本篇博客
1.Controller监控图表(有6张图表,在Controller里。)
2.windows服务器资源监控
3.nmon工具的使用
3.1 捕获数据
3.2 分析数据
4.Analysis
4.1 summary report(概要部分)
4.2 图表信息(也有6张图表,不过在分析器里)
5.测试报告
6.总结
6.1 性能测试流程
6.2 LoadRunner性能测试
1.Controller监控图表
Controller监控图表
- running vuser
- Trans/sec
- RT
- hits/sec
- Throughput
- System resources
System resources:
1.windows resources
2.Linux:
- rpc服务
- nmon工具
2.windows服务器资源监控
测试机和服务器不在同一台机器上,服务器是windows的。
监控服务器资源的时候要注意,之前监控windows资源都可以监控的到,是因为LoadRunner和windows服务器(也就是项目)在同一台机器上,并没有涉及到ip能不能ping通这样的问题。但是很多情况,如果服务器,
是一个windows服务器。我们LoadRunner想要去监控它的时候,有的时候是ping不通的,也的时候监控也会报错。
例:
1)直接打开LoadRunner的Controller的。
2)随便选择一个脚本。
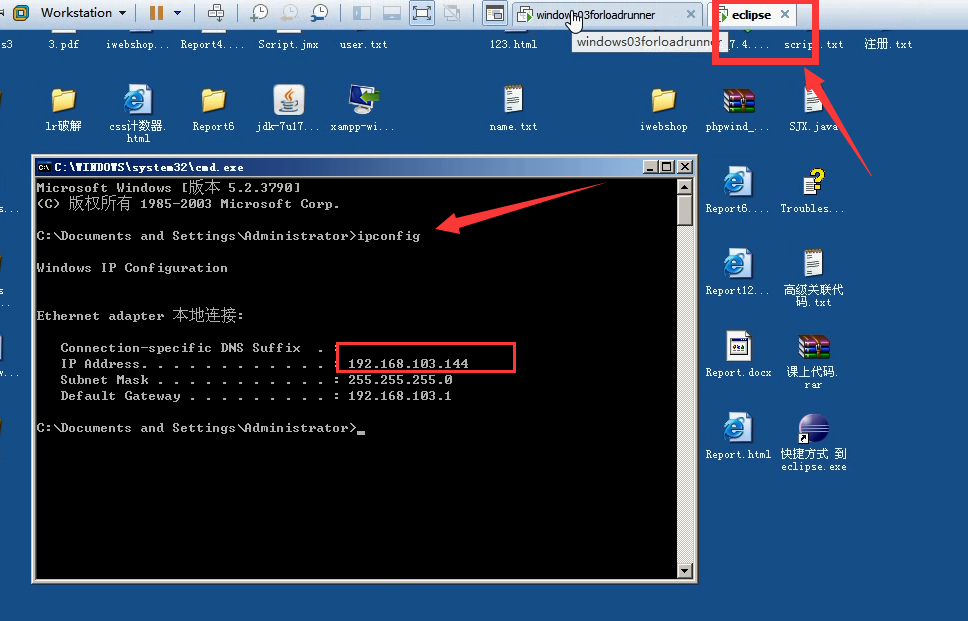
3)比如说服务器并不是这台机器,而是另一台。而是另一台虚拟机里面的(eclipse)。
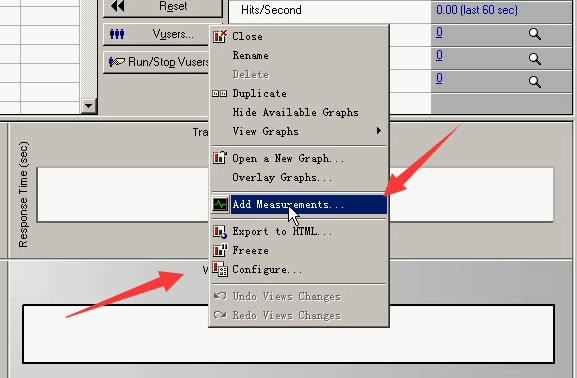
4)选择windows-------单击右键-----Add Measurements
5)ip写那台服务器的ip,不能写本机的。
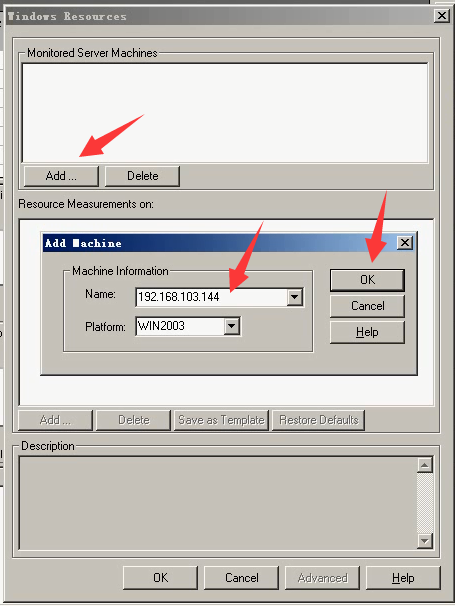
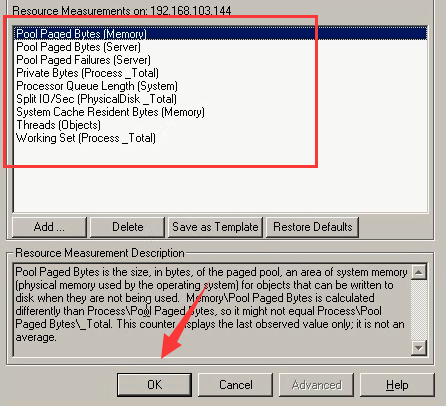
6)把没用的资源,删几个。(这里随笔留几个)
7)有报错,连接不上。
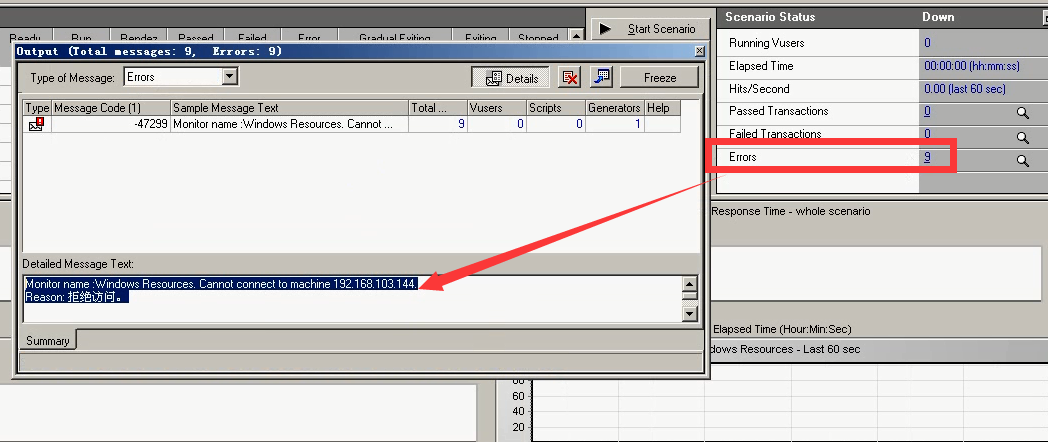
注意:即使我们的服务器是windows的,如果我们的压力机(测试机)和服务器不在同一台电脑上的时候,也是连不上的。如果连不上,需要做一个东西就可以了。
需要操作:
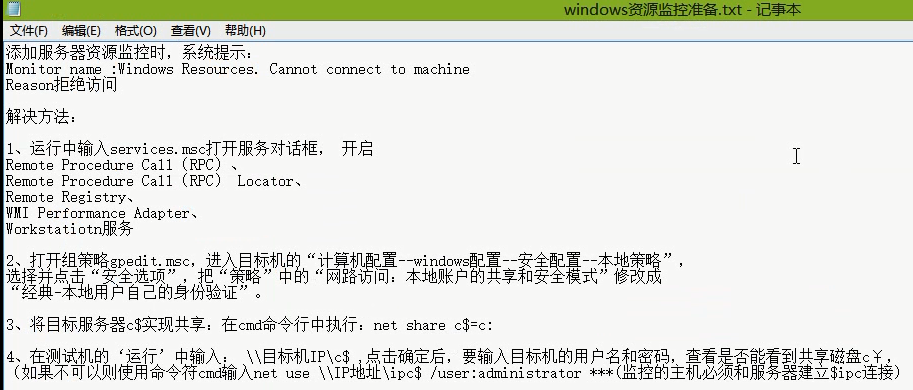
文字版本
1.服务器中服务列表services.msc--->开启服务
- Remote Procedure Call(RPC)、
- Remote Procedure Call(RPC) Locator、
- Remote Registry、
- WMI Performance Adapter、
- Workstatiotn服务
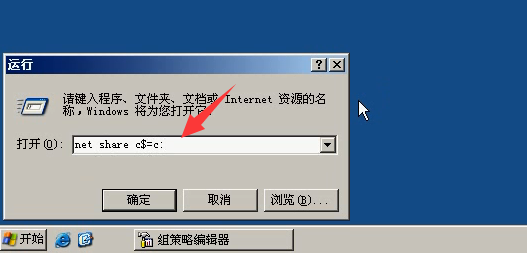
2.在服务器:计算机配置--windows配置--安全配置--本地策略”,选择并点击“安全选项”,把“策略”中的“网路访问:本地账户的共享和安全模式”修改成“经典-本地用户自己的身份验证”。
3.将服务器的C盘实现共享。运行--->net share c$=c:
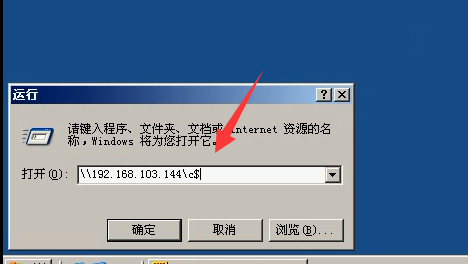
4.测试机进行测试。运行--->\服务器ipc$
5.如果能够看到服务器的C盘共享,此时再次在Controller的windows resources中添加服务器的Ip以及监控的指标即可
例:
1)打开服务列表:cmd-----输入:services.msc
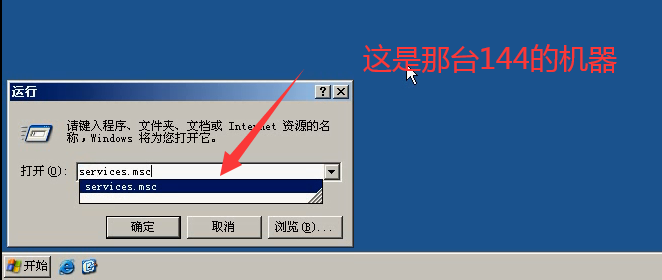
2)远程服务开启:显示已启动,就不用再启了。如果没有启动,就单击右键---启动起来。
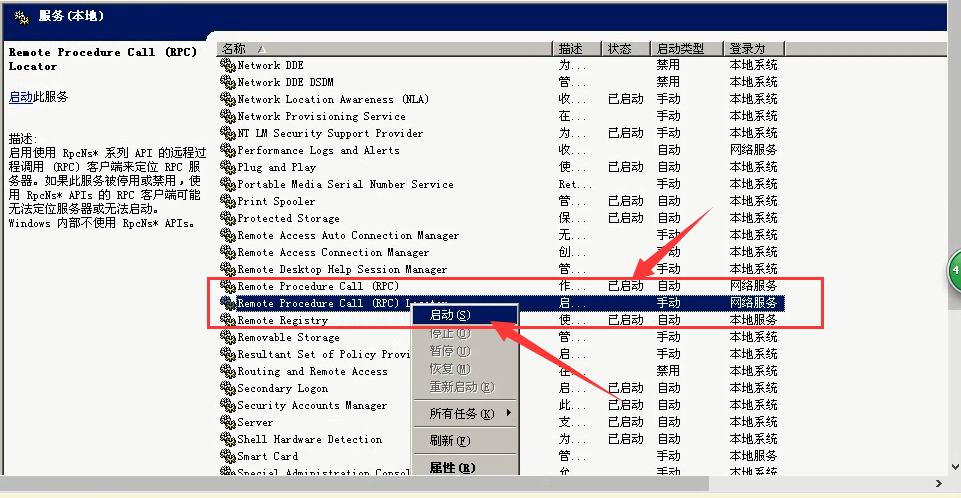
还有下面的也要启,下面的是启好了。

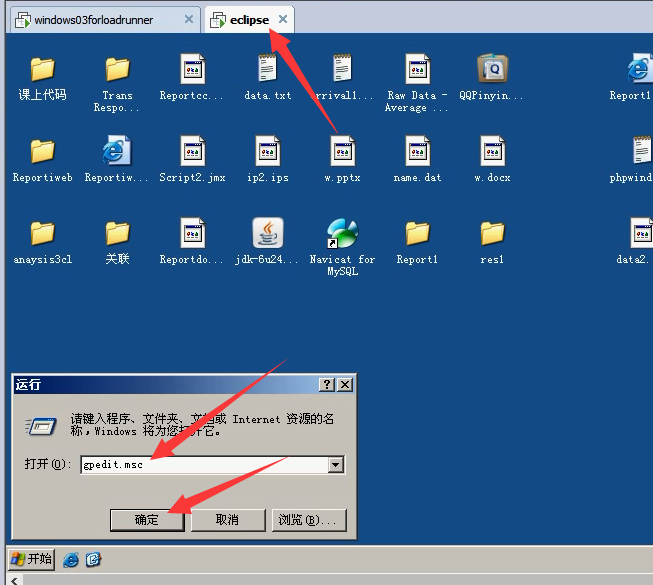
3)打开组策略编辑器:进入cmd窗口-----gpedit.msc(也还是144的服务器)
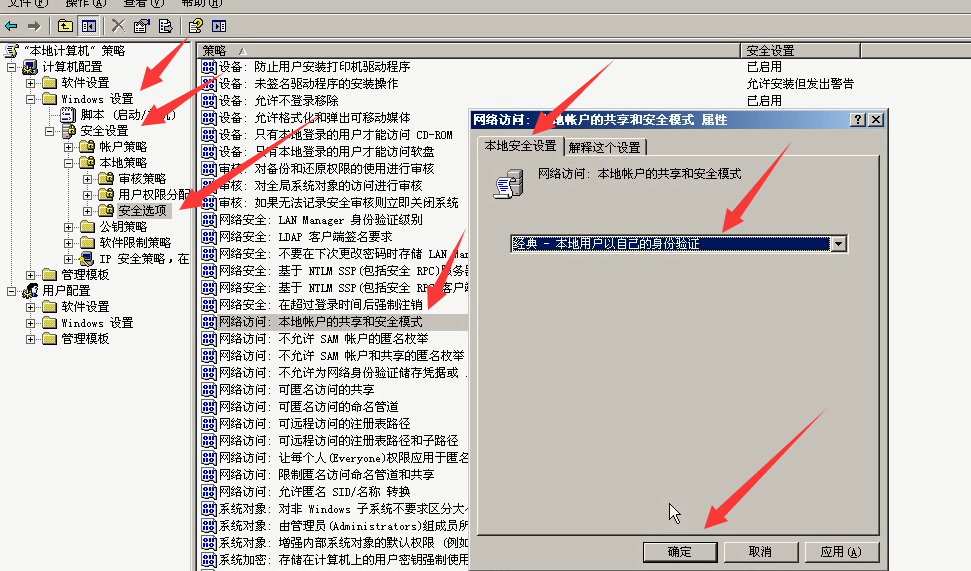
4)windows设置-----安全设置-----本地策略-----安全选项-----找到(本地账户的共享和安全模式)-----右键---属性----修改成,经典本地用户以自己的身份验证
5)将目标服务器的c盘实现共享,看一下效果的。(这里还是144机器上。)
那么客户端应该就可以访问144服务器上的c盘。如果可以就说明客户端和服务器就能联通。
6)在客户端的机器上,输入以下。
7)密码:123456
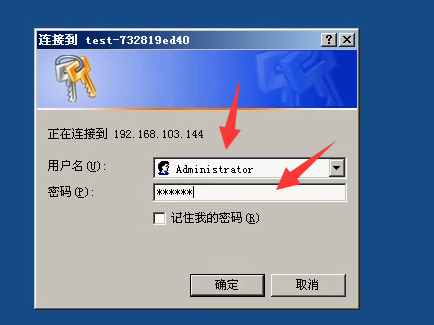
8)可以看到144服务器上c盘的内容。
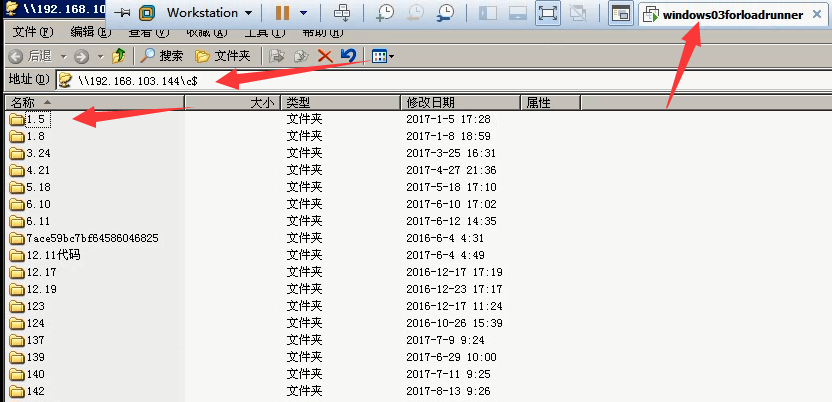
可以对一下,144服务器上c盘的内容。是一样的。
注意:现在测试机(windows的LoadRunner),监控目标服务器(eclipse)的时候就可以了。

9)把之前的删除了。Windows资源重新添加ip,下面的指标随便删删,点击ok。(2和3的顺序反了)
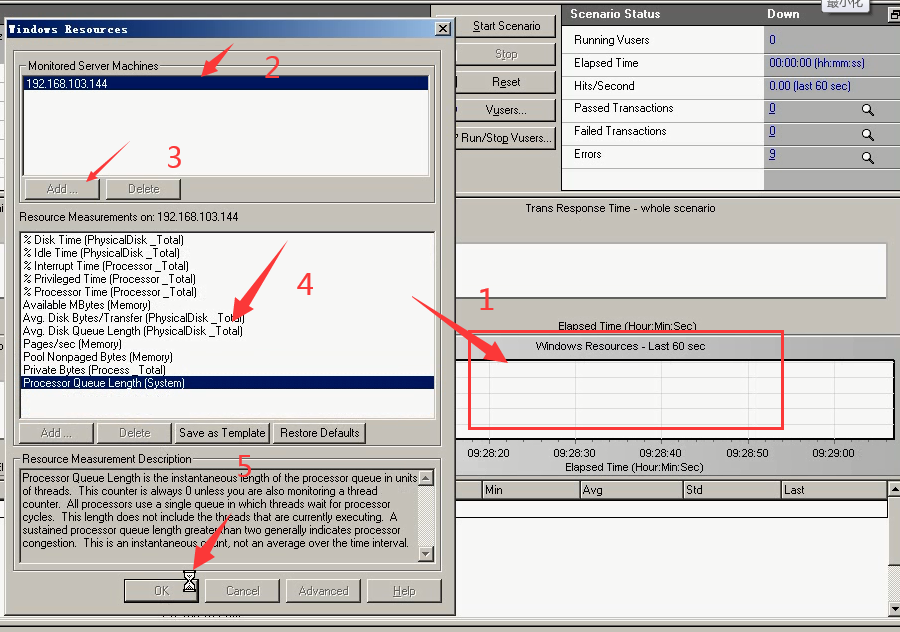
10)现在访问就没什么问题了。
3.nmon工具的使用
测试机和服务器不在同一台机器上,服务器是Linux的。(比windows服务器更常见),需要使用第三方工具:nmon。
3.1 捕获数据
1.将nmon工具在linux中进行解压
2.将文件nmon_x86_64_centos6重命名为nmon
3.捕获数据
./nmon -f -s 5 -c 100 -m /home
参数
- -f:文件名是以捕获时间命名
- -s:每隔一定的时间捕获一次数据
- -c:捕获数据的次数
- -m:捕获的数据文件的位置
例:
1)将nomon_linux_14i.tar.gz包放入centos中,如放在/data/nmon下
如果不能将文件拖入到centos中,可以设置共享。选中Centos-1教学-------虚拟机------设置----共享文件夹-----添加要共享的文件夹----确定
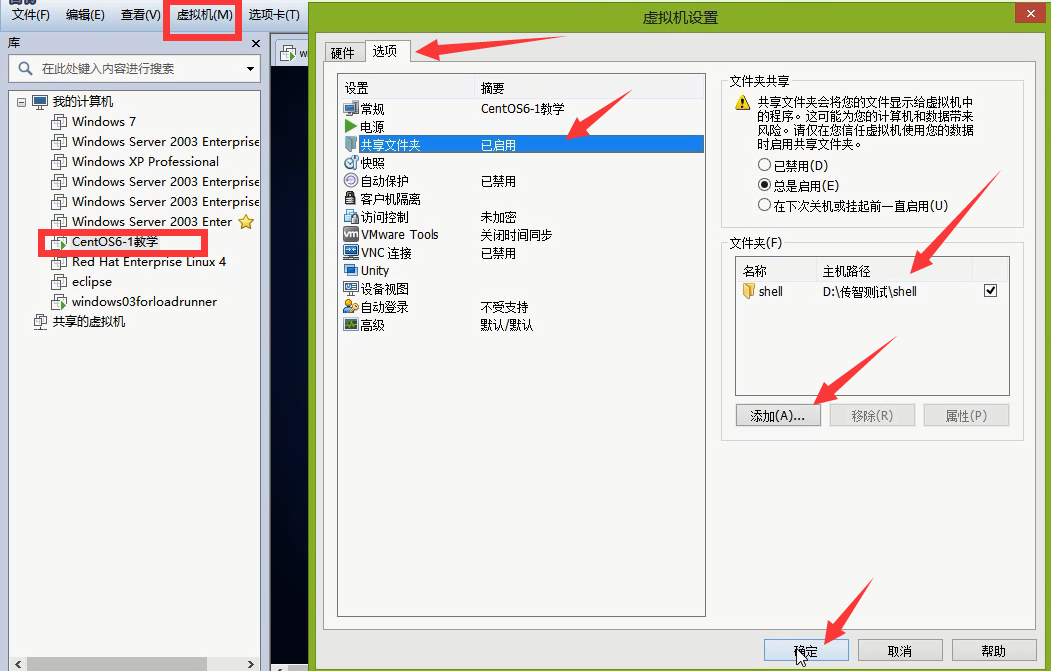
按照下面的操作,共享文件夹的位置是/mnt/hgfs/。(也可以拷贝到别的文件夹下面。)
2)解压nomon_linux_14i.tar.gz包

