spark是个啥?
Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发。
- 本地模式
- Standalone模式
- Mesoes模式
- yarn模式
1.下载安装
http://spark.apache.org/downloads.html
这里可以选择下载源码编译,或者下载已经编译好的程序(因为spark是运行在JVM上面,也可以说是跨平台的),这里是直接下载可执行程序。
Chose a package type: Pre-built for Hadoop 2.4 and later 。
解压这个 spark-1.3.0-bin-hadoop2.4.tgz 即可。
PS:你需要安装java运行环境
~/project/spark-1.3.0-bin-hadoop2.4 $java -version java version "1.8.0_25" Java(TM) SE Runtime Environment (build 1.8.0_25-b17) Java HotSpot(TM) 64-Bit Server VM (build 25.25-b02, mixed mode)
2.目录分布
sbin目录是各种启动命令
~/project/spark-1.3.0-bin-hadoop2.4 $tree sbin/
sbin/
├── slaves.sh
├── spark-config.sh
├── spark-daemon.sh
├── spark-daemons.sh
├── start-all.sh
├── start-history-server.sh
├── start-master.sh
├── start-slave.sh
├── start-slaves.sh
├── start-thriftserver.sh
├── stop-all.sh
├── stop-history-server.sh
├── stop-master.sh
├── stop-slaves.sh
└── stop-thriftserver.sh
conf目录是一些配置模板:
~/project/spark-1.3.0-bin-hadoop2.4 $tree conf/
conf/
├── fairscheduler.xml.template
├── log4j.properties.template
├── metrics.properties.template
├── slaves.template
├── spark-defaults.conf.template
└── spark-env.sh.template
3.启动master
~/project/spark-1.3.0-bin-hadoop2.4 $./sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /Users/qpzhang/project/spark-1.3.0-bin-hadoop2.4/sbin/../logs/spark-qpzhang-org.apache.spark.deploy.master.Master-1-qpzhangdeMac-mini.local.out
没有进行任何配置时,采用的都是默认配置,可以看到日志文件的输出:
~/project/spark-1.3.0-bin-hadoop2.4 $cat logs/spark-qpzhang-org.apache.spark.deploy.master.Master-1-qpzhangdeMac-mini.local.out Spark assembly has been built with Hive, including Datanucleus jars on classpath Spark Command: /Library/Java/JavaVirtualMachines/jdk1.8.0_25.jdk/Contents/Home/bin/java -cp :/Users/qpzhang/project/spark-1.3.0-bin-hadoop2.4/sbin/../conf:/Users/qpzhang/project/spark-1.3.0-bin-hadoop2.4/lib/spark-assembly-1.3.0-hadoop2.4.0.jar:/Users/qpzhang/project/spark-1.3.0-bin-hadoop2.4/lib/datanucleus-api-jdo-3.2.6.jar:/Users/qpzhang/project/spark-1.3.0-bin-hadoop2.4/lib/datanucleus-core-3.2.10.jar:/Users/qpzhang/project/spark-1.3.0-bin-hadoop2.4/lib/datanucleus-rdbms-3.2.9.jar -Dspark.akka.logLifecycleEvents=true -Xms512m -Xmx512m org.apache.spark.deploy.master.Master --ip qpzhangdeMac-mini.local --port 7077 --webui-port 8080 ======================================== Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties 15/03/20 10:08:09 INFO Master: Registered signal handlers for [TERM, HUP, INT] 15/03/20 10:08:10 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 15/03/20 10:08:10 INFO SecurityManager: Changing view acls to: qpzhang 15/03/20 10:08:10 INFO SecurityManager: Changing modify acls to: qpzhang 15/03/20 10:08:10 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(qpzhang); users with modify permissions: Set(qpzhang) 15/03/20 10:08:10 INFO Slf4jLogger: Slf4jLogger started 15/03/20 10:08:10 INFO Remoting: Starting remoting 15/03/20 10:08:10 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkMaster@qpzhangdeMac-mini.local:7077] 15/03/20 10:08:10 INFO Remoting: Remoting now listens on addresses: [akka.tcp://sparkMaster@qpzhangdeMac-mini.local:7077] 15/03/20 10:08:10 INFO Utils: Successfully started service 'sparkMaster' on port 7077. 