一、字符串常用操作:


#! /usr/bin/env python # -*- coding: utf-8 -*- # __author__ = "Z'N'Y" # Date: 2017/7/17 #Python strip() 方法用于移除字符串头尾指定的字符(默认为空格) name='*egon**' print(name.strip('*'))#移除 name 变量对应的值两边的*,并输出处理结果 print(name.lstrip('*'))#移除 name 变量左边的*,并输出处理结果 print(name.rstrip('*'))#移除 name 变量右边的*,并输出处理结果 #startswith,endswith name='alex_SB' print(name.endswith('SB'))#判断 name 变量对应的值是否以 "SB" 结尾,并输出结果 print(name.startswith('alex'))#判断 name 变量对应的值是否以 "alex" 开头,并输出结果 #replace name='alex say :i have one tesla,my name is alex'#将 name 变量对应的值中的第一个“alex” 替换为 “SB”,并输出结果 print(name.replace('alex','SB',1))#若数字1变为2,则两个alex都为SB #format的三种玩法,定义打印顺序 res='{} {} {}'.format('egon',18,'male') res='{1} {0} {1}'.format('egon',18,'male') res='{name} {age} {sex}'.format(sex='male',name='egon',age=18) res='{name} {sex} {age}'.format(sex='male',name='egon',age=18) print(res) #find,rfind,index,rindex,count name='egon say hello' print(name.find('o',1,3)) #顾头不顾尾,找不到则返回-1不会报错,找到了则显示索引, # 即在第一至第4个字符中查找字符“O” # print(name.index('e',2,4)) #同上,但是找不到会报错 print(name.count('e',1,3)) #顾头不顾尾,如果不指定范围则查找所有 # 用于统计字符串里某个字符出现的次数。可选参数为在字符串搜索的开始与结束位置 #split name='root:x:0:0::/root:/bin/bash' print(name.split(':')) #默认分隔符为空格 name='C:/a/b/c/d.txt' #只想拿到顶级目录 print(name.split('/',1)) name='a|b|c' print(name.rsplit('|',1)) #从右开始切分,移除| #join:Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串 tag=' ' print(tag.join(['egon','say','hello','world'])) #可迭代对象必须都是字符串 #center,ljust,rjust,zfill name='egon' print(name.center(30,'-'))#用-填充在两边位置 print(name.ljust(30,'*'))#用*填充在右边位置 print(name.rjust(30,'*'))#用*填充在左边位置 print(name.zfill(50)) #用0填充在左边 #expandtabs:把字符串中的 tab 符号(' ')转为空格,tab 符号(' ')默认的空格数是 8 name='egon hello' print(name) print(name.expandtabs(1))#使用1个空格替换 ' ' #lower,upper name='egon' print(name.lower())# 方法转换字符串中所有大写字符为小写 print(name.upper())# 方法转换字符串中所有小写字符为大写 #captalize,swapcase,title print(name.capitalize()) #首字母大写 print(name.swapcase()) #大小写翻转 msg='egon say hi' print(msg.title()) #每个单词的首字母大写 #is数字系列 #在python3中 num1=b'4' #bytes num2=u'4' #unicode,python3中无需加u就是unicode num3='四' #中文数字 num4='Ⅳ' #罗马数字 #isdigt:bytes,unicode print(num1.isdigit()) #True print(num2.isdigit()) #True