爬虫到底是个什么玩意?
为什么要有这么多参数要设置?
到底应该怎么发送请求?
请求库,解析库,存储数据的方式?
请求到的内容跟浏览器看到的内容不一样?
爬虫基本原理的梳理
1.什么是爬虫?---->请求网站并提取数据的自动化程序。
爬虫呢也就是网络爬虫,可以理解为在网络上爬行着一只蜘蛛,互联网可以把它比喻为一个大网。这个爬虫呢就是在这个网上一直爬来爬去的一个蜘蛛,它如果在这个互联网上遇到一些网站资源就可以把它抓取下来。怎么抓取呢?就是由你来控制了。
#1、什么是互联网? 互联网是由网络设备(网线,路由器,交换机,防火墙等等)和一台台计算机连接而成,像一张网一样。 #2、互联网建立的目的? 互联网的核心价值在于数据的共享/传递:数据是存放于一台台计算机上的,而将计算机互联到一起的目的就是为了能够方便彼此之间的数据共享/传递,否则你只能拿U盘去别人的计算机上拷贝数据了。 #3、什么是上网?爬虫要做的是什么? 我们所谓的上网便是由用户端计算机发送请求给目标计算机,将目标计算机的数据下载到本地的过程。 #3.1 只不过,用户获取网络数据的方式是: 浏览器提交请求->下载网页代码->解析/渲染成页面。 #3.2 而爬虫程序要做的就是: 模拟浏览器发送请求->下载网页代码->只提取有用的数据->存放于数据库或文件中 #3.1与3.2的区别在于: 我们的爬虫程序只提取网页代码中对我们有用的数据 #4、总结爬虫 #4.1 爬虫的比喻: 如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的猎物/数据 #4.2 爬虫的定义: 向网站发起请求,获取资源后分析并提取有用数据的程序 #4.3 爬虫的价值: 互联网中最有价值的便是数据,比如天猫商城的商品信息,链家网的租房信息,雪球网的证券投资信息等等,这些数据都代表了各个行业的真金白银, 可以说,谁掌握了行业内的第一手数据,谁就成了整个行业的主宰,如果把整个互联网的数据比喻为一座宝藏,那我们的爬虫课程就是来教大家如何来高效地挖掘这些宝藏, 掌握了爬虫技能,你就成了所有互联网信息公司幕后的老板,换言之,它们都在免费为你提供有价值的数据。
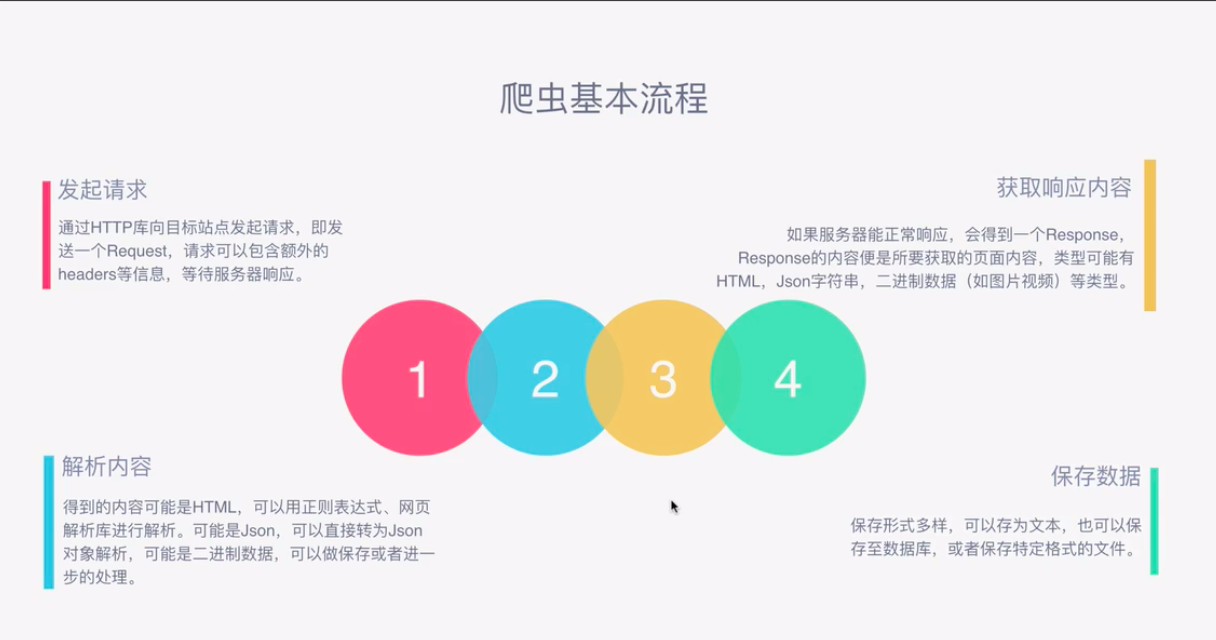
爬虫的流程:
我们平时在浏览网页的时候,在浏览器里输入一个网址,然后敲击回车,我们就会看到网站的一些页面,那么这个过程实际上就是这个浏览器请求了一些服务器然后获取到了一些服务器的网页资源,然后我们看到了这个网页。
