基排......
- 一小点小东西。
我们设现在合并的是每个后缀前(k)个字符((k)为2的倍数),那么,那么(n-k+1)到(n)个后缀的排名的个位都是0,同时十位互不相同。
这个很好想,因为倍增原本就是正确的QMQ。
好吧,我想是因为(前方高能,仅为作者临时所想):
那么(n-k+1)到(n)个后缀的排名的个位都是0,这个不讲,So easy。
证明后一句话:
我们设x=k/2,也就是上一步过程。
假设再上一步过程之前,(n-k+1)到(n-x)都有相同的话,那么不同只能不同在个位,也就是他们分别合并的(n-x+1)到(n),那么,一步步下去,最终(x)会折中到(0),(k)到(1),那么这是(n-k+1)到(n-x)只有一个数,肯定不相等。
同时(n-k+1)到(n-x)的排名肯定没有一个与(n-x+1)到(n)相等,因为再合并每个后缀前x个的时候,(n-x+1)到(n)的排名的个位都是0,而(n-k+1)到(n-x)的排名的个位都是大于0的数,因此(n-k+1)到(n)个后缀的排名互不相等。
那么,上一句话是对的,我们就可以进而推导出倍增的过程到(log_{2}(n)+1)是肯定每个后缀排名互不相等,故倍增(O(nlogn))。
代码
#include<cstdio>
#include<cstring>
#include<algorithm>
#define N 1200000
using namespace std;
int xx[N],yy[N],cc[N],sa[N],n,m;
char st[N];
void get_sa()
{
//基数排序
for(int i=1;i<=n;i++)cc[xx[i]=st[i]]++;//统计每个字符有多少个
for(int i=2;i<=m;i++)cc[i]+=cc[i-1];
for(int i=n;i>=1;i--/*仅对一个字符排序,正的反的都可以*/)sa[cc[xx[i]]--]=i;//计算第一个字符
//先对第一个字符排序
//cc
for(int k=1;k<=n;k<<=1)
{
//yy数组相当于对个位排序的每个后缀的排名。
int num=0;
for(int i=n-k+1;i<=n;i++)yy[++num]=i;//为0的先预先都到yy数组里面去
for(int i=1;i<=n;i++)//遍历一边sa数组
{
if(sa[i]>k)yy[++num]=sa[i]-k;//将自己的值给到-k的位置上
}
//yy
memset(cc+1,0,(m<<2));//部分清0,int有4个字节
//对十位排序
for(int i=1;i<=n;i++)cc[xx[i]]++;//统计
for(int i=2;i<=m;i++)cc[i]+=cc[i-1];//统计
for(int i=n;i>=1;i--/*按照yy数组从大到小*/)sa[cc[xx[yy[i]]]--]=yy[i];//按照十位一个个对到sa数组里面去
//cc
swap(xx,yy);//将xx数组给到yy数组,同时xx数组要更新出新的xx数组,相当于原来的yy数组已经没用了。
xx[sa[1]]=num=1;//先处理第一项
for(int i=2;i<=n;i++)
{
xx[sa[i]]=(yy[sa[i]]==yy[sa[i-1]]/*原本的排名相同*/ && yy[sa[i]+k]==yy[sa[i-1]+k]/*加k位的排名相同*/)?num/*不变*/:++num/*+1*/;
}
if(n==num)break;//优化
m=num;//更新m
}
}
int main()
{
scanf("%s",st+1);
n=strlen(st+1);m=122;
get_sa();
for(int i=1;i<n;i++)printf("%d ",sa[i]);//输出
printf("%d
",sa[n]);
return 0;
}
注意:这里的基数排序写法可能有点奇怪,但是很实用,其实就是借用了桶思想的基数排序。
玄学优化
听说把(xx[yy[i]])用另一个数组储存起来,能加速到很快的时间。
SA-IS
一个写起来会死人的算法,QAQ。
一个写得十分好的博客,比较建议去这里看,毕竟我的语文不是很好
大佬:SA-IS核心就是诱导排序。
一步步慢慢讲,不急。。。QAQ
过程
导语
首先,我们定义type数组,如何灵活应用这个数组是这个算法的核心。
定义s数组代表字符串,一个后缀的集合表示为字母大写,第(i)个后缀代表以第(i)个字母开头的后缀。
所有下标从1开始!!!
在刚开始的时候,我们要给s数组的最后加一个比所有字符都要小的字符,假设就是'#'。
type与LMS的构建
type数组分三种情况(默认最后一位,也就是'#'为'S'):
- 当(s[i]<s[i+1])时,(type[i]='S')。
- 当(s[i]>s[i+1])时,(type[i]='L')。
- 当(s[i]=s[i+1])时,(type[i]=type[i+1])。
注意,在后文中提到的一个后缀的类型就是这个后缀首字母的(type)。
那么我们倒着搜(O(n))可以处理出来
//0为S,1为L。
//因为type数组默认清零,所以type[n]=0
for(int i=n-1;i>=1;i--)
{
if(st[i]>st[i+1])type[i]=1;
// if(st[i]<st[i+1])type[i]=0;默认为0,所以可以不写
else if(st[i]==st[i+1])type[i]=type[i+1];
}
//type
那么(LMS)是什么情况?就是当(type[i]='S') && (type[i-1]='L')时,我们称(i)位(LMS)节点。
同时称两个(LMS)节点间(包括两个点)的子串叫LMS子串,以LMS节点为开头的后缀叫LMS后缀。
定理1
'#'一定是(LMS)节点
显而易见,'#'比所有节点小,自然比(s[n-1])小,同时他还默认十(S)类型
定理2
那么我们可以发现(LMS)节点就是一大串(L)后面的第一个(S),因此我们可以知道(LMS子串)肯定是前面一段(S)类型,中间一段(L)类型,最后一个(S)类型的。
给个表格帮助理解:
| 下标 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 字母 | a | b | c | a | a | c | d | e | # |
| type | L | L | L | S | S | S | S | L | S |
| (LMS) | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
定理3
对于两个后缀(A)与(B),当(A[1]=B[1])且A的类型为(L),(B)的类型为(S),则(A<B)
证明:
设(A=abX,B=acY)
我们可以知道(b≤a,c≥a),当(b<a)或(c>a)时,很明显我们要讨论(a=b,a=c)的情况。
当(a=b,a=c)时,我们转化为讨论(aX)与(aY)的关系,不断下去。
由于(type[n]=S,type[n-1]=L),所以A顶多转化到第(n-2)个后缀。而B顶多转化到第(n-1)个后缀,且都最少有两个字符,因此我们可以不用担心没有(b)或(c)的情况。
这个有什么用?
也就是说在sa数组里面,同样首字母的后缀,类型是(L)排前面,类型是(S)的排后面
诱导排序的基本过程
诱导排序先讲过程再讲证明会简单一点。
其实type数组与LMS数组就是诱导排序的核心数组,那么如何排序呢?
