Python模块
-
认识模块
-
常用模块一:
collections模块
时间模块
random模块
os模块
sys模块
序列化模块
re模块
-
常用模块二:
hashlib模块
hmac模块
configparse模块
logging模块
一、认识模块
1.什么是模块?
常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀;
使用import加载的模块分为四个通用类别:
a.使用python编写的代码(.py文件) b.已被编译为共享库或dll的C或C++扩展
c.包好一组模块的包 d.使用C编写并链接到python解释器的内置模块
使用模块的好处:
如果我们退出python解释器然后重新进入,那么之前定义的函数或是变量都将丢失,因此我们通常将程序写到文件中以便永久保存下来,需要时就通过命令行方式去运行,此时*.py就被称作脚本script。
随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结果更清晰,方便管理,这时我们不仅仅可以把这些文件当做脚本去执行,还可以把它们当做模块来导入到其他的模块中,实现功能的重复利用。
2.模块的导入和使用
模块的导入应在程序开始的地方;
http://www.cnblogs.com/Eva-J/articles/7292109.html此处先放置一个链接;
二、常用模块一
1.collections模块
2.时间模块(time)
说明:顾名思义,时间模块就是用来解决一些和时间相关的问题,在使用时间模块前,我们应该先将此模块导入到命名空间中;
名称:time
表示时间的三种方式:
1)时间戳时间(timestamp)
说明:时间戳指的是从1970年1月1号的00:00:00开始按秒计算的偏移量;
类型:浮点型;
查看:time.time() #表示当前的时间戳;


>>> import time #导入time模块 >>> time.time() #查看当前时间戳 1534750110.050263 >>> print(type(time.time())) 查看时间戳的数据类型 <class 'float'>
2)格式化时间(Format String)
说明:将当前的时间进行格式化输出一方便用户阅读效果;
类型:字符串;
查看:time.strftime(n) #表示以格式化方式输出时间;
参数:n ------> 表示自定义输出格式,比如:“%Y-%m-%d”、“%Y/%m/%d %H:%M:%S”等等之类的
>>> import time #导入time模块 >>> time.strftime("%Y-%m-%d %H:%M:%S") #根据定义格式进行输出 '2018-08-20 15:33:47' >>> print(type(time.strftime("%Y-%m-%d %H:%M:%S"))) #查看格式化时间的类型 <class 'str'>
%y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身
3)结构化时间(struct_time)
说明:结构化时间会输出一个元组,元组中共有9个元素(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
类型:<class 'time.struct_time'>;由元组组成;
查看:time.localtime #localtime是以结构化方式查看本地时间,此处还有一个gmtime是以结构化方式查看伦敦时间;
元组中的元素类说明:
| 索引(Index) | 属性(Attribute) | 值(Values) |
|---|---|---|
| 0 | tm_year(年) | 比如2011 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 60 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为0 |
>>> print(type(time.localtime())) #查看结构化时间的数据类型 <class 'time.struct_time'> >>> print(time.localtime()) #查看结构化时间 time.struct_time(tm_year=2018, tm_mon=8, tm_mday=20, tm_hour=15, tm_min=48, tm_sec=7, tm_wday=0, tm_yday=232, tm_isdst=0)
小结:时间戳是计算机能够识别的时间;时间字符串是人能够看懂的时间;元组则是用来操作时间的
几种时间格式之间的转化:
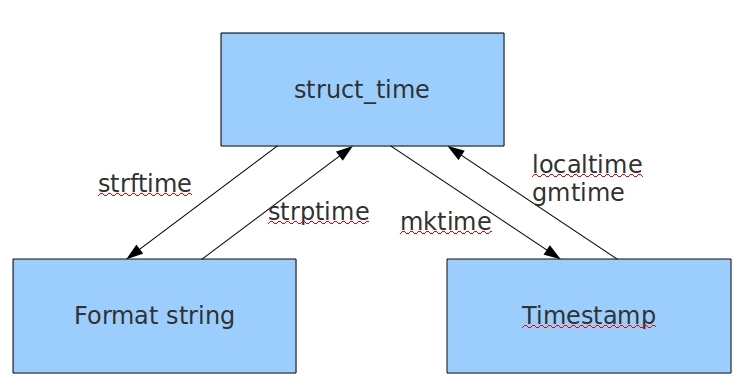
由上图我们可知,结构化时间起着一个中间桥梁的作用,当格式化时间和时间戳时间相互转换时必须先转换成结构化时间;
接下来我们就进行这几种类型的转换:
a.时间戳和结构化之间的相互转换;
# 时间戳 ----------> 结构化时间 #time模块有两个方法进行转换;time.gmtime(时间戳)、time.localtime(时间戳) #time.gmtime(时间戳),UTC时间,与英国伦敦当地时间一致 #time.localtime(时间戳),当地时间。例如我们现在在北京执行这个方法:与UTC时间相差8小时,UTC时间+8小时 = 北京时间 ------------------------------下面开始转换--------------------------------------- >>> import time #导入时间模块 >>> time.gmtime(1500000000) #使用UTC时间转换 time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=2, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) >>> time.localtime(1500000000) #使用本地时间转换 time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) #可以看出伦敦时间和北京时间相差了8个小时; # 结构化时间 -----------> 时间戳时间 >>> struce_time = time.localtime(time.time()) #先将时间转换为结构化时间 >>> time.mktime(struce_time) #再将结构化时间转换为时间戳时间 1534752087.0
b.格式化和结构化之间的相互转换:
# 结构化 ---------> 格式化时间 #time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则显示当前时间 --------------------------- 例子 ------------------------------------------------- >>> import time >>> time.strftime("%F %H:%M:%S") '2018-08-20 16:05:04' >>> time.strftime("%Y-%m-%d",time.localtime()) '2018-08-20' # 格式化 ----------> 结构化时间 #time.strptime(时间字符串,字符串对应格式) ------------------------------ 例子 ---------------------------------------------- >>> time.strptime("2018-08-20","%Y-%m-%d") time.struct_time(tm_year=2018, tm_mon=8, tm_mday=20, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=232, tm_isdst=-1) >>>time.strptime("07/24/2017","%m/%d/%Y") time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=205, tm_isdst=-1)
3.random模块
说明:这是一个取随机数模块,用来产生随机数;
名称:random
random有四种基本方式:
1)取随机小数;
random.random()
说明:取0-1之间的小数;
>>> import random >>> print(random.random()) 0.3569863449931081
random.uniform(n,m)
说明:取指定范围内的小数
>>> print(random.uniform(5,8)) 6.6214335271284135
2)取随机整数;
random.randint(n,m)
说明:取指定范围内的整数,取值包括n,m,相当于[n,m]
>>> print(random.randint(5,8)) 8
random.randrange(n,m,s)
说明:由range生成一些数,在这些数中取随机数,取值包括n,不包括m,相当于[n,m);s表示的是步长,先由range生成数字,然后在用random取;
>>> print(random.randrange(6)) 1 >>> print(random.randrange(2,6,2)) 4 >>> print(random.randrange(2,6,2)) 2 >>> print(random.randrange(2,6,2)) 4
3)从一个列表或字符串元组等等有长度(len)的数据类型中随机抽取值;
random.choice(n)
说明:从字符串或列表或元组等有索引的数据类型中取一个值,只取1个值;不支持集合、字典、数字;
参数:n ------- > 指定字符串或列表或元组等有索引的数据类型
>>> print(random.choice("zjksldfjl")) z >>> print(random.choice("zjksldfjl")) l >>> print(random.choice([1,"zjk",8,False])) False >>> print(random.choice([1,"zjk",8,False])) False >>> print(random.choice([1,"zjk",8,False])) 1 >>> print(random.choice([1,"zjk",8,False])) zjk >>> print(random.choice((1,"zjk",8,False))) 8
random.sample(n,c)
说明:从字符串或列表或元组等有索引的数据类型中一次取多个值;不支持集合、字典、数字;
参数:n ---------> 指定数据; c -----------> 指定一次取多值的个数
返回值:返回的是一个列表;
>>> print(random.sample([1,2,"zjk","A"],3)) ['zjk', 'A', 1]
4)打乱一个列表的顺序,在原列表的基础上直接进行修改,节省空间;
random.shuffle(list)
说明:打乱一个列表的顺序,在原列表的基础上直接进行修改,节省空间;
参数:list --------> 使用列表数据类型;
>>> li = [1,2,3,4,5,6,7,8,9] >>> random.shuffle(li) >>> print(li) [1, 2, 5, 4, 6, 8, 7, 3, 9]
实例:
#使用for循环方式 >>> st = "" >>> for n in range(4): ... num = random.randint(0,9) ... st += str(num) ... >>> print(st) 1084 # 函数版 >>> def func(n=6): ... st = "" ... for i in range(n): ... num = random.randint(0,9) ... st += str(num) ... return st ... >>> print(func()) 931404 >>> print(func(4)) 3780
#for循环方式 >>> st = "" >>> for i in range(6): ... num = str(random.randint(0,9)) ... alpha_upper = chr(random.randint(65,90)) ... alpha_lower = chr(random.randint(97,122)) ... res = random.choice([num,alpha_upper,alpha_lower]) ... st += res ... >>> print(st) KO0SnR # 函数升级版 >>> import random >>> >>> def func(n=6,alpha=True): ... st = "" ... for i in range(n): ... num = str(random.randint(0,9)) ... if alpha: ... alpha_upper = chr(random.randint(65,90)) ... alpha_lower = chr(random.randint(97,122)) ... num = random.choice([num,alpha_upper,alpha_lower]) ... st += num ... return st ... >>> print(func(4)) HI1H >>> print(func(8)) 05S7rqm3 >>> print(func(8,False)) 46654230 >>> print(func(8,False)) 09328134
4.os模块
说明:os模块是与操作系统交互的一个借口,
名称:os
os模块基本用途:
1)文件的操作;
os.mkdir(dirname)
# 创建一个空目录;
os.makedirs(dirname1/diename2..)