3)执行: ./nmon_x86_64_centos6
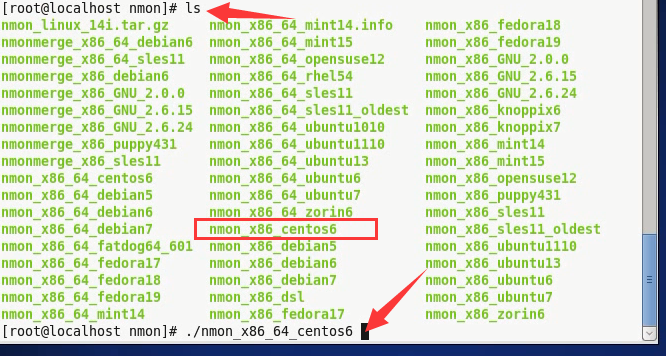
显示图标MNON。说明就启起来了。
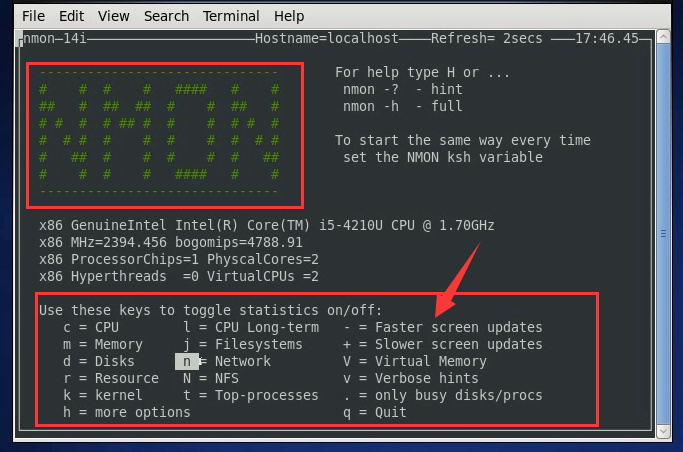
可以通过不同的键盘输入监控不同数据
按c:监控的是CPU的信息。
按m:监控的是内存信息。
按d:监控的是磁盘信息。
按q:退出。
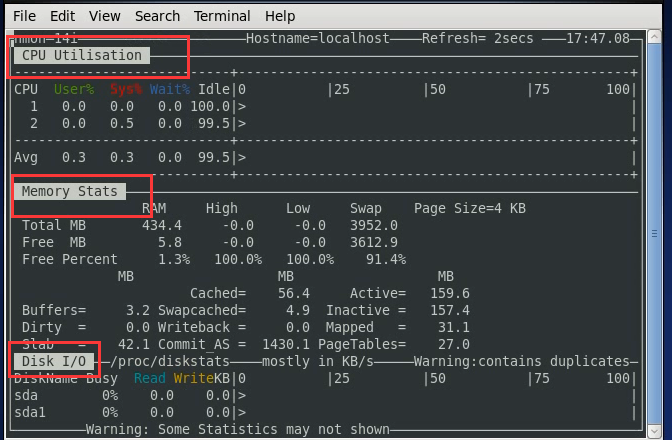
这些很像linux的命令:top。
命令有个不好的地方,只能实时的去看,不能拿出来分析。现在的nmon也是这样。
4)感觉名字太长,修改个简单的名字:找到nmon_x86_64_centos6,并重命名为nmon

5)捕获数据到文件
举例1:每1秒捕获数据快照,捕获20次:nmon -f -s 1 -c 20 -m /home/
举例2:每30s捕获数据快照,捕获120次,包含进程信息
nmon -f -t -s 30 -c 120 -m /home
参数解释:
-s: 每x秒采集一次数据
-c: 采集Y次
-f :生成的数据文件名中包含文件创建的时间
-t:在导出的信息中包含前几位的进程信息
-m :生成的数据文件的存放目录
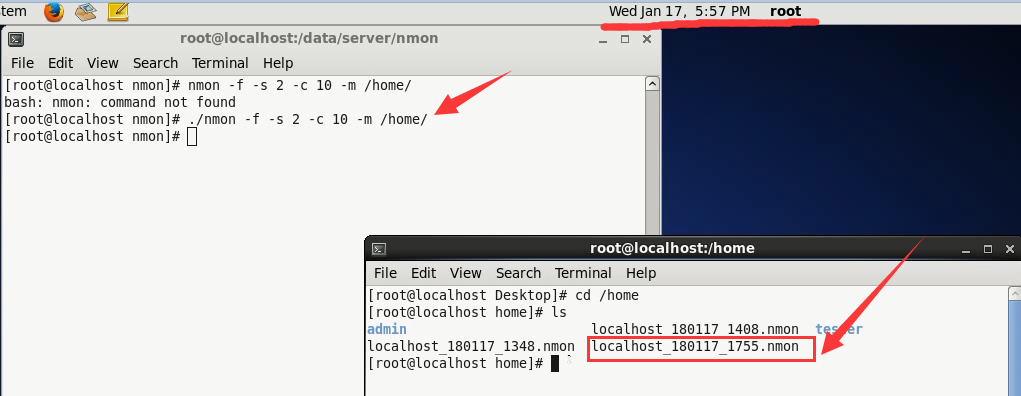
6)拷贝出来,放在共享文件夹中。

就可以找到该打文件了。

怎么打开呢?就用到下面的。
3.2 分析数据
nmon_analyser
1.打开.xlsm文件
2.解除宏禁用
3.点击Analyze nmon data,并找到监控数据的路径
4.保存数据的最新路径(xlsx文件)
5.分析器打开,并查看到服务器的资源
例:
1)直接解压zip文件,双击xlsm。
2)选项----宏(启用此内容)-----确定
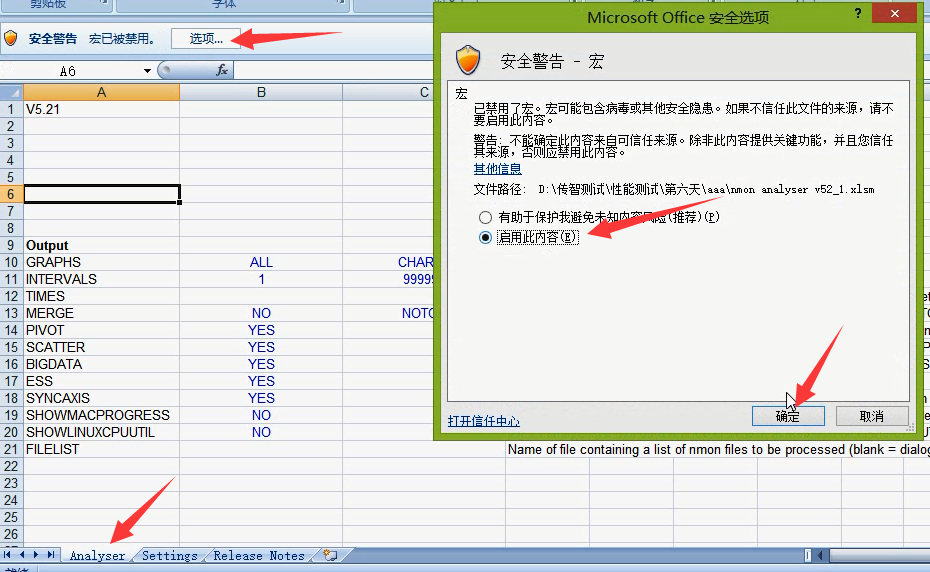
3)添加文件,点击打开。
它会让你重新保存一下xlsx的,保存在桌面上。
4)就会看到一些信息。
以后在压测的过程中,把nmon开启起来,估算啥时候压完,就取多长时间。同样的LoadRunner的数据也可以取出来。
如果压的是Linux的,就别在服务器上装那个rpc了。直接用nmon工具。
4.Analysis
4.1 summary report
1)统计概要:Statistics summary
- 最大用户数
- 吞吐量
- hits/sec
2)事务概要(这是最关注的)
看时间是不是达到我们设定的,或者说看百分之多少的事物达到这个设定的时间。
例:要求90%的事物要达到2秒以内。
直接加个过滤,90%。就可以看大90%事物的通过时间。如果在2秒以内,就过去了,没有问题。
事务的时间:
- 最大
- 最小
- 平均
- 百分比
- Std. Deviation----------偏移量(越小越好)
3)响应概要
- 响应状态码
- 总数
- 每秒响应数
例:
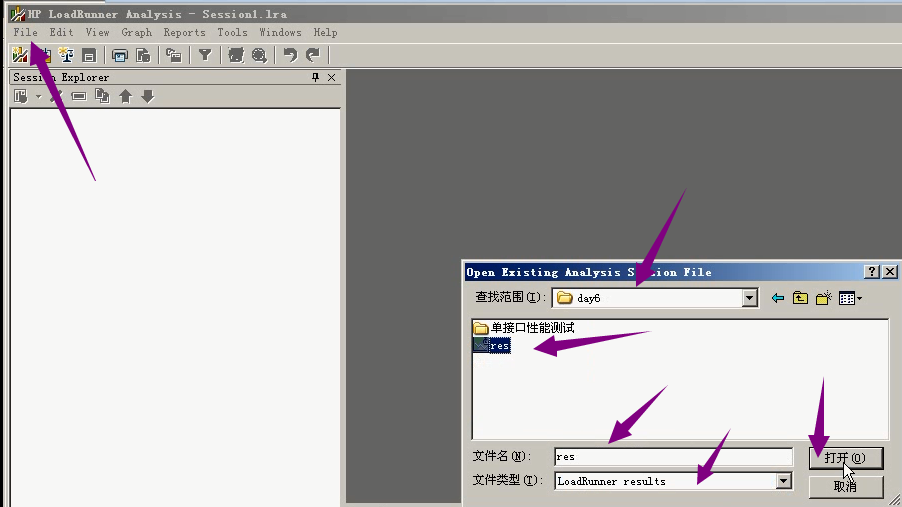
1)之前压过一个webtours关联的。打开分析器看一下。
2)File-----open----找到day3下的res-----文件类型:LoadRunner results-----打开
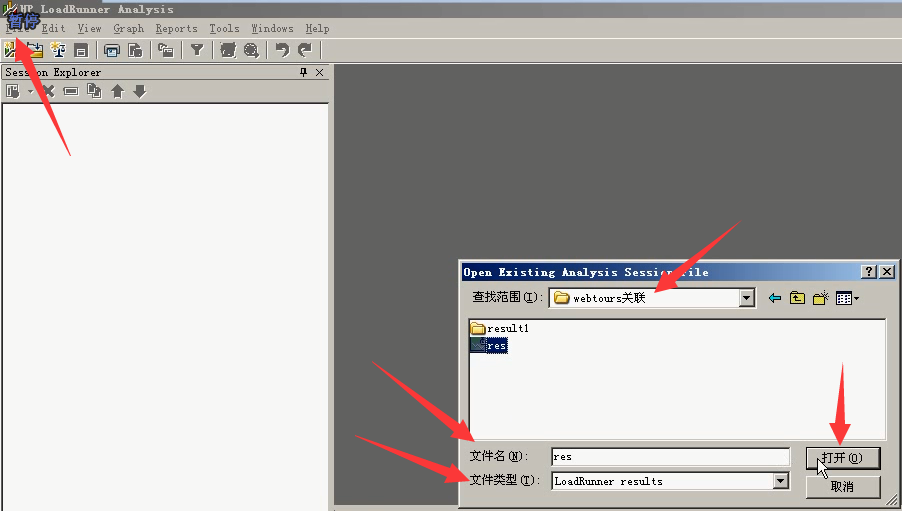
正常情况下就是Controller下压完,在分析器里看效果。
3)总体:分为报告和图表两部分。报告下面分支:概要报告。(右边就是概要报告的详细)
概要报告:分析器概要部分,统计概要部分,事物概要部分,响应概要信息。
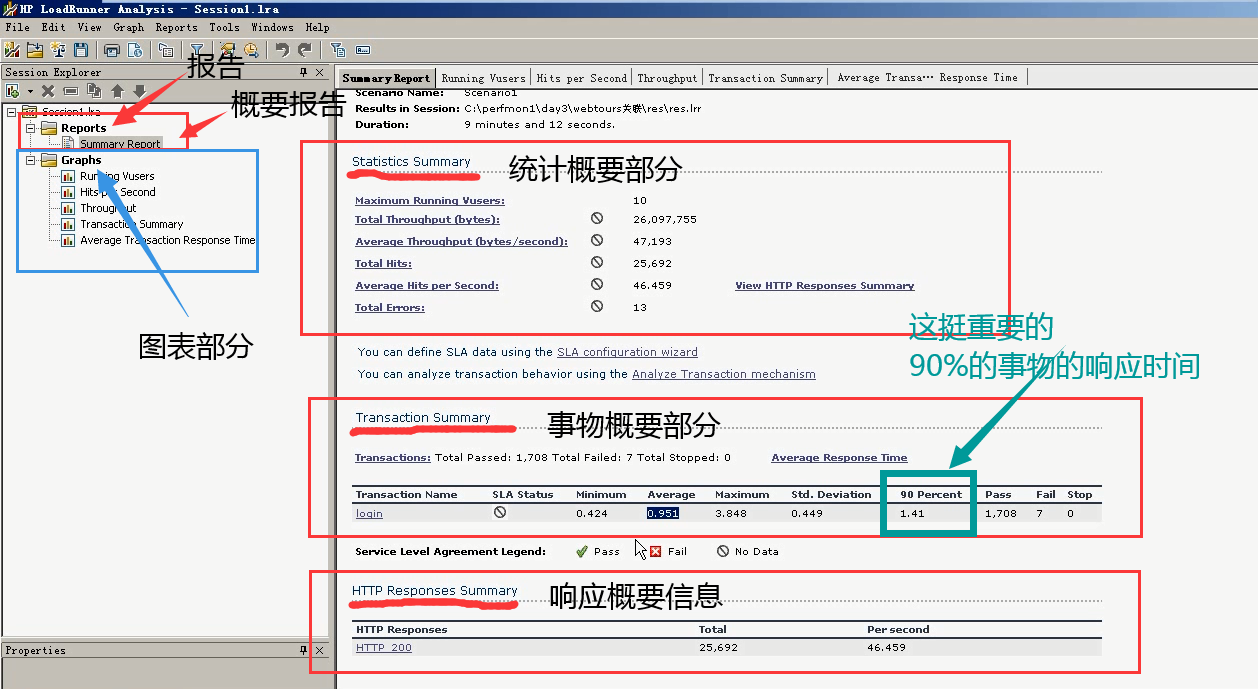
Analysis Summary部分
名称,结果目标,持续时间。(注意:这里是从开始到结束的时间,并不是Duration,Duration有可能只是其中的5分钟。)
Period:压的时间(什么时候压的,压的多长时间。)

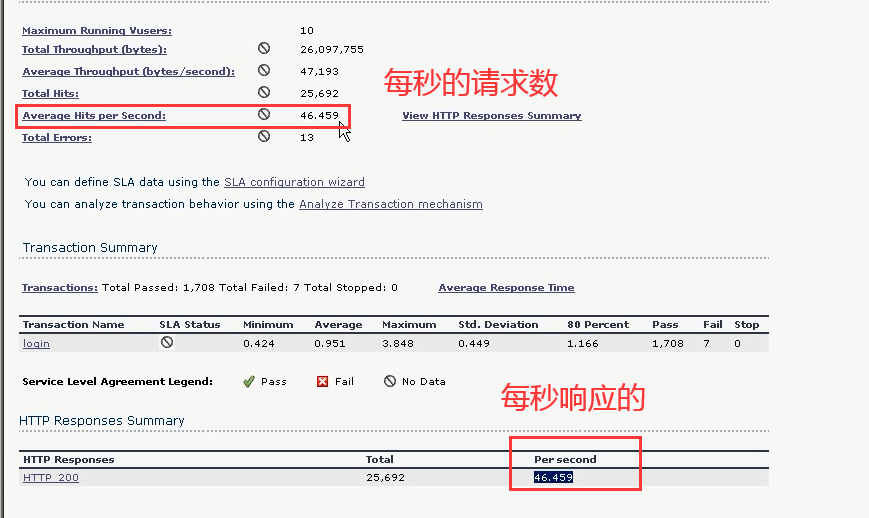
第一部分:统计概要部分
最大用户数为:10个
总共的吞吐量,字节数。
平均的每秒的字节数:可以算每秒的兆币数,可以根据实际带宽作比较。
总共压的过程中的请求数
平均每秒的请求数=Total Hits/Duration(从开始到结束的时间)
总的错误

第二部分:事物概要部分(描述事物的平均,最大,最小,百分比:百分之多少的事物的通过的时间。通过,失败的事物数。)
总共通过1708个事物,失败了7个。
响应时间:最小,平均,最大
其中平均响应时间:只针对验收测试的人或者客户来说。因为不准,只针对不懂的人。
90 percent:表示90%的事物的响应时间是1.41。(和公司开发或者运维来说,大部分的。)这是很重要的。
通过数为1708,失败数为7。停止为0(由于失败的没有往下走,所以stop为0)。

注意:上面的90 percent是可以修改的。
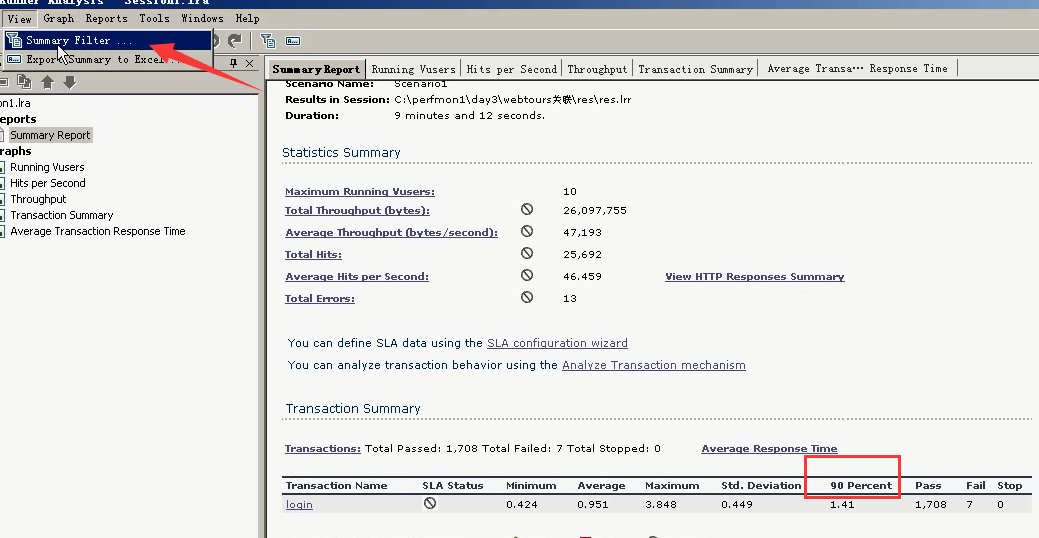
事物的百分比:修改成80%。
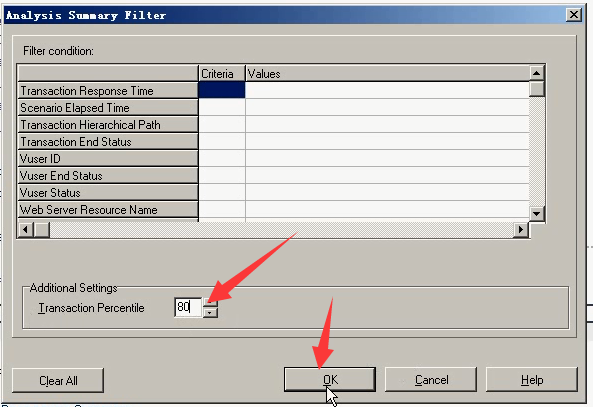
这里就改成了80%的事物的响应时间。
这里就可以改成80%的事物,时间是多少。90%的事物的时间是多少。观察到底是哪些用户的增加,让时间数据突然增大。

第三部分:响应概要信息
响应状态码:200
总共的响应信息:25692
每秒响应多少:46459

上面表示:每秒请求的,已经都处理了。(因为显示每秒请求数和每秒响应数相等。)
4.2 图表信息
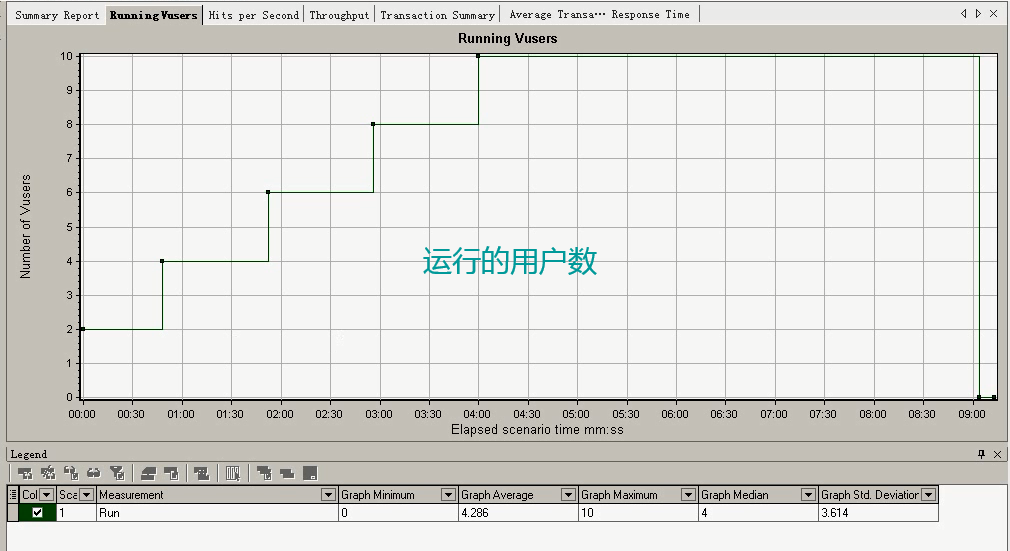
- Running Vusers:运行的用户数
- Hits Per Second :每秒点击数
- Throughput:吞吐量
- Average Transaction Response Time:事务平均响应时间
- 页面细分系统资源:Web Page Diagnostics(有很多)
- 系统资源:windows Resources
1 运行的用户数:Running Vusers
每50秒加载2个
设置过滤:单击右键------Set Filter/Group By
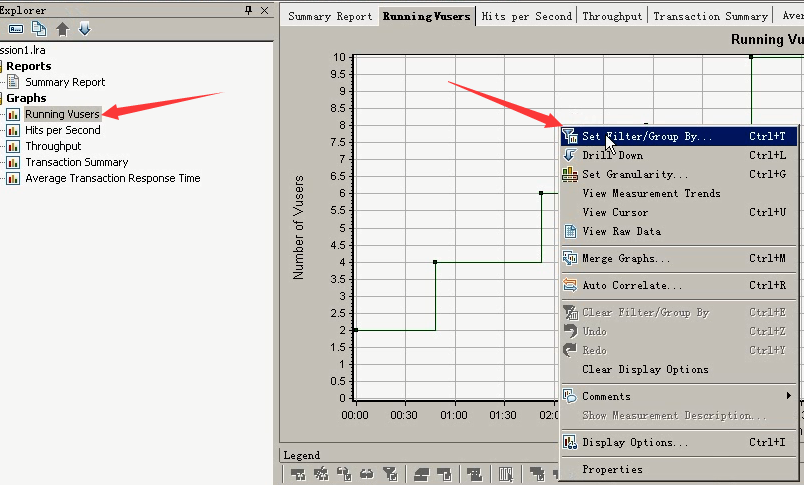
Criteria:
=
<>:不等于
like, not like
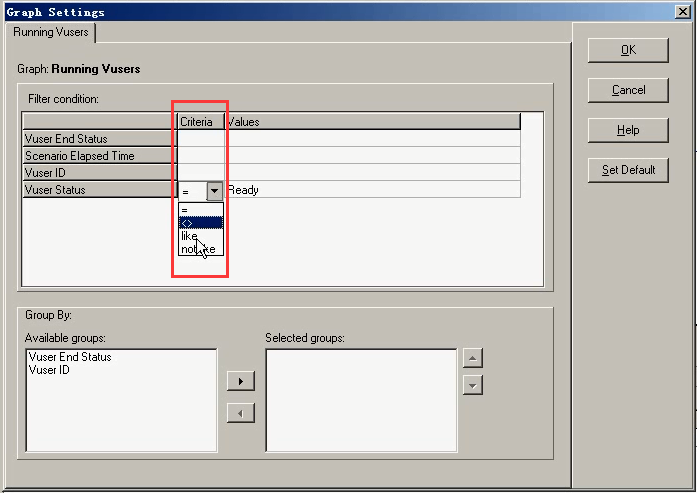
Vaules:Load Pause Quit Ready Run
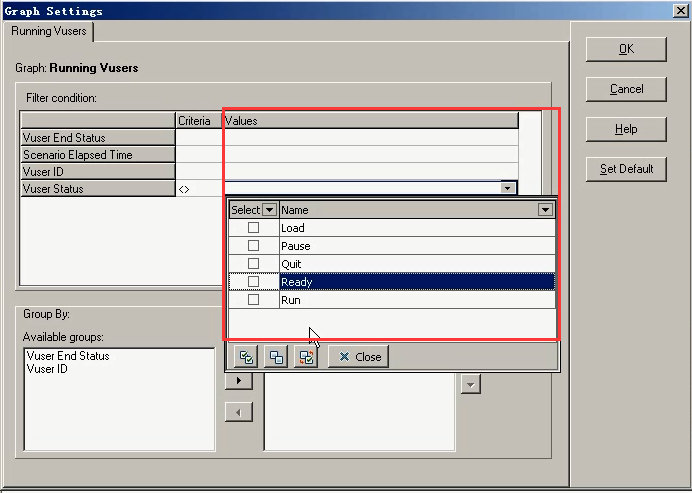
设置一些过滤:比如说看一些准备状态
单击右键------Set Filter/Group By---- = Ready------Ok