首先,我们假设LMS后缀是之间已经排好序的了。
过程:
- 用桶排序思想将每个字符的出现次数记录,同时用(lbsa)与(rbsa)数组记录每个字符在(sa)数组中出现的左端点与右端点。
- 逆序扫描LMS数组,同时将LMS后缀依次加入S型桶里面。
- 正序扫描一遍sa数组,当(type[sa[i]-1]=L)时,将(sa[i]-1)放入L型桶里面。(依赖于LMS后缀的排序性)
- 倒序扫描一遍sa数组,当(type[sa[i]-1]=S)时,将(sa[i]-1)放入S型桶里面。(依赖于L型放入的正确性)
同时注意:LMS后缀在sa中的真正位置不一定就是一开始放入的位置。
举个例子:
| 下标 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 桶 | # | a | a | a | b | c | c | d | e |
| type | S | L | S | S | L | L | S | S | L |
诱导排序的正确性
定理4
L型
正序扫描的时候能扫描完所有的L型。
证明:
A为L型后缀,且A不是第一个后缀,B为A的前一个后缀。
设(B)为(abcX),则(A)为(bcX)。
当(a>b)时,B会出现在b型桶所对位置的后面的位置。
当(a=b)时,我们把他添加到b型桶里面的S型桶。
因此后面可以查询到后缀B,也就自然可以不断添加B的前一个后缀。
又因为每一段L型桶后面都有一个LMS节点,所以可以扫描完所有的L型。
S型
倒序扫描的时候能扫描完所有的S型。
如上,每一段S型后面都有一个L型,当然,#除外。
定理5
这样的排序是对的吗?
是对的,我们其实只要证明两个相同字符开头的后缀的排序是正确的。
证明:
有两个后缀,首先,他们都是从右边离他们最近的LMS节点开始一直延伸到这里的,不容易我们设从后缀开头到右边最近的LMS节点(包括LMS节点和后缀开头)分别为(aX,aY)。
aX与aY肯定是前面一段S型,后面一段L型,以及LMS节点的一个S型,所以本质上就是从LMS节点开始,从尾到头排序aX与aY以及LMS节点,由于是从尾到头,所以遵循在两个子串最开头的第一个不相等位置(字符不相等或者类型不相等)上,那么字符小在前,字符大在后,字符相同就是类型了,前面定理三已经讲过了。
当然,我讲的比较抽象,这个需要你自己模拟一下。其实就是语文不好
所以诱导排序就是对类似(aX)的字符串从尾到头一个个进行排序,同时,我们也不用担心(aX=aY),因为最后的LMS节点已经排序好了QMQ。
注意:(aX)是其中一个LMS子串去掉最后一个字符,因为从这个LMS节点开始的L段与S段中,S段的开头就是上一个LMS节点。
至此,我们可以知道,当LMS后缀排好序后,我们就可用这种过程来对整串排序。
LMS后缀排序
万事俱备,只欠东风,LMS后缀如何排序?
我们先对LMS子串进行排序:
将每个LMS节点按随机顺序扔进去,然后跑一遍诱导排序,定理5也都讲了,又到排序就是对(aX)这样的子串进行排序,那么我们就利用他对LMS子串进行排序。
排序完以后,我们找一下LMS节点,此时的每一个LMS节点其实就是他与下一个LMS节点构成的LMS子串的排序,当然,有一个特例,#在排序中永远都在sa的第1位。

当所有的LMS子串都不一样时,我们就把他们认为是LMS后缀的排名,当一样时,我们就把LMS子串的排名归到LMS子串开头的LMS节点上,同时对所有LMS节点的排名当成字符串,再跑一遍SA-IS,得出他们的后缀排名。
总结
总算写完了。偷工减料能不写完吗?
时间复杂度
由于LMS节点最多n/2个,因此最坏时间复杂度式子:
化简一下,其实就是(O(n))(就是因为时间复杂度短,才成为了我与大佬打架讨论的资本)。
代码
不用class的纯天然代码
不得不说代码长...
#include<cstdio>
#include<cstring>
#define N 2100000
#define NN 1100000
using namespace std;
int lbsa[NN],rbsa[NN],sa[N];
char str[NN];int st[N];
bool type[N];int cs[NN]/*记录字符出现次数,一开始有要记录122个,后面排序要多记录n/2,n/4,n/8......,因此化简得出空间要NN就可以了*/;
int qwq[NN]/*记录LMS节点*/,num[N];
int n;
inline bool pd(bool type[],int q){return !type[q] && type[q-1];}//判断是否是LMS节点
inline bool ccmp(bool type[],int st[],int q,int p)//判断两个LMS子串是否相等,不相等返回1,相等返回0
{
do
{
if(st[q]!=st[p])return 1;
q++;p++;
}while(!pd(type,q) && !pd(type,p));
return (!pd(type,q) || !pd(type,p) || st[q]!=st[p]);
}
inline void isort(int sa[],int st[],bool type[],int cs[],int n,int m)//诱导排序
{
/*st[n]可以不动,因为他肯定在1的位置,所以不用记录lbsa[0]与rbsa[0]*/for(int i=1;i<=m;i++)lbsa[i]=cs[i-1]+1,rbsa[i]=cs[i];
for(int i=1;i<=n;i++)//正序扫描
{
if(sa[i]>1 && type[sa[i]-1])sa[lbsa[st[sa[i]-1]]++]=sa[i]-1;
}
for(int i=n;i>=1;i--)//倒序扫描
{
if(sa[i]>1 && !type[sa[i]-1])sa[rbsa[st[sa[i]-1]]--]=sa[i]-1;
}
}
void get_sa(int sa[],int st[],bool type[],int cs[],int qwq[],int num[],int n,int m)
{
for(int i=1;i<=n;i++)cs[st[i]]++;//统计字符
rbsa[0]=cs[0];for(int i=1;i<=m;i++)rbsa[i]=cs[i]+=cs[i-1];//分配空间,LMS节点只用S型桶。
//rbsa,cs
//0为S,1为L。
//因为type数组默认清零,所以type[n]=0
for(int i=n-1;i>=1;i--)
{
if(st[i]>st[i+1])type[i]=1;
// if(st[i]<st[i+1])type[i]=0;默认为0,所以可以不写
else if(st[i]==st[i+1])type[i]=type[i+1];
}
//type
int cnt=0;
for(int i=2;i<=n;i++)
{
if(pd(type,i))qwq[++cnt]=i,sa[rbsa[st[i]]--]=i;//记录LMS节点,同时添加,省一点常数
}
//qwq,sa,cnt
isort(sa,st,type,cs,n,m);//诱导排序
//isort
int t=0,last=n;//默认num[n]=0,下面可以省last!=0的判断
for(int i=2;i<=n;i++)
{
if(!pd(type,sa[i]))continue;
if(ccmp(type,st,last,sa[i]))t++;//添加
last=sa[i];num[last]=t;
}
//num,t
if(t<cnt-1)/*t从0开始*/
{
for(int i=1;i<=cnt;i++)st[n+i]=num[qwq[i]];
get_sa(sa+n,st+n,type+n,cs+m+1,qwq+cnt,num+n,cnt,t);//不用在后面添加一个字符,因为n号位置肯定是LMS节点
}
else
{
for(int i=1;i<=cnt;i++)sa[n+num[qwq[i]]+1]=i;//没有排序,为了代码短一点,将num一个个放进sa
}
memset(sa+1,0,(n<<2));//部分清0
memcpy(rbsa,cs,(m<<2)+4);//部分拷贝
for(int i=cnt;i>=1;i--)sa[rbsa[st[qwq[sa[n+i]]]]--]=qwq[sa[n+i]];//将后缀放入sa数组
isort(sa,st,type,cs,n,m);//排序QMQ
}
int main()
{
scanf("%s",str+1);n=strlen(str+1);
for(int i=1;i<=n;i++)st[i]=str[i];//转成int类型
get_sa(sa,st,type,cs,qwq,num,n+1/*添加字符0*/,130);
for(int i=2/*跳过sa[1]*/;i<=n;i++)printf("%d ",sa[i]);//输出
printf("%d
",sa[n+1]);
return 0;
}
注意
后面的代码都是用SA-IS实现的,倍增也差不多,如果你真正理解这两个算法,改代码并不难。
LCP最长公共前缀
过程
后缀数组有时候会很鸡肋,但是如果配合上LCP,最长公共前缀,那就了不得了。
我们设(height[i])为(sa[i])与(sa[i-1])的最长公共前缀(LCP),那么怎么求height呢?