15/03/20 10:08:11 INFO Server: jetty-8.y.z-SNAPSHOT 15/03/20 10:08:11 INFO AbstractConnector: Started SelectChannelConnector@qpzhangdeMac-mini.local:6066 15/03/20 10:08:11 INFO Utils: Successfully started service on port 6066. 15/03/20 10:08:11 INFO StandaloneRestServer: Started REST server for submitting applications on port 6066 15/03/20 10:08:11 INFO Master: Starting Spark master at spark://qpzhangdeMac-mini.local:7077 15/03/20 10:08:11 INFO Master: Running Spark version 1.3.0 15/03/20 10:08:11 INFO Server: jetty-8.y.z-SNAPSHOT 15/03/20 10:08:11 INFO AbstractConnector: Started SelectChannelConnector@0.0.0.0:8080 15/03/20 10:08:11 INFO Utils: Successfully started service 'MasterUI' on port 8080. 15/03/20 10:08:11 INFO MasterWebUI: Started MasterWebUI at http://10.60.215.41:8080 15/03/20 10:08:11 INFO Master: I have been elected leader! New state: ALIVE
可以看到输出的几条重要的信息,service端口6066,spark端口 7077,ui端口8080等,并且当前node通过选举,确认自己为leader。
这个时候,我们可以通过 http://localhost:8080/ 来查看到当前master的总体状态。
4.附加一个worker到master
~/project/spark-1.3.0-bin-hadoop2.4 $./bin/spark-class org.apache.spark.deploy.worker.Worker spark://qpzhangdeMac-mini.local:7077 Spark assembly has been built with Hive, including Datanucleus jars on classpath Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties 15/03/20 10:33:49 INFO Worker: Registered signal handlers for [TERM, HUP, INT] 15/03/20 10:33:49 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 15/03/20 10:33:49 INFO SecurityManager: Changing view acls to: qpzhang 15/03/20 10:33:49 INFO SecurityManager: Changing modify acls to: qpzhang 15/03/20 10:33:49 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(qpzhang); users with modify permissions: Set(qpzhang) 15/03/20 10:33:50 INFO Slf4jLogger: Slf4jLogger started 15/03/20 10:33:50 INFO Remoting: Starting remoting 15/03/20 10:33:50 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkWorker@10.60.215.41:60994] 15/03/20 10:33:50 INFO Remoting: Remoting now listens on addresses: [akka.tcp://sparkWorker@10.60.215.41:60994] 15/03/20 10:33:50 INFO Utils: Successfully started service 'sparkWorker' on port 60994. 15/03/20 10:33:50 INFO Worker: Starting Spark worker 10.60.215.41:60994 with 8 cores, 7.0 GB RAM 15/03/20 10:33:50 INFO Worker: Running Spark version 1.3.0 15/03/20 10:33:50 INFO Worker: Spark home: /Users/qpzhang/project/spark-1.3.0-bin-hadoop2.4 15/03/20 10:33:50 INFO Server: jetty-8.y.z-SNAPSHOT 15/03/20 10:33:50 INFO AbstractConnector: Started SelectChannelConnector@0.0.0.0:8081 15/03/20 10:33:50 INFO Utils: Successfully started service 'WorkerUI' on port 8081. 15/03/20 10:33:50 INFO WorkerWebUI: Started WorkerWebUI at http://10.60.215.41:8081 15/03/20 10:33:50 INFO Worker: Connecting to master akka.tcp://sparkMaster@qpzhangdeMac-mini.local:7077/user/Master... 15/03/20 10:33:50 INFO Worker: Successfully registered with master spark://qpzhangdeMac-mini.local:7077
从日志输出可以看到, worker自己在60994端口工作,然后为自己也起了一个UI,端口是8081,可以通过 http://10.60.215.41:8081查看worker的工作状态,(不得不说,选择的分布式少不了UI监控状态这一块儿了)。
5.启动spark shell终端:
~/project/spark-1.3.0-bin-hadoop2.4 $./bin/spark-shell Spark assembly has been built with Hive, including Datanucleus jars on classpath log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties 15/03/20 10:43:39 INFO SecurityManager: Changing view acls to: qpzhang 15/03/20 10:43:39 INFO SecurityManager: Changing modify acls to: qpzhang 15/03/20 10:43:39 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(qpzhang); users with modify permissions: Set(qpzhang) 15/03/20 10:43:39 INFO HttpServer: Starting HTTP Server 15/03/20 10:43:39 INFO Server: jetty-8.y.z-SNAPSHOT 15/03/20 10:43:39 INFO AbstractConnector: Started SocketConnector@0.0.0.0:61644 15/03/20 10:43:39 INFO Utils: Successfully started service 'HTTP class server' on port 61644. Welcome to ____ __ / __/__ ___ _____/ /__ _ / _ / _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_ version 1.3.0 /_/ Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_25) Type in expressions to have them evaluated. Type :help for more information. 15/03/20 10:43:43 INFO SparkContext: Running Spark version 1.3.0 15/03/20 10:43:43 INFO SecurityManager: Changing view acls to: qpzhang 15/03/20 10:43:43 INFO SecurityManager: Changing modify acls to: qpzhang 15/03/20 10:43:43 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(qpzhang); users with modify permissions: Set(qpzhang) 15/03/20 10:43:43 INFO Slf4jLogger: Slf4jLogger started 15/03/20 10:43:43 INFO Remoting: Starting remoting 15/03/20 10:43:43 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@10.60.215.41:61645] 15/03/20 10:43:43 INFO Utils: Successfully started service 'sparkDriver' on port 61645. 15/03/20 10:43:43 INFO SparkEnv: Registering MapOutputTracker 15/03/20 10:43:44 INFO SparkEnv: Registering BlockManagerMaster 15/03/20 10:43:44 INFO DiskBlockManager: Created local directory at /var/folders/2l/195zcc1n0sn2wjfjwf9hl9d80000gn/T/spark-5349b1ce-bd10-4f44-9571-da660c1a02a3/blockmgr-a519687e-0cc3-45e4-839a-f93ac8f1397b 15/03/20 10:43:44 INFO MemoryStore: MemoryStore started with capacity 265.1 MB 15/03/20 10:43:44 INFO HttpFileServer: HTTP File server directory is /var/folders/2l/195zcc1n0sn2wjfjwf9hl9d80000gn/T/spark-29d81b59-ec6a-4595-b2fb-81bf6b1d3b10/httpd-c572e4a5-ff85-44c9-a21f-71fb34b831e1 15/03/20 10:43:44 INFO HttpServer: Starting HTTP Server 15/03/20 10:43:44 INFO Server: jetty-8.y.z-SNAPSHOT 15/03/20 10:43:44 INFO AbstractConnector: Started SocketConnector@0.0.0.0:61646 15/03/20 10:43:44 INFO Utils: Successfully started service 'HTTP file server' on port 61646. 15/03/20 10:43:44 INFO SparkEnv: Registering OutputCommitCoordinator 15/03/20 10:43:44 INFO Server: jetty-8.y.z-SNAPSHOT 15/03/20 10:43:44 INFO AbstractConnector: Started SelectChannelConnector@0.0.0.0:4040 15/03/20 10:43:44 INFO Utils: Successfully started service 'SparkUI' on port 4040. 