# 递归创建目录
os.rmdir(dirname)
# 删除一个空目录,若目录不为空则无法删除,报错;
os.removedirs(dirname)
# 递归删除空目录,如果目录为空,则删除,并递归到上一级目录,如果上一级目录也为空,则也删除,一次类推;
os.listdir(dirname)
# 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式进行打印;
os.remove(file)
# 删除一个文件file
os.rename(oldname,newname)
# 文件或目录重命名
os.stat(filename)
# 获取文件/目录信息
stat 结构: st_mode: inode 保护模式 st_ino: inode 节点号。 st_dev: inode 驻留的设备。 st_nlink: inode 的链接数。 st_uid: 所有者的用户ID。 st_gid: 所有者的组ID。 st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。 st_atime: 上次访问的时间。 st_mtime: 最后一次修改的时间。 st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。
2)调用系统shell类
os.system(bash command)
# 调用系统shell,有系统shell去执行;
os.popen(bash command).read()
#调用系统shell,由系统shell去执行,并将执行结果返回给python;
os.getcwd()
#获取当前所在目录,相当于pwd;
os.chdir(dirname)
# 切换当前所在的目录,相当于cd;
3)系统路径类(os.path)
os.path.abspath(path)
#返回path规范化的绝对路径,os.path.split(path) 将path分割成目录和文件名二元组返回;
os.path.dirname(path)
# 返回path的目录。其实就是os.path.split(path)的第一个元素,也就是返回该文件的目录;
os.path.basename(path)
# 返回path的文件名,其实就是返回该文件的文件名;如果这是一个目录,则返回空值;
os.path.exists(path)
# 如果文件路径存在则返回True,否则返回False
os.path.isabs(path)
# 如果该文件是绝对路径,则返回True,否则返回False;
os.path.isfile(path)
#如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path)
# 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]])
# 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略,此用法会自动区分操作系统,因为不同的操作系统,路径分隔符也不同;
os.path.getatime(path)
# 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path)
# 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path)
# 返回path的大小
os.path.split(path)
#把一个路径分成两段,第一段是目录,第二段是一个文件或目录
def func(path): # r'D:sylars15' size_sum = 0 name_lst = os.listdir(path) for name in name_lst: path_abs = os.path.join(path,name) if os.path.isdir(path_abs): size = func(path_abs) size_sum += size else: size_sum += os.path.getsize(path_abs) return size_sum ret = func(r'D:sylars15') print(ret)
思路:循环,堆栈思想。列表 满足一个顺序 先进来的后出去
lst = [r'D:sylars15',] # 列表的第一个目录就是我要统计的目录 size_sum = 0 while lst: # [r'D:sylars15',] lst = ['D:sylars15day01','D:sylars15day01'..] path = lst.pop() # path = 'D:sylars15' lst = [] path_list = os.listdir(path) # path_list = ['day01',day02',aaa,day15.py] for name in path_list: # name = day01 abs_path = os.path.join(path,name) if os.path.isdir(abs_path): # 文件夹的逻辑 lst.append(abs_path) # lst.append('D:sylars15day01') lst = ['D:sylars15day01'] else: size_sum += os.path.getsize(abs_path) print(size_sum)
os.sep 输出操作系统特定的路径分隔符,win下为"\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为" ",Linux下为" " os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为: os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
5.sys模块
说明:sys模块是与python解释器交互的一个接口;
名称:sys
sys模块的几个常用方法:
sys.argv[num]
# 用来接收命令行参数;num是数字;0表示当前脚本的位置,1表示传入的第一个参数;2表示传入的第2个参数;依次类推;
sys.exit(obj)
# 退出程序,正常退出时exit(0),错误退出sys.exit(1),obj也可以自定义,退出时显示obj;
sys.version
# 获取Python解释程序的版本信息
sys.path
# 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值;
sys.platform
# 返回操作系统平台名称
6.序列化模块
说明:将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化;
有两个模块:json pickle