定义rank数组表示第i位在SA中的位置,h数组为(height[rank[i]])。
定理6
(h[i]≥h[i-1]-1)
本貌似人家也是转载别人博客然后做些改动的
首先我们不妨设第i-1个字符串按排名来的前面的那个字符串是第k个字符串,注意k不一定是i-2,因为第k个字符串是按字典序排名来的i-1前面那个,并不是指在原字符串中位置在i-1前面的那个第i-2个字符串。
这时,依据height[]的定义,第k个字符串和第i-1个字符串的公共前缀自然是height[rk[i-1]],现在先讨论一下第k+1个字符串和第i个字符串的关系。
第一种情况,第k个字符串和第i-1个字符串的首字符不同,那么第k+1个字符串的排名既可能在i的前面,也可能在i的后面,但没有关系,因为height[rk[i-1]]就是0了呀,那么无论height[rk[i]]是多少都会有height[rk[i]]>=height[rk[i-1]]-1,也就是h[i]>=h[i-1]-1。
第二种情况,第k个字符串和第i-1个字符串的首字符相同,那么由于第k+1个字符串就是第k个字符串去掉首字符得到的,第i个字符串也是第i-1个字符串去掉首字符得到的,那么显然第k+1个字符串要排在第i个字符串前面。同时,第k个字符串和第i-1个字符串的最长公共前缀是height[rk[i-1]],
那么自然第k+1个字符串和第i个字符串的最长公共前缀就是height[rk[i-1]]-1。
到此为止,第二种情况的证明还没有完,我们可以试想一下,对于比第i个字符串的排名更靠前的那些字符串,谁和第i个字符串的相似度最高(这里说的相似度是指最长公共前缀的长度)?显然是排名紧邻第i个字符串的那个字符串了呀,即sa[rank[i]-1]。但是我们前面求得,有一个排在i前面的字符串k+1,LCP(rk[i],rk[k+1])=height[rk[i-1]]-1;
又因为height[rk[i]]=LCP(i,i-1)>=LCP(i,k+1)
所以height[rk[i]]>=height[rk[i-1]]-1,也即h[i]>=h[i-1]-1。
证明证明完了作者要懒呀!
那么我们只要按顺序求出h数组就行了,复杂度(O(n))。
那么,就到了重要的地方了,我们height数组只处理了SA中临近两个后缀的LCP,但是任意两个呢?
定理7
两个后缀,x开头的和y开头的后缀(默认(sa[x]<sa[y])),他们的SA等于(min(height[i])(sa[x]<i≤sa[y]))。
证明:
设他们的LCP为x。
那么在以(sa[i](sa[x]<i≤sa[y]))开头的后缀中,一定会有一个后缀的第(x+1)位的字符跟(Y)的第(x+1)位不同,所以取min就是找这个(x)位,类似DP。
栗子:(摘自)
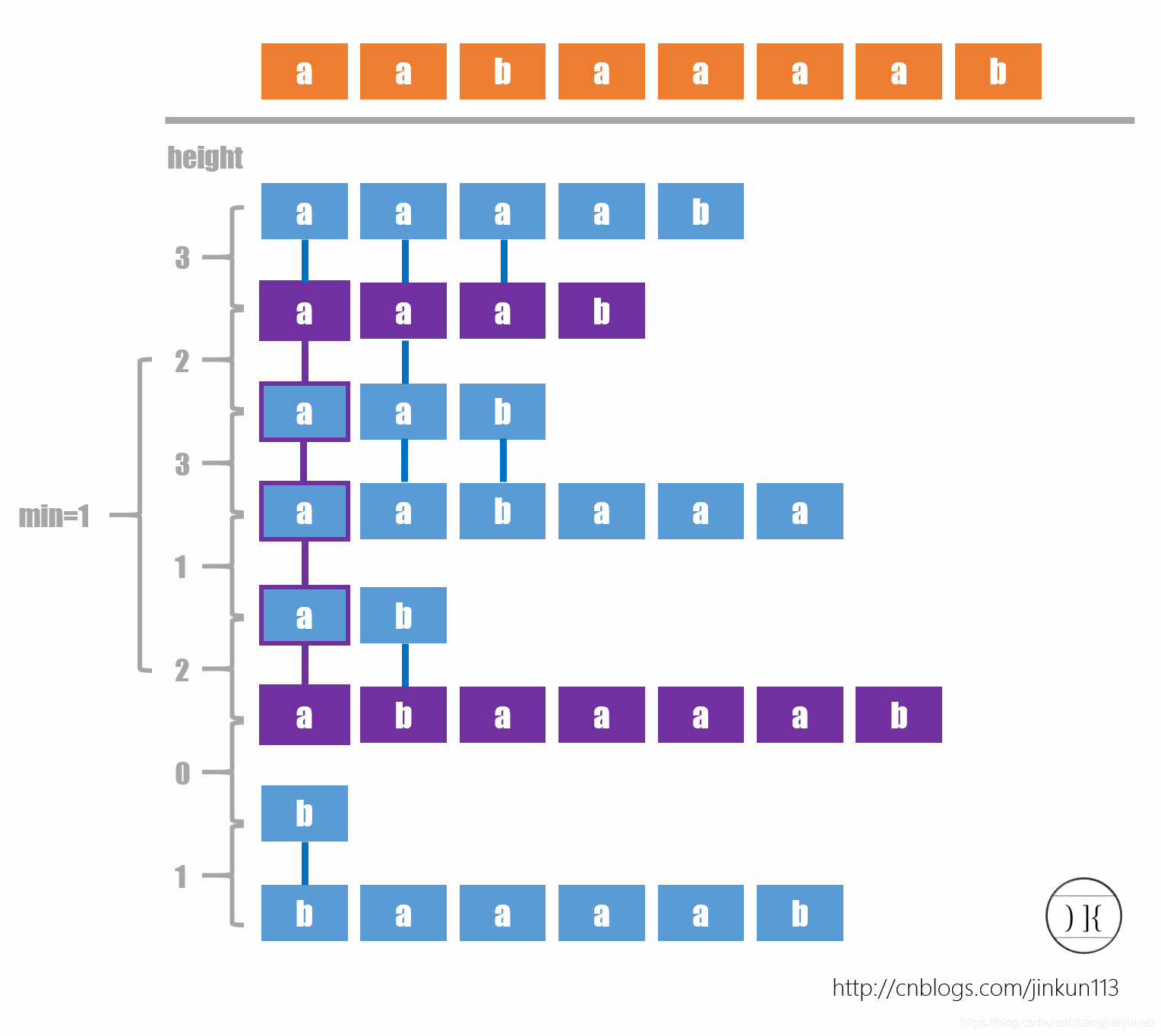
于是,我们可以用ST表来处理,总时间复杂度(O(nlogn))
例题与代码
解题思路:
求出height数组,(ans=(n-sa[i]+1)-height[i](1≤i≤n))
#include<cstdio>
#include<cstring>
#define N 210000
#define NN 410000
using namespace std;
int lbsa[NN],rbsa[NN],sa[N];
char sstt[NN];int str[N];
bool type[N];int cs[NN];
int qwq[NN],num[N];
long long ans;
inline bool pd(bool type[],int p){return (!type[p] && type[p-1]);}
inline bool ccmp(int st[],bool type[],int q,int p)
{
do
{
if(st[q]!=st[p])return 1;
q++;p++;
}while(!pd(type,q) && !pd(type,p));
return (!pd(type,q) || !pd(type,p) || st[q]!=st[p]);
}
inline void isort(int st[],int sa[],bool type[],int cs[],int n,int m)
{
lbsa[0]=rbsa[0]=cs[0];for(int i=1;i<=m;i++)lbsa[i]=cs[i-1]+1,rbsa[i]=cs[i];
for(int i=1;i<=n;i++)
{
if(sa[i]>1 && type[sa[i]-1])sa[lbsa[st[sa[i]-1]]++]=sa[i]-1;
}
for(int i=n;i>=1;i--)
{
if(sa[i]>1 && !type[sa[i]-1])sa[rbsa[st[sa[i]-1]]--]=sa[i]-1;
}
}
void get_sa(int sa[],int st[],bool type[],int cs[],int qwq[],int num[],int n,int m)
{
for(int i=1;i<=n;i++)cs[st[i]]++;
rbsa[0]=cs[0];for(int i=1;i<=m;i++)cs[i]+=cs[i-1],rbsa[i]=cs[i];
//cs
for(int i=n-1;i>=1;i--)
{
if(st[i]>st[i+1])type[i]=1;
else if(st[i]==st[i+1])type[i]=type[i+1];
}
//type
int cnt=0,t=-1,last=0;
for(int i=2;i<=n;i++)
{
if(pd(type,i))qwq[++cnt]=i,sa[rbsa[st[i]]--]=i;
}
//qwq
isort(st,sa,type,cs,n,m);
//isort
for(int i=1;i<=n;i++)
{
if(!pd(type,sa[i]))continue;
if(!last || ccmp(st,type,last,sa[i]))t++;
num[sa[i]]=t;last=sa[i];
}
//num
if(t<cnt-1)
{
for(int i=1;i<=cnt;i++)st[n+i]=num[qwq[i]];
get_sa(sa+n,st+n,type+n,cs+m+1,qwq+cnt,num+n,cnt,t);
}
else
{
for(int i=1;i<=cnt;i++)sa[n+num[qwq[i]]+1]=i;
}
memset(sa,0,(n<<2));
memcpy(rbsa,cs,(m<<2)+4);
for(int i=cnt;i>=1;i--)sa[rbsa[st[qwq[sa[n+i]]]]--]=qwq[sa[n+i]];
isort(st,sa,type,cs,n,m);
}
//sa-is
int ra[NN]/*rank*/,height[NN];
void get_height(int n)
{
int k=0,j=0;
for(int i=1;i<=n;i++)//从1到n
{
j=sa[ra[i]-1];
k?k--:1;//h[i]>=h[i-1]-1
while(sstt[i+k]==sstt[j+k])k++;//寻找