当时设置初始化过程,那个单词特别长,一次性加载进来。
设置:不等于run状态下信息
单击右键------Set Filter/Group By------<> Run----OK
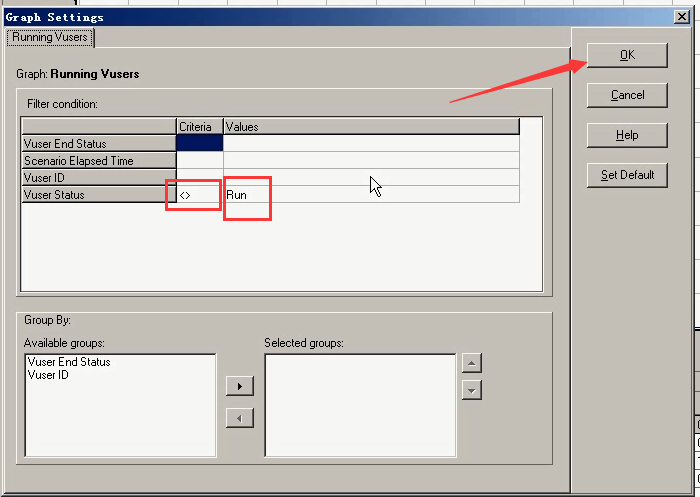
看一些都拿出来了
设置:= run状态的。
单击右键------Set Filter/Group By----- = Run -----OK。
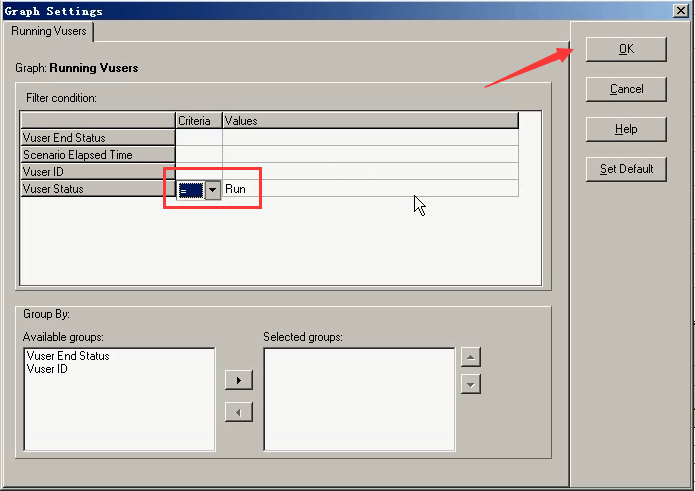
看一下:运行的用户数
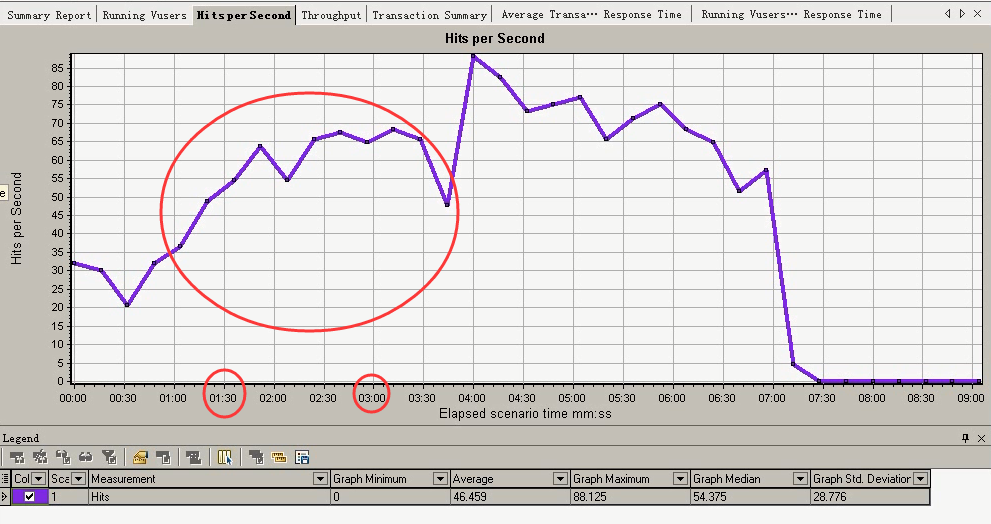
2 每秒点击数:Hits per second
是Vuser每秒向web服务器提交的HTTP请求数,查看其曲线情况可以判断被测系统是否稳定,曲线呈现下降趋势表名web服务器的响应速度在变慢,其原因可能是服务器瓶颈问题,
也有可能是Vuser数量减少,访问服务器的HTTP请求减少。
看下面的图:4分钟的时候,每秒点击数是最大的。