比如,我们在python代码中计算的一个数据需要给另外一段程序使用,那我们怎么给? 现在我们能想到的方法就是存在文件里,然后另一个python程序再从文件里读出来。 但是我们都知道,对于文件来说是没有字典这个概念的,所以我们只能将数据转换成字典放到文件中。 你一定会问,将字典转换成一个字符串很简单,就是str(dic)就可以办到了,为什么我们还要学习序列化模块呢? 没错序列化的过程就是从dic 变成str(dic)的过程。现在你可以通过str(dic),将一个名为dic的字典转换成一个字符串, 但是你要怎么把一个字符串转换成字典呢? 聪明的你肯定想到了eval(),如果我们将一个字符串类型的字典str_dic传给eval,就会得到一个返回的字典类型了。 eval()函数十分强大,但是eval是做什么的?e官方demo解释为:将字符串str当成有效的表达式来求值并返回计算结果。 BUT!强大的函数有代价。安全性是其最大的缺点。 想象一下,如果我们从文件中读出的不是一个数据结构,而是一句"删除文件"类似的破坏性语句,那么后果实在不堪设设想。 而使用eval就要担这个风险。 所以,我们并不推荐用eval方法来进行反序列化操作(将str转换成python中的数据结构)
#能够在网络上传输的只能是bytes, #能够存储在文件里的只有bytes和str
目的:a.以某种存储形式使自定义对象持久化;
b.将对象从一个地方传递到另一个地方;
c.使程序更具维护性;

6.1 json
说明:json模块提供了四个功能:dumps、dump、loads、load
只支持:列表、数字、字符串、bytes的类型
import json dic = {'k1':'v1','k2':'v2','k3':'v3'} str_dic = json.dumps(dic) #序列化:将一个字典转换成一个字符串 print(type(str_dic),str_dic) #<class 'str'> {"k3": "v3", "k1": "v1", "k2": "v2"} #注意,json转换完的字符串类型的字典中的字符串是由""表示的 dic2 = json.loads(str_dic) #反序列化:将一个字符串格式的字典转换成一个字典 #注意,要用json的loads功能处理的字符串类型的字典中的字符串必须由""表示 print(type(dic2),dic2) #<class 'dict'> {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'} list_dic = [1,['a','b','c'],3,{'k1':'v1','k2':'v2'}] str_dic = json.dumps(list_dic) #也可以处理嵌套的数据类型 print(type(str_dic),str_dic) #<class 'str'> [1, ["a", "b", "c"], 3, {"k1": "v1", "k2": "v2"}] list_dic2 = json.loads(str_dic) print(type(list_dic2),list_dic2) #<class 'list'> [1, ['a', 'b', 'c'], 3, {'k1': 'v1', 'k2': 'v2'}]
import json f = open('json_file','w') dic = {'k1':'v1','k2':'v2','k3':'v3'} json.dump(dic,f) #dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件 f.close() f = open('json_file') dic2 = json.load(f) #load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回 f.close() print(type(dic2),dic2)
import json f = open('file','w') json.dump({'国籍':'中国'},f) ret = json.dumps({'国籍':'中国'}) f.write(ret+' ') json.dump({'国籍':'美国'},f,ensure_ascii=False) ret = json.dumps({'国籍':'美国'},ensure_ascii=False) f.write(ret+' ') f.close()
Serialize obj to a JSON formatted str.(字符串表示的json对象) Skipkeys:默认值是False,如果dict的keys内的数据不是python的基本类型(str,unicode,int,long,float,bool,None),设置为False时,就会报TypeError的错误。此时设置成True,则会跳过这类key ensure_ascii:,当它为True的时候,所有非ASCII码字符显示为uXXXX序列,只需在dump时将ensure_ascii设置为False即可,此时存入json的中文即可正常显示。) If check_circular is false, then the circular reference check for container types will be skipped and a circular reference will result in an OverflowError (or worse). If allow_nan is false, then it will be a ValueError to serialize out of range float values (nan, inf, -inf) in strict compliance of the JSON specification, instead of using the JavaScript equivalents (NaN, Infinity, -Infinity). indent:应该是一个非负的整型,如果是0就是顶格分行显示,如果为空就是一行最紧凑显示,否则会换行且按照indent的数值显示前面的空白分行显示,这样打印出来的json数据也叫pretty-printed json separators:分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就是(‘,’,’:’);这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。 default(obj) is a function that should return a serializable version of obj or raise TypeError. The default simply raises TypeError. sort_keys:将数据根据keys的值进行排序。 To use a custom JSONEncoder subclass (e.g. one that overrides the .default() method to serialize additional types), specify it with the cls kwarg; otherwise JSONEncoder is used.