height[ra[i]]=k;
ans+=n+1-i-k;//统计
}
}
int main()
{
int n;scanf("%d%s",&n,sstt+1);n++;
for(int i=1;i<n;i++)str[i]=sstt[i];
get_sa(sa,str,type,cs,qwq,num,n,300);
for(int i=2/*跳过sa[1]*/;i<=n;i++)ra[sa[i]]=i;//处理rank
get_height(n-1/*跳过最后一位*/);
printf("%lld
",ans);
return 0;
}
至此,LCP求完了。
普通后缀数组练习
练习1
首先,推介大家一篇写得十分好的论文,讲的是后缀数组的应用,十分好!
叫《后缀数组——处理字符串的有力工具》,是罗穗骞大佬写的。
讲得十分详细。
回归正题,在研究这道题之前,我们研究一下如何判断找一个字符串的最长重复子串,这两个子串不能重叠。
首先,我们二分长度,将这道题目变成二分判定性问题,二分长度,然后对height分组,在每一组里面找sa值的最大值与最小值之差是否符合答案就行了。
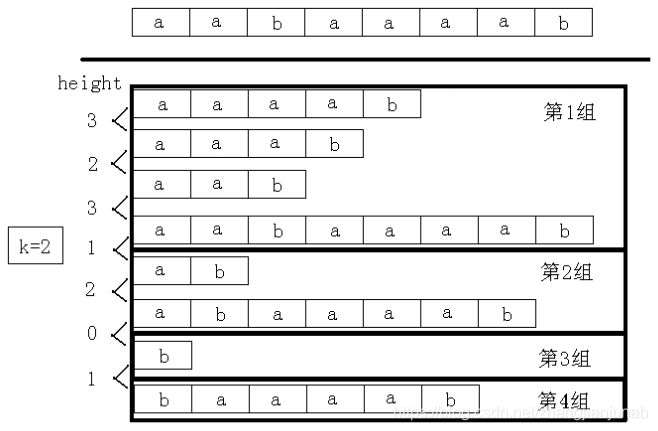
而这道题目,则更变态,我们需要对原数组差分,比如:1,2,3。差分后变成1,1,1,然后省略掉第一位,变成1,1,那么我们就只要改变一下判断条件,找不可重叠最长重复子串,然后加1就行了。
吾丑陋的代码:
#include<cstdio>
#include<cstring>
#define N 81000
#define NN 41000
using namespace std;
int lbsa[NN],rbsa[NN],sa[N];
int st[N];
int cs[NN];bool type[N];
int qwq[NN],num[N];
inline bool pd(bool type[],int p){return !type[p] && type[p-1];}
inline bool ccmp(int st[],bool type[],int q,int p)
{
do
{
if(st[q]!=st[p])return 1;
q++;p++;
}while(!pd(type,q) && !pd(type,p));
return (!pd(type,q) || !pd(type,p) || st[q]!=st[p]);
}
inline void isort(int sa[],int st[],bool type[],int cs[],int n,int m)
{
lbsa[0]=rbsa[0]=cs[0];for(int i=1;i<=m;i++)lbsa[i]=cs[i-1]+1,rbsa[i]=cs[i];
for(int i=1;i<=n;i++)
{
if(sa[i]>1 && type[sa[i]-1])sa[lbsa[st[sa[i]-1]]++]=sa[i]-1;
}
for(int i=n;i>=1;i--)
{
if(sa[i]>1 && !type[sa[i]-1])sa[rbsa[st[sa[i]-1]]--]=sa[i]-1;
}
}
void get_sa(int sa[],int st[],bool type[],int cs[],int qwq[],int num[],int n,int m)
{
for(int i=1;i<=n;i++)cs[st[i]]++;
rbsa[0]=cs[0];for(int i=1;i<=m;i++)cs[i]+=cs[i-1],rbsa[i]=cs[i];
//cs
for(int i=n-1;i>=1;i--)
{
if(st[i]>st[i+1])type[i]=1;
else if(st[i]==st[i+1])type[i]=type[i+1];
}
//type
int cnt=0;
for(int i=2;i<=n;i++)
{
if(pd(type,i))qwq[++cnt]=i,sa[rbsa[st[i]]--]=i;
}
//qwq
isort(sa,st,type,cs,n,m);
//isort
int t=0,last=n;num[n]=0;//num没有初始化
for(int i=1;i<=n;i++)
{
if(!pd(type,sa[i]))continue;
if(ccmp(st,type,last,sa[i]))t++;
last=sa[i];num[last]=t;
}
//num,t
if(t<cnt-1)
{
for(int i=1;i<=cnt;i++)st[n+i]=num[qwq[i]];
get_sa(sa+n,st+n,type+n,cs+m+1,qwq+cnt,num+n,cnt,t);
}
else
{
for(int i=1;i<=cnt;i++)sa[n+num[qwq[i]]+1]=i;
}
memset(sa+1,0,(n<<2));
memcpy(rbsa,cs,(m<<2)+4);
for(int i=cnt;i>=1;i--)sa[rbsa[st[qwq[sa[n+i]]]]--]=qwq[sa[n+i]];
isort(sa,st,type,cs,n,m);
}
//SA-IS
int height[NN],rank[NN];
void get_height(int n)
{
st[n]=-1;//最后一个位置为-1
int j,k=0;
for(int i=1;i<n;i++)
{
j=sa[rank[i]-1];
if(k)k--;
while(st[i+k]==st[j+k])k++;
height[rank[i]]=k;
}
}
inline int mymax(int x,int y){return x>y?x:y;}
inline int mymin(int x,int y){return x<y?x:y;}
bool check(int n,int x)
{
n++;//判断最后一位
int minsa=0,maxsa=0;//不用初始化,因为height[2]=0
for(int i=2/*用sa-is的话,第1位是添加字符*/;i<=n;i++)//height[n]=0,判断最后一位
{
if(height[i]>=x)minsa=mymin(minsa,sa[i]),maxsa=mymax(maxsa,sa[i]);
else maxsa=minsa=sa[i];
if(maxsa-minsa>x/*这道题的不重叠要注意,最后答案要在相同子串前加一个字母*/)return 1;//判断
}
return 0;
}
int main()
{
int n;scanf("%d",&n);
while(n)
{
memset(sa,0,sizeof(sa));
memset(cs,0,sizeof(cs));
memset(type,0,sizeof(type));
memset(height,0,sizeof(height));
for(int i=1;i<=n;i++)scanf("%d",&st[i]);
for(int i=1;i<n;i++)st[i]=st[i+1]-st[i]+100;//差分数组省略开头(只是这题与开头无缘)