请求呢就是用程序来实现上面的过程,就需要写代码来模拟这个浏览器向服务器发起请求,然后获取这些网页资源。那么一般来说实际上获取的这些网页资源是一串HTML代码,这里面包含HTML标签,还有一些在浏览器里面看到的文字。那么我们要提取的一些数据就包含在这些HTML文本里面。我们要做的下一步工作就是从这些文本里提取我们想要的一些信息(比如一段话,一个手机号,一个文字这类的),这就是我们提取的一个过程。提取出来之后呢我们就把提取出来的信息存到数据库啊文本啊这类的。这就是完成了一个数据采集的过程。
我们写完程序之后呢就让它一直运行着,它就能代替我们浏览器来向服务器发送请求,然后一直不停的循环的运行进行批量的大量的获取数据了,这就是爬虫的一个基本的流程。
爬虫的工作原理:
打开一个浏览器---输入网址---回车----看到呈现的有关关键字网站的列表(每一个网站里有标题,描述信息,站点,百度快照连接等等之类的)
我们要用爬虫抓取有关新闻的网页面的话怎么做呢? -----> 点击右键--审查元素---控制台(Elements是网页源代码(我们看到的网页就是源代码解析出来的),)-----> 把代码获取下来用一些解析库把代码解析出来然后存成一些结构化的数据。
什么是Request和Response?(请求和响应)
浏览器访问一个网站(域名:www.baidu.com)这个站点其实也是运行在一台一直运行着的电脑上的(这个就叫做服务器)
如果一点击回车的话,实际上我的浏览器就向这个服务器发送了一个请求,这个请求里面就包含了一些信息,比如我要请求某某某页面,那么这个流程就是向服务器发送了一个请求,这个服务器收到这个请求就会看你是什么浏览器发过来的,然后服务器经过解析之后呢向浏览器返回一个响应这就是一个Response。这Response里面内容呢就包含一些HTML代码,那么浏览器解析这些代码就是呈现出网页内容了。这个流程就是Request和Response(请求和相应)的一个过程。

我们要用爬虫抓取有关新闻的网页面的话怎么做呢? -----> 点击右键--审查元素---控制台(Elements是网页源代码(我们看到的网页就是源代码解析出来的),Network)-----> 把代码获取下来用一些解析库把代码解析出来然后存成一些结构化的数据。
Network选项卡
下面有个列表形式的东西,里面有网址,还有status,type。。。
name里面放的是浏览器的请求和服务器的相应的记录,点进一个去,有headers,preview,response,cookies,timing
headers :
request headers 请求头的信息
response headers 响应头的信息
general 请求的基本描述信息包括:请求的连接,请求的方法,请求的状态码,ip地址等等。。。
preview:
response: 源代码隐藏在这里,浏览器就解析这个代码,然后呈现出网页内容
cookies:
timing:
Request中包含什么?