import json data = {'username':['李华','二愣子'],'sex':'male','age':16} json_dic2 = json.dumps(data,sort_keys=True,indent=2,separators=(',',':'),ensure_ascii=False) print(json_dic2)
6.2 pickle
说明:支持在python中几乎所有的数据类型;
注意:dumps 序列化的结果只能是字节;只能在python中使用;在和文件操作的时候,需要用rb wb的模式打开文件;可以多次dump 和 多次load
ith open('pickle_file','rb') as f: while True: try: ret = pickle.load(f) print(ret,type(ret)) except EOFError: break
三、常用模块二:
1.hashlib
说明:用于加密相关的操作,代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法;
注意:字符串字加密时需要转换成字节形式才可以加密;
一旦加密形成密文后是无法解密的,尤其是自定义key更是无法解密,所以在进行验证用户时,可以对用户输入的密码进行加密然后和数据库里的密文进行比较,一致的话说明密码是正确的。
import md5 hash = md5.new() hash.update('admin') print hash.hexdigest()
import sha hash = sha.new() hash.update('admin') print hash.hexdigest()
import hashlib # ######## md5 ######## hash = hashlib.md5() hash.update('admin'.encode('utf-8')) print(hash.hexdigest()) # ######## sha1 ######## hash = hashlib.sha1() hash.update('admin'.encode('utf-8')) print(hash.hexdigest()) # ######## sha256 ######## hash = hashlib.sha256() hash.update('admin'.encode('utf-8')) print(hash.hexdigest()) # ######## sha384 ######## hash = hashlib.sha384() hash.update('admin'.encode('utf-8')) print(hash.hexdigest()) # ######## sha512 ######## hash = hashlib.sha512() hash.update('admin'.encode('utf-8')) print(hash.hexdigest())
以上加密算法虽然依然非常厉害,但时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密。
就是在hashlib.算法(key),括号里加key,这个key也是一个字节形式,比如:b'2erer3a',
import hashlib #注意:admin 加密后就是c5395258d82599e5f1bec3be1e4dea4a SALT = b'2erer3asdfwerxdf34sdfsdfs90' #固定一个key,切记不能修改或泄露此key, def md5(pwd): # 实例化对象 obj = hashlib.md5(SALT) # 写入要加密的字节 obj.update(pwd.encode('utf-8')) # 获取密文 return obj.hexdigest() user = input("请输入用户名:") pwd = input("请输入密码:") if user == 'zjk' and md5(pwd) == 'c5395258d82599e5f1bec3be1e4dea4a': print('登录成功') else: print('登录失败') ------------------ 打印输出 ---------------------------------------------- 请输入用户名:zjk 请输入密码:admin 登录成功
2.hmac模块
hashlib不够强大??python 还有一个 hmac 模块。
说明:该模块加密是先把数据存储到字典中,然后再进行加密,方法与上述方法类似。