st[n]=0;get_sa(sa,st,type,cs,qwq,num,n,300);
for(int i=2;i<=n;i++)rank[sa[i]]=i;
get_height(n);
int l=0,r=n/*最后一个*/,mid,ans=0;
while(l<=r)//二分
{
mid=(l+r)/2;
if(check(n,mid))ans=mid,l=mid+1;
else r=mid-1;
}
if(ans>=4)printf("%d
",ans+1);
else printf("0
");
scanf("%d",&n);
}
return 0;
}
练习2
也是二分答案,分组,只不过判定条件变了。
#include<cstdio>
#include<cstring>
#include<algorithm>
#define N 81000
#define NN 41000
using namespace std;
struct LS
{
int x,y;
}ls[NN];int lslen;
inline bool cmp(LS x,LS y){return x.x<y.x;}
int lbsa[NN],rbsa[NN],sa[N];
int st[N];
bool type[N];int cs[N];
int qwq[NN],num[N];
inline bool pd(bool type[],int p){return !type[p] && type[p-1];}
inline bool ccmp(int st[],bool type[],int q,int p)
{
do
{
if(st[q]!=st[p])return 1;
q++;p++;
}while(!pd(type,q) && !pd(type,p));
return (!pd(type,q) || !pd(type,p) || st[q]!=st[p]);
}
inline void isort(int st[],int sa[],bool type[],int cs[],int n,int m)
{
lbsa[0]=rbsa[0]=cs[0];for(int i=1;i<=m;i++)lbsa[i]=cs[i-1]+1,rbsa[i]=cs[i];
for(int i=1;i<=n;i++)
{
if(sa[i]>1 && type[sa[i]-1])sa[lbsa[st[sa[i]-1]]++]=sa[i]-1;
}
for(int i=n;i>=1;i--)
{
if(sa[i]>1 && !type[sa[i]-1])sa[rbsa[st[sa[i]-1]]--]=sa[i]-1;
}
}
void get_sa(int st[],int sa[],bool type[],int cs[],int qwq[],int num[],int n,int m)
{
for(int i=1;i<=n;i++)cs[st[i]]++;
rbsa[0]=cs[0];for(int i=1;i<=m;i++)rbsa[i]=cs[i]+=cs[i-1];
//cs
type[n]=0;
for(int i=n-1;i>=1;i--)
{
if(st[i]>st[i+1])type[i]=1;
else if(st[i]<st[i+1])type[i]=0;//多组数据啦,QAQ
else if(st[i]==st[i+1])type[i]=type[i+1];
}
//type
int cnt=0;
for(int i=2;i<=n;i++)
{
if(pd(type,i))qwq[++cnt]=i,sa[rbsa[st[i]]--]=i;
}
//qwq
isort(st,sa,type,cs,n,m);
//isort
int last=n,t=0;num[n]=0;/*没初始化*/
for(int i=2;i<=n;i++)
{
if(!pd(type,sa[i]))continue;
if(ccmp(st,type,sa[i],last))t++;
num[sa[i]]=t;last=sa[i];
}
//num,t
if(t<cnt-1)
{
for(int i=1;i<=cnt;i++)st[n+i]=num[qwq[i]];
get_sa(st+n,sa+n,type+n,cs+m+1,qwq+cnt,num+n,cnt,t);
}
else
{
for(int i=1;i<=cnt;i++)sa[n+num[qwq[i]]+1]=i;
}
memset(sa+1,0,(n<<2));
memcpy(rbsa,cs,(m<<2)+4);
for(int i=cnt;i>=1;i--)
{
sa[rbsa[st[qwq[sa[n+i]]]]--]=qwq[sa[n+i]];
}
isort(st,sa,type,cs,n,m);
}
int height[NN],ra[NN];
void get_height(int n)
{
int j,k=0;
for(int i=1;i<n;i++)
{
j=sa[ra[i]-1];
if(k)k--;
while(st[i+k]==st[j+k])
{
k++;
}
height[ra[i]]=k;
}
}
inline bool check(int n,int m,int x)
{
height[n+1]=-1;
int maxqwq=0;
for(int i=2;i<=n;i++)//这个循环里的东西变了一点
{
if(height[i]>=x)maxqwq++;
else maxqwq=1;
if(maxqwq>=m)return 1;
}
return 0;
}
int main()
{
ls[0].x=-1;
int n,m;
while(scanf("%d%d",&n,&m)!=EOF)//多组数据
{
lslen=0;
memset(sa,0,sizeof(sa));
memset(cs,0,sizeof(cs));
for(int i=1;i<=n;i++){scanf("%d",&ls[i].x);ls[i].y=i;}
sort(ls+1,ls+1+n,cmp);
for(int i=1;i<=n;i++)
{
if(ls[i].x!=ls[i-1].x)lslen++;
st[ls[i].y]=lslen;
}
st[++n]=0;get_sa(st,sa,type,cs,qwq,num,n,lslen);
for(int i=2;i<=n;i++)ra[sa[i]]=i;
get_height(n);
int l=0,r=n-1,mid,ans=0;
while(l<=r)
{
mid=(l+r)/2;
if(check(n,m,mid))ans=mid,l=mid+1;
else r=mid-1;
}
printf("%d
",ans);
}
return 0;
}
练习3
给出一个字符串S(S<=250000),令F(x)表示S的所有长度为x的子串中,出现次数的最大值。求F(1)..F(Lengh(S));
样例输入
ababa
样例输出
3
2
2
1
1
博主,这不是后缀自动机的题目吗,你怎么把这道题目敲诈过来了?
那是因为这道题目(O(n))即可以做。
怎么做?