请求,由客户端向服务端发出,可以分为4部分内容:请求方法(Request Method)、请求的网址(Request URL)、请求头(Request Headers)、请求体(Request Body)

一、请求方法 Request Method
常见的请求方法有两种:GET 和 POST。
在浏览器中直接输入URL并回车,这便发起了一个GET 请求,请求的参数会直接包含到URL里。例如在百度中搜索Github,这就是一个GET请求,链接为https://www.baidu.com/s? wd=Github&rsv_spt=1&rsv_iqid=0xebc1ff2d000fdfed&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&rqlang=cn&tn=baiduhome_pg&rsv_enter=1&oq=Python&rsv_t=7a32zwvyXvd90SKrPo8%2BE%2B5cMCxO5sqm7P9HJpvNjq5UpSqzHpZUi%2B6hBJRn6sGWg7lK&rsv_pq=ae74c7880000f00d&inputT=6006&rsv_sug3=27&rsv_sug1=23&rsv_sug7=100&rsv_sug2=0&rsv_sug4=6006,其中URL中包含了对请求的参数信息,这里参数 wd 表示要搜索的关键字。POST请求大多在表单提交是发起。比如,对于一个登录表单,输入用户名和密码后,点击"登录"按钮,这通常会发起一个POST请求,其数据通常以表单的形式传输,而不会体现在URL中。
GET 和 POST的区别?
GET请求中的参数包含在URL里面,数据可以在URL中看到,而POST请求的URL不会包含这些数据,数据都是通过表单形式传输的,会包含在请求体中。
GET请求提交的数据最多只有1024字节,而POST方式没有限制。
一般来说,登录时,需要提交用户名和密码,其中包含了敏感信息,使用GET 方法请求的话,密码就会暴露在URL中,造成密码泄露,所以这里最好以POST方式发送。上传文件时,由于文件内容比较大,也会选用POST方式。
我们平常遇到的绝大部分请求都是GET 和 POST请求,另外还有一些请求方法如HEAD、PUT、 DELETE、 OPTIONS、 CONNECT、 TRACE等,我们简单的将其总结为:
| 方法 | 描述 |
| GET | 请求页面,并返回页面内筒 |
| HEAD | 类似于GET请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| POST | 大多数用于提交表单或上传文件,数据包含在请求体中 |
| PUT | 从客户端向服务器传送的数据取代指定文档中的内容 |
| DELETE | 请求服务器删除指定的页面 |
| CONNECT | 把服务器当做跳板,让服务器代替客户端访问其他网页 |
| OPTIONS | 允许客户端查看服务器的性能 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断 |
二、请求的网址
请求URL即统一资源定位符,它可以唯一确定我们想请求的资源。比如一个网页文档、一张图片、一个视频等都可以用URL来确定。
三、请求头 Request Headers (键值对的形式) 请求的一些配置信息告诉服务器,让服务器判断这些配置信息解析
请求头,用来说明服务器要使用的附加信息,比较重要的信息有Cookie,Referer,User-Agent等。
下面简要说明一些常用的头信息。
Accept: 请求报头域,用于指定客户端可接受哪些类型的信息。
Accept - Language: 指定客户端可接受的语言类型。
Accept-Encoding: 指定客户端可接受的内容编码。
Host:用于指定请求支援的主机IP和端口号,其内容为请求URL的原始服务器或网关的位置。从HTTP1.1版本开始,请求必须包含此内容。
Cookie: 也常用复数形式Cookies,这是网站为了辨别用户进行会话跟踪而存储在用户本地的数据。它的主要功能是维持当前访会话。例如,我们输入用户名和密码成功登录某个网站后,服务器会用会话保存登录状态信息,后面我们每次刷新或请求该站点的其他页面时,会发现都是登录状态,这就是Cookies的功劳。Cookies里有信息标识了我们所对应的服务器的会话,每次浏览器在请求该站点的页面时,都会在请求头加上Cookies 并将其返回给服务器,服务器通过Cookies识别出是我们自己,并且查出当前状态是登录状态,所以返回结果就是登陆之后才能看到的网页内容。
Referer: 此内容用来标识这个请求是从哪个页面发过来的,服务器可以拿到这一信息并做相应处理,如做来源统计、防盗链处理等。
User-Agent: 简称UA,它是一个特殊的字符串头,可以使服务器识别客户使用的操作系统及版本、浏览器及版本等信息。再做爬虫时加上此信息,可以伪装为浏览器:如果不加,很容易可能被识别出为爬虫。
Content-Type: 也叫互联网媒体类型(Internet Media Type)或者MIME类型,在HTTP协议消息头中,它用来表示具体请求中的媒体类型信息。例如,text/html 代表HTML格式,image/gif 代表GIF图片,application/json 代表JSON类型,更多对应关系可以查看此对照表:
http://tool.oschina.net/commons.