首先需要准备待计算的原始消息message,随机key,哈希算法,这里采用MD5;
import hmac message = b'Hello world' key = b'secret' h = hmac.new(key,message,digestmod='MD5') print(h.hexdigest())
可见使用hmac和普通hash算法非常类似。hmac输出的长度和原始哈希算法的长度一致。需要注意传入的key和message都是bytes类型,str类型需要首先编码为bytes。
def hmac_md5(key, s): return hmac.new(key.encode('utf-8'), s.encode('utf-8'), 'MD5').hexdigest() class User(object): def __init__(self, username, password): self.username = username self.key = ''.join([chr(random.randint(48, 122)) for i in range(20)]) self.password = hmac_md5(self.key, password)
3.logging模块
1)日志相关概念
日志是一种可以追踪某些软件运行时所发生事件的方法。软件开发人员可以向他们的代码中调用日志记录相关的方法来表明发生了某些事情。一个事件可以用一个可包含可选变量数据的消息来描述。此外,事件也有重要性的概念,这个重要性也可以被称为严重性级别(level)。
日志的作用
通过log的分析,可以方便用户了解系统或软件、应用的运行情况;如果你的应用log足够丰富,也可以分析以往用户的操作行为、类型喜好、地域分布或其他更多信息;如果一个应用的log同时也分了多个级别,那么可以很轻易地分析得到该应用的健康状况,及时发现问题并快速定位、解决问题,补救损失。
简单来讲就是,我们通过记录和分析日志可以了解一个系统或软件程序运行情况是否正常,也可以在应用程序出现故障时快速定位问题。比如,做运维的同学,在接收到报警或各种问题反馈后,进行问题排查时通常都会先去看各种日志,大部分问题都可以在日志中找到答案。再比如,做开发的同学,可以通过IDE控制台上输出的各种日志进行程序调试。对于运维老司机或者有经验的开发人员,可以快速的通过日志定位到问题的根源。可见,日志的重要性不可小觑。日志的作用可以简单总结为以下3点:
-
程序调试
-
了解软件程序运行情况,是否正常
-
软件程序运行故障分析与问题定位
日志的等级
在软件开发阶段或部署开发环境时,为了尽可能详细的查看应用程序的运行状态来保证上线后的稳定性,我们可能需要把该应用程序所有的运行日志全部记录下来进行分析,这是非常耗费机器性能的。当应用程序正式发布或在生产环境部署应用程序时,我们通常只需要记录应用程序的异常信息、错误信息等,这样既可以减小服务器的I/O压力,也可以避免我们在排查故障时被淹没在日志的海洋里。那么,怎样才能在不改动应用程序代码的情况下实现在不同的环境记录不同详细程度的日志呢?这就是日志等级的作用了,我们通过配置文件指定我们需要的日志等级就可以了。
不同的应用程序所定义的日志等级可能会有所差别,分的详细点的会包含以下几个等级:
| 级别 | 何时使用 | 数字表示 |
|---|---|---|
| DEBUG | 详细信息,典型地调试问题时会感兴趣。 详细的debug信息。 | 10 |
| INFO | 证明事情按预期工作。 关键事件。 | 20 |
| WARNING | 表明发生了一些意外,或者不久的将来会发生问题(如‘磁盘满了’)。软件还是在正常工作。 | 30 |
| ERROR | 由于更严重的问题,软件已不能执行一些功能了。 一般错误消息。 | 40 |
| CRITICAL | 严重错误,表明软件已不能继续运行了。 | 50 |
日志字段信息与日志格式
一条日志信息对应的是一个事件的发生,而一个事件通常需要包括以下几个内容:
-
事件发生时间
-
事件发生位置
-
事件的严重程度--日志级别
-
事件内容
上面这些都是一条日志记录中可能包含的字段信息,当然还可以包括一些其他信息,如进程ID、进程名称、线程ID、线程名称等。日志格式就是用来定义一条日志记录中包含那些字段的,且日志格式通常都是可以自定义的。
日志功能的实现
几乎所有开发语言都会内置日志相关功能,或者会有比较优秀的第三方库来提供日志操作功能,比如:log4j,log4php等。它们功能强大、使用简单。Python自身也提供了一个用于记录日志的标准库模块--logging。
2)logging模块