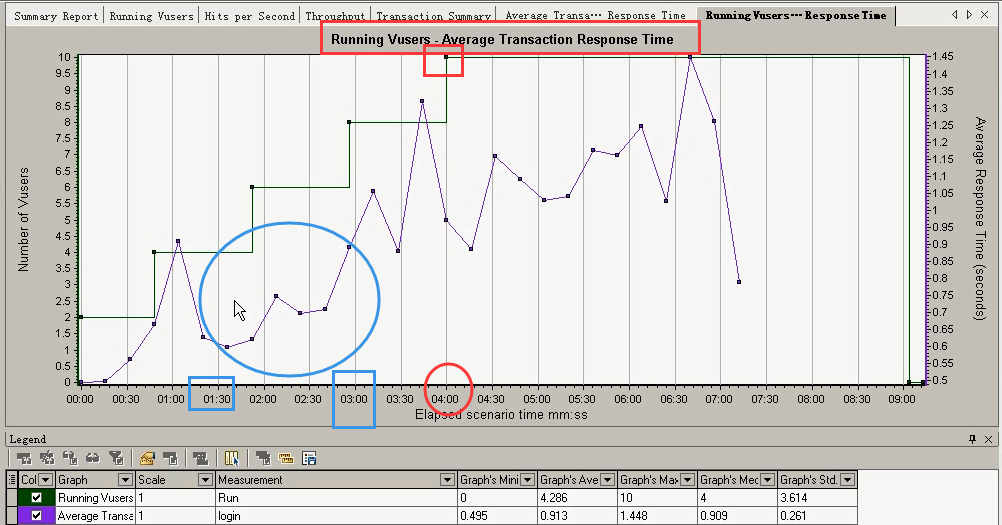
看下面的图(Running vusers和Transaction Response)有两个点:
第一个点:结合上面的,四分钟的时候(最大请求数),Running vusers对应的是10个用户。
第二个点:在1:30~3:00分钟的时候,响应时间在下降。为什么在下降?
看下面的图(每秒点击数)
在1:30~3:00(上面的响应时间图表在这个阶段是下降),每秒点击数是上升的。
结合这2点,说明在轻负载区。
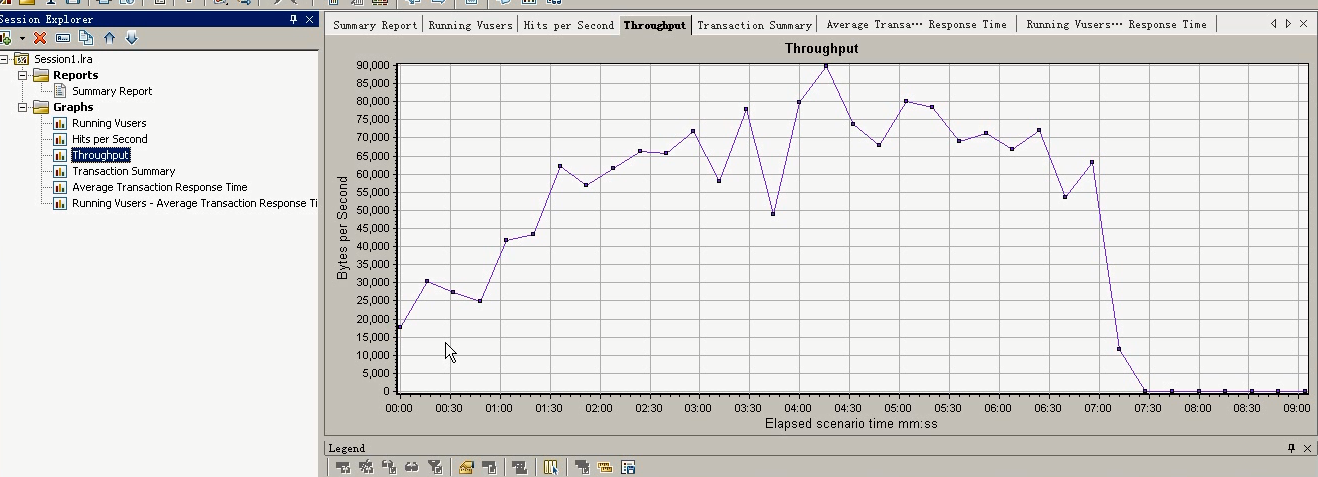
3 吞吐量:Throughput
指的是单位时间内客户端和服务器成功传递数据的数量,即任意时间服务器发送给Vuser的流量,其是度量服务器性能的重要指标,度量单位是字节,另外也有兆字节
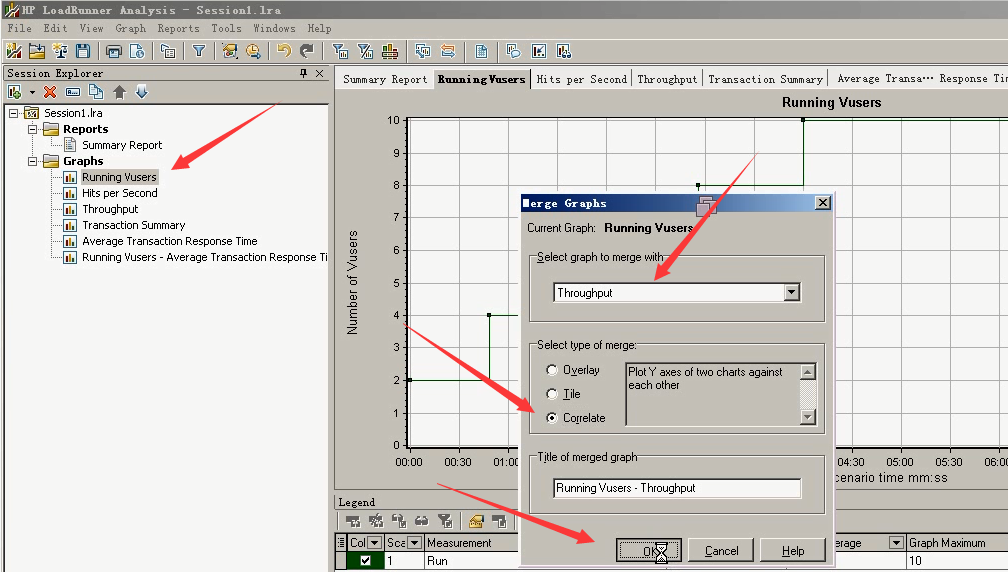
合并图1::Running Vuser ----Throughput合并关联图
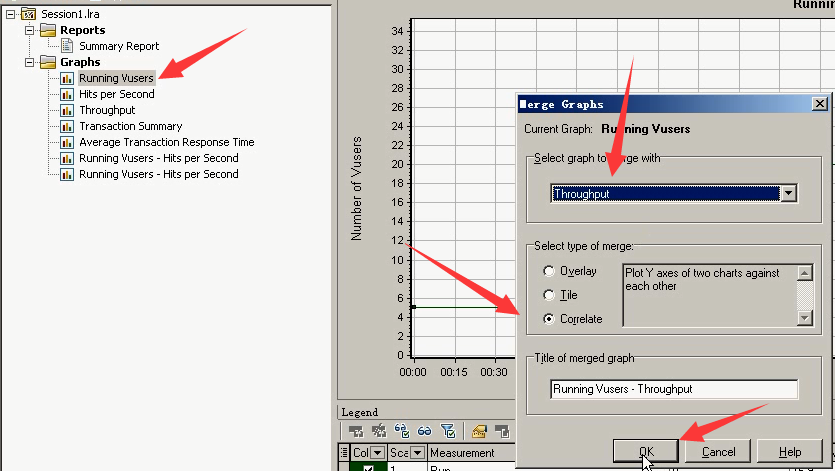
把吞吐和Running Vusers合并关联图:右键-----选中Running Vusers-----Throughput-----选择关联----点击ok。
并发用户数和吞吐量瓶颈之间存在一定的关联,(在网络和服务器正常情况下,随着并发用户数增加,网络吞吐量也会增加)因此可以通过不断增加并发用户数和吞吐量观察系统的性能瓶颈,然后从网络、数据库、应
用服务器和代码4个环节确定系统的性能瓶颈。
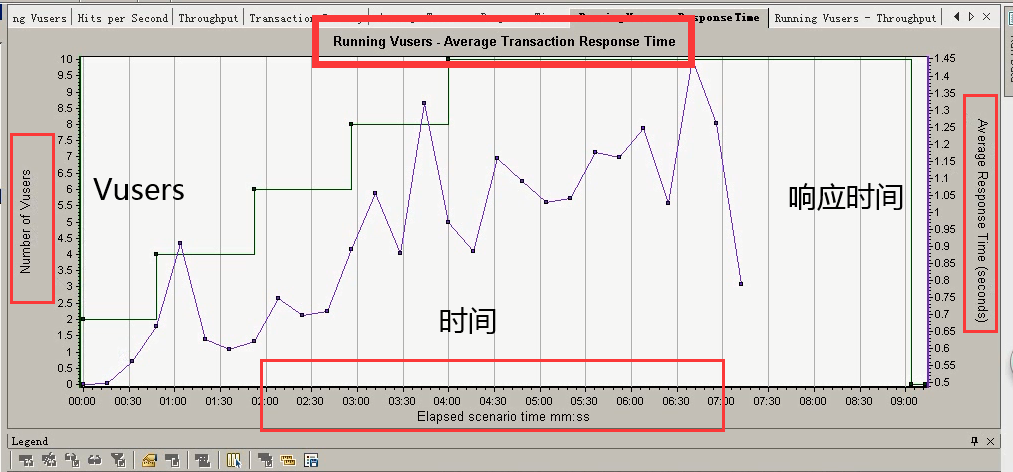
这是之前的(Runnning Vusers和响应时间的,覆盖。)横坐标:都是时间,左纵坐标:Vusers,右纵坐标:响应时间。
这是现在的(Running Vusers和吞吐结合图,关联)。横坐标:Vusers,纵坐标:吞吐。
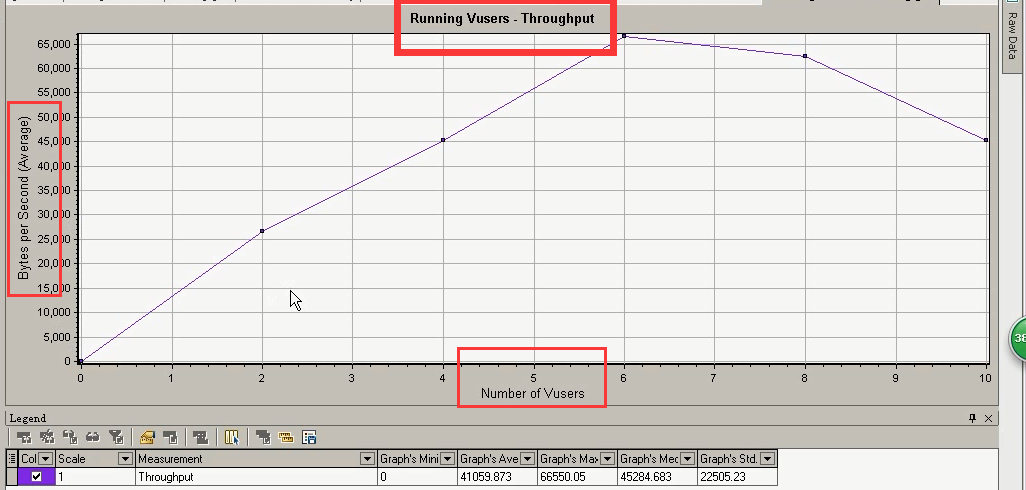
分析下面的(Running Vusers和Throughput)
在6个用户的时候,达到最大的吞吐。超过6个用户,吞吐就下降,看看6个用户是怎么样的一个情况?
结合着下面的几点:6个用户达到最佳并发用户点。
请求数不再变,响应时间往上长,6个用户的吞吐量最大点。
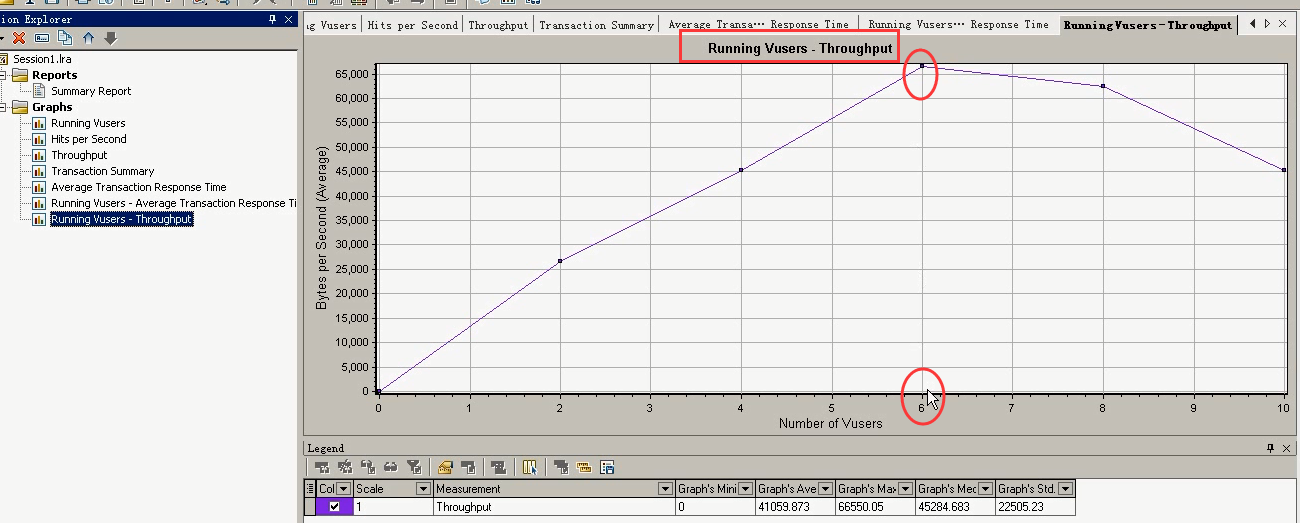
Running Vusers的图:在6个用户的时候,时间是在2:00~3:00的阶段。
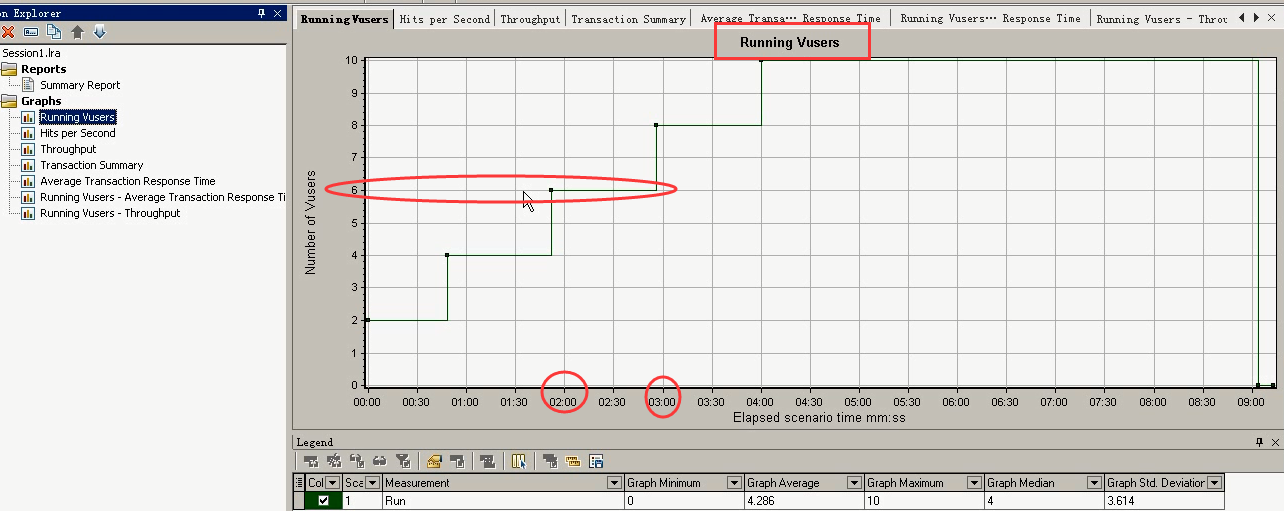
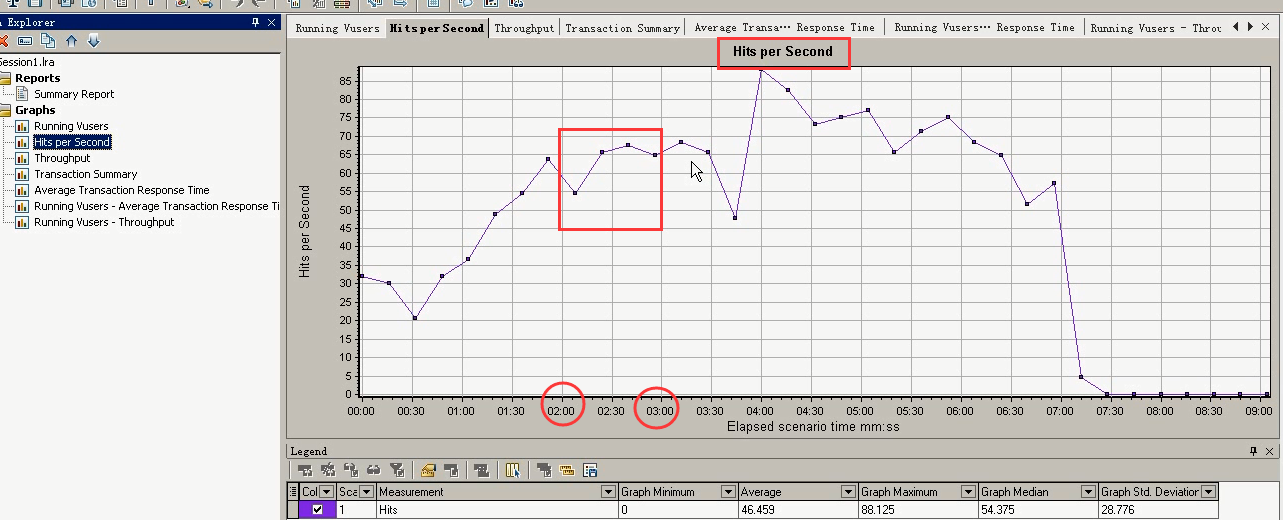
在Hit per Sencond:在2:00~3:00的时候,每秒点击数是一个平稳状态。
在事务平均响应时间的图中,可以看到在2:00~3:00的时候,响应时间是一个上升趋势。
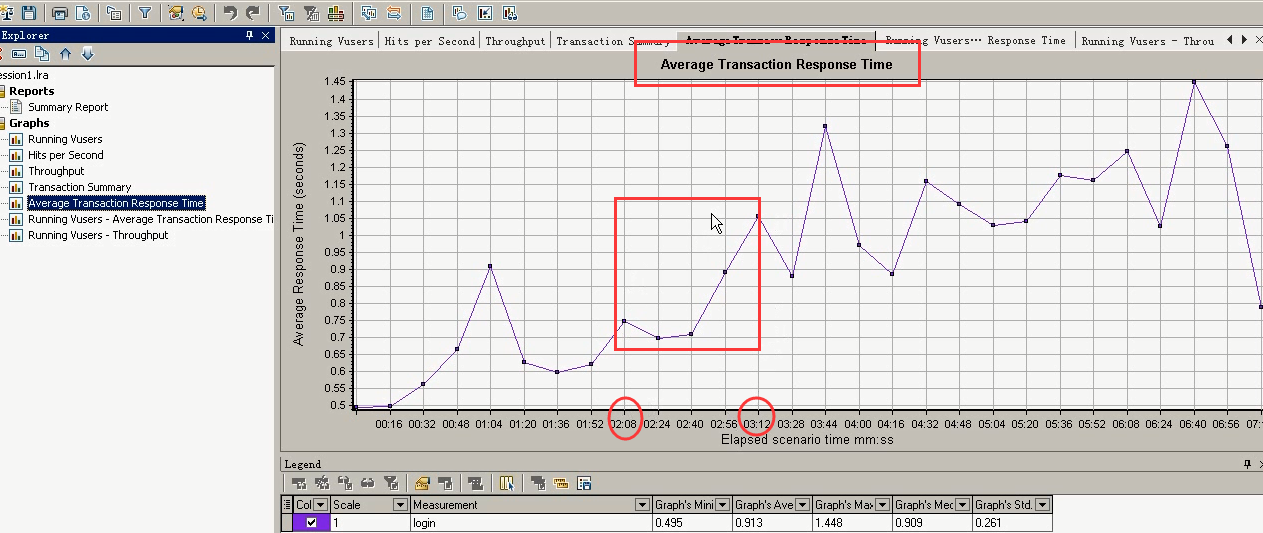
分析:结合着上面的图和下面的图。总结到:
轻负载区:6个并发用户以内的。
重负载区:6-10个
奔溃区:10个以后。
(以后就是这样,很多张图结合着看,分析出最佳并发,最大并发。然后在相应的点上,做一些压力测试,并发测试,负载测试。)
在Hits Per Second:在4:00的时候,达到最大每秒点击数。之后就下降。
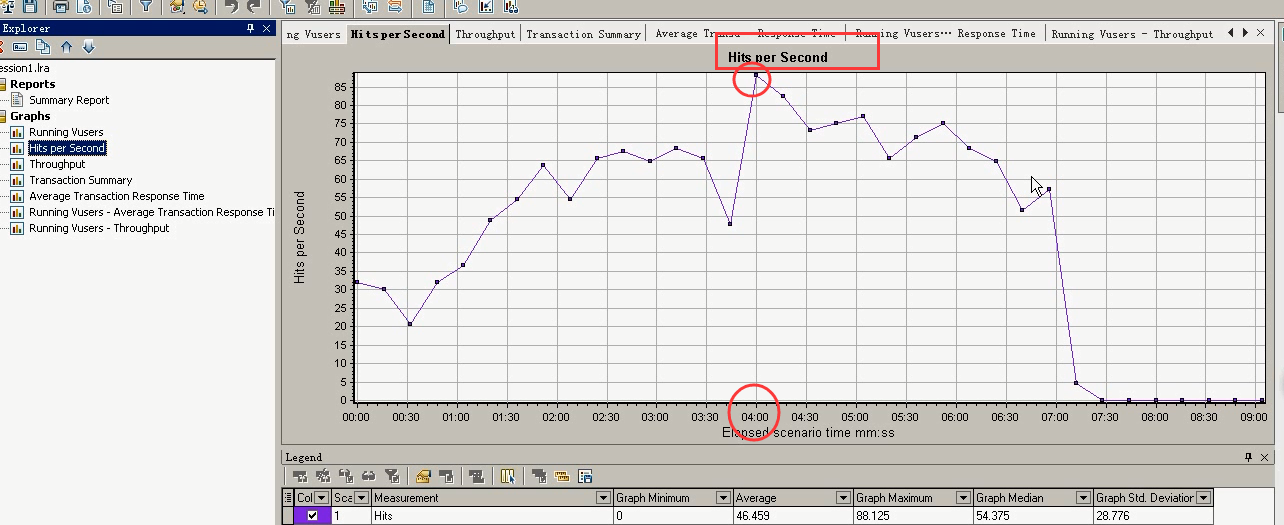
在Running Vusers中,4:00的时候,10个用户。
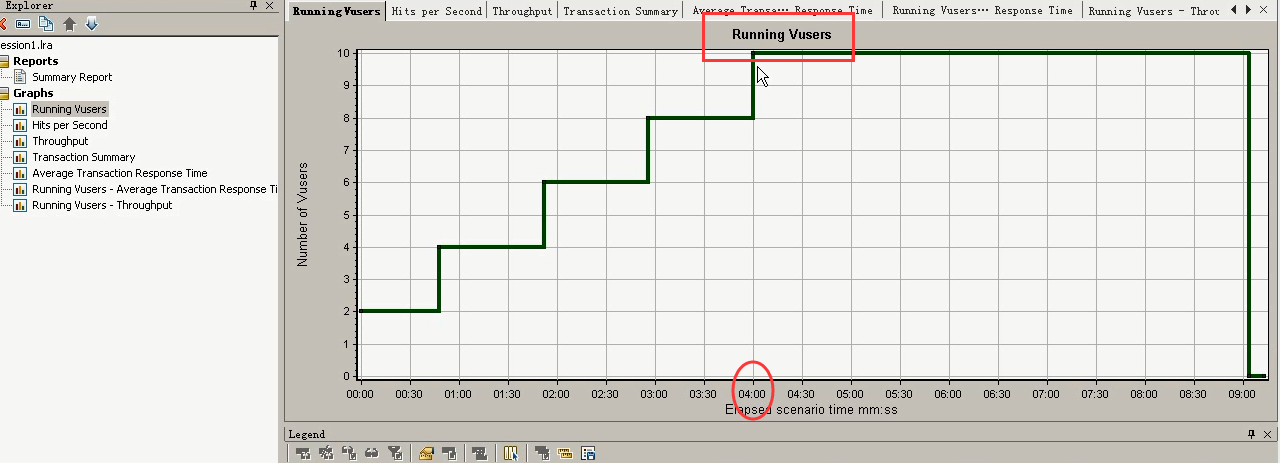
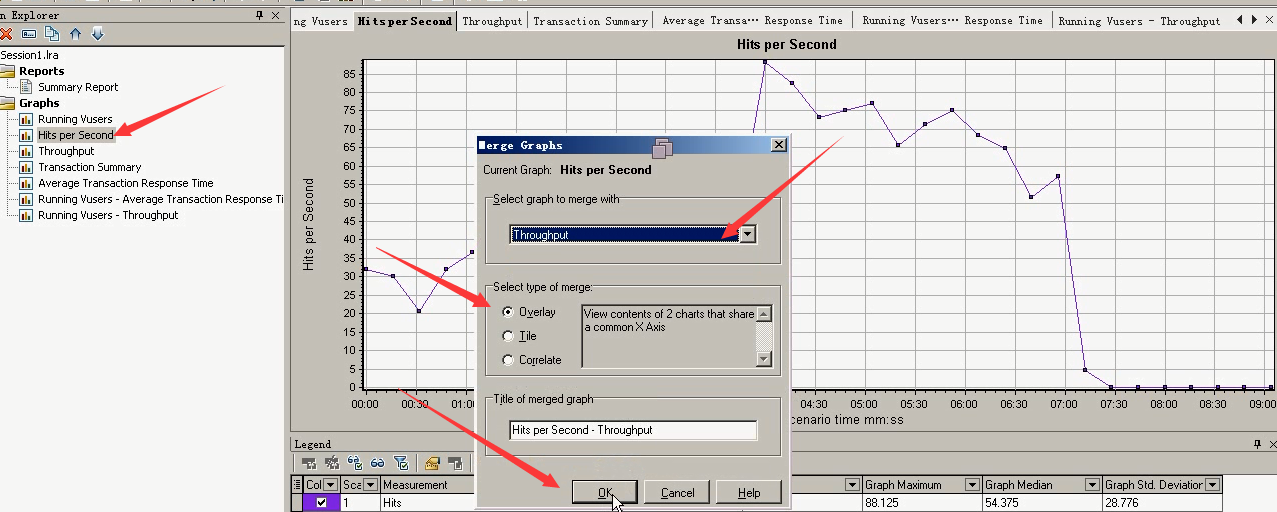
合并图2:Hits per second----Throughput合并关联图
在比较吞吐量和每秒点击率中我们可以获得服务器在执行过程中的情况,如果服务器如预期的一样在执行,那么吞吐量会随着它每秒的点击量的增加而增加,这是期望实现的情况,因为点击增加一次就会需要服务器发
送更多的返回信息给用户,如果点击的次数增加而吞吐量恒定或者减少以及自固定范围内波动,就说明服务器无法执行增加的请求(每秒点击率),结果就是事务反应时间增加。
这里只是随便看一下。(选择的也是覆盖,没有选关联。)
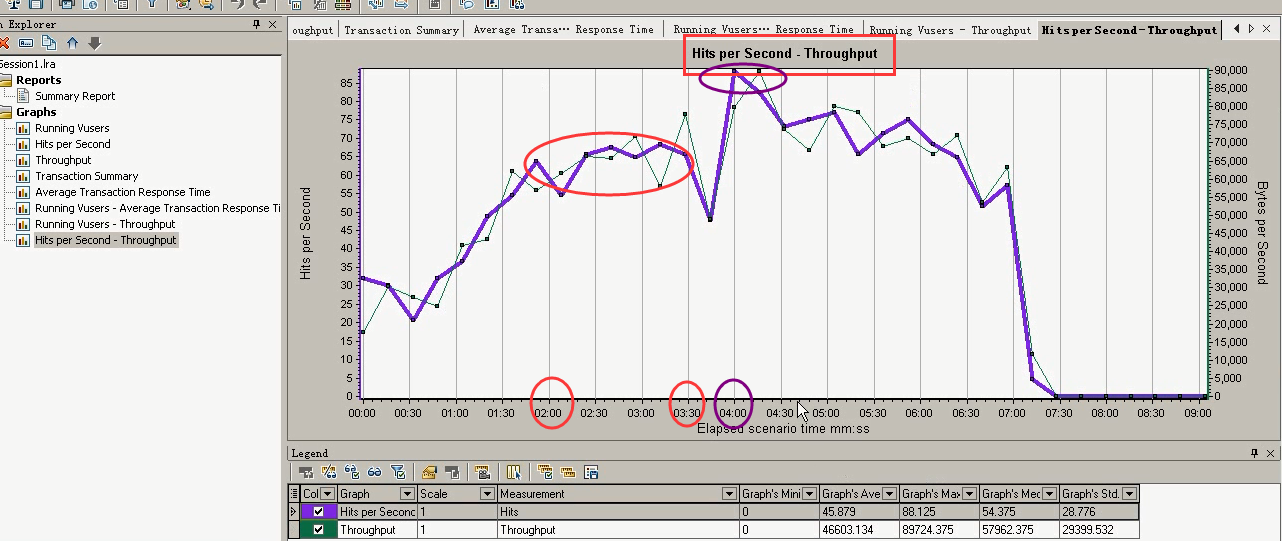
下面的图:可以看出请求和吞吐这样变化的规律。
随着Hit增加,吞吐也在增加。2:00~3:30的时候 :Hitss比较平稳。
3:30~4:00的时候:Hits增加,吞吐也在增加。4:00以后,都在下降,不能承受这么多点击数。
添加一张图表:HTTP Response per second(每秒HTTP响应数)
按如下操作,最后点击close。
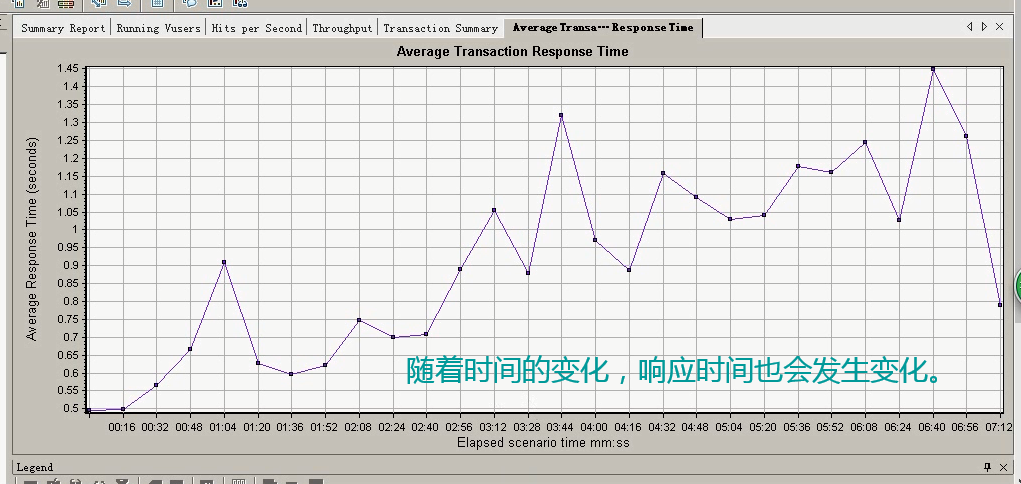
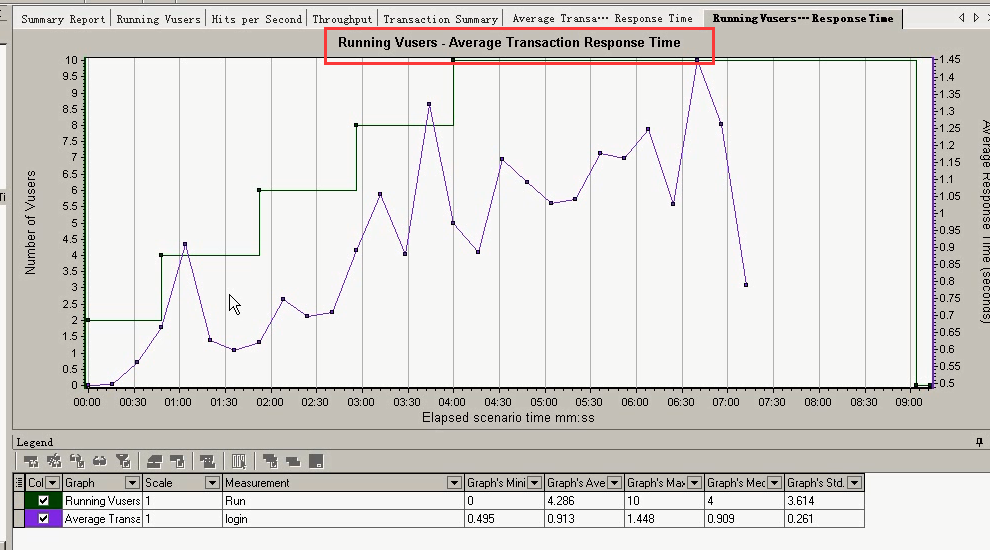
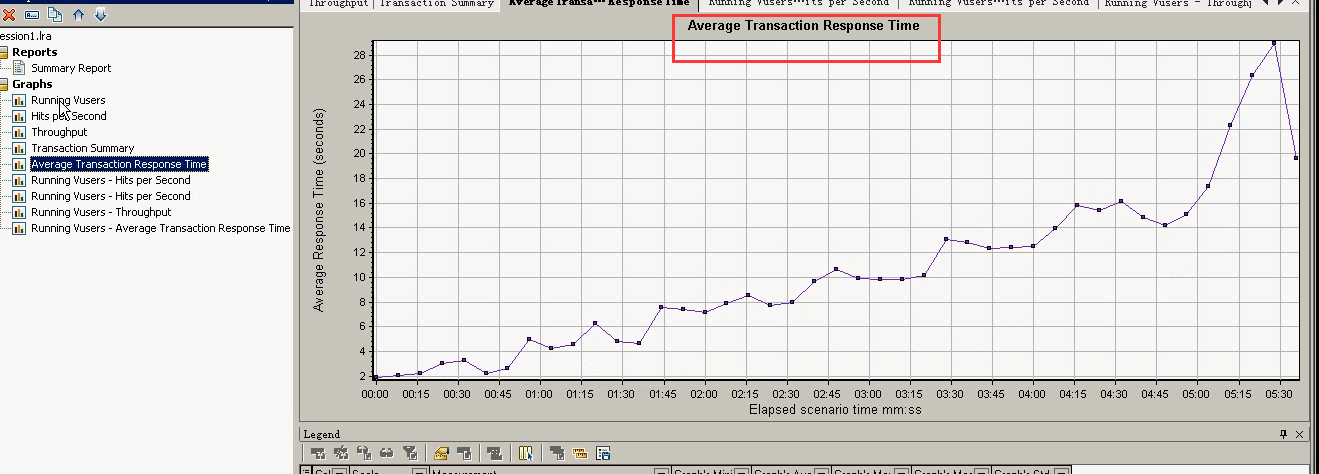
4 事务平均响应时间:Average Transaction Response Time
“事务平均响应时间”显示的是测试场景运行期间的每一秒内事务执行所用的平均时间,通过它可以分析测试场景运行期间应用系统的性能走向,例如随着测试时间的变化,系统处理事务的速度开始逐渐变慢,这说明应
用系统随着时间的变化,整体性能将会有下降的趋势。
上面这张图,不是单独拿出来看的。对于这个响应时间的,都是用户发生请求的时候产生的。
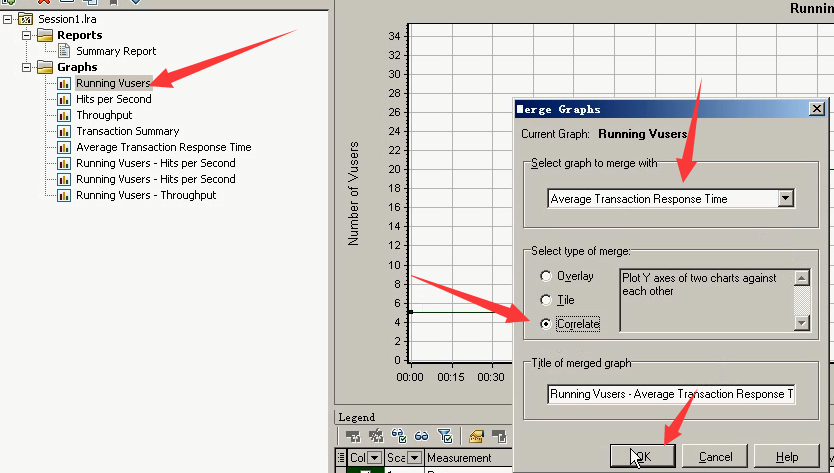
合并图3:Running Vusers-----Average Transaction Response Time覆盖合并
Average Transaction Response Time可以和运行用户图一起来看。选中Running Vusers------Merge Graphs
设置:响应时间+覆盖
select type of merge:
覆盖,看似一张图(其实上面是一张图,下面是一张图。),关联。
下面是运行用户数和响应时间的图表。
通过该合并图可以分析出随着用户数量的变化,各个事务平均响应时间的变化,从而可以得出各个事务在指定时间内最大的并发用户数
5 页面细分图
继续加图
双击打开第一个页面细分图,然后点击close。
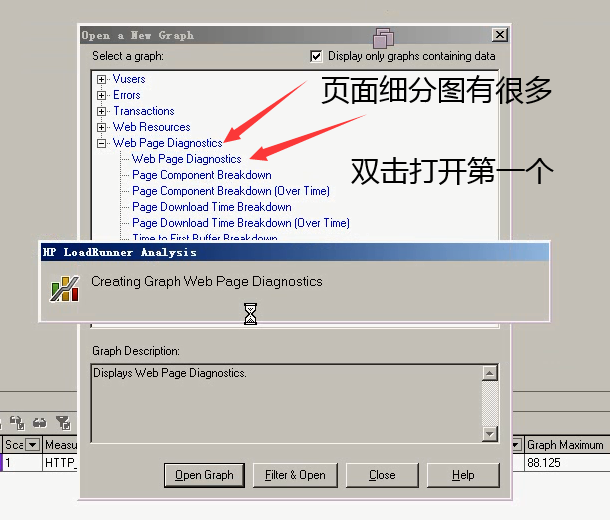
可以看到页面细分图。这只是一部分,下面还有一部分。
页面细分图:这个就是在发送登陆请求过程中,它的这个页面(哪个页面,哪个图片,哪个css文件,哪个js文件),由于请求的时候,服务器处理的时间过长,而导致整个的时间变长的,是这个页面细分的。