如果你用的是SA-IS的话,你可以在(O(n))时间内处理出(h)数组。
现在我们定义一个(L)和(R)数组,(L[i])表示的是最小的(j)使得(j<i)并且(LCP(i,j)>=height[i]),(R[i])表示的就是最大的(j)了,这里不再赘述。
我们可以用单调栈实现(O(n))处理,然后我们就可以得出每个子串的最大出现次数就是(R[i]-L[i]+1),当然,还不够,我们还要从上到下,把上面的(ans)给下面的(ans)做个比较和更新。
这题没打代码,代码采用机房大佬ljy的。(他就是那个D爆我的倍增大佬。)
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <cstring>
#define maxn 250005
#define inf 0x3f3f3f3f
#define pn putchar('
')
#define px(x) putchar(x)
#define ps putchar(' ')
#define pd puts("======================")
#define pj puts("++++++++++++++++++++++")
//看看行不行
using namespace std;
inline int read(){
int x=0,y=0;
char ch=getchar();
while(ch<'0'||ch>'9'){if(ch=='-')y=1;ch=getchar();}
while(ch>='0'&&ch<='9')x=(x<<1)+(x<<3)+(ch^48),ch=getchar();
return y?-x:x;
}
int sa[maxn],rk[maxn],hei[maxn],tp[maxn],tax[maxn],ll[maxn],rr[maxn],ans[maxn],n,m;
char s[maxn];
struct MonoStack{
int sta[maxn],top;
inline void push(int x){
while(top>1&&hei[sta[top]]>=hei[x])--top;
sta[++top]=x;
}
inline int back(){
return sta[top-1];
}
inline void clear(){
top=0;
}
}st;//单调栈
void Rsort(){
for(register int i=0;i<=m;++i)tax[i]=0;
for(register int i=1;i<=n;++i)++tax[rk[i]];
for(register int i=1;i<=m;++i)tax[i]+=tax[i-1];
for(register int i=n;i;--i)sa[tax[rk[tp[i]]]--]=tp[i];
}
void Ssort(){//倍增
for(register int i=1;i<=n;++i)rk[i]=s[i],tp[i]=i;
m=225,Rsort();
for(register int k=1,p=0;p<n;m=p,k<<=1){
p=0;
for(register int i=1;i<=k;++i)tp[++p]=n-k+i;
for(register int i=1;i<=n;++i)if(sa[i]>k)tp[++p]=sa[i]-k;
Rsort();
for(register int i=1;i<=n;++i)tp[i]=rk[i];
rk[sa[1]]=p=1;
for(register int i=2;i<=n;++i)
rk[sa[i]]=tp[sa[i]]==tp[sa[i-1]]&&tp[sa[i]+k]==tp[sa[i-1]+k]?p:++p;
}
}
void get_height(){
int k=0,x;
for(register int i=1;i<=n;++i){
if(rk[i]==1)continue;
if(k)--k;
x=sa[rk[i]-1];
while(i+k<=n&&x+k<=n&&s[i+k]==s[x+k])++k;
hei[rk[i]]=k;
}
}
void solve(){
st.push(0);
for(register int i=1;i<=n;++i)
st.push(i),ll[i]=st.back()+1;//这里我也不知道为什么他+1,但是后面他+2了,就抵消了,这样会更好理解。
st.clear(),st.push(n+1);
for(register int i=n;i;--i)
st.push(i),rr[i]=st.back()-1;
for(register int i=1;i<=n;++i)
ans[hei[i]]=max(ans[hei[i]],rr[i]-ll[i]+2);//先只更新当前答案 ,比hei[i]小的下面做一个后缀最大值取到
ans[n+1]=1;//答案最少为1
for(register int i=n;i;--i)
ans[i]=max(ans[i],ans[i+1]);
for(register int i=1;i<=n;++i)
printf("%d
",ans[i]);
}
//sam是什么,不存在的,SA才是正解
int main(){
scanf("%s",s+1),n=strlen(s+1);
Ssort(),get_height(),solve();
}
练习4
黑题真不好惹,看题解都差点懵掉。。。
UPDATA: 后面A了,但是因为这里篇幅太大写了会卡,就不写了,换其他文章写。
广义后缀数组
也就是求多个字符串之间的SA,是不是觉得很困难?
其实不然。
两个串
方法
先把问题化简。
首先我们假设有两个字符串,(A,B),那么有人说是不是把两个串拼在一起?
首先,两个串之间要有一个性质。
设A的一个后缀为X,长度为x,设B的一个后缀为Y,长度为y。
当(min(x,y)=x)时,而且(LCP(X,Y)=x)。
那么,在比较(X[x+1],Y[x+1])时,因为X的(x+1)位已经没数字了,所以理所应当(X<Y),但是两个拼在一起后,(X[x+1]=B[1]),然后又会继续比较下去,这怎么行?
于是答案就出来了,不要简单的拼在一起,要添加一个比所有字符都小的字符在两个串中间。
那么两个串的就解决了。
例题
拼在一起后,求height,找最大。
#include<cstdio>
#include<cstring>
#define N 410000
#define NN 210000
using namespace std;
int lbsa[N],rbsa[N],sa[N];
char sstt[NN];int st[N];
bool type[N];int cs[NN];
int qwq[NN],num[N];
inline bool pd(bool type[],int p){return !type[p] && type[p-1];}
inline bool ccmp(int st[],bool type[],int q,int p)
{
do
{
if(st[q]!=st[p])return 1;
q++;p++;
}while(!pd(type,q) && !pd(type,p));
return (!pd(type,q) || !pd(type,p) || st[q]!=st[p]);
}
inline void isort(int sa[],int st[],bool type[],int cs[],int n,int m)
{
lbsa[0]=rbsa[0]=cs[0];for(int i=1;i<=m;i++)lbsa[i]=cs[i-1]+1,rbsa[i]=cs[i];
for(int i=1;i<=n;i++)
{
if(sa[i]>1 && type[sa[i]-1])sa[lbsa[st[sa[i]-1]]++]=sa[i]-1;
}
for(int i=n;i>=1;i--)
{
if(sa[i]>1 && !type[sa[i]-1])sa[rbsa[st[sa[i]-1]]--]=sa[i]-1;
}
}
void get_sa(int sa[],int st[],bool type[],int cs[],int qwq[],int num[],int n,int m)
{
for(int i=1;i<=n;i++)cs[st[i]]++;
rbsa[0]=cs[0];for(int i=1;i<=m;i++)rbsa[i]=cs[i]+=cs[i-1];
//cs,rbsa
for(int i=n-1;i>=1;i--)
{
if(st[i]>st[i+1])type[i]=1;
else if(st[i]==st[i+1])type[i]=type[i+1];
}
//type
int cnt=0;
for(int i=2;i<=n;i++)
{
if(pd(type,i))qwq[++cnt]=i,sa[rbsa[st[i]]--]=i;
}
//qwq,sa
isort(sa,st,type,cs,n,m);
//isort
int last=n,t=0;
for(int i=2;i<=n;i++)
{
if(!pd(type,sa[i]))continue;
if(ccmp(st,type,last,sa[i]))t++;
last=sa[i];num[last]=t;
}
//t,num
if(t<cnt-1)
{
for(int i=1;i<=cnt;i++)st[n+i]=num[qwq[i]];
get_sa(sa+n,st+n,type+n,cs+m+1,qwq+cnt,num+n,cnt,t);
}
else
{
for(int i=1;i<=cnt;i++)sa[n+num[qwq[i]]+1]=i;
}
memset(sa+1,0,(n<<2));
memcpy(rbsa,cs,(m<<2)+4);
for(int i=cnt;i>=1;i--)sa[rbsa[st[qwq[sa[n+i]]]]--]=qwq[sa[n+i]];
isort(sa,st,type,cs,n,m);
}
//长长的SA-IS
int he[NN],ra[NN];
void get_height(int n)
{
int j,k=0;
for(int i=1;i<n;i++)
{
j=sa[ra[i]-1];
if(k)k--;
while(st[i+k]==st[j+k])k++;
he[ra[i]]=k;
}
}
inline int mymax(int x,int y){return x>y?x:y;}
int main()
{
// freopen("a.in","r",stdin);
int n,n_n;
scanf("%s",sstt+1);n_n=strlen(sstt+1);
sstt[++n_n]='1';//添加比所有字母都小的字符
scanf("%s",sstt+1+n_n);n=strlen(sstt+1);
for(int i=1;i<=n;i++)st[i]=sstt[i];//拼接
n++;/*用SA-IS要添加一个比中间的字符还小的字符*/get_sa(sa,st,type,cs,qwq,num,n,130);
for(int i=1;i<=n;i++)ra[sa[i]]=i;
get_height(n);
int maxid=0;
for(int i=4;i<=n;i++)//sa[i]!=n_n或n,sa[i-1]!=n_n或n
{
if((sa[i]<n_n && sa[i-1]>n_n) || (sa[i]>n_n && sa[i-1]<n_n))maxid=mymax(maxid,he[i]);
}
printf("%d
",maxid);
return 0;
}
多个串
点拨一下
不就是继续拼在一起,每个串之间添加一个在串中比所有字符都小的字符,不过需要注意,添加的字符不能有一个相等,不然在求height的时候很有可能原地爆炸!!!
