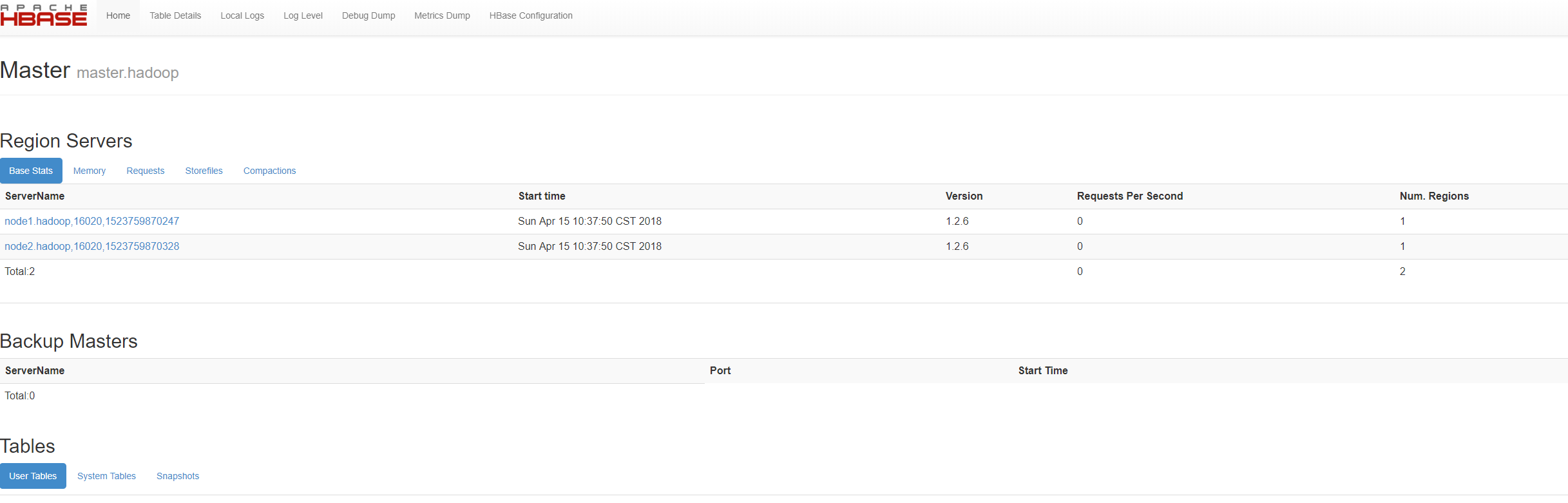
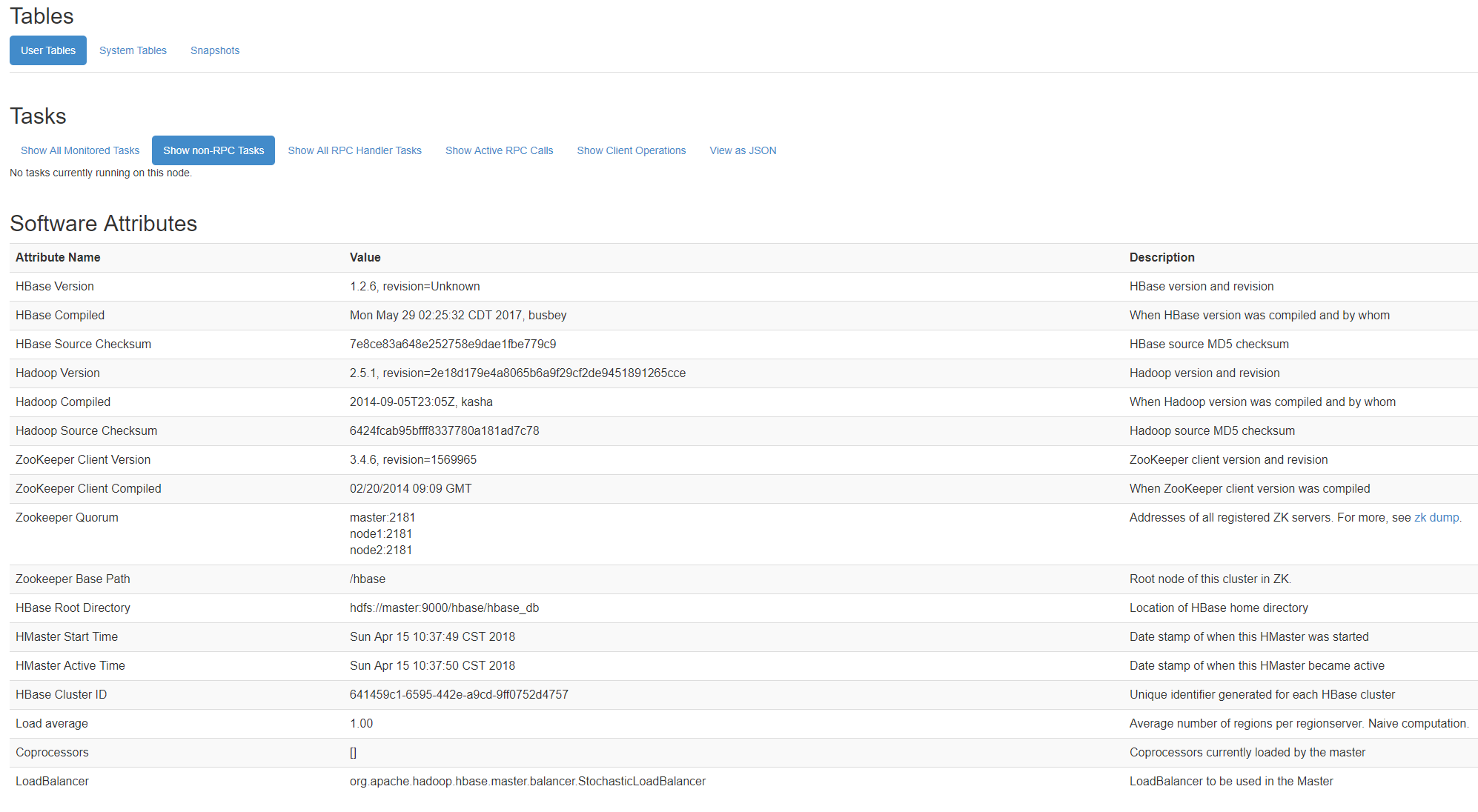
hadoop的安装请看http://www.cnblogs.com/zhangmin1987/p/8808711.html
一、Hbase简介
Apache HBase™是Hadoop数据库,这是一个分布式,可扩展的大数据存储。
当您需要随机,实时读取/写入您的大数据时使用Apache HBase™。该项目的目标是托管非常大的表 - 数十亿行×数百万列 - 在商品硬件集群上。Apache HBase是一个开源的,分布式的,版本化的非关系数据库,其模型是在Chang等人的Google Bigtable:结构化数据分布式存储系统之后建立的。就像Bigtable利用Google文件系统提供的分布式数据存储一样,Apache HBase在Hadoop和HDFS之上提供了类似Bigtable的功能。
截取官网的一些内容如下,官网地址
Welcome to Apache HBase™
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
Use Apache HBase™ when you need random, realtime read/write access to your Big Data. This project's goal is the hosting of very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google's Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
Features-特性
- Linear and modular scalability.
- Strictly consistent reads and writes.
- Automatic and configurable sharding of tables
- Automatic failover support between RegionServers.
- Convenient base classes for backing Hadoop MapReduce jobs with Apache HBase tables.
- Easy to use Java API for client access.
- Block cache and Bloom Filters for real-time queries.
- Query predicate push down via server side Filters
- Thrift gateway and a REST-ful Web service that supports XML, Protobuf, and binary data encoding options
- Extensible jruby-based (JIRB) shell
- Support for exporting metrics via the Hadoop metrics subsystem to files or Ganglia; or via JMX
二、下载
Download-下载地址
Click here to download Apache HBase™.