因此,请求头是请求的重要组成部分,在写爬虫时,大部分情况下都需要设定请求头
四、请求体
请求体一般承载的内容是POST请求中的表单数据,而对于GET请求,请求体则为空。
例如,我们登录GitHub时捕获到的请求和响应如图:
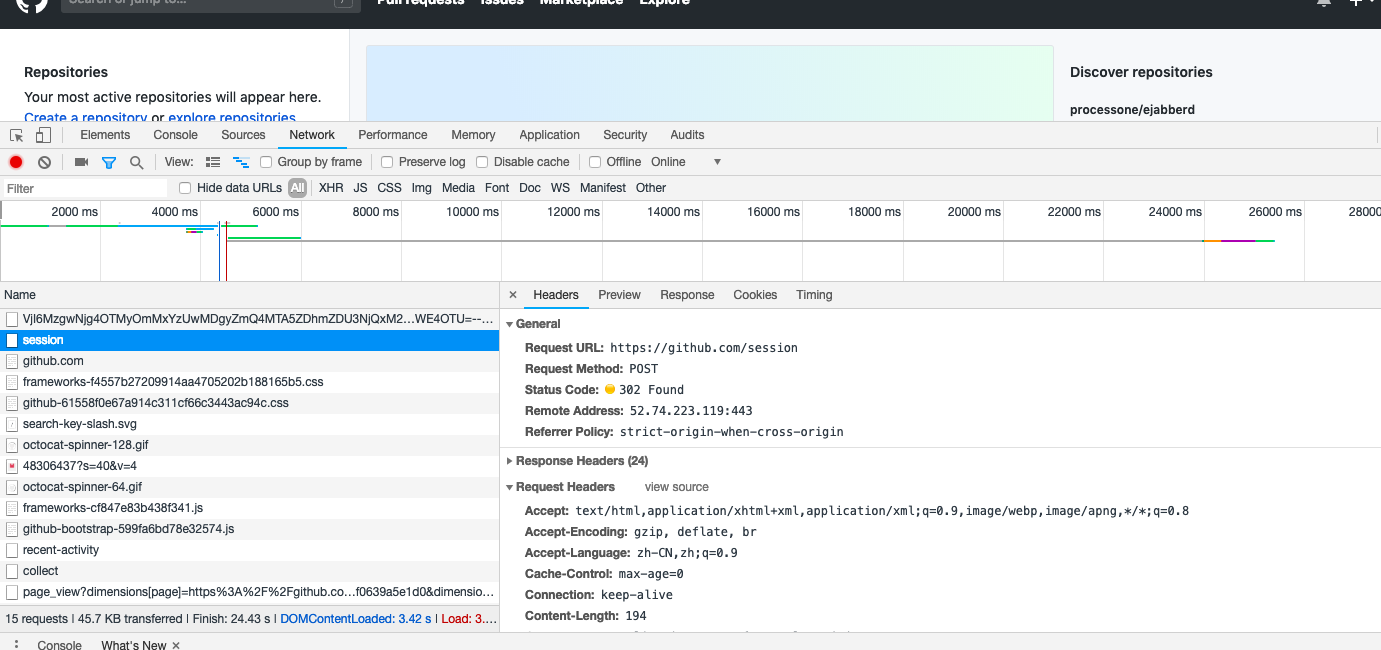
登录之前,我们填写了用户名和密码信息,提交时这些内容就会以表单数据的形式提交给服务器,此时需要注意 Requsest Headers 中指定的Content-Type 为 application/x-www-form-urlencoded。只有设置Content-Type为application/x-www-form-urlencoded,才会以表单数据的形式提交。另外,我们也可以将Content-Type 设置为application/json来提交JSON数据,或者设置为multipart/from-data来上传文件。
以下表列出了Content-Type 与 POST提交数据方式的关系
| Content-Type | 提交数据的方式 |
| application/x-www-form-urlencoded | 表单数据 |
| multipart/from-data | 表单文件上传 |
| application/json | 序列化JSON数据 |
| text/xml | XML数据 |
在爬虫中,如果要构造POST请求,需要使用正确的Content-Type,并了解各种请求库的各个参数设置时使用的是那种Content-Type,不然可能会导致POST提交后无法正常响应。
Response中包含什么内容?
响应,由服务端返回给客户端,可以分为三部分:响应状态码(Response Status Code)、响应头(Response Headers)、响应体(Response Body)

1、响应状态码