print(num3.isdigit()) #False print(num4.isdigit()) #False #isdecimal:uncicode #bytes类型无isdecimal方法 print(num2.isdecimal()) #True print(num3.isdecimal()) #False print(num4.isdecimal()) #False #isnumberic:unicode,中文数字,罗马数字 #bytes类型无isnumberic方法 print(num2.isnumeric()) #True print(num3.isnumeric()) #True print(num4.isnumeric()) #True #三者不能判断浮点数 num5='4.3' print(num5.isdigit()) print(num5.isdecimal()) print(num5.isnumeric()) ''' 总结: 最常用的是isdigit,可以判断bytes和unicode类型,这也是最常见的数字应用场景 如果要判断中文数字或罗马数字,则需要用到isnumeric ''' #is其他 print('===>') name='egon123' print(name.isalnum()) #判断字符串由字母和数字组成 print(name.isalpha()) #判断字符串只由字母组成 print(name.isidentifier()) print(name.islower())#lower() 方法检测字符串是否由小写字母组成。 print(name.isupper())#isupper() 方法检测字符串中所有的字母是否都为大写。 print(name.isspace())#描述 Python isspace() 方法检测字符串是否只由空格组成。 print(name.istitle())#描述 istitle() 方法检测字符串中所有的单词拼写首字母是否为大写,且其他字母为小写
二、数据类型内置转换函数
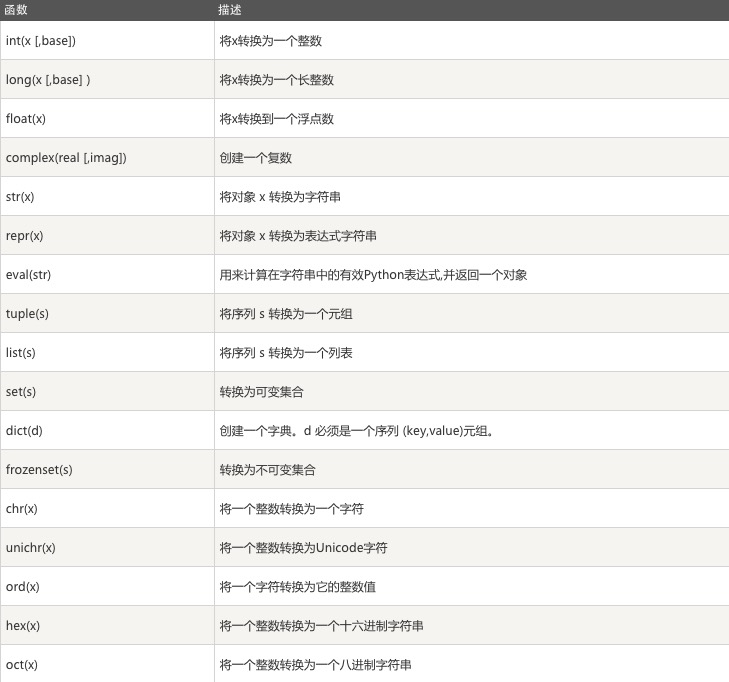
注:真对acsii表unichr在python2.7中比chr的范围更大,python3.*中chr内置了unichar
三.运算符
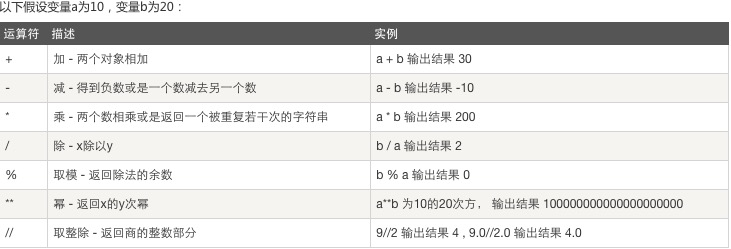
2、比较运算:

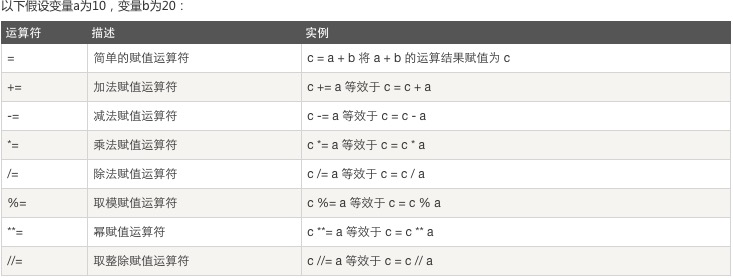
3、赋值运算:
4、位运算:
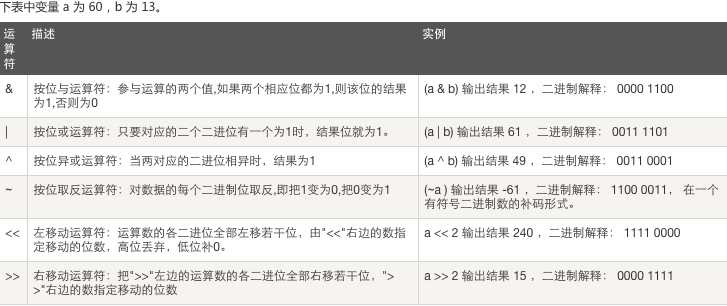
注: ~ 举例: ~5 = -6 解释: 将二进制数+1之后乘以-1,即~x = -(x+1),-(101 + 1) = -110
按位反转仅能用在数字前面。所以写成 3+~5 可以得到结果-3,写成3~5就出错了
5、逻辑运算:

and注解:
- 在Python 中,and 和 or 执行布尔逻辑演算,如你所期待的一样,但是它们并不返回布尔值;而是,返回它们实际进行比较的值之一。
- 在布尔上下文中从左到右演算表达式的值,如果布尔上下文中的所有值都为真,那么 and 返回最后一个值。
- 如果布尔上下文中的某个值为假,则 and 返回第一个假值
or注解:
- 使用 or 时,在布尔上下文中从左到右演算值,就像 and 一样。如果有一个值为真,or 立刻返回该值
- 如果所有的值都为假,or 返回最后一个假值
- 注意 or 在布尔上下文中会一直进行表达式演算直到找到第一个真值,然后就会忽略剩余的比较值
and-or结合使用:
- 结合了前面的两种语法,推理即可。
- 为加强程序可读性,最好与括号连用,例如:
(1 and 'x') or 'y'
6、成员运算:

7.身份运算

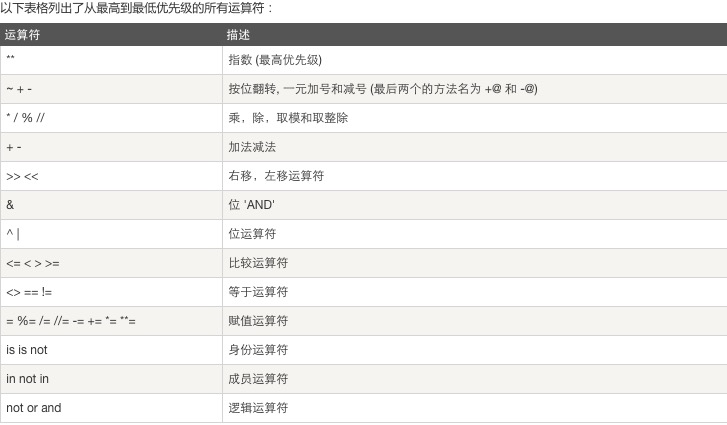
8.运算符优先级:自上而下,优先级从高到低
四、流程控制
1、if语法:
if 条件:
子代码
elif 条件:
子代码
else:
子代码
例如:
age=63 age = int(input("老男孩的age是:") ) if age > 63 : print("too big") elif age < 63 : print("too small") else: print("you get it")
总结:
- if 后表达式返回值为True则执行其子代码块,然后此if语句到此终结,否则进入下一分支判断,直到满足其中一个分支,执行后终结if
- expression可以引入运算符:not,and,or,is,is not
- 多重expression为加强可读性最好用括号包含
- if与else缩进级别一致表示是一对
- elif与else都是可选的
- 一个if判断最多只有一个else但是可以有多个elif
- else代表if判断的终结
- expession可以是返回值为布尔值的表达式(例x>1,x is not None)的形式,也可是单个标准对象(例 x=1;if x:print('ok'))