三、Hbase的参考指南
Apache HBase™参考指南
大家可以仔细看下这个指南,包括了安装说明和适配说明以及数据库的模型和具体特性。
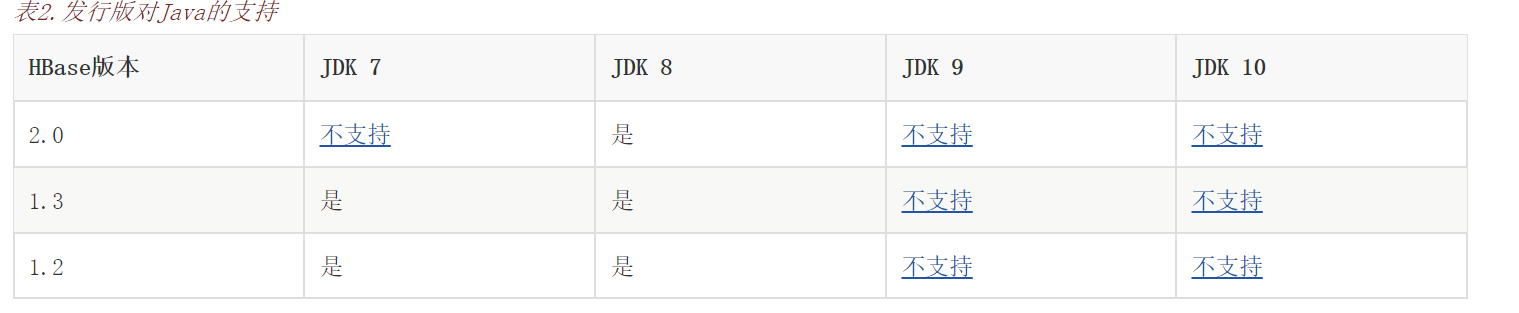
贴一下Hbase对JDK的适配性:
三、环境准备
三台linux-cent0s6.5机器
机器1 192.168.234.129 master 主机
机器2 192.168.234.130 node1 主机
机器3 192.168.234.131 node2 主机
四、安装
4.1 下载
下载请看二或者用wget 命令
4.2 安装
[root@master local]# ls /local/hadoop-3.1.0.tar.gz /local/hadoop-3.1.0.tar.gz [root@master local]# tar -zxvf /local/hadoop-3.1.0.tar.gz
将解压后的文件mv到/opt/下。
[root@master hbase]# pwd
/opt/hbase
然后配置/etc/profile
内容如下
#hbase config export HBASE_HOME=/opt/hbase export PATH=$HBASE_HOME/bin:$PATH "/etc/profile" 91L, 2237C written [root@master ~]# source /etc/profile
4.3 habse配置
配置三个文件:
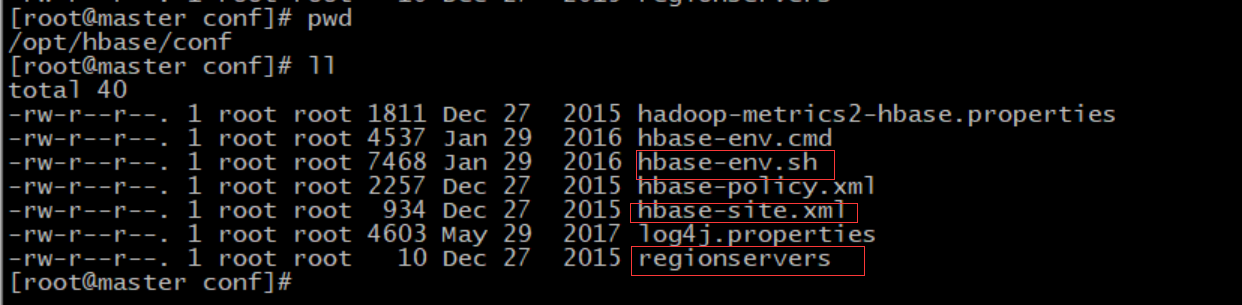
1) 配置hbase-env.sh

默认情况下hbase自带的zookeeper配置是被注释掉的,代表着当启动hbase的时候它会再一次启动hbase自带的zookeeper,这个时候会报错,端口被占用。

所以这里修改成
export HBASE_MANAGES_ZK=false
2)配置/opt/hbase/conf/hbase-site.xml
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://master:9000/hbase/hbase_db</value> </property> <property> <name>hbase.master</name> <value>master</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>master,node1,node2</value> </property> <property> <name>zookeeper.session.timeout</name> <value>60000000</value> </property> <property> <name>dfs.support.append</name> <value>true</value> </property> </configuration>
3) 配置regionservers
[root@master conf]# cat regionservers node1 node2
4)集群安装:
配置完以后将hbase整个目录和/etc/profile全部copy到node1和node2. (略)
和hadoop和zookeeper的复制类似,请参看http://www.cnblogs.com/zhangmin1987/p/8808711.html
复制完以后记得source
4.4 启动
1)启动顺序: zookeeper--hadoop--hbase
启动zookeeper和hadoop请参看前2篇文章 http://www.cnblogs.com/zhangmin1987/p/8808711.html 和 http://www.cnblogs.com/zhangmin1987/p/8818426.html
启动hbase
[root@master bin]# pwd /opt/hbase/bin [root@master bin]# ./start-hbase.sh starting master, logging to /opt/hbase/logs/hbase-root-master-master.out Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0 Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0 node2: starting regionserver, logging to /opt/hbase/bin/../logs/hbase-root-regionserver-node2.out node1: starting regionserver, logging to /opt/hbase/bin/../logs/hbase-root-regionserver-node1.out node2: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0 node2: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0 node1: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0 node1: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
2)jps验证
[root@master bin]# jps
9856 Jps
9584 HMaster
2931 NameNode
3306 ResourceManager
2731 QuorumPeerMain
[root@master bin]#
3)前端验证
hdfs
http://192.168.234.129:50070/dfshealth.html#tab-startup-progress
yarn
http://192.168.234.129:8088/cluster/nodes

hbase
http://192.168.234.129:16010/master-status