响应状态码表示服务器的响应状态,如200代表服务器正常响应,404代表页面未找到,500代表服务器内部发生错误。在爬虫中,我们可以根据状态码来判断服务器响应状态,如状态码为200,则证明成功返回数据,在进行进一步的处理,否则直接忽略。
2、响应头
响应头包含了服务器对请求的应答信息,如Content-Type、Server、Set-Cookie等。下面简要说明一些常用的头信息。
Date: 标识响应产生的时间。
Last-Modified: 指定资源的最后修改时间。
Content-Encoding:指定响应内容的编码。
Server: 包含服务器的信息,比如名称、版本号等。
Content-Type: 文档类型,指定返回的数据类型是什么,如text/html代表返回HTML文档,application/x-javascript则代表返回JavaScript文件,image/jpeg则代表返回图片。
Set-Cookie: 设置Cookies。响应头中的Set-Cookie 告诉浏览器需要将此内容放在Cookies中,下次请求携带Cookies请求。
Expires: 指定响应的过期时间,可以使代理服务器或浏览器将加载的内容更新到缓存中。如果再次访问时,就可以直接从缓存中加载,降低服务器负载,缩短加载时间。
3、响应体
最重要的当属响应体的内容了。响应的正文数据都在响应体中,比如请求网页时,它的响应体就是网页的HTML代码;请求一张图片时,它的响应体就是图片的二进制数据。我们走爬虫请求网页后,要解析的内容就是响应体,如图所示:
在浏览器开发者工具中点Preview,就可以看到王爷的源代码,也就是响应体的内容,它是解析的目标。
在做爬虫时,我们主要通过响应体得到的网页的源代码、JSON数据等,然后从中做相应内容的提取。
用http请求库向服务器发送一个请求,然后得到这个response,把这个响应体里的内容拿下来,然后解析就可以拿到我们的数据了。
爬虫能抓怎样的数据呢?