15/03/20 10:43:44 INFO SparkUI: Started SparkUI at http://10.60.215.41:4040 15/03/20 10:43:44 INFO Executor: Starting executor ID <driver> on host localhost 15/03/20 10:43:44 INFO Executor: Using REPL class URI: http://10.60.215.41:61644 15/03/20 10:43:44 INFO AkkaUtils: Connecting to HeartbeatReceiver: akka.tcp://sparkDriver@10.60.215.41:61645/user/HeartbeatReceiver 15/03/20 10:43:44 INFO NettyBlockTransferService: Server created on 61651 15/03/20 10:43:44 INFO BlockManagerMaster: Trying to register BlockManager 15/03/20 10:43:44 INFO BlockManagerMasterActor: Registering block manager localhost:61651 with 265.1 MB RAM, BlockManagerId(<driver>, localhost, 61651) 15/03/20 10:43:44 INFO BlockManagerMaster: Registered BlockManager 15/03/20 10:43:44 INFO SparkILoop: Created spark context.. Spark context available as sc. 15/03/20 10:43:45 INFO SparkILoop: Created sql context (with Hive support).. SQL context available as sqlContext. scala>
从输出可以看到,又是一堆端口(各种service进行通信,没办法),包含UI, driver等等。warning日志告诉你没有进行config,采用默认。如何进行config,后面再说,先用默认的跑起来玩玩。
6.通过shell下达命令
下面我们来执行几个官网上面overview中的几个命令来玩玩。
scala> val textFile = sc.textFile("README.md") //加载数据文件,可以是本地路径,也是是HDFS路径或者其它 15/03/20 10:55:20 INFO MemoryStore: ensureFreeSpace(159118) called with curMem=0, maxMem=278019440 15/03/20 10:55:20 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 155.4 KB, free 265.0 MB) 15/03/20 10:55:20 INFO MemoryStore: ensureFreeSpace(22692) called with curMem=159118, maxMem=278019440 15/03/20 10:55:20 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 22.2 KB, free 265.0 MB) 15/03/20 10:55:20 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:61651 (size: 22.2 KB, free: 265.1 MB) 15/03/20 10:55:20 INFO BlockManagerMaster: Updated info of block broadcast_0_piece0 15/03/20 10:55:20 INFO SparkContext: Created broadcast 0 from textFile at <console>:21 textFile: org.apache.spark.rdd.RDD[String] = README.md MapPartitionsRDD[1] at textFile at <console>:21 scala> textFile.count() //列出文件行数 15/03/20 10:56:38 INFO FileInputFormat: Total input paths to process : 1 15/03/20 10:56:38 INFO SparkContext: Starting job: count at <console>:24 15/03/20 10:56:38 INFO DAGScheduler: Got job 0 (count at <console>:24) with 2 output partitions (allowLocal=false) 15/03/20 10:56:38 INFO DAGScheduler: Final stage: Stage 0(count at <console>:24) 15/03/20 10:56:38 INFO DAGScheduler: Parents of final stage: List() 15/03/20 10:56:38 INFO DAGScheduler: Missing parents: List() 15/03/20 10:56:38 INFO DAGScheduler: Submitting Stage 0 (README.md MapPartitionsRDD[1] at textFile at <console>:21), which has no missing parents 15/03/20 10:56:38 INFO MemoryStore: ensureFreeSpace(2632) called with curMem=181810, maxMem=278019440 15/03/20 10:56:38 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 2.6 KB, free 265.0 MB) 15/03/20 10:56:38 INFO MemoryStore: ensureFreeSpace(1923) called with curMem=184442, maxMem=278019440 15/03/20 10:56:38 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 1923.0 B, free 265.0 MB) 15/03/20 10:56:38 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost:61651 (size: 1923.0 B, free: 265.1 MB) 15/03/20 10:56:38 INFO BlockManagerMaster: Updated info of block broadcast_1_piece0 15/03/20 10:56:38 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:839 15/03/20 10:56:38 INFO DAGScheduler: Submitting 2 missing tasks from Stage 0 (README.md MapPartitionsRDD[1] at textFile at <console>:21) 15/03/20 10:56:38 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks 15/03/20 10:56:38 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, PROCESS_LOCAL, 1327 bytes) 15/03/20 10:56:38 