- 所有标准对象均可用于布尔测试,同类型的对象之间可以比较大小。每个对象天生具有布 尔 True 或 False 值。空对象、值为零的任何数字或者 Null 对象 None 的布尔值都是 False。
下列对象的布尔值是 False

2、while循环
作用:
while循环的本质就是让计算机在满足某一条件的前提下去重复做同一件事情(即while循环为条件循环,包含:1.条件计数循环,2条件无限循环)
这一条件指:条件表达式
同一件事指:while循环体包含的代码块
重复的事情例如:从1加到10000,求1-10000内所有奇数,服务等待连接
语法:
while 条件
执行子代码
满足条件循环执行直到条件不满足。
死循环
while true:
print(ok)
循环终止语句:
- break用于完全结束一个循环,跳出循环体执行循环后面的语句
- continue和break有点类似,区别在于continue只是终止本次循环,接着还执行后面的循环,break则完全终止循环
break跳出本层循环
count=0 while (count < 9): count+=1 if count == 3: print('跳出本层循环,即彻底终结这一个/层while循环') break print('the loop is %s' %count)
continue跳出本次循环count=0 while (count < 9): count+=1 if count == 3: print('跳出本次循环,即这一次循环continue之后的代码不再执行,进入下一次循环') continue print('the loop is %s' %count)
else在循环完成后执行,break会跳过elsecount=0 while (count < 9): count+=1 if count == 3: print('跳出本次循环,即这一次循环continue之后的代码不再执行,进入下一次循环') continue print('the loop is %s' %count) else: print('循环不被break打断,即正常结束,就会执行else后代码块') count=0 while (count < 9): count+=1 if count == 3: print('跳出本次循环,即这一次循环continue之后的代码不再执行,进入下一次循环') break print('the loop is %s' %count) else: print('循环被break打断,即非正常结束,就不会执行else后代码块')
用户登录三次name= "user" passwd="password" n=1 while n<=3: x = 3 - n name = input("请输入用户名:") if name=="user": passwd = input("请输入密码:") if passwd == "password": print("登陆成功") break else: print("密码错误,请重新输入,您还有",x,"次机会") while n<=2: y = 2 - n passwd = input("请输入密码:") if name == "user" and passwd == "password": print("登陆成功") break else: print("密码错误,请重新输入,您还有",y,"次机会") n+=1 else : print("用户名有误,请重新登陆,您还有",x,"次机会") n+=1
1-2+3-4+5 ... 99的所有数的和i=1 n=0 while i<=99: if i % 2 == 1: n=n+i else: n=n-i i+=1 print(n)
使用while循环输出1 2 3 4 5 6 8 9 10Cyle = 0 while Cyle <= 9: Cyle += 1 if Cyle == 7: print(" ") else: print(Cyle)
求1-100的所有数的和i=1 n=0 while i<=100: n =n +i i+=1 print(n)
输出 1-100 内的所有奇数、偶数#奇数 i=0 while i<100: i+=1 if i % 2 == 1: print(i) #偶数 i=0 while i<100: i+=1 if i % 2 == 0: print(i)
Python 的字符串内建函数
Python 的字符串常用内建函数如下:
序号 方法及描述 1 capitalize()
将字符串的第一个字符转换为大写2
返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。3 count(str, beg= 0,end=len(string))