logging模块是Python内置的标准模块,主要用于输出运行日志,可以设置输出日志的等级、日志保存路径、日志文件回滚等;相比print,具备如下优点:
-
可以通过设置不同的日志等级,在release版本中只输出重要信息,而不必显示大量的调试信息;
-
print将所有信息都输出到标准输出中,严重影响开发者从标准输出中查看其它数据;logging则可以由开发者决定将信息输出到什么地方,以及怎么输出。
logging模块的日志级别
logging模块默认定义了以下几个日志等级,它允许开发人员自定义其他日志级别,但是这是不被推荐的,尤其是在开发供别人使用的库时,因为这会导致日志级别的混乱。
| 日志等级(level) | 描述 | 数字表示 |
|---|---|---|
| DEBUG | 最详细的日志信息,典型应用场景是 问题诊断 | 10 |
| INFO | 信息详细程度仅次于DEBUG,通常只记录关键节点信息,用于确认一切都是按照我们预期的那样进行工作 | 20 |
| WARNING | 当某些不期望的事情发生时记录的信息(如,磁盘可用空间较低),但是此时应用程序还是正常运行的 | 30 |
| ERROR | 由于一个更严重的问题导致某些功能不能正常运行时记录的信息 | 40 |
| CRITICAL | 当发生严重错误,导致应用程序不能继续运行时记录的信息 | 50 |
开发应用程序或部署开发环境时,可以使用DEBUG或INFO级别的日志获取尽可能详细的日志信息来进行开发或部署调试;
说明:
-
上面列表中的日志等级是从上到下依次升高的,即:DEBUG < INFO < WARNING < ERROR < CRITICAL,而日志的信息量是依次减少的;
-
当为某个应用程序指定一个日志级别后,应用程序会记录所有日志级别大于或等于指定日志级别的日志信息,而不是仅仅记录指定级别的日志信息,nginx、php等应用程序以及这里的python的logging模块都是这样的。同样,logging模块也可以指定日志记录器的日志级别,只有级别大于或等于该指定日志级别的日志记录才会被输出,小于该等级的日志记录将会被丢弃。
logging模块的使用方式介绍
logging模块提供了两种记录日志的方式:
-
第一种方式是使用logging提供的模块级别的函数
-
第二种方式是使用Logging日志系统的四大组件
其实,logging所提供的模块级别的日志记录函数也是对logging日志系统相关类的封装而已。
logging模块定义的模块级别的常用函数
| 函数 | 说明 |
|---|---|
| logging.debug(msg, *args, **kwargs) | 创建一条严重级别为DEBUG的日志记录 |
| logging.info(msg, *args, **kwargs) | 创建一条严重级别为INFO的日志记录 |
| logging.warning(msg, *args, **kwargs) | 创建一条严重级别为WARNING的日志记录 |
| logging.error(msg, *args, **kwargs) | 创建一条严重级别为ERROR的日志记录 |
| logging.critical(msg, *args, **kwargs) | 创建一条严重级别为CRITICAL的日志记录 |
| logging.log(level, *args, **kwargs) | 创建一条严重级别为level的日志记录 |
| logging.basicConfig(**kwargs) | 对root logger进行一次性配置 |
其中logging.basicConfig(**kwargs)函数用于指定“要记录的日志级别”、“日志格式”、“日志输出位置”、“日志文件的打开模式”等信息,其他几个都是用于记录各个级别日志的函数。
import logging logging.debug("debug_msg") logging.info("info_msg") logging.warning("warning_msg") logging.error("error_msg") logging.critical("critical_msg") --------------------------------- 输出结果 -------------------------------------- WARNING:root:warning_msg ERROR:root:error_msg CRITICAL:root:critical_msg
默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG)。