接着介绍:login(登陆)事物:有个秒表,表示统计时间的。主请求中有页面和图片。
Download Time:下载时间分析----组成页面的每个请求下载时间
Component(over time) 各模块的时间变化--通过这个功能可以分析响应时间变长是因为页面生成慢还是因为图片资源下载慢
Download Time(over time):模块下载时间-----针对每个组成页面元素的时间组成部分进行分析,方便确认该元素的处理时间组成部分
Time to first Buffer(over time)模块时间分类---列出元素所使用的时间分配比例。是受NetWork Time影响的多还是Server Time影响的多
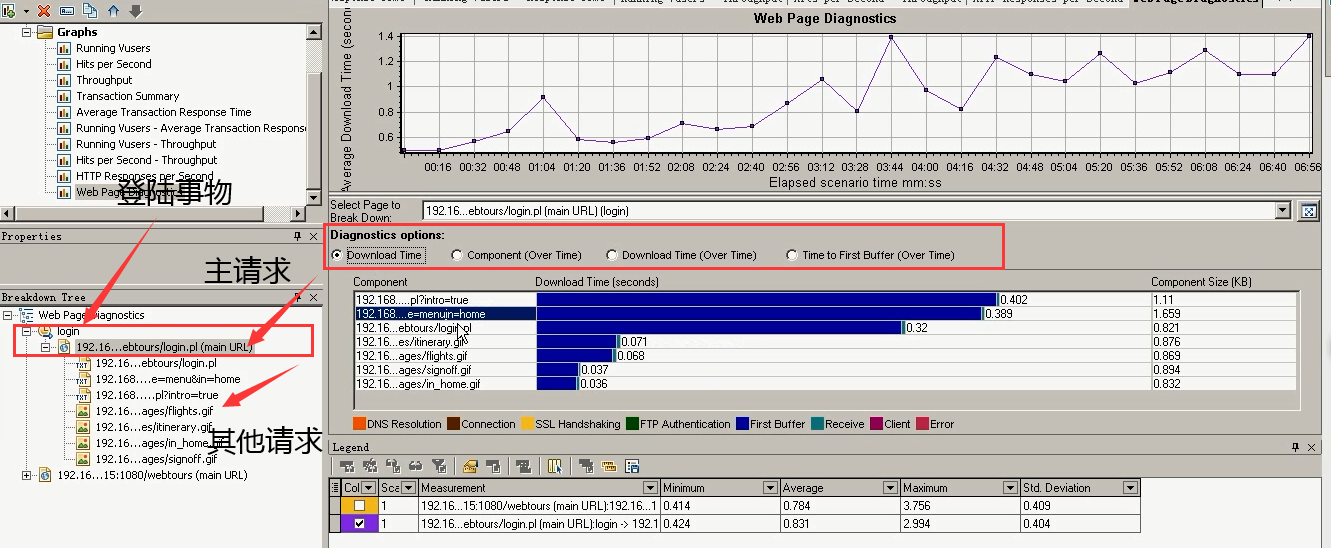
第一个:Download Time:下载时间分析----组成页面的每个请求下载时间
问题出在:前三个页面是,服务器响应第一个字节时间过长。看是服务器服务器处理能力还是网络传输能力,这三个页面可以优化。
DNS Resolution:解析域时间
Connection:连接时间(找到ip,发送请求过去之前,需要做一次连接。)
SSL Handshaking:HTTPS请求的
FTP Authentication:关于FTP协议的,现在是HTTP请求的。
First Buffer:第一个字节。(是发送请求,服务器响应过来的第一个字节。)
Receive :接受服务器所有响应信息的一个时间。(从First Buffer接受第一个字节,到接受所有的字节的这个时间。)
Client:客户端
Error:错误
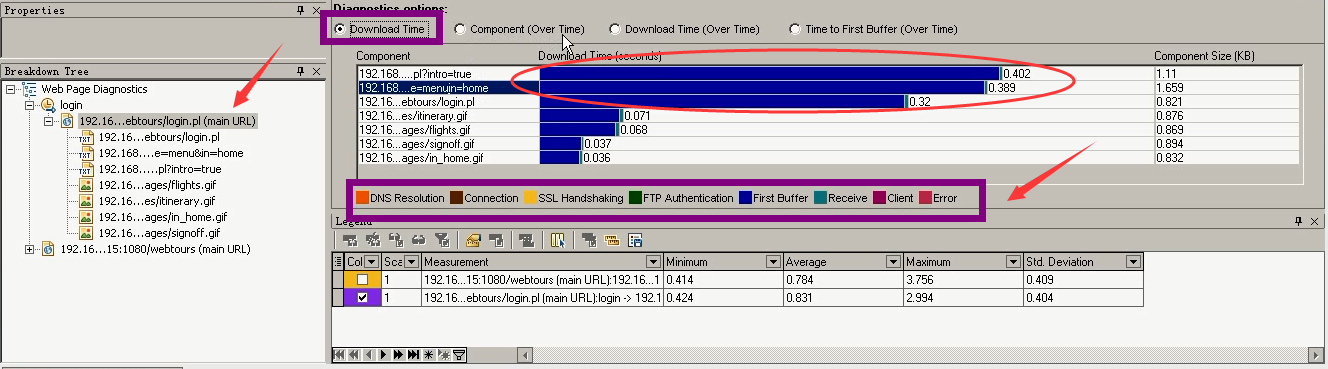
第二个: Component(over time) 各模块的时间变化--通过这个功能可以分析响应时间变长是因为页面生成慢还是因为图片资源下载慢
可以看到在运行场景过程中,这些组件时间变化情况。
下面的几张图片时间没有超过0.2秒,还是那几个页面时间比较长。(可以把前面的勾去掉,看的更明显。)
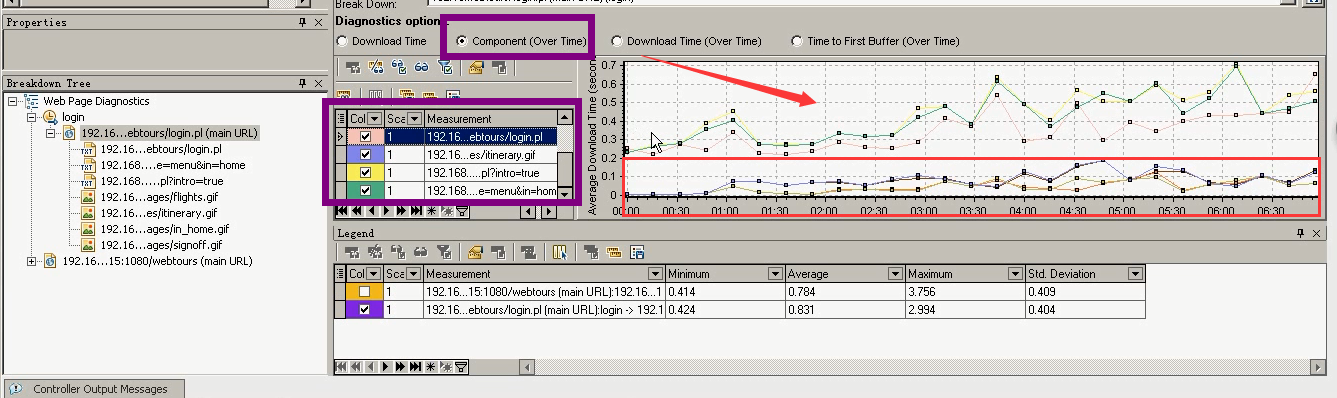
第三个:Download Time(over time):模块下载时间-----针对每个组成页面元素的时间组成部分进行分析,方便确认该元素的处理时间组成部分
在场景运行过程中,下载时间的变化情况。
可以看出还是那三个页面,时间确实有点长。可以让人把内容该删除的删除,冗余的去掉。进行优化。
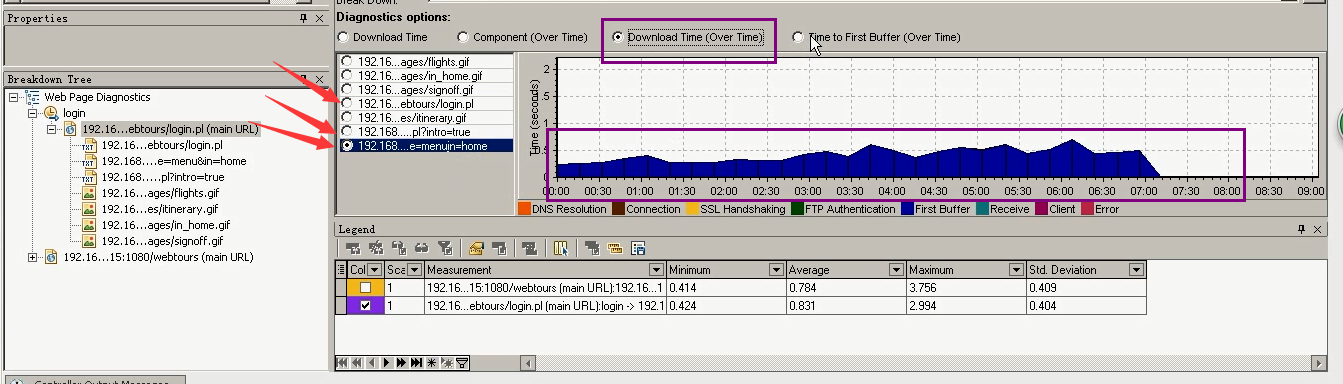
第四个:Time to first Buffer(over time)模块时间分类---列出元素所使用的时间分配比例。是受NetWork Time影响的多还是Server Time影响的多。
在场景运行过程中,第一个字节的消耗情况。
哪个页面有问题,可以在这里看出是到底是网络有问题还是服务器有问题。
绿色:网络
蓝色:服务器
那三个页面可以看出是服务器的问题,并不是网络问题。所以要优化那三张页面,主要是服务器。

补充:
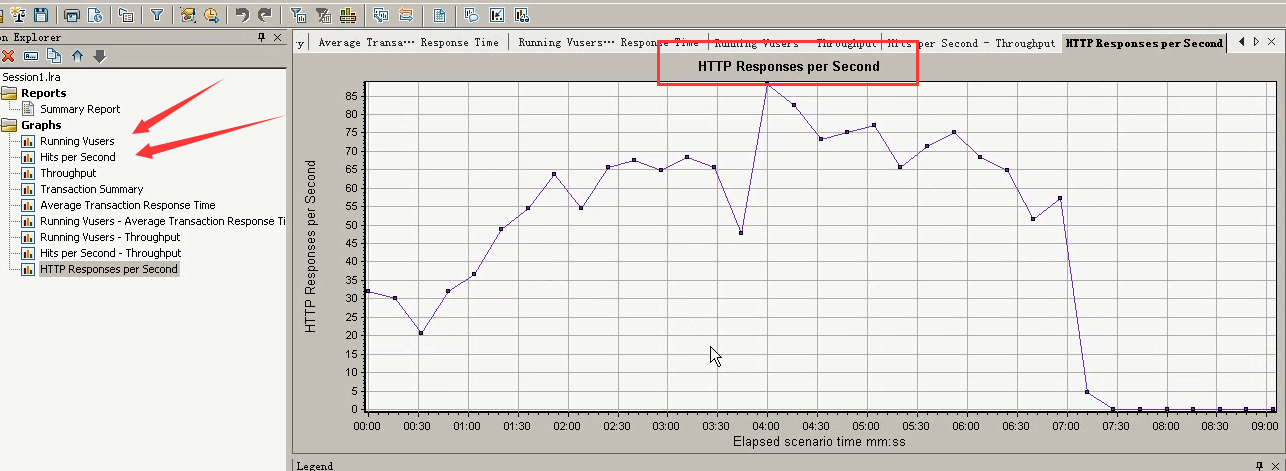
1)每秒HTTP响应数:HTTP Response per second
每秒HTTP响应数是显示运行场景过程中每秒从web服务器返回的不同HTTP状态码的数量,还能返回各类状态码的信息,通过分析状态码,可以判断服务器在压力下的运行情况,也可以通过对图中显示的结果进行分
组,进而定位生成错误的代码脚本。(和Hit Per Second图很像。也可以和Running Vusers图结合起来看。)
2)Transcation Response Time Under Load:加用户过程,事物响应时间的变化过程。
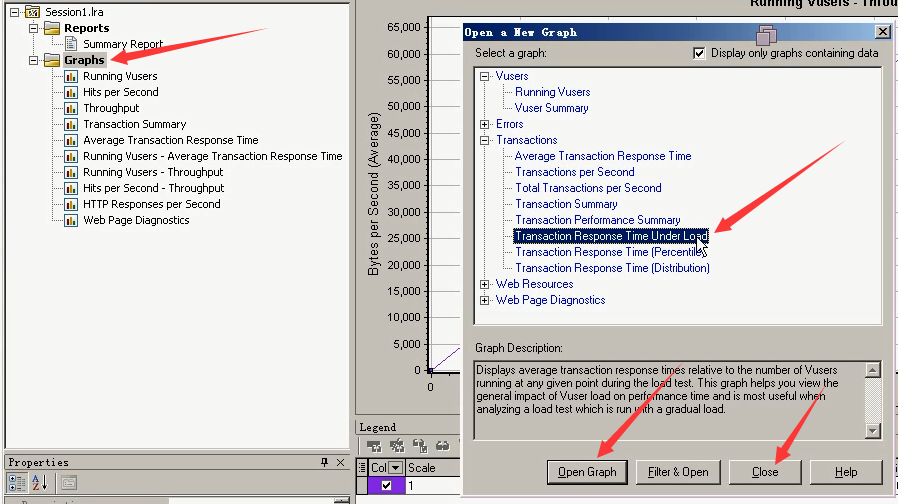
这么看,还挺有规律。

3)Error Statisics(by Description):错误统计,通过描述。
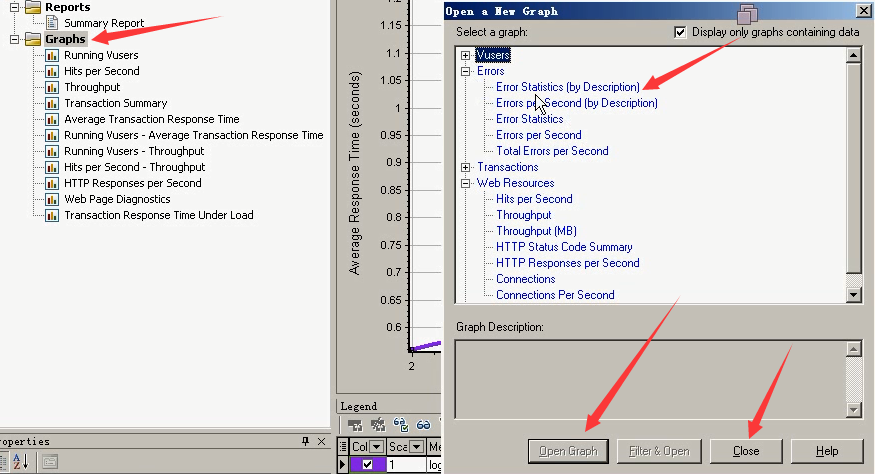
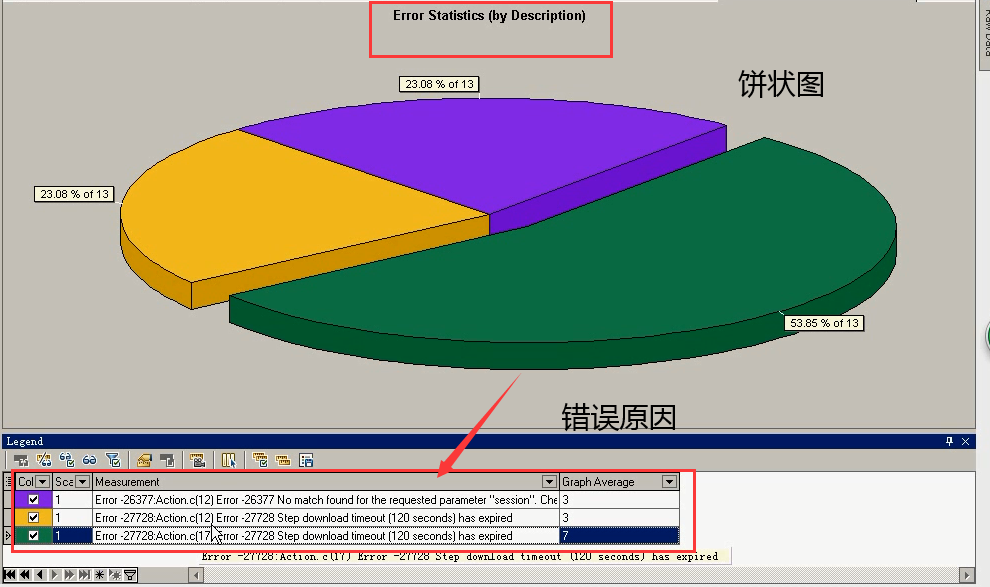
错误的统计可以通过饼状图,能够清晰的看清楚。
下面是错误的原因:
第一个:没有匹配到session。
第二个,第三个:时间过长,超过120s没有成功。
4)Transction Summary:事物的统计
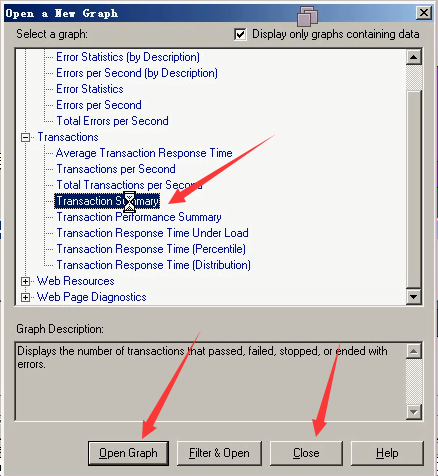
事物成功了多少,失败了多少。通过柱状图就可以清晰看出来。(可以复制到测试报告,分析报告里。当然并不是只看结果,主要是分析这个东西是怎么变的。)
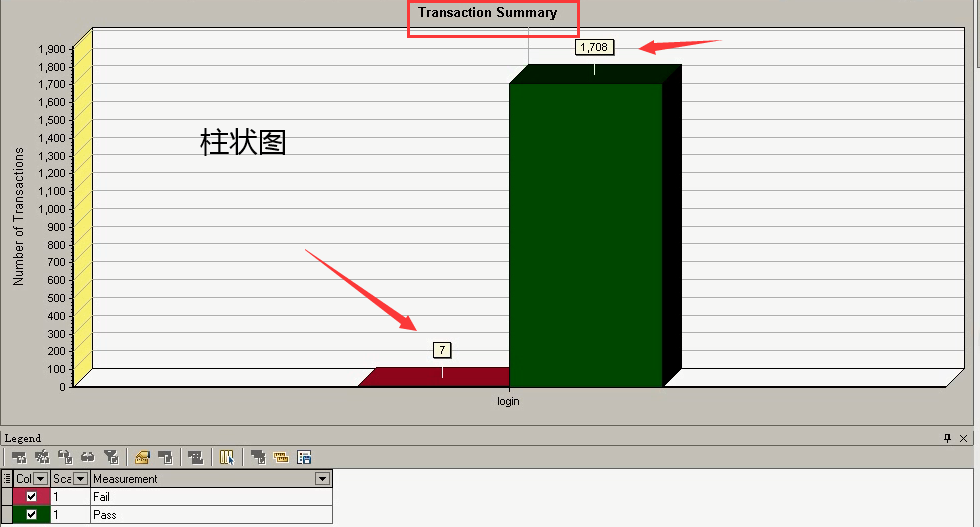
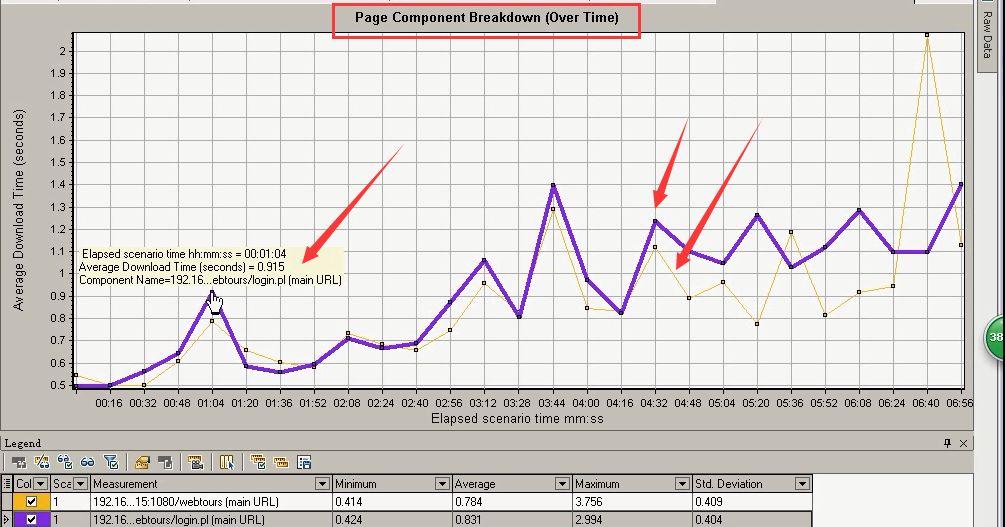
5)Page Component Breakdown(Over Time):页面细分图中,组件的变化情况,在整个场景当中。
两条线表示两个请求:登陆和打开网站。
把鼠标放在点上(有的需要等一会儿),会显示数据的信息:
1.运行时间 2.下载时间 3.组件名称
双击登陆,就会出现很多线。可以通过把下面的勾去掉,显示的更明显。
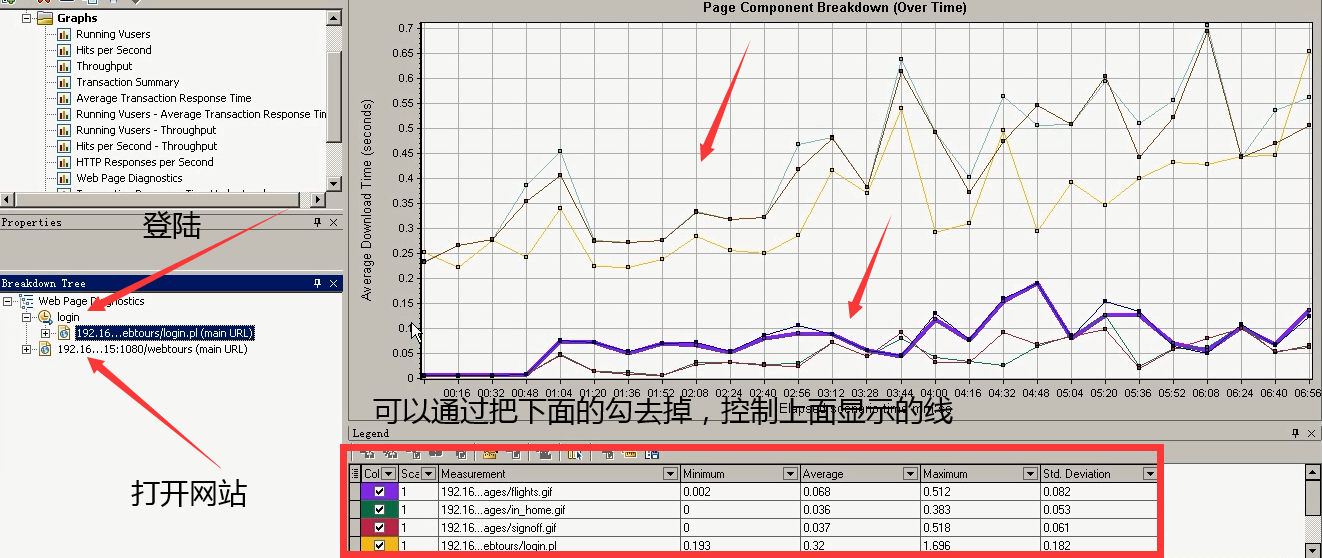
只留其中一个,可以看出:随着用户的负载增加,图片的下载时间也在长。(看着这里很大,其实单位不大。)
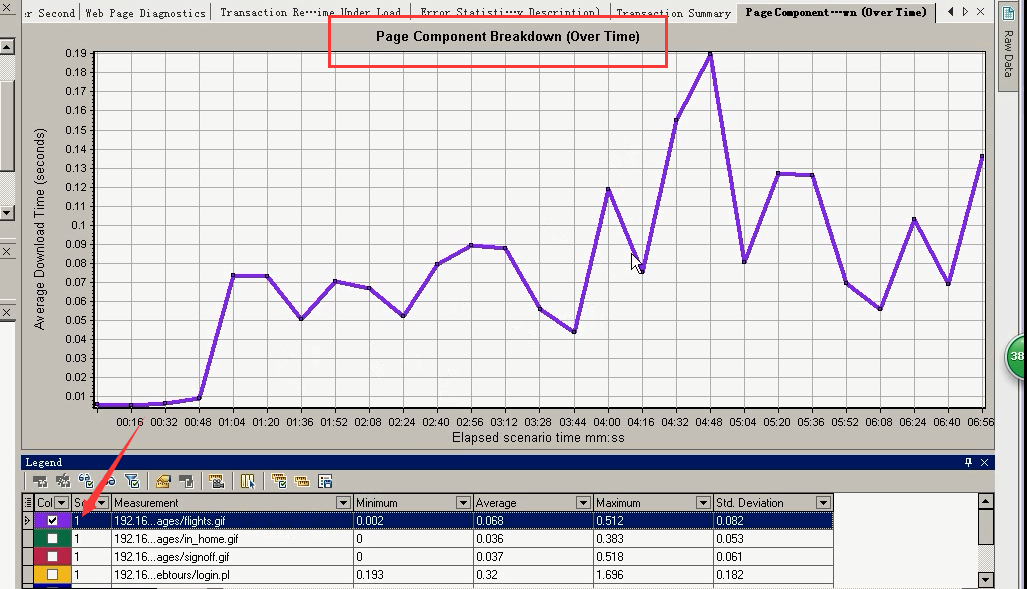
那三个页面的其中一个:最大的时间是0.7s。可以肯定的说,对于那三个页面请求来说肯定是有问题的。太长了,而且是服务器这块的问题。
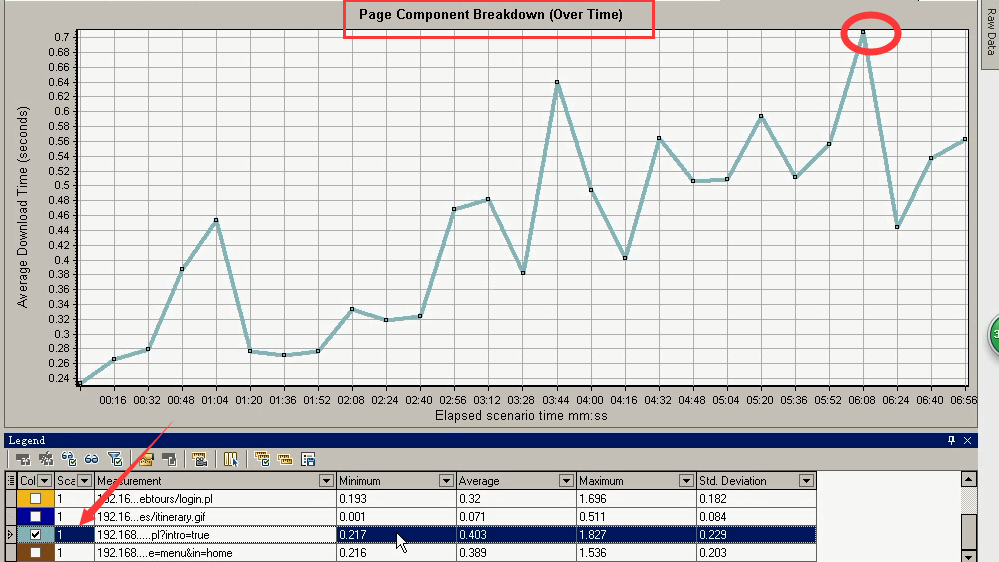
小总结:关于分析
分析:需要仔细,一点点儿看。
把这些图合并起来看看它们之间有什么规律,找到它所相应的点。找到点之后,可以在这些点上做一些压测。或者看看这些性能指标是否满足,如果不满足,再去查看。比如:内存,或者页面的加载等等这些问题。看
看是否还有问题。一点点儿的就能把这些东西分析出来。
6 系统资源
系统资源分析(难点,下面有例子)
1 内存分析方法:
内存分析方法主要用于判断系统有无遇到内存瓶颈,是否需要通过增加内存等手段提高系统性能表现,主要计数器包括Memory(内存)和Physical Disk(磁盘)类别的计数器
内存分析的主要步骤和方法如下:
1).首先查看Available Mbytes(可用内存)指标,(可用内存肯定在下降。)
该值是用于描述系统可用内存的直接指标,在对系统进行操作系统级别的内存分析时,首先应通过该值建立一个初步的印象,了解性能系统测试过程中,系统是否仍然有足够的内存可用 如果该指标的数据比较小,系
统可能出现了内存方面的问题,此时需要进一步分析。
2).注意page/sec(每秒页交换频率) ,pages read/sec(读取磁盘频率) 和page faults/sec(每秒失效次数)的值。(想一下内存读取磁盘数据,来回交换的过程。)
(每秒页交换频率:看内存是否充足,内存从磁盘里读取数据,如果反复去读,说明内存一次性读取不了太多。很有可能说明内存是不足的,就需要去看pages read/sec(读取磁盘频率)每秒能读多少,如
果>=5,说明内存有问题。)
(内存读取磁盘数据,放在page(页)上面。内存是一页页分开的,会把数据放在一页页上面来。当把这些数据读取完之后,还去磁盘再去读取一些数据,就要看这块有没有足够内存供它可以去读这里面
的数据。如果不够的话,根本就读不过来,或者读的次数比较多,一次只能读几页。那也说明它一次性不能够读多页,那么说明这个内存也是有问题的。)
操作系统经常会使用磁盘交换的方式来提高系统可用的内存量或者是提高内存的使用效率,这三个指标直接反映了操作系统进行磁盘交换的频度
如果pages/sec 的计数器持续高于几百,很可能存在内存方面的问题,但其值很大不一定表示内存有问题。
page faults/sec说明了每秒发生页面失效的次数,页面失效次数越多,说明操作系统向内存中读取的次数越多
此时还需要查看pages read/sec 计数器,该计数器阈值为5,如果超高5,则可以判定存在内存方面的问题
3)根据Physical Disk(磁盘)计数器的值分析性能瓶颈。(因为内存是从磁盘里读取数据的。所以也要关注磁盘这块。)
对于physical disk计数器的分析包括:pages read/sec (磁盘在读的时候,它的一个频率。)和%Disk time(磁盘利用率)以及Average(磁盘的队列)
Disk Queue length的值很高,则可能是由磁盘瓶颈,但是如果Average Disk Queue Lngth增加的同时Pages Read/sec并未降低则是由于内存不足
2 处理器分析方法:
处理器CPU也可能是系统的瓶颈,对处理器进行性能分析的步骤如下:
1).首先查看%Total Processor Time性能计数器的计数值
该值用于体现服务器整体的处理器利用率,对于多处理器的系统而言,该值体现的是所有CPU的平均利用率
(如果想看cpu到底被谁用了,要看%user time和%privileged time。)
如果该值的数值持续超高90%,则说明整个系统面临着处理器方面的瓶颈,需要增加处理器来提高性能
注意:由于操作系统本身的特性,在某些CPU系统中,该数据本身并不大,但此时CPU之间的负载状况极不均衡此时也应该视作系统产生了处理器方面的瓶颈
2).其次查看每个CPU的%processor time和%user time(应用程序)和%privileged time
%user time 是指系统的非核心操作消耗的CPU时间,如果该值很大,可以考虑是否通过算法优化等方法降低该值,如果服务器是数据库服务器, %User time值大的原因很可能是数据库的排序或者函数操作消耗
了过多的CPU时间此时可以考虑对数据库系统进行优化。(通俗的理解:如果该值过大,看看是否能够优化代码来降低这个值。如果是数据库服务器,该值过大。有可能是sql语句或者数据库位置影响的。优化:增加
索引,改变查询方法。)
3).研究系统处理器瓶颈
查看processor queue length(关于cpu队列长度)计数器的值,当该值大于CPU数量的总数+1时,说明产生了处理器阻塞(出现了排队现象),且%Total Processor Time值保持超过95%,就表示当前系统
的瓶颈为CPU,可以考虑增加一个处理器或者更换一个性能更好的处理器。(更换处理器或者增加cpu。)
例1:
这个服务器,改一下cpu的个数,改为单核。压一下,cpu队列会太长,cpu的使用率太高。调整一下cpu的个数,压一下,cpu队列会变短,cpu的使用率没有那么高。是否可以判断这就是硬件问题,完全可以调整
硬件来优化它。
例2:
1.打开网页。打开网站的过程:看它的一些负载量,或者并发量,或者100个用户并发,它打开时候的一些响应时间是怎么样的。
2.页面搜索。能支持多大负载,响应时间是怎样的。
例3:打开网站的单接口压力测试。(步骤详细)
1)代码如下