返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数4 bytes.decode(encoding="utf-8", errors="strict")
Python3 中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象,这个 bytes 对象可以由 str.encode() 来编码返回。5 encode(encoding='UTF-8',errors='strict')
以 encoding 指定的编码格式编码字符串,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace'6 endswith(suffix, beg=0, end=len(string))
检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False.7
把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 。8 find(str, beg=0 end=len(string))
检测 str 是否包含在字符串中 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-19 index(str, beg=0, end=len(string))
跟find()方法一样,只不过如果str不在字符串中会报一个异常.10
如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False11
如果字符串至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False12
如果字符串只包含数字则返回 True 否则返回 False..13
如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False14
如果字符串中只包含数字字符,则返回 True,否则返回 False15
如果字符串中只包含空格,则返回 True,否则返回 False.16
如果字符串是标题化的(见 title())则返回 True,否则返回 False17
如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False18
以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串19
返回字符串长度20
返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。21
转换字符串中所有大写字符为小写.22
截掉字符串左边的空格或指定字符。23
创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。24
返回字符串 str 中最大的字母。25
返回字符串 str 中最小的字母。26
把 将字符串中的 str1 替换成 str2,如果 max 指定,则替换不超过 max 次。27 rfind(str, beg=0,end=len(string))
类似于 find()函数,不过是从右边开始查找.28 rindex( str, beg=0, end=len(string))
类似于 index(),不过是从右边开始.29
返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串30
删除字符串字符串末尾的空格.31 split(str="", num=string.count(str))
num=string.count(str)) 以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num 个子字符串32
按照行(' ', ' ', ')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。33 startswith(str, beg=0,end=len(string))
检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。34
在字符串上执行 lstrip()和 rstrip()35
将字符串中大写转换为小写,小写转换为大写36
返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle())37 translate(table, deletechars="")
根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 deletechars 参数中38
转换字符串中的小写字母为大写39
返回长度为 width 的字符串,原字符串右对齐,前面填充040
检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false。