例题
你没有看错!例题!
这道题目,合并,然后跑一遍SA-IS,求height,然后二分,当然,别忘了特判(n=1)的情况。
因为当(n=1)的时候,所有的区间都刚好包含一个,然后就输出了这个字符串的所有后缀,但是在(n>1)时,不用担心两个后缀的长度不够,然后还被输出,因为有添加的点的限制导致两个后缀的长度如果不够,他们的height也不会长到到了其他字符串那里去。
#include<cstdio>
#include<cstring>
#define N 210000
#define NN 110000
using namespace std;
int lbsa[NN],rbsa[NN],sa[N];
char sstt[1100];int st[N];
bool type[N];int cs[NN];
int qwq[NN],num[N];
int belong[NN],ti[210]/*ti[0]是时间戳*/;
int n/*有几个字符串*/;
inline int mymax(int x,int y){return x>y?x:y;}
inline bool pd(bool type[],int p){return !type[p] && type[p-1];}
inline bool ccmp(int st[],bool type[],int q,int p)
{
do
{
if(st[q]!=st[p])return 1;
q++;p++;
}while(!pd(type,p) && !pd(type,q));
return (!pd(type,p) || !pd(type,q) || st[q]!=st[p]);
}
inline void isort(int sa[],int st[],bool type[],int cs[],int n,int m)
{
lbsa[0]=rbsa[0]=cs[0];for(int i=1;i<=m;i++)lbsa[i]=cs[i-1]+1,rbsa[i]=cs[i];
for(int i=1;i<=n;i++)
{
if(sa[i]>1 && type[sa[i]-1])sa[lbsa[st[sa[i]-1]]++]=sa[i]-1;
}
for(int i=n;i>=1;i--)
{
if(sa[i]>1 && !type[sa[i]-1])sa[rbsa[st[sa[i]-1]]--]=sa[i]-1;
}
}
void get_sa(int sa[],int st[],bool type[],int cs[],int qwq[],int num[],int n,int m)
{
for(int i=1;i<=n;i++)cs[st[i]]++;
rbsa[0]=cs[0];for(int i=1;i<=m;i++)rbsa[i]=cs[i]+=cs[i-1];
//rbsa,cs
type[n]=0;
for(int i=n-1;i>=1;i--)
{
if(st[i]>st[i+1])type[i]=1;
else if(st[i]<st[i+1])type[i]=0;
else type[i]=type[i+1];
}
//type
int cnt=0;
for(int i=2;i<=n;i++)
{
if(pd(type,i))qwq[++cnt]=i,sa[rbsa[st[i]]--]=i;
}
//qwq,sa
isort(sa,st,type,cs,n,m);
//isort
int t=0,last=n;num[n]=0;
for(int i=2;i<=n;i++)
{
if(!pd(type,sa[i]))continue;
if(ccmp(st,type,last,sa[i]))t++;
last=sa[i];num[last]=t;
}
//last,t
if(t<cnt-1)
{
for(int i=1;i<=cnt;i++)st[n+i]=num[qwq[i]];
get_sa(sa+n,st+n,type+n,cs+m+1,qwq+cnt,num+n,cnt,t);
}
else
{
for(int i=1;i<=cnt;i++)sa[n+num[qwq[i]]+1]=i;
}
memset(sa,0,(n<<2));
memcpy(rbsa,cs,(m<<2)+4);
for(int i=cnt;i>=1;i--)sa[rbsa[st[qwq[sa[n+i]]]]--]=qwq[sa[n+i]];
isort(sa,st,type,cs,n,m);
}
int ra[NN],he[NN];
void get_he(int n)
{
int j,k=0;
for(int i=1;i<n;i++)//省去最后一个
{
j=sa[ra[i]-1];
if(k)k--;
while(st[i+k]==st[j+k])k++;
he[ra[i]]=k;
}
}
bool check(int n,int m,int x)//二分判断函数
{
he[++n]=0;belong[n]=0;
int maxid=0;
for(int i=1/*1是用来更新时间戳的*/;i<=n;i++)
{
if(he[i]>=x)
{
if(ti[belong[sa[i]]]!=ti[0])
{
maxid++;ti[belong[sa[i]]]=ti[0];
}
}
else
{
if(maxid>=m)return 1;
ti[0]++;
if(belong[sa[i]]!=0)
{
maxid=1;
ti[belong[sa[i]]]=ti[0];
}
else maxid=0;
}
}
return 0;
}
int main()
{
// freopen("a.in","r",stdin);
// freopen("a.out","w",stdout);
int len=0;
while(scanf("%d",&n)!=EOF && n)
{
int l=1,r=0,mid,ans=0;
len=0;
memset(sa,0,sizeof(sa));
memset(cs,0,sizeof(cs));
for(int i=1;i<=n;i++)
{
scanf("%s",sstt+1);
int x=strlen(sstt+1);r=mymax(r,x);
for(int j=1;j<=x;j++)
{
st[++len]=sstt[j]-'a'+n;
belong[len]=i;
}
st[++len]=n-i;belong[len]=0;
}//合并字符串
if(n==1)//特判
{
printf("%s
",sstt+1);
continue;
}
get_sa(sa,st,type,cs,qwq,num,len,n+25/*n+26-1*/);
for(int i=1;i<=len;i++)ra[sa[i]]=i;
get_he(len);
//SA的基本操作
while(l<=r)//二分
{
mid=(l+r)/2;
if(check(len,(n/2+1),mid))ans=mid,l=mid+1;
else r=mid-1;
}
if(ans==0)printf("?