2)保存。file-----save as
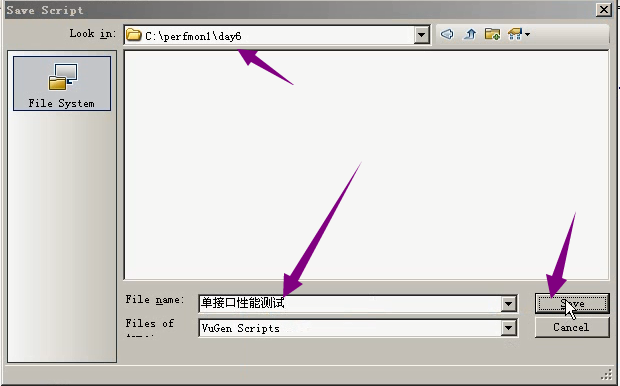
3)设置迭代次数为5次。
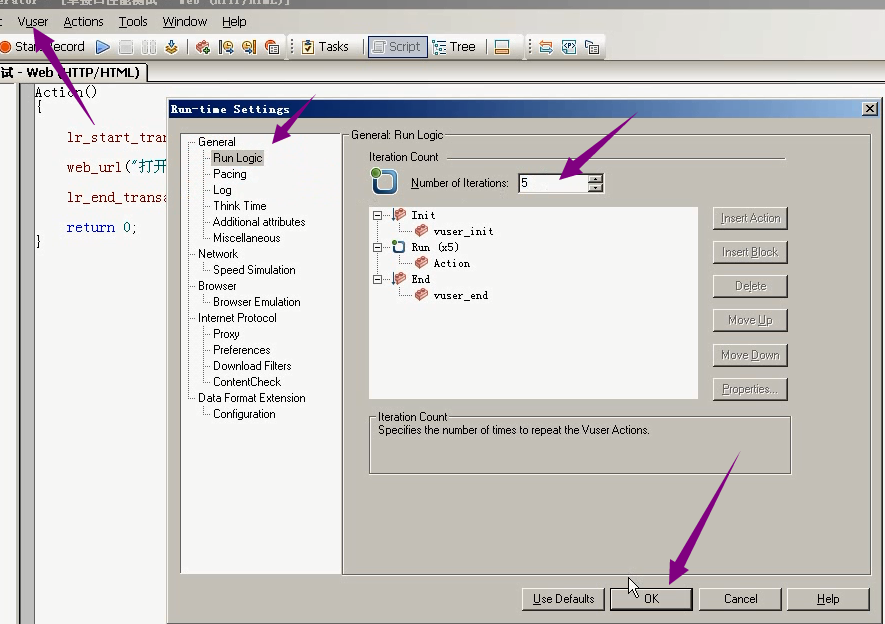
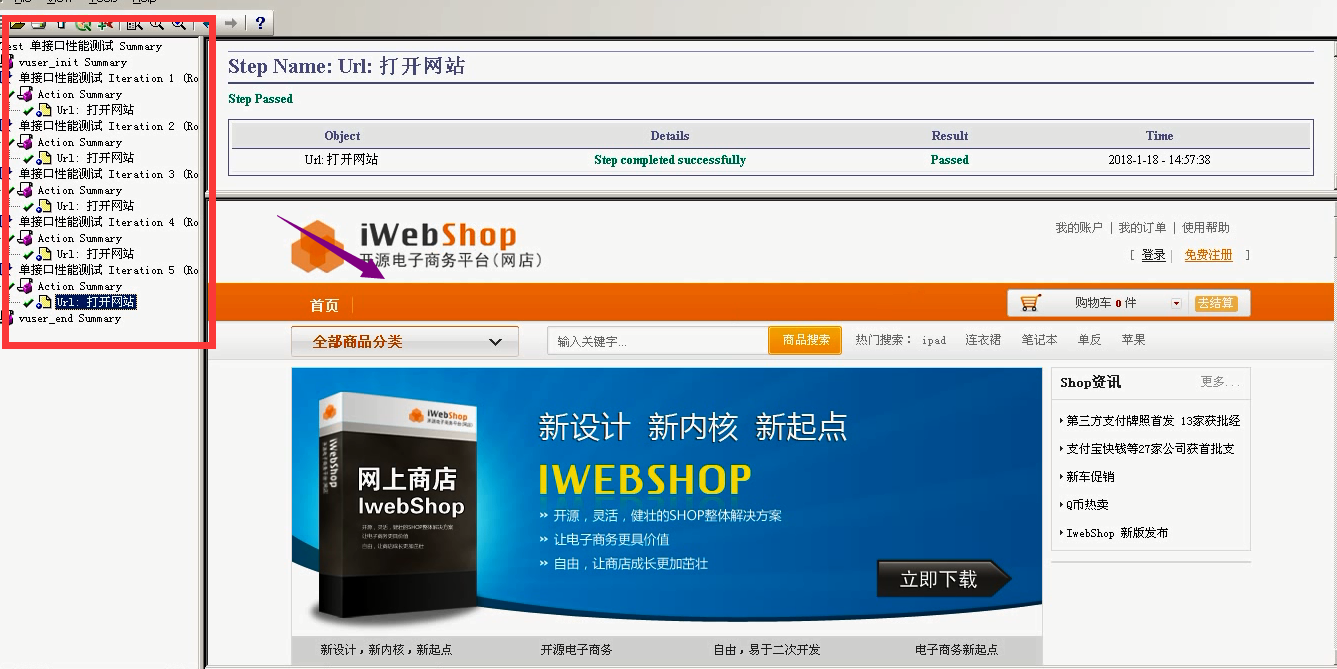
4)点击运行。看结果:VIew----Test Results-----这几个打开网站都没什么问题。
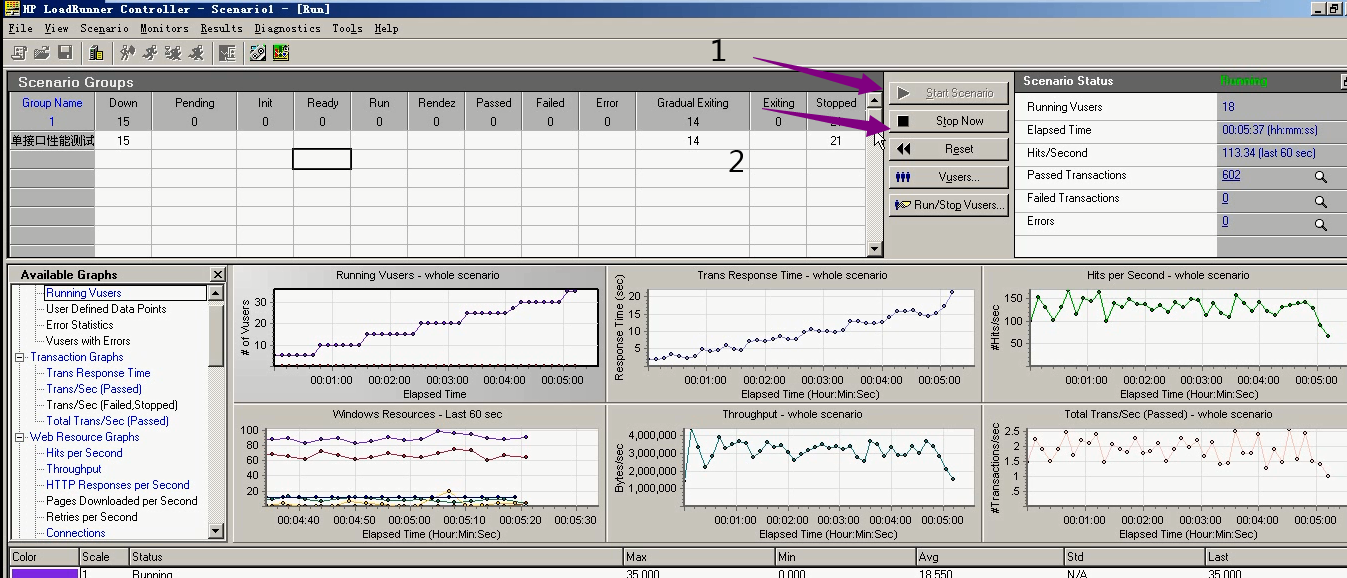
5) 打开Controller。设置50个。
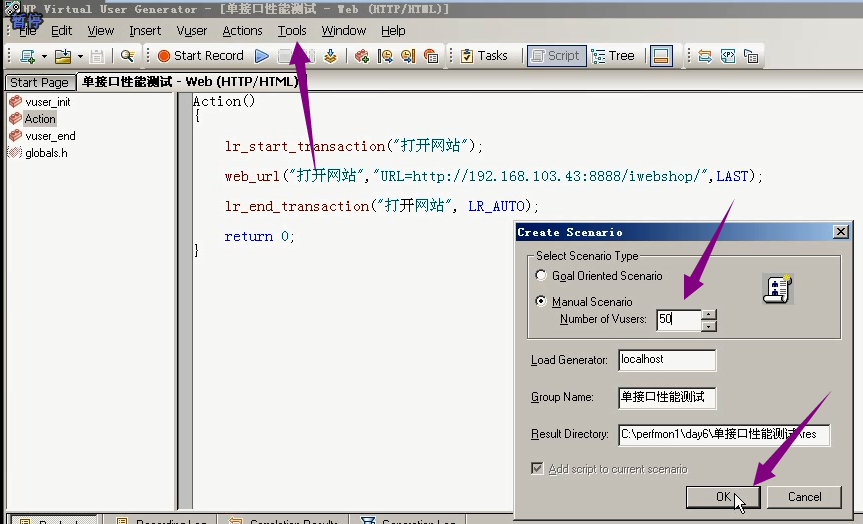
最好不要点,等待就行。
6)单接口性能测试(代码)
7)看一下结果
从第2步开始就好,重新设置结果路径。
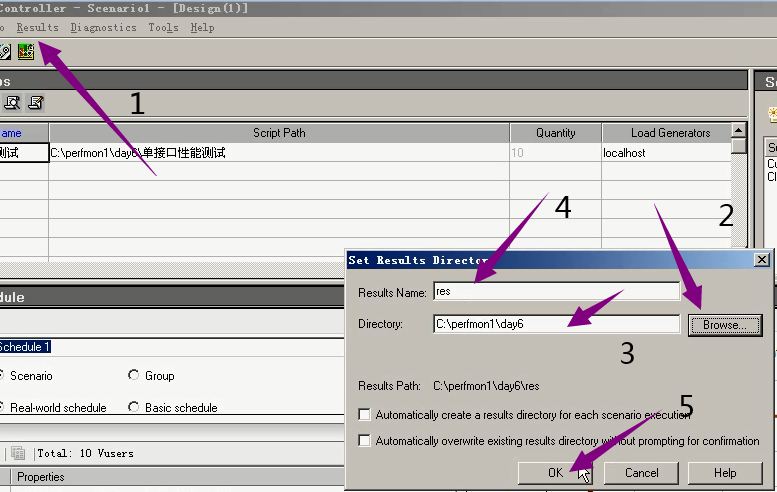
为什么要重新设置结果路径。 原因是:结果路径被换掉了。
只要是从三类两种里面没有直接打开,结果路径就会换掉。
一旦重新选择,结果路径就会换掉。
8)因为是时间控制的,所以设置迭代次数多少次都没有关系(这里是5次)。关闭日志,关闭思考时间。
9)逐步增压的方式:随着不断加负载,看页面响应时间是怎样的。