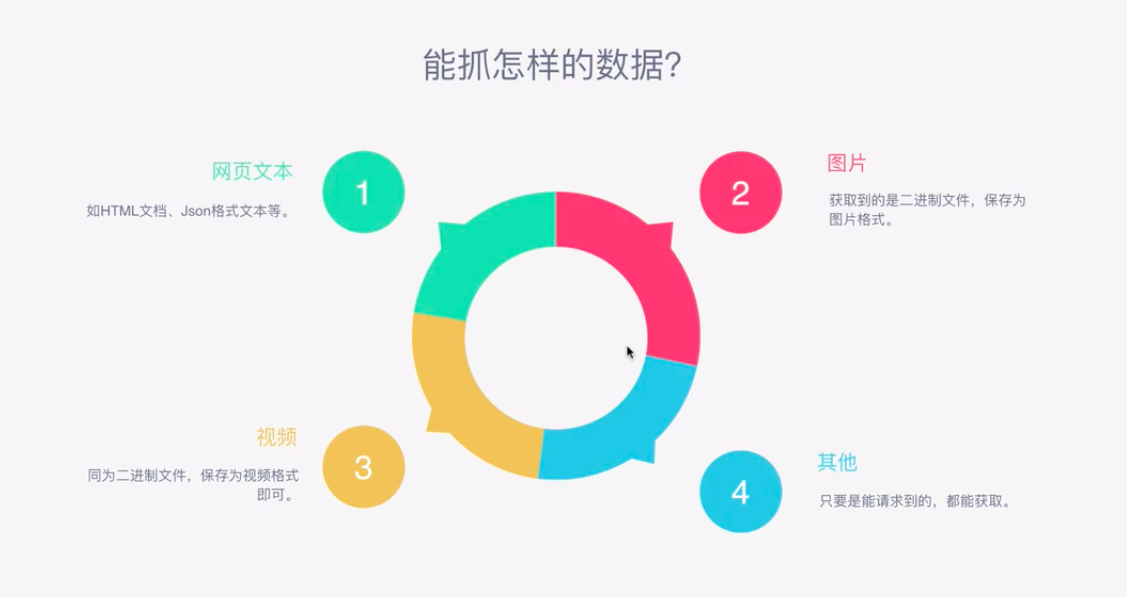
怎样来解析?

为什么我抓到的数据和浏览器中看到的不一样?
怎么解决JavaScript渲染的问题?

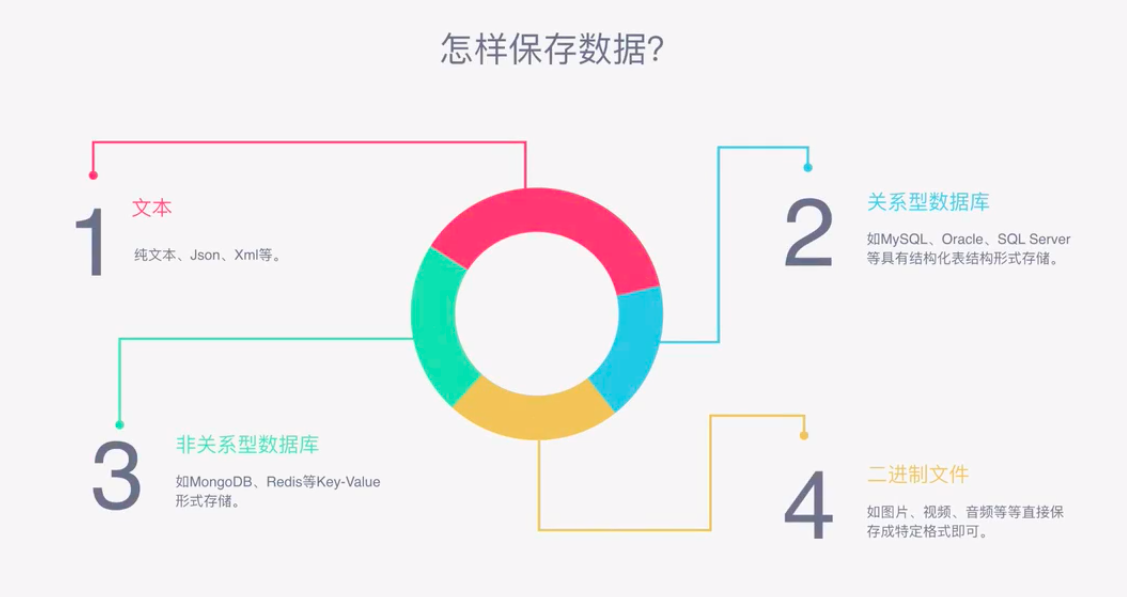
怎样可以保存数据?