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, PROCESS_LOCAL, 1327 bytes) 15/03/20 10:56:38 INFO Executor: Running task 1.0 in stage 0.0 (TID 1) 15/03/20 10:56:38 INFO Executor: Running task 0.0 in stage 0.0 (TID 0) 15/03/20 10:56:38 INFO HadoopRDD: Input split: file:/Users/qpzhang/project/spark-1.3.0-bin-hadoop2.4/README.md:0+1814 15/03/20 10:56:38 INFO HadoopRDD: Input split: file:/Users/qpzhang/project/spark-1.3.0-bin-hadoop2.4/README.md:1814+1815 15/03/20 10:56:38 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id 15/03/20 10:56:38 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id 15/03/20 10:56:38 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap 15/03/20 10:56:38 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition 15/03/20 10:56:38 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id 15/03/20 10:56:38 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 1830 bytes result sent to driver 15/03/20 10:56:38 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1830 bytes result sent to driver 15/03/20 10:56:38 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 120 ms on localhost (1/2) 15/03/20 10:56:38 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 111 ms on localhost (2/2) 15/03/20 10:56:38 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 15/03/20 10:56:38 INFO DAGScheduler: Stage 0 (count at <console>:24) finished in 0.134 s 15/03/20 10:56:38 INFO DAGScheduler: Job 0 finished: count at <console>:24, took 0.254626 s res0: Long = 98 scala> textFile.first() //输出第一个item, 也就是第一行内容 15/03/20 10:59:31 INFO SparkContext: Starting job: first at <console>:24 15/03/20 10:59:31 INFO DAGScheduler: Got job 1 (first at <console>:24) with 1 output partitions (allowLocal=true) 15/03/20 10:59:31 INFO DAGScheduler: Final stage: Stage 1(first at <console>:24) 15/03/20 10:59:31 INFO DAGScheduler: Parents of final stage: List() 15/03/20 10:59:31 INFO DAGScheduler: Missing parents: List() 15/03/20 10:59:31 INFO DAGScheduler: Submitting Stage 1 (README.md MapPartitionsRDD[1] at textFile at <console>:21), which has no missing parents 15/03/20 10:59:31 INFO MemoryStore: ensureFreeSpace(2656) called with curMem=186365, maxMem=278019440 15/03/20 10:59:31 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 2.6 KB, free 265.0 MB) 15/03/20 10:59:31 INFO MemoryStore: ensureFreeSpace(1945) called with curMem=189021, maxMem=278019440 15/03/20 10:59:31 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 1945.0 B, free 265.0 MB) 15/03/20 10:59:31 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on localhost:61651 (size: 1945.0 B, free: 265.1 MB) 15/03/20 10:59:31 INFO BlockManagerMaster: Updated info of block broadcast_2_piece0 15/03/20 10:59:31 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:839 15/03/20 10:59:31 INFO DAGScheduler: Submitting 1 missing tasks from Stage 1 (README.md MapPartitionsRDD[1] at textFile at <console>:21) 15/03/20 10:59:31 INFO TaskSchedulerImpl: Adding task set 1.0 with 1 tasks 15/03/20 10:59:31 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 2, localhost, PROCESS_LOCAL, 1327 bytes) 15/03/20 10:59:31 INFO Executor: Running task 0.0 in stage 1.0 (TID 2) 15/03/20 10:59:31 INFO HadoopRDD: Input split: file:/Users/qpzhang/project/spark-1.3.0-bin-hadoop2.4/README.md:0+1814 15/03/20 10:59:31 INFO Executor: Finished task 0.0 in stage 1.0 (TID 2). 