10)自定义表。
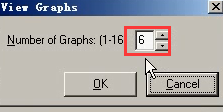
11)需要下面6张表添加进来。
资源这块要设置一下。
windows系统资源设置。
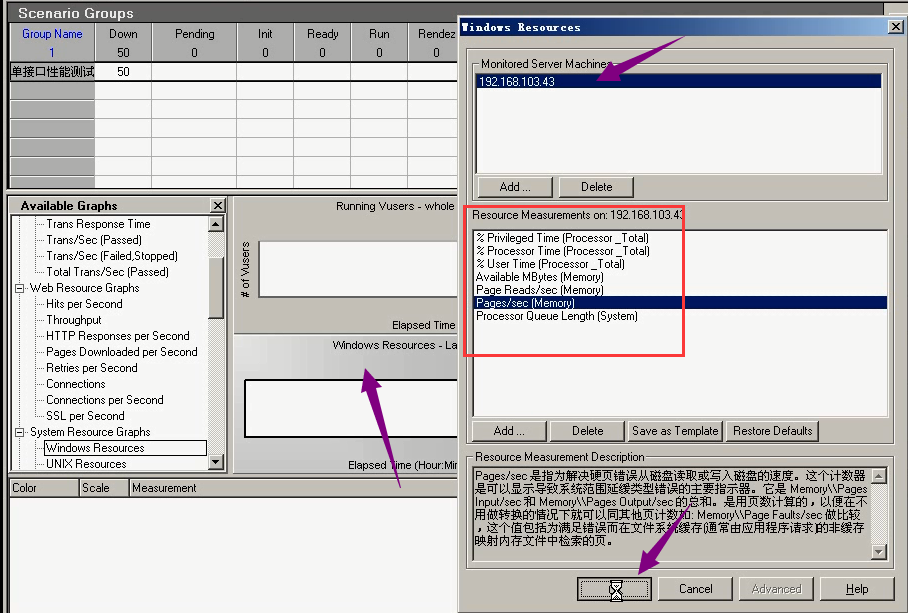
12)点击运行,等待一段时间后。可以点击关闭。在分析器里查看结果(边执行边搜集,执行多少就搜集多少)。
13)打开分析器,file----open----找到文件并打开。
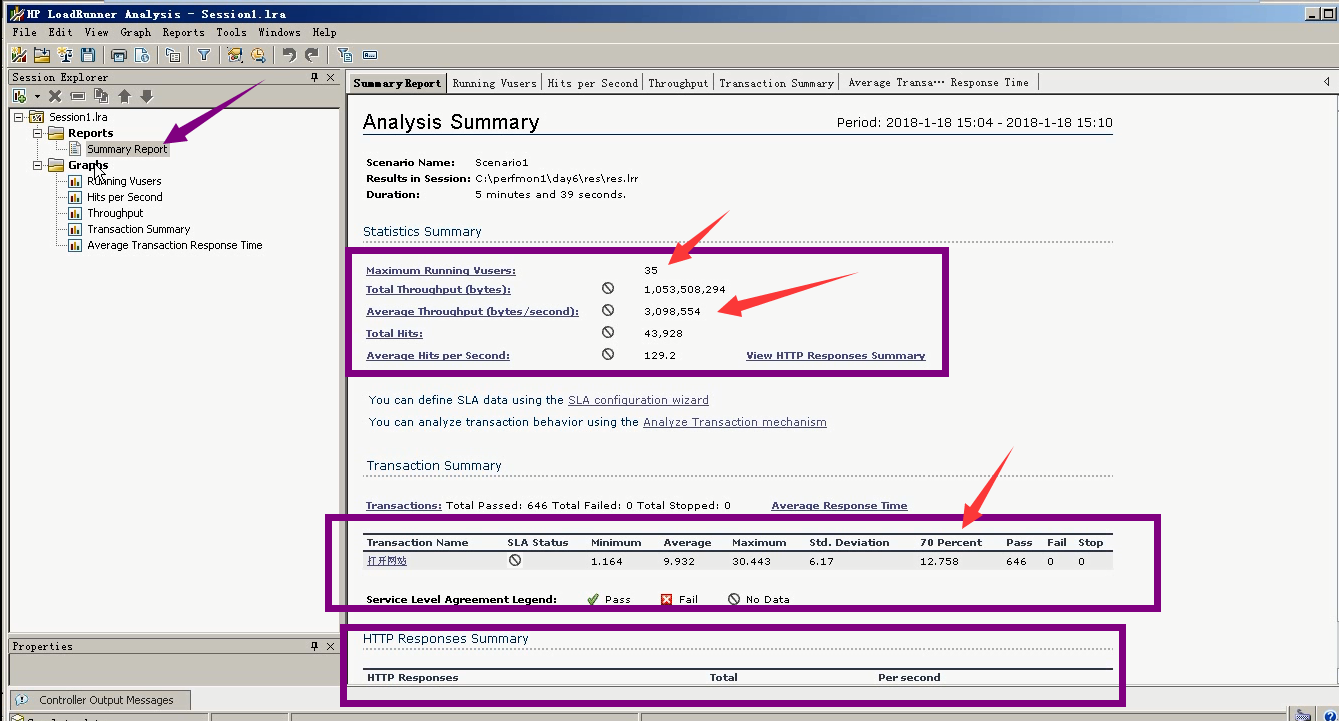
14)看一下第一部分。
运行用户数量:35个
通过平均吞吐算出网络带宽。3098554/1024/1024=3兆(网络带宽消耗)
更改百分比:90%是16.38秒,80%是14.46秒,70%是12.758秒。(运行用户35个,每增加10%,也就是3-4个用户,会增加2秒的时间。)
15) 看第二部分图表。Running Vusers和Hits per Secong关联合并。选中Running Vusers----右键----merge Graphs---选好---点击ok。
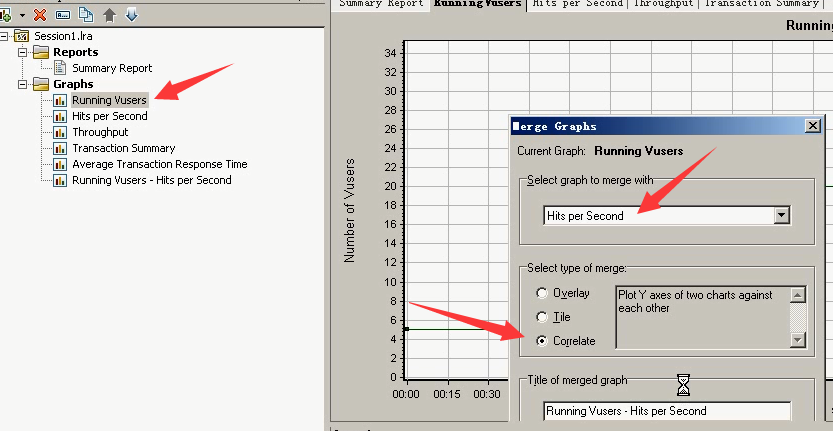
大概在5个用户之后,Hits Per second(每秒点击数)在一定的数据之间稳定的波动。
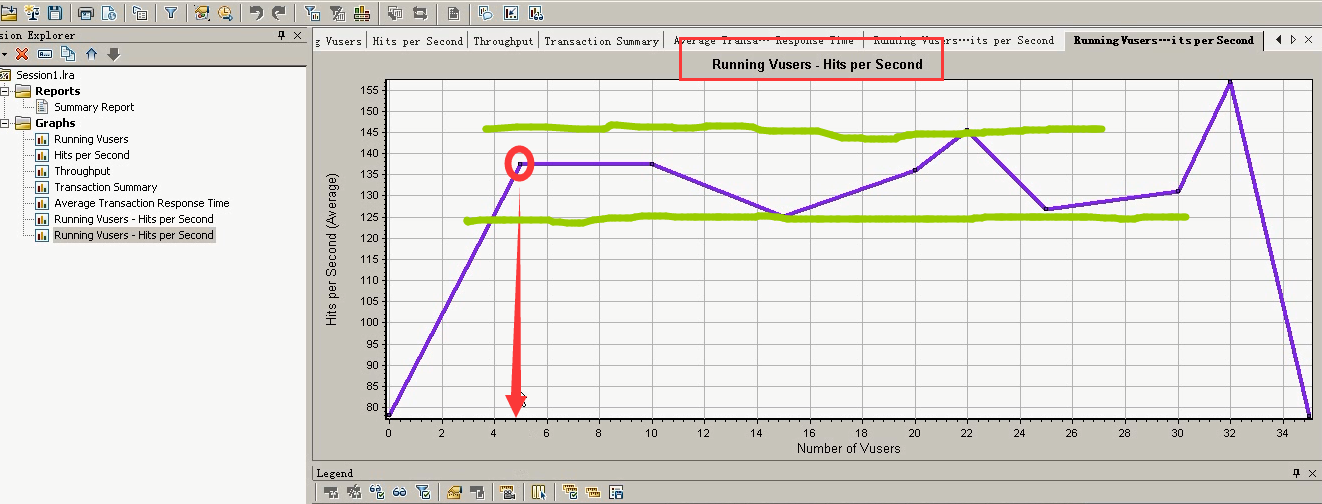
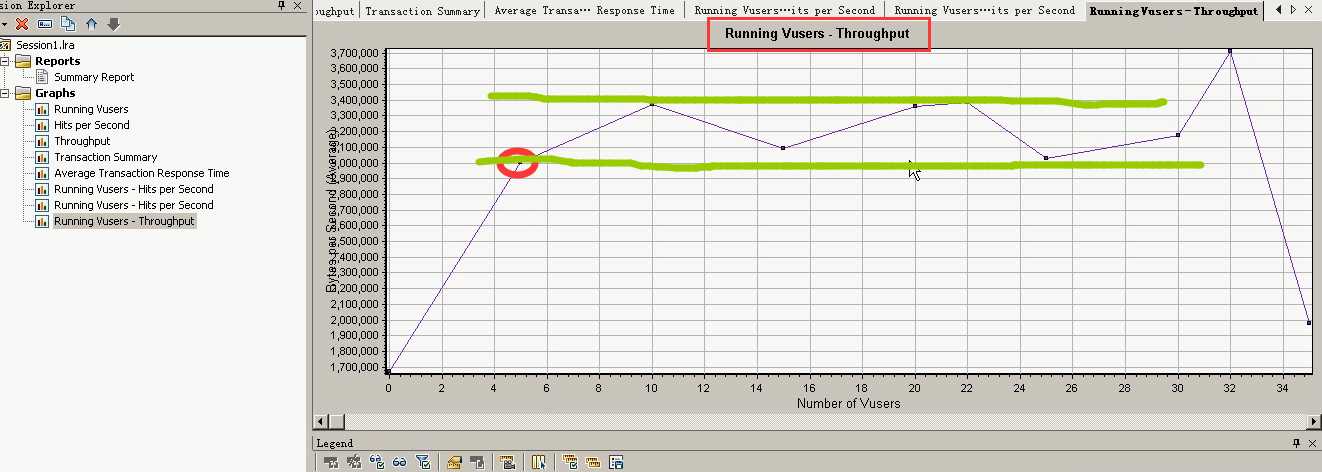
Running Vusers和吞吐关联合并。
也是在5-6个用户之后,吞吐趋于一个稳定状态。
Running Vusers和时间关联合并。
前面是刚打开的时候,会出现慢的情况。5-8个的时候趋于正常情况,之后就开始往上涨。
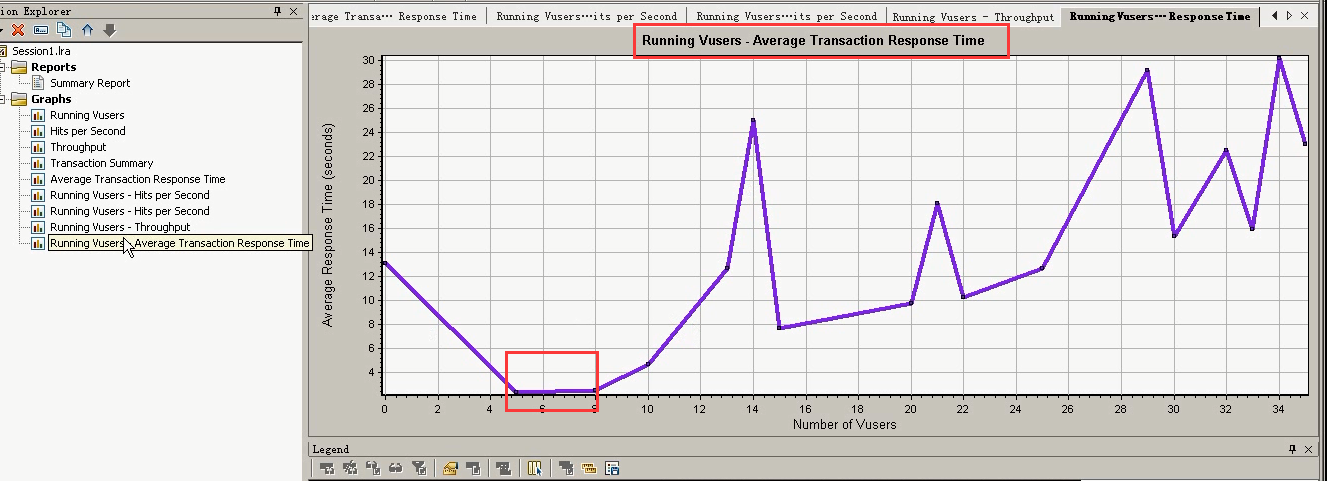
看一下Average Transaction Response图:随着时间是往上涨的。
总结:
Running Vuser和Hits Per Second(关联合并图):随着用户增加,5个以后每秒点击数也趋于稳定。
Running Vuser和ThroughPut (关联合并图):5个以后,用户增加,吞吐不再变了(趋于稳定状态)。也就是说处理不了那么多请求了。
Running Vuser和Average Transaction Response Time (关联合并图):随着过了个以后,时间不断往上涨。
最佳并发用户数:5-6个左右。
16)再增加一些图表。
页面细分图表
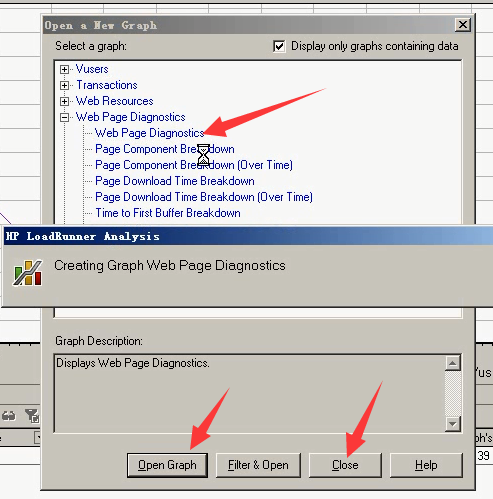
看一下:相比较其它的,主要还是打开网页,花费时间长(1.937秒),接受第一个字节:1.8秒多。接受完整字节:0.0.53秒。