");
else
{
//找出所有的字符串,再跑一遍。
int maxid=0;
for(int i=1/*1是用来更新时间戳的*/;i<=len+1;i++)
{
if(he[i]>=ans)
{
if(ti[belong[sa[i]]]!=ti[0])
{
maxid++;ti[belong[sa[i]]]=ti[0];
}
}
else
{
if(maxid>=(n/2+1))
{
for(int j=1;j<=ans;j++)printf("%c",st[sa[i-1]+j-1]-n+'a');
printf("
");
}
ti[0]++;
if(belong[sa[i]]!=0)
{
maxid=1;
ti[belong[sa[i]]]=ti[0];
}
else maxid=0;
}
}
}
printf("
");
}
return 0;
}
后缀数组与广义后缀数组总结
其实一般的后缀数组的题目就是利用height数组进行求值,比较常见的有二分答案,当然优秀的拆分用到了贪心。
树上后缀数组
例题与导言
题目描述:
CJB来到HZ王国旅游。HZ王国给CJB留下了深刻的印象,特别是HZ王国的道路系统。HZ王国有N个城市,编号从1到N。其中,城市1为HZ王国的首都。这N个城市由N-1条无向道路来连接。虽然只有这么少路,但任意两个城市都可以互相到达。
每个城市都有一座标志性的建筑(比如广州塔、东方明珠),站在上面可以看到这座城市有多少条道路与它连接。如果与城市A连接的道路数量等于与城市B连接的道路数量,站在高处看A城市和B城市就没什么区别了,我们就认为城市A与城市B是相似的。
有一天,CJB又想旅游了,于是开始规划旅行线路。他选择了两座城市A和城市B,满足城市B在城市A和首都的最短路径上。然后,CJB会从城市A沿着最短路径走到B。注:A可以等于B,这意味着CJB只在一座城市旅游。
CJB不想有相似的旅行线路。两条旅行线路是相似的当且仅当他们经过相同的城市数量且对于任意的i,一条旅行线路经过的第i座城市与另一条旅行线路经过的第i座城市是相似的。
CJB想让你给他找一个最大的旅行线路的集合,使得集合内任意两条旅行线路都不相似。由于这个集合可能很大,你只需要告诉他集合的大小即可。
N<=500000
解题思路:
将度数看成字符,则任意节点到根的路径都是一个字符串,且可行路径为这些字符串的子串。问题等价于求N个字符串中不同的子串个数。与后缀数组的求法类似,建立树上后缀数组。那么答案即所有字符串的长度和减去相邻两个排名的字符串的LCP。时间复杂度 O(nlogn) ,可以通过所有数据。
那么树上后缀数组怎么构建?height怎么求?这是个问题。
构建树上后缀数组思想
就是因为树上后缀数组,让我被大佬嘲笑了好久。Why?
树上后缀数组只能用倍增做!Why?
然后,我就开始了被嘲讽的学习生涯。
--摘自《作者的痛苦生涯》
那么,具体怎么做呢?
首先,考虑普通倍增的过程:先求一个字符的排序,然后两个字符合并,然后四个字符合并。
那么后缀数组也是一样,先算每一个字符的排序,然后两个字符合并,然后四个字符合并。不过不大一样的是普通倍增是找后面第一个字符合并,再找后面第二个字符合并...,而树上就是找父亲了,那么我们看合并跳的父亲的层数:(1,2,4,8...),那我们只需要预处理出每个点的第一个父亲,第二个父亲...,然后正常倍增算法拍一遍就行了,只不过需要改一点代码。
构建height
有一个十分凉凉的事情,希望大家振作,没有(h[i]≥h[i-1]-1)了。。。
Hash
那么,我们考虑(O(nlogn))的做法,考虑预处理每个点自己的Hash值,自己到父亲的Hash,自己到第三个父亲的Hash...
然后(O(nlogn))找一遍。
波兰表
大家别在意标题,我只是不想被大佬Diss,毕竟我太菜了QAQ。
说到底,波兰表就是把SA中的rank数组记录下来。
什么意思,在倍增中,第一次合并两个字符,第二次合并四个字符,那如果两个点在第一次的rank相等的话,代表以他为开头的两个字符相等,以此类推,为了节省代码,一个字符的就特判,不计入数组当中。
然后像Hash一样找一遍,我个人比较喜欢波兰表,毕竟比Hash安全,速度也差不多(找波兰表的代码可融入倍增中)。
代码
没错,就是这么暴力,不过希望学会了树上后缀树到的同学能不能告诉我时间复杂度,是不是也是(O(nlogn))
#include<cstdio>
#include<cstring>
#include<algorithm>
#define N 110000
#define NN 210000
using namespace std;
inline int mymax(int x,int y){return x>y?x:y;}
inline int mymin(int x,int y){return x<y?x:y;}
struct bian
{
int y,next;
}a[NN];int len,last[N];
struct dian
{
int rd/*入度*/,pa[20]/*父亲数组*/,bo[20]/*波兰表*/,dep;
}tr[N];int maxdep;
int sa[N],xx[N],yy[N],cs[N];
int depcnt;
char st[N];
long long ans,he[N];
int n,m;
inline void ins(int x,int y){len++;a[len].y=y;a[len].next=last[x];last[x]=len;tr[y].rd++;}
void dfs(int x)
{
maxdep=mymax(maxdep,tr[x].dep);//优化
ans+=tr[x].dep;
for(int i=1;i<=18;i++)tr[x].pa[i]=tr[tr[x].pa[i-1]].pa[i-1];//父亲
for(int k=last[x];k;k=a[k].next)
{
int y=a[k].y;
if(tr[x].pa[0]!=y)
{
tr[y].pa[0]=x;tr[y].dep=tr[x].dep+1;
dfs(y);
}
}
}
//遍历
void get_SA()
{
for(int i=1;i<=n;i++)cs[xx[i]=tr[i].rd]++;
for(int i=2;i<=m;i++)cs[i]+=cs[i-1];
for(int i=1;i<=n;i++)sa[cs[xx[i]]--]=i;
for(depcnt=0;(1<<depcnt)+1<=maxdep/*可能存在两个相同的字符串!*/;depcnt++)
{
memset(cs+1,0,(m<<2));
for(int i=1;i<=n;i++)cs[xx[tr[i].pa[depcnt]]]++;
for(int i=1;i<=m;i++)cs[i]+=cs[i-1];//有可能父母为0!
for(int i=1;i<=n;i++)yy[cs[xx[tr[i].pa[depcnt]]]--]=i;
//yy关键字的排序,与原本的yy关键字排序不大一样
memset(cs+1,0,(m<<2));//cs[0]在--的时候就归0了,这样打代码容易记
for(int i=1;i<=n;i++)cs[xx[i]]++;
for(int i=2;i<=m;i++)cs[i]+=cs[i-1];
for(int i=n/*重点,到这搜*/;i>=1;i--)sa[cs[xx[yy[i]]]--]=yy[i];//重点,这里我不知漏打了多少次了
//xx关键字
swap(xx,yy);
int num=tr[sa[1]].bo[depcnt]=xx[sa[1]]=1;
for(int i=2;i<=n;i++)
{
xx[sa[i]]=(yy[sa[i]]==yy[sa[i-1]] && yy[tr[sa[i]].pa[depcnt]]==yy[tr[sa[i-1]].pa[depcnt]])?num:++num;
tr[sa[i]].bo[depcnt]=num;//波兰表
}
if(n==num)break;//优化
m=num;
}
}
void get_he()
{
for(int i=2;i<=n;i++)
{
//像二进制一样找出每个height
int x=sa[i],y=sa[i-1];
for(int j=depcnt;j>=0;j--)
{
if(mymin(tr[x].dep,tr[y].dep)>=(1<<(j+1)))//保证层数要够
{
if(tr[x].bo[j]==tr[y].bo[j])
{
he[i]+=(1<<(j+1));//第j轮合并(1<<(j+1))个字符
x=tr[x].pa[j+1];y=tr[y].pa[j+1];//继续跳
}
}
}
if(tr[x].rd==tr[y].rd && x/*特判x!=0*/)he[i]++;//特判
ans-=he[i];
}
}
int main()
{
scanf("%d",&n);
for(int i=1;i<n;i++)
{
int x,y;scanf("%d%d",&x,&y);
ins(x,y);ins(y,x);
}
tr[1].dep=1;dfs(1);
for(int i=1;i<=n;i++)m=mymax(m,tr[i].rd);//处理m
get_SA();
get_he();
printf("%lld
",ans);
return 0;
}
不容易,不容易!QAQ,这道题目真的不容易。
总结
后缀数组是个好东西!