1809 bytes result sent to driver 15/03/20 10:59:31 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 2) in 8 ms on localhost (1/1) 15/03/20 10:59:31 INFO DAGScheduler: Stage 1 (first at <console>:24) finished in 0.009 s 15/03/20 10:59:31 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool 15/03/20 10:59:31 INFO DAGScheduler: Job 1 finished: first at <console>:24, took 0.016292 s res1: String = # Apache Spark scala> val linesWithSpark = textFile.filter(line => line.contains("Spark")) //定义一个filter, 这里定义的是包含Spark关键词的filter linesWithSpark: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at filter at <console>:23 scala> linesWithSpark.count() //输出filter中的结果数 15/03/20 11:00:28 INFO SparkContext: Starting job: count at <console>:26 15/03/20 11:00:28 INFO DAGScheduler: Got job 2 (count at <console>:26) with 2 output partitions (allowLocal=false) 15/03/20 11:00:28 INFO DAGScheduler: Final stage: Stage 2(count at <console>:26) 15/03/20 11:00:28 INFO DAGScheduler: Parents of final stage: List() 15/03/20 11:00:28 INFO DAGScheduler: Missing parents: List() 15/03/20 11:00:28 INFO DAGScheduler: Submitting Stage 2 (MapPartitionsRDD[2] at filter at <console>:23), which has no missing parents 15/03/20 11:00:28 INFO MemoryStore: ensureFreeSpace(2840) called with curMem=190966, maxMem=278019440 15/03/20 11:00:28 INFO MemoryStore: Block broadcast_3 stored as values in memory (estimated size 2.8 KB, free 265.0 MB) 15/03/20 11:00:28 INFO MemoryStore: ensureFreeSpace(2029) called with curMem=193806, maxMem=278019440 15/03/20 11:00:28 INFO MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 2029.0 B, free 265.0 MB) 15/03/20 11:00:28 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on localhost:61651 (size: 2029.0 B, free: 265.1 MB) 15/03/20 11:00:28 INFO BlockManagerMaster: Updated info of block broadcast_3_piece0 15/03/20 11:00:28 INFO SparkContext: Created broadcast 3 from broadcast at DAGScheduler.scala:839 15/03/20 11:00:28 INFO DAGScheduler: Submitting 2 missing tasks from Stage 2 (MapPartitionsRDD[2] at filter at <console>:23) 15/03/20 11:00:28 INFO TaskSchedulerImpl: Adding task set 2.0 with 2 tasks 15/03/20 11:00:28 INFO TaskSetManager: Starting task 0.0 in stage 2.0 (TID 3, localhost, PROCESS_LOCAL, 1327 bytes) 15/03/20 11:00:28 INFO TaskSetManager: Starting task 1.0 in stage 2.0 (TID 4, localhost, PROCESS_LOCAL, 1327 bytes) 15/03/20 11:00:28 INFO Executor: Running task 0.0 in stage 2.0 (TID 3) 15/03/20 11:00:28 INFO Executor: Running task 1.0 in stage 2.0 (TID 4) 15/03/20 11:00:28 INFO HadoopRDD: Input split: file:/Users/qpzhang/project/spark-1.3.0-bin-hadoop2.4/README.md:1814+1815 15/03/20 11:00:28 INFO HadoopRDD: Input split: file:/Users/qpzhang/project/spark-1.3.0-bin-hadoop2.4/README.md:0+1814 15/03/20 11:00:28 INFO Executor: Finished task 1.0 in stage 2.0 (TID 4). 1830 bytes result sent to driver 15/03/20 11:00:28 INFO Executor: Finished task 0.0 in stage 2.0 (TID 3). 