默认输出格式为:默认的日志格式为日志级别:Logger名称:用户输出消息
logging.basicConfig()函数调整日志级别、输出格式等
import logging logger = logging.basicConfig(filename='xxxxxxx.txt', format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S', level=30) logging.debug('x1') # 10 logging.info('x2') # 20 logging.warning('x3') # 30 logging.error('x4') # 40 logging.critical('x5') # 50
#输出结果: #在xxxxxxxxx.txt文件中 2018-08-31 17:50:24 - root - WARNING -面向对象: x3 2018-08-31 17:50:24 - root - ERROR -面向对象: x4 2018-08-31 17:50:24 - root - CRITICAL -面向对象: x5
logging.basicConfig()函数包含参数说明
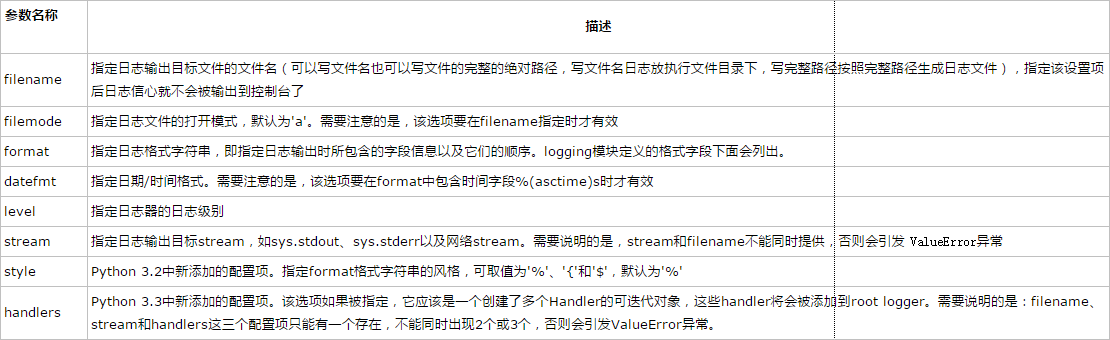
logging模块中定义好的可以用于format格式字符串说明
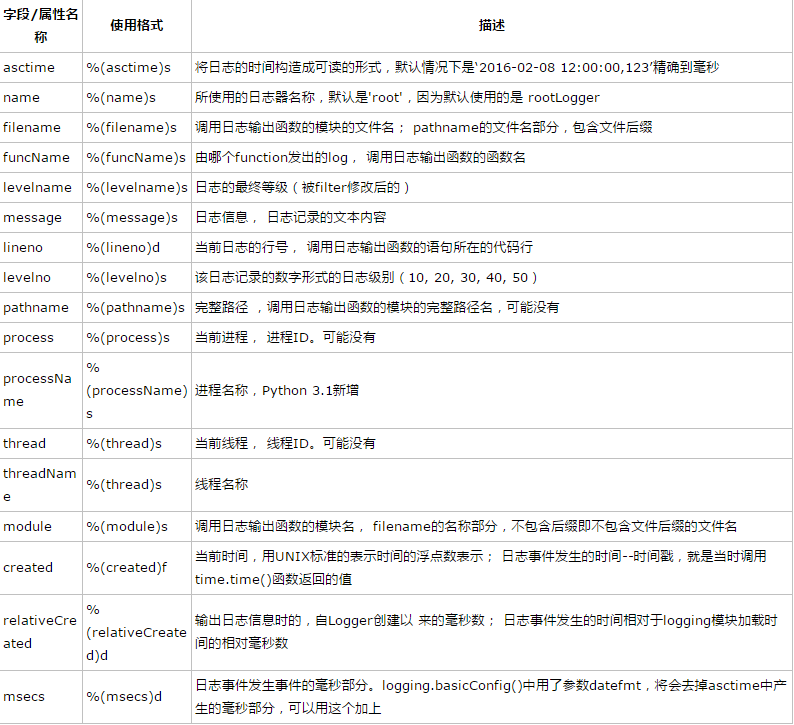
说明:
-
logging.basicConfig()函数是一个一次性的简单配置工具使,也就是说只有在第一次调用该函数时会起作用,后续再次调用该函数时完全不会产生任何操作的,多次调用的设置并不是累加操作。 -
日志器(Logger)是有层级关系的,上面调用的logging模块级别的函数所使用的日志器是
RootLogger类的实例,其名称为'root',它是处于日志器层级关系最顶层的日志器,且该实例是以单例模式存在的。
自定义日志:
logging日志模块四大组件:

logging模块就是通过这些组件来完成日志处理的,上面所使用的logging模块级别的函数也是通过这些组件对应的类来实现的。
这些组件之间的关系描述:
-
日志器(logger)需要通过处理器(handler)将日志信息输出到目标位置,如:文件、sys.stdout、网络等;
-
不同的处理器(handler)可以将日志输出到不同的位置;
-
日志器(logger)可以设置多个处理器(handler)将同一条日志记录输出到不同的位置;
-
每个处理器(handler)都可以设置自己的过滤器(filter)实现日志过滤,从而只保留感兴趣的日志;
-
每个处理器(handler)都可以设置自己的格式器(formatter)实现同一条日志以不同的格式输出到不同的地方。
简单点说就是:日志器(logger)是入口,真正干活儿的是处理器(handler),处理器(handler)还可以通过过滤器(filter)和格式器(formatter)对要输出的日志内容做过滤和格式化等处理操作。
import logging # 创建一个操作日志的对象logger(依赖FileHandler) file_handler = logging.FileHandler('l1.log', 'a', encoding='utf-8') file_handler.setFormatter(logging.Formatter(fmt="%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s")) logger1 = logging.Logger('s1', level=logging.ERROR) logger1.addHandler(file_handler) logger1.error('123123123') # 在创建一个操作日志的对象logger(依赖FileHandler) file_handler2 = logging.FileHandler('l2.log', 'a', encoding='utf-8') file_handler2.setFormatter(logging.Formatter(fmt="%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s")) logger2 = logging.Logger('s2', level=logging.ERROR) logger2.addHandler(file_handler2) logger2.error('666')
梵蒂冈梵蒂冈