请求页面,在这个时间段时间非常大,为12秒,所以导致了整个平均时间非常大。关该平均页面的时间是在4秒左右。
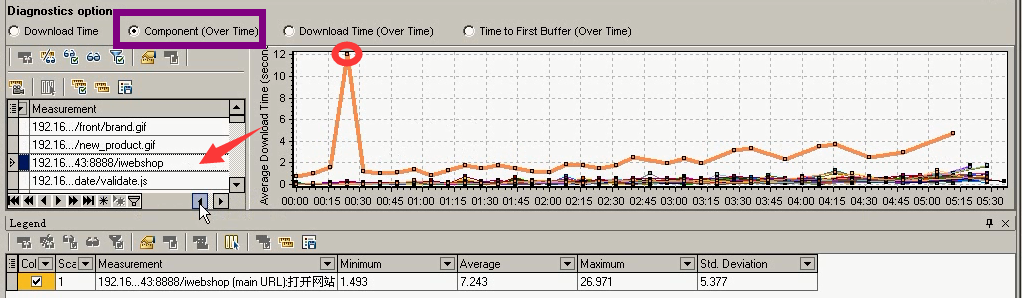
唯有页面下载的时候时间最长,和上面对应起来了。
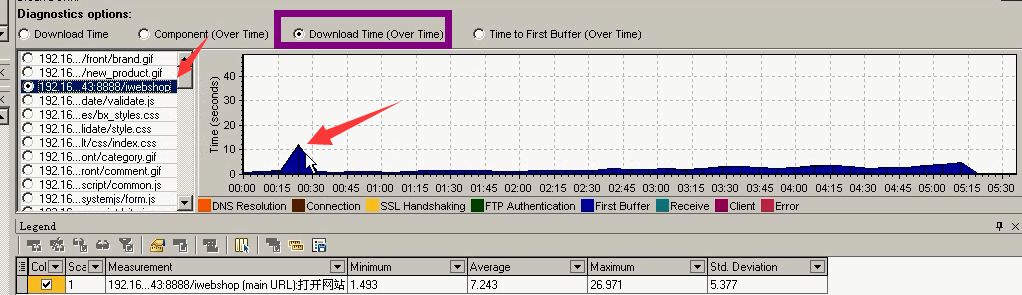
还是服务器问题,消耗时间最长。其实这个问题,一眼就能看出来。就是请求页面太大,所以请求时间过长。直接优化这个请求页面。(再去以这么多用户量,再给之前先做一个基准测试,优化完成做page测试,看
优化情况怎么样,还是相同的脚本。)
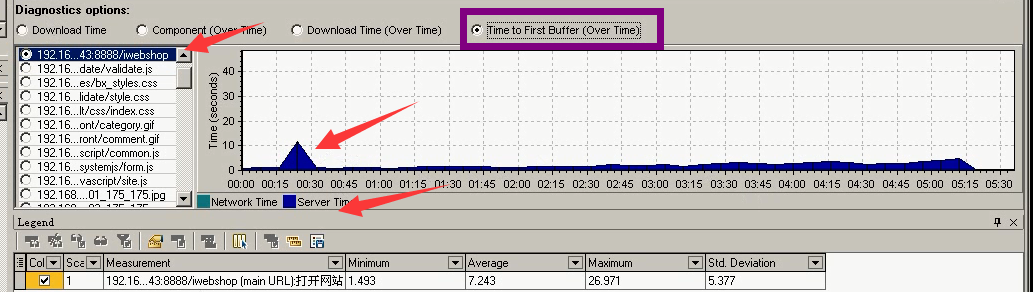
总结:平均请求时间很长,因为是该页面过大,所以请求时间很长。
事物请求时间过长。
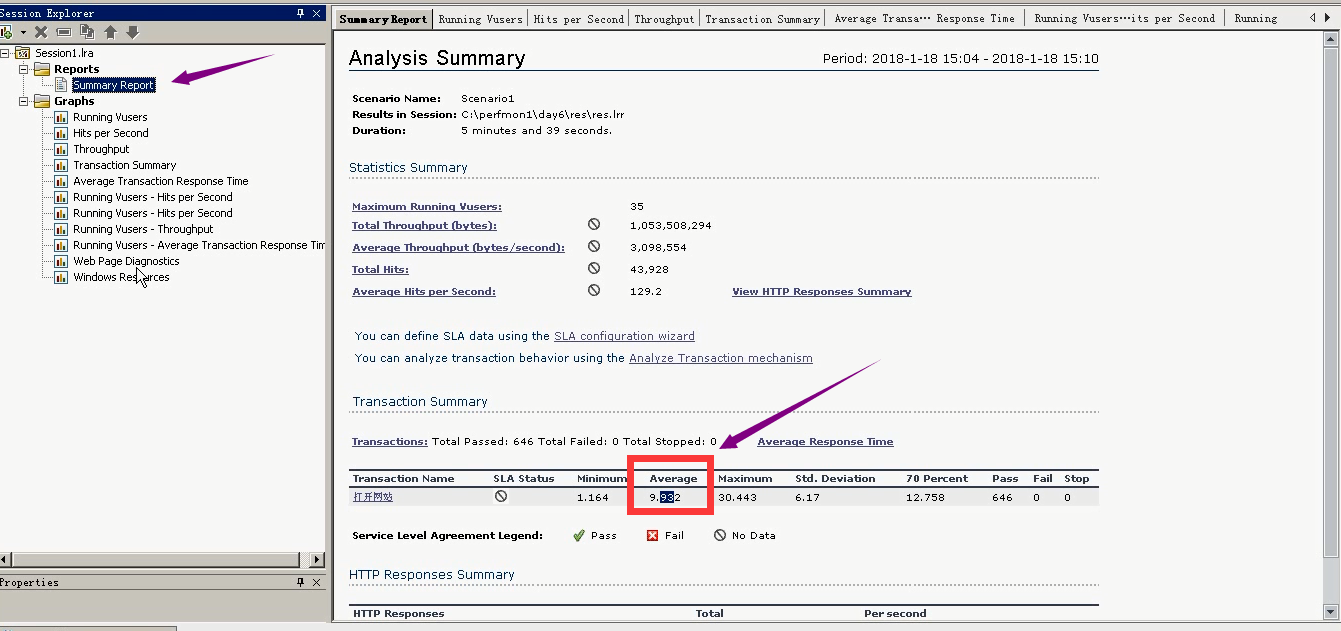
是因为这块东西导致的。
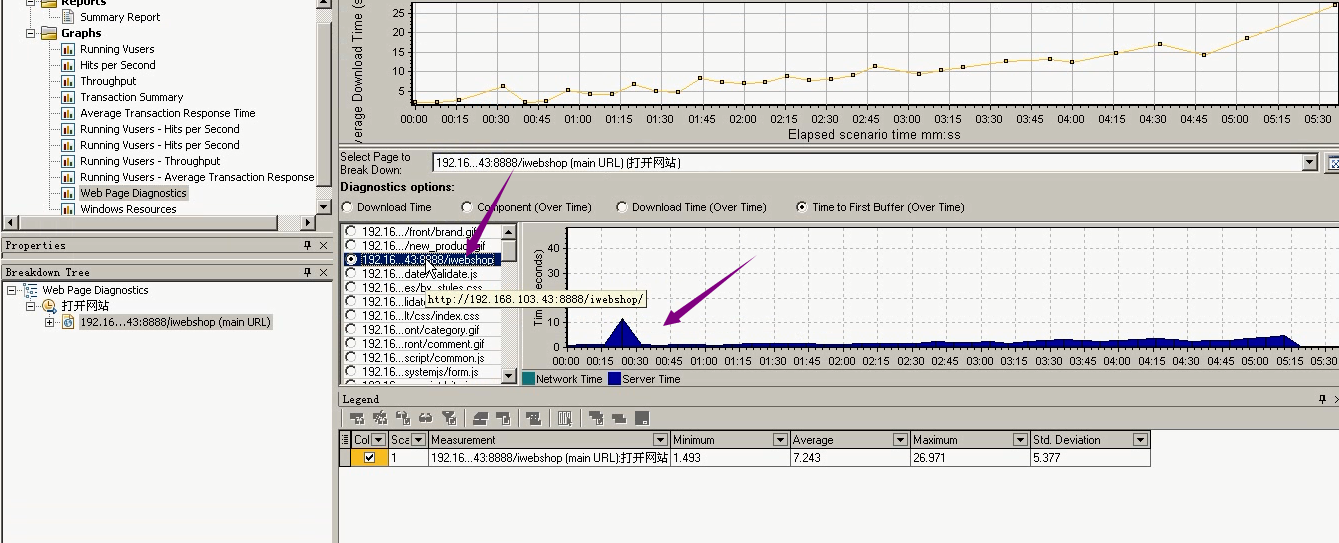
17)还增加服务器资源消耗的。
可用内存不断在下降。
%User Time(Processor_Toal):非系统程序消耗cpu的能力,最后下降是因为停下来了。整体看波动不是很大,cpu还是可以的。
可用内存:1218兆。(1个多G)
Page Reads/sec:4.17。(如果达到1000----10000可能出现情况。这里没问题。)
Page/sec:4.455。(也交换频率在4个左右也是没问题的。)
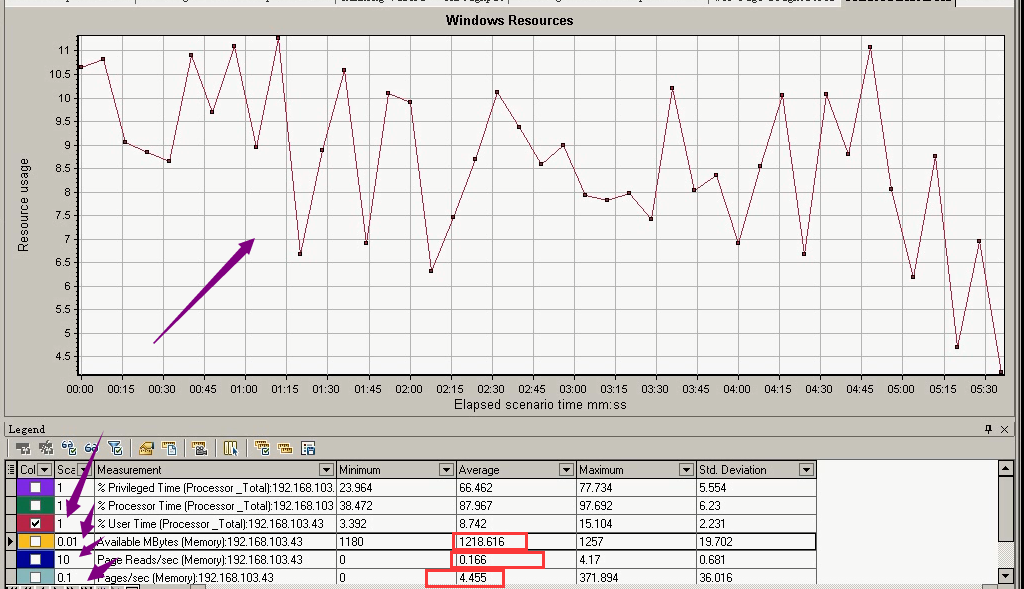
Privileged Time:系统程序对cpu的消耗
Processor Time:cpu总的消耗情况(平均:87。不太准,压力机和服务器在同一台机器上。)没有任何操作的时候,cpu使用率是下降的趋势,使用LoadRunner上涨了。
User Time:非系统程序对cpu的消耗
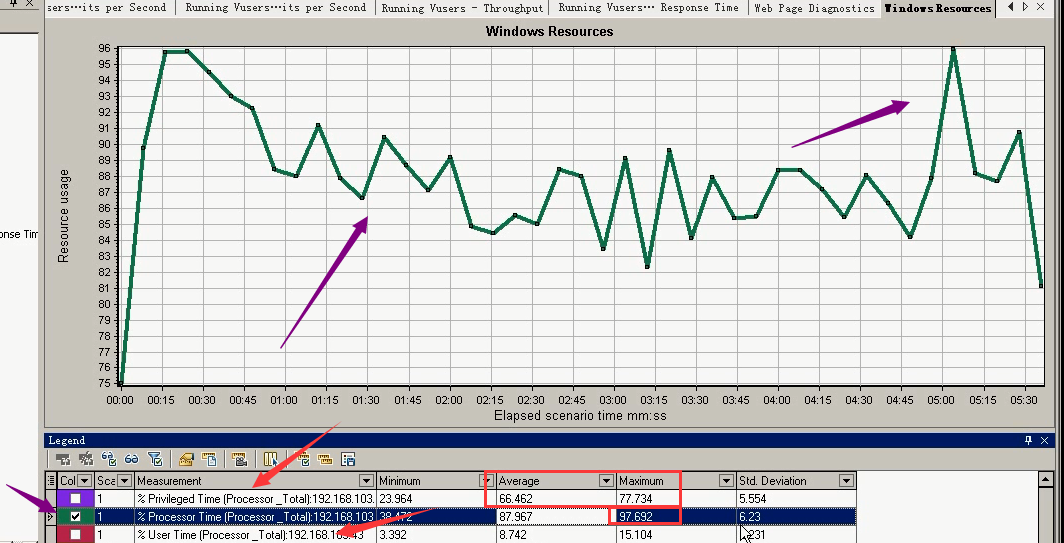
队列长度:5.045(大于了cpu4个+1)。最大:33。说明cpu是不够用的。调节cpu,看是否能够承受更多用户。
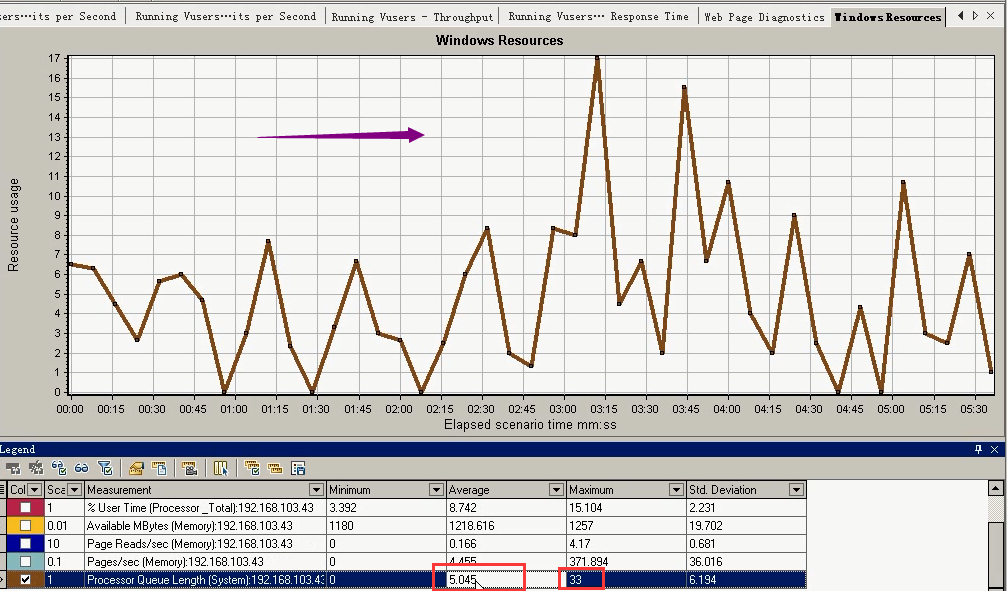
如果觉得图的波动太大,可以把密度调小(时间长点,用户小点。)一定要记得逐步增压即可。
页面有问题,时间过长。可以把问题交给开发,让它们去解决这个问题。
5.测试报告
LoadRunner自动生成报告。有两种形式。
第一种报告形式:HTML
1)查看报告
2)保存在桌面上
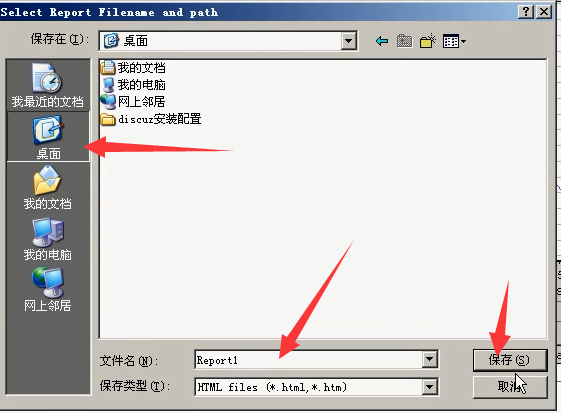
就会有这个html页面。
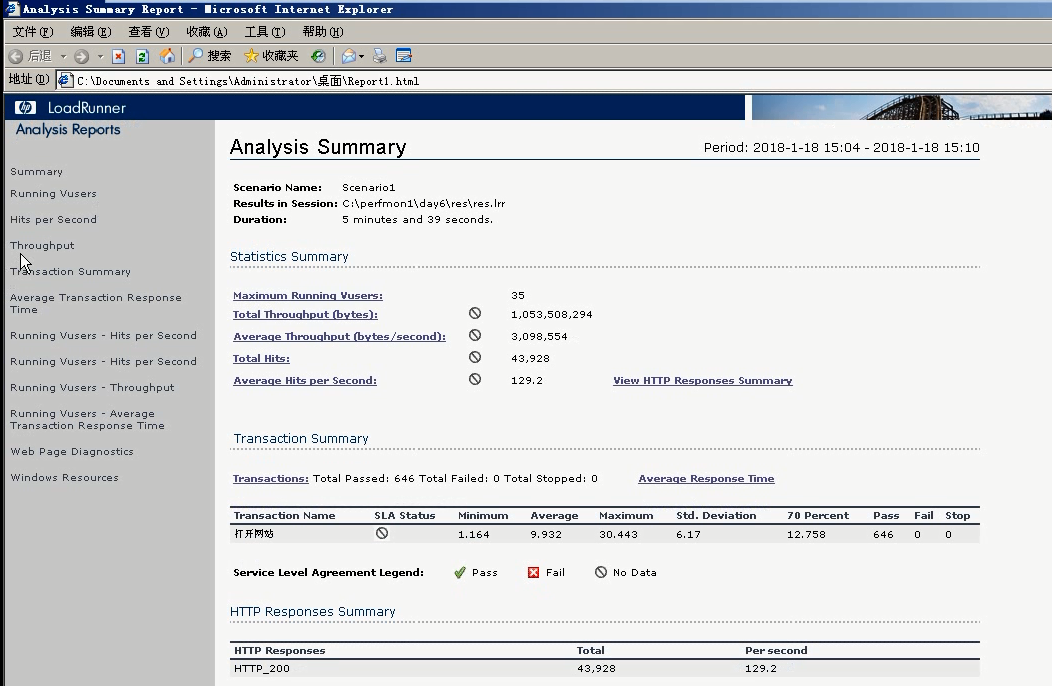
3)可以到桌面上去看。点进文件夹有很多东西(css,图片,html)。
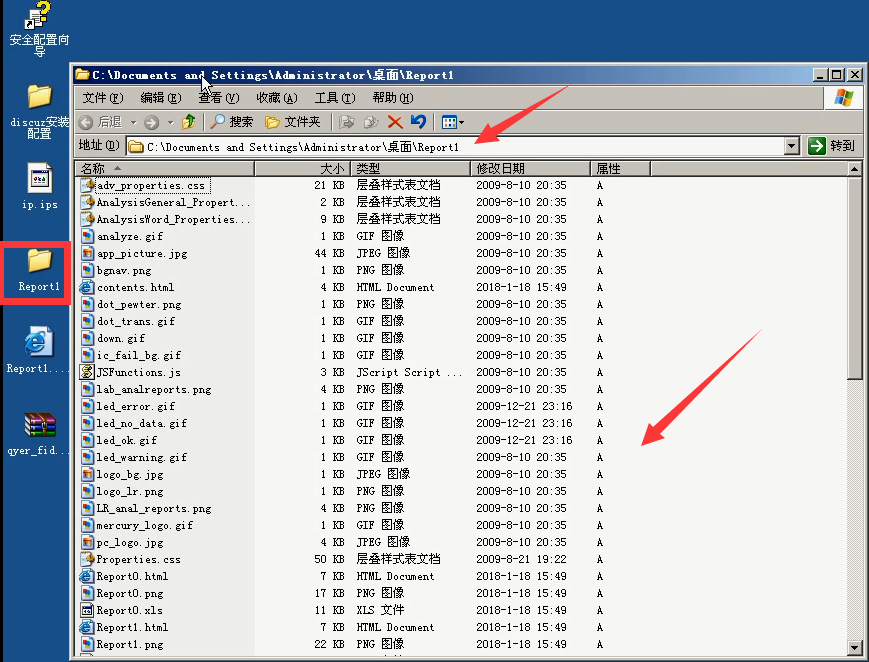
可以把这东西发给开发,让他们去看这个东西。(和上面看的图表信息是一样的)
第二种报告形式:自定义形式。(可以导成pdf或者文档都可以)
1)自定义或者新建报告:Reports----New Report
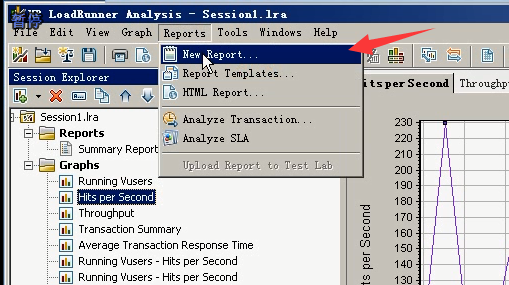
基本信息:标题,作者,工作名称,组织内容。(随便写下,不要写中文)
格式,内容。(都可以不改)
可以保存,也可以直接生成。点击Generate(这样直接是word文档的,可以通过一保存生成word,pdf,excel都可以的。)
生成word文档形式的。
可以保存很多种形式。(选择保存word文档)
所有内容:选择all----点击ok
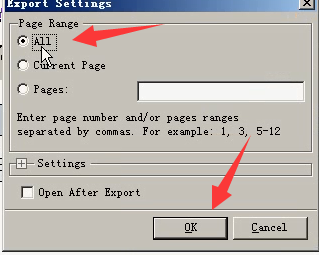
保存到桌面。类型是.docx。
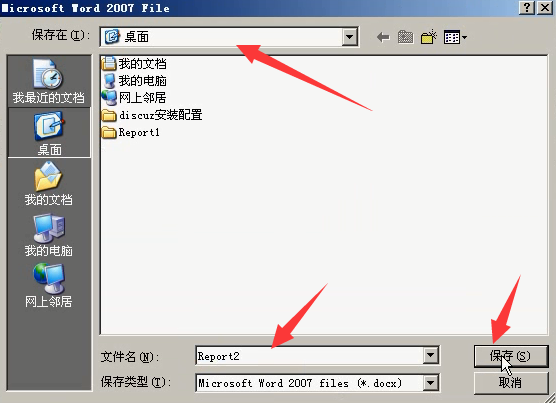
去桌面点开,就是这样的东西。(这些报告可能自己再加工一下,重要的图拿起来,要简单的解释一下。)
也可以自己写报告:
理论描述性的可以粘出来,自己用一点,不是全部用。

脚本录制:如果有cookie信息就删除,因为模拟的是第一次登陆。

做系统测试,windows2003是比较多的。
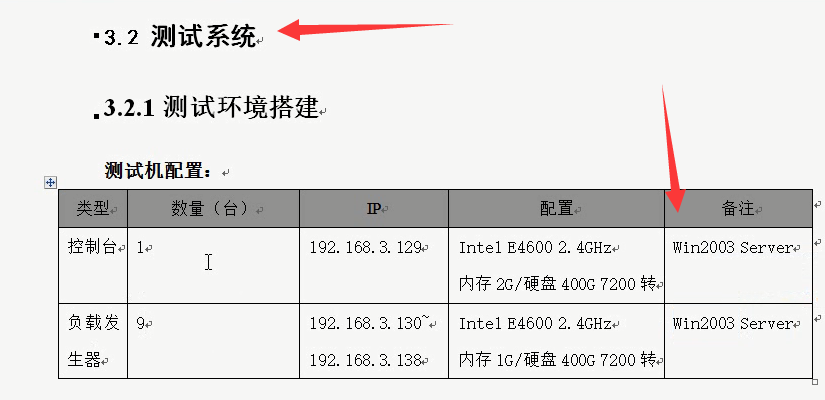
实际中,是多跑几个,拿出来对比。图是excel生成的。
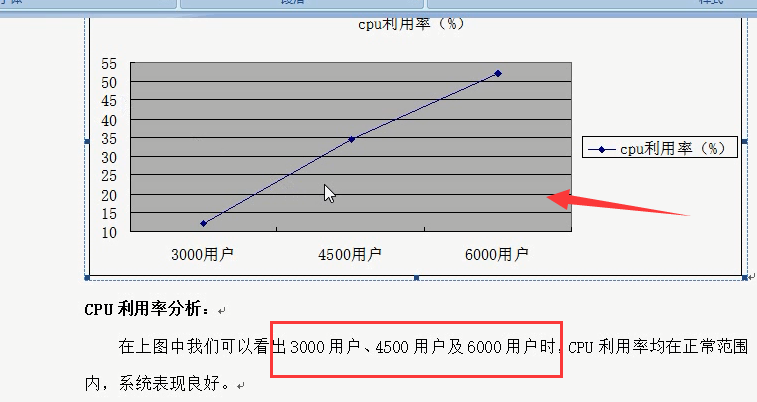
6.总结
6.1 性能测试流程
性能测试流程:
- 计划
- 方案
- 设计
- 实现(实现只写代码,没写用例)
- 执行
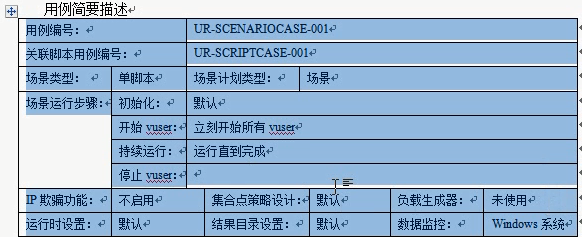
实现----场景的方式用例
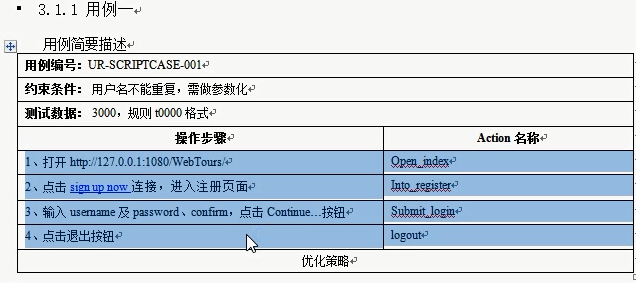
实现-----脚本的方式用例
6.2 LoadRunner性能测试
(#6.2)1.Vugen--->脚本生成器
1.函数
web_url():get请求函数
web_submit_data():post,get请求函数
web_custom_request():任何方式的请求函数
lr_output_message():输出函数,输出信息到日志中。
lr_eval_string():获取参数的值。
web_reg_find():检查点函数,检查的是响应数据。(常用)
web_find():检查点函数,检查的是页面。
web_image_check():图片检查点函数。
lr_reg_save_param():关联函数。
lr_think_time():思考时间函数。
lr_start_transaction("事务名"):开始事物
lr_end_transaction("事务名",事务状态):结束事物
lr_save_string():把字符串保存到参数中去。
lr_paramarr_idx():获取参数数组中指定位置参数的值。
lr_paramarr_random():获取参数数组中随机位置参数的值。
lr_paramarr_len():获取参数数组长度。
atoi:字符串转数字
itoa:数字转字符串
lr_rendezvous():集合函数
F1帮助文档(函数名,参数,返回值)
2.6个
1)参数化
文件类型
- File
- Unique number
- Random Number
- Data/Time(日期类型)
参数策略(9种策略)比较重要的点
- Unique+Iteration/Each occurces(难理解)
- sequential+iteration
- random+iteration
- sequential+Each occurces
- (后面三个迭代次数多,会出现一种平衡状态。)
2)关联
1.获取服务器端响应的数据
2.web_reg_save_param()---->注册型函数(哪个函数有我们要的数据,就放在该函数的前面)
3.主要依赖于左右边界值
4.关联方式
手动:
- 基本关联---》获取一个数据
- 高级关联---》获取多个数据
自动
录制过程中关联:前提是需设置好规则
录制完后关联:
- 1.先运行一次脚本
- 2.扫描脚本
- 3.扫描出结果之后,选中数据右键--->create correlation
3)事务
作用:
- 1.描述功能或者业务的响应时间
- 2.查看事务通过率
lr_start_transaction()--开始事务
lr_end_transaction()---结束事务
4)检查点
作用:主要验证业务是否成功
函数:
- web_reg_find()
- web_find()
- 区别:
web_reg_find():检查点函数,检查的是响应数据。(常用)
web_find():检查点函数,检查的是页面。
5)集合点(注意位置,不要放在事物里)
模拟多用户的同时操作
集合点策略:三种
- 1.所有用户达到指定的百分比以后,释放用户
- 2.运行中的用户达到指定的百分比以后,释放用户
- 3.指定达到一定用户量以后进行释放
6)思考时间
作用:模拟真实用户操作
设置策略:四种
- 忽略
- 按脚本中时间执行
- 脚本中时间的倍数
- 脚本中时间的百分比
(#6.2)2.Controler控制器
1.下达命令由Load Generator执行脚本
2.两类三种
手工模式:
- 按照数量模式
- 按照百分比模式
目标场景模式
3.Load Generator(叫测试机,负载机,压力机)
支持操作系统:windows,Linux
连接其他压力机:装有压力机的机器上开启代理,LoadRunner Agent process
4.Details下面可以刷新脚本以及运行时设置(注意:在脚本中修改后)
5.IP欺骗
使虚拟用户拥有独立的IP地址--->适用于局域网(比如说:百度,阿里就不可以)
注意:IP欺骗使用完成后要进行释放
6.场景方案
运行方式schedule by
- scenario:所有脚本按照相同的运行轨迹进行执行
- group:脚本是采用独立的运行轨迹进行执行
运行模式:run mode
- real-world schedule(实际模式)
- basic schedule(基础模式)
举例:性能、负载、压力测试
- scenario+basic schdeule
- Subtopic
运行策略
- 初始化、(什么时候执行vuser_init)
- start vsuer(加载用户:什么时候执行Action)
- Duration(执行完一次Action后,看要不要继续重复执行Action。)
- stop vuser(执行完Duration后,看什么时候结束掉。)
7.场景监控图表(主要6张)
1)running vusers:(正在运行用户数)
2)transaction response time:RT,事务响应时间(统计的是每一个事物的响应时间)
3)trans/sec:每秒事务数(也可以判断服务器的处理能力)
4)hits/sec:请求数(又叫并发请求数)
5)Troughput:吞吐量
- 1.服务器处理能力
- 2.网络带宽评估
6)System resources(系统资源图表)
windows:注意:需要开启远程访问(参考文档即可)
Linux:
使用LoadRunner监控:需要再服务器上安装rpc服务
通过第三方软件:nmon,cacti(下面是nmon)
- 1.捕获数据
- 2.分析数据:nmon_analyser(excel表要是office的,不能是wps的)
(#6.2)3.Analysis分析器
1.概要报告
- 统计概要
- 事务概要
- 响应概要
2.Graph
1)Running vusers:正在运行用户数
2)hps:每秒点击数
3)RT:事物响应时间
4)Troughput:吞吐
5)web Page Diagnostics---》页面细分图
- DNS解析
- Connection:连接
- First Buffer--->接收到服务器响应的第一个字节的时间
- Receive-->接收到服务器所有的响应数据的时间
- SSL handshaking--->关于https请求
- FTP Authentication-->FTP认证
6)Sytem Resources(系统资源图表)
7)图表合并
- overlay---覆盖
- tile--->上下关系
- correlate--->关联(用的比较多)
8)过滤--->sit filter/Group by
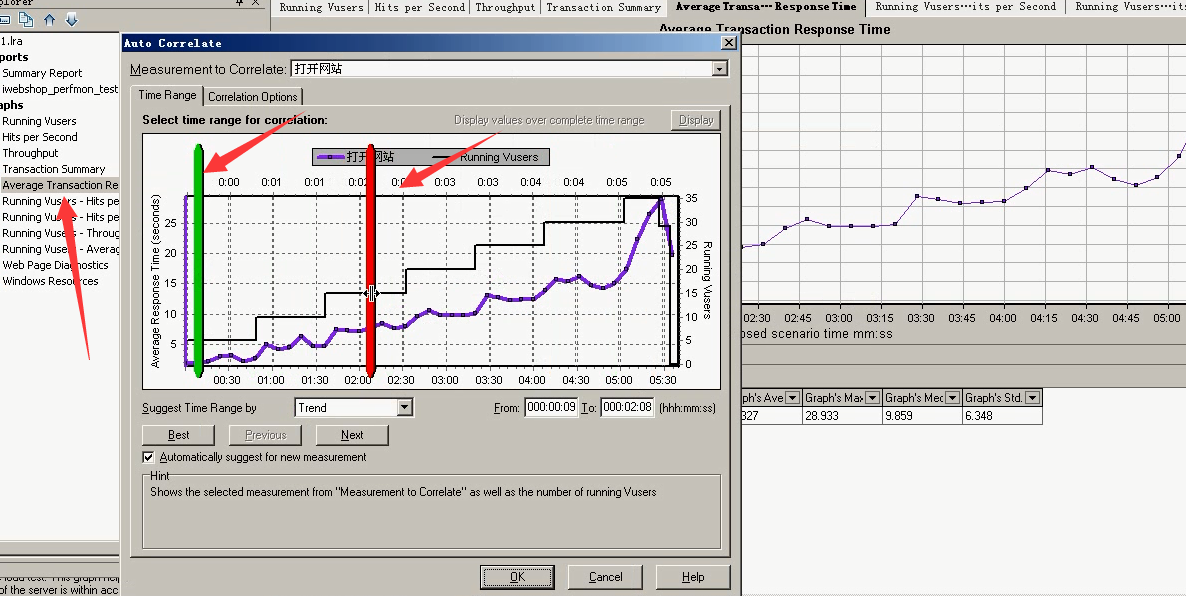
9)Auto Correlate:自动关联,可以取出某一部分内容。(选取某种图表-----右键-----Auto Correlate----移动到某一段时间----ok)
3.测试报告
生成html
自定义
(#6.2)4.模型
模型:
理发师模型
压力曲线模型
-
(#6.2)5.性能测试分类
狭义的和广义的。