1830 bytes result sent to driver 15/03/20 11:00:28 INFO TaskSetManager: Finished task 1.0 in stage 2.0 (TID 4) in 9 ms on localhost (1/2) 15/03/20 11:00:28 INFO TaskSetManager: Finished task 0.0 in stage 2.0 (TID 3) in 11 ms on localhost (2/2) 15/03/20 11:00:28 INFO DAGScheduler: Stage 2 (count at <console>:26) finished in 0.011 s 15/03/20 11:00:28 INFO TaskSchedulerImpl: Removed TaskSet 2.0, whose tasks have all completed, from pool 15/03/20 11:00:28 INFO DAGScheduler: Job 2 finished: count at <console>:26, took 0.019407 s res2: Long = 19 //可以看到有19行包含 Spark关键词 scala> linesWithSpark.first() //打印第一行数据 15/03/20 11:00:35 INFO SparkContext: Starting job: first at <console>:26 15/03/20 11:00:35 INFO DAGScheduler: Got job 3 (first at <console>:26) with 1 output partitions (allowLocal=true) 15/03/20 11:00:35 INFO DAGScheduler: Final stage: Stage 3(first at <console>:26) 15/03/20 11:00:35 INFO DAGScheduler: Parents of final stage: List() 15/03/20 11:00:35 INFO DAGScheduler: Missing parents: List() 15/03/20 11:00:35 INFO DAGScheduler: Submitting Stage 3 (MapPartitionsRDD[2] at filter at <console>:23), which has no missing parents 15/03/20 11:00:35 INFO MemoryStore: ensureFreeSpace(2864) called with curMem=195835, maxMem=278019440 15/03/20 11:00:35 INFO MemoryStore: Block broadcast_4 stored as values in memory (estimated size 2.8 KB, free 265.0 MB) 15/03/20 11:00:35 INFO MemoryStore: ensureFreeSpace(2048) called with curMem=198699, maxMem=278019440 15/03/20 11:00:35 INFO MemoryStore: Block broadcast_4_piece0 stored as bytes in memory (estimated size 2.0 KB, free 264.9 MB) 15/03/20 11:00:35 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on localhost:61651 (size: 2.0 KB, free: 265.1 MB) 15/03/20 11:00:35 INFO BlockManagerMaster: Updated info of block broadcast_4_piece0 15/03/20 11:00:35 INFO SparkContext: Created broadcast 4 from broadcast at DAGScheduler.scala:839 15/03/20 11:00:35 INFO DAGScheduler: Submitting 1 missing tasks from Stage 3 (MapPartitionsRDD[2] at filter at <console>:23) 15/03/20 11:00:35 INFO TaskSchedulerImpl: Adding task set 3.0 with 1 tasks 15/03/20 11:00:35 INFO TaskSetManager: Starting task 0.0 in stage 3.0 (TID 5, localhost, PROCESS_LOCAL, 1327 bytes) 15/03/20 11:00:35 INFO Executor: Running task 0.0 in stage 3.0 (TID 5) 15/03/20 11:00:35 INFO HadoopRDD: Input split: file:/Users/qpzhang/project/spark-1.3.0-bin-hadoop2.4/README.md:0+1814 15/03/20 11:00:35 INFO Executor: Finished task 0.0 in stage 3.0 (TID 5). 1809 bytes result sent to driver 15/03/20 11:00:35 INFO TaskSetManager: Finished task 0.0 in stage 3.0 (TID 5) in 10 ms on localhost (1/1) 15/03/20 11:00:35 INFO DAGScheduler: Stage 3 (first at <console>:26) finished in 0.010 s 15/03/20 11:00:35 INFO TaskSchedulerImpl: Removed TaskSet 3.0, whose tasks have all completed, from pool 15/03/20 11:00:35 INFO DAGScheduler: Job 3 finished: first at <console>:26, took 0.016494 s res3: String = # Apache Spark
更多命令参考: https://spark.apache.org/docs/latest/quick-start.html
期间,我们可以通过UI看到job列表和状态:
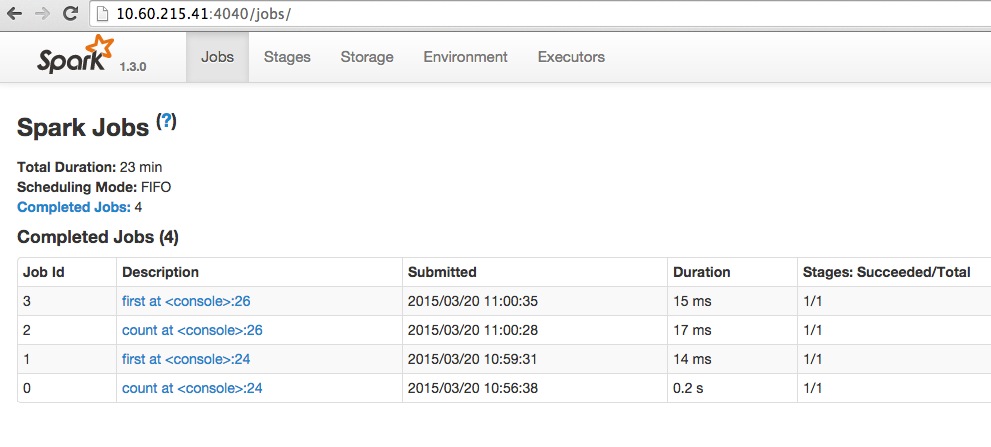
跑起来先,第一步已经完成,那么spark架构是什么样的?运行原理?如何自定义配置?如何扩展到分布式?如何编程实现?我们后面再慢慢研究。
参考资料:
http://dataunion.org/bbs/forum.php?mod=viewthread&tid=890
===================================
转载请注明出处:http://www.cnblogs.com/zhangqingping/p/4352977.html