前言:
测试在mysql中使用索引和不使用索引查询数据的速度区别、
创建测试用表:
CREATE TABLE `app_user` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT '',
`email` varchar(50) NOT NULL,
`phone` varchar(20) DEFAULT '',
`gender` tinyint(4) unsigned DEFAULT '0',
`password` varchar(100) NOT NULL DEFAULT '',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1000001 DEFAULT CHARSET=utf8
向表中插入一百万条数据:
-- 1、插入100万数据.
DELIMITER $$
-- 写函数之前必须要写$$标志
CREATE FUNCTION mock_data ()
RETURNS INT
BEGIN
DECLARE num INT DEFAULT 1000000;
DECLARE i INT DEFAULT 0;
WHILE i<num DO
INSERT INTO `app_user`(`name`,`email`,`phone`,`gender`)VALUES(CONCAT('用户',i),'19224305@qq.com','123456789',FLOOR(RAND()*2));
SET i=i+1;
END WHILE;
RETURN i;
END;
-- 2、执行此函数 生成一百万条数据大约要执行半分钟
SELECT mock_data()
-- 3、查询表中数据
select * from app_user;
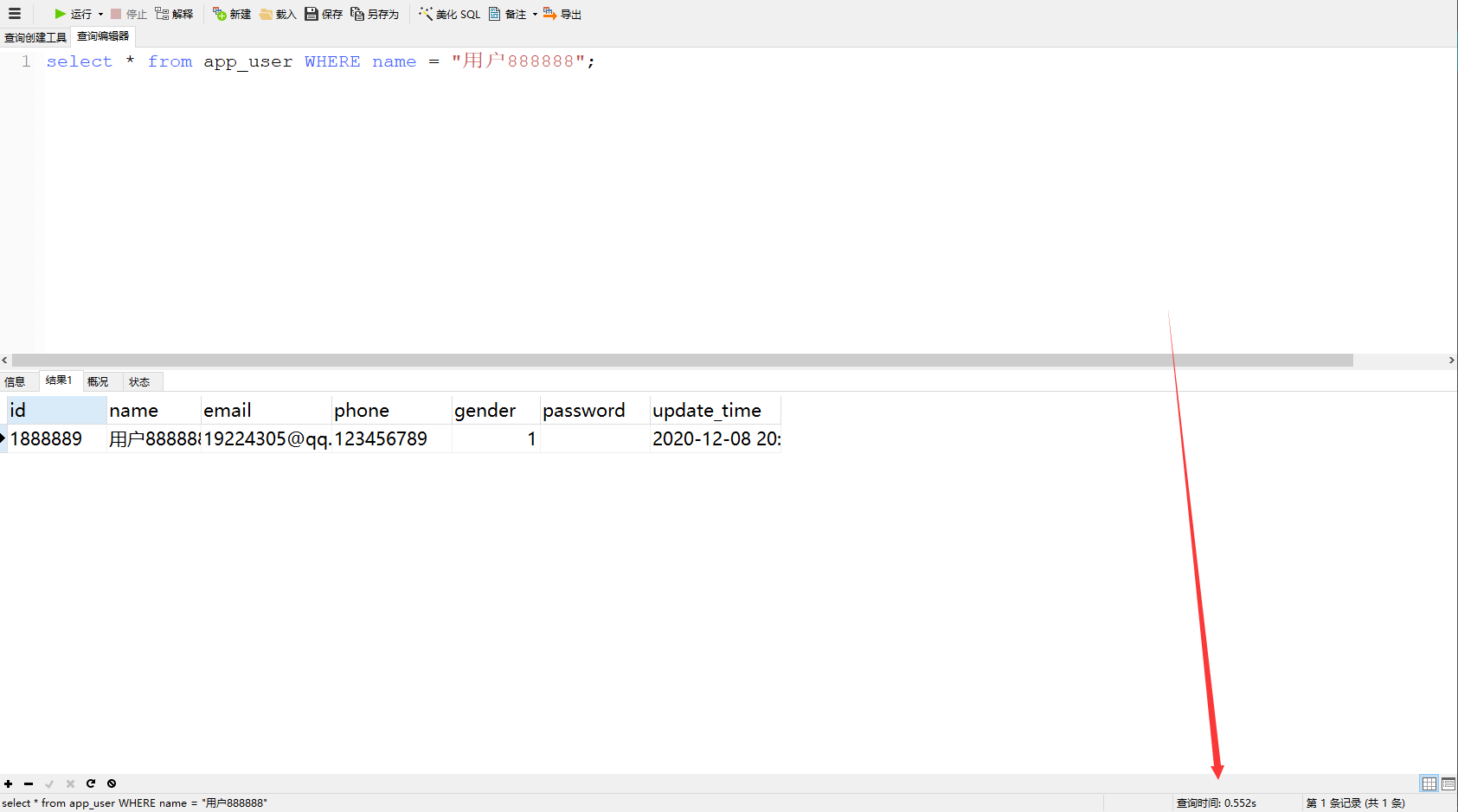
查询数据:
可以看到查询用户名为“用户名888888”的信息,耗费了0.5s左右,在人的眼睛中这是非常短暂的,但是在计算机的世界中,是非常久的。所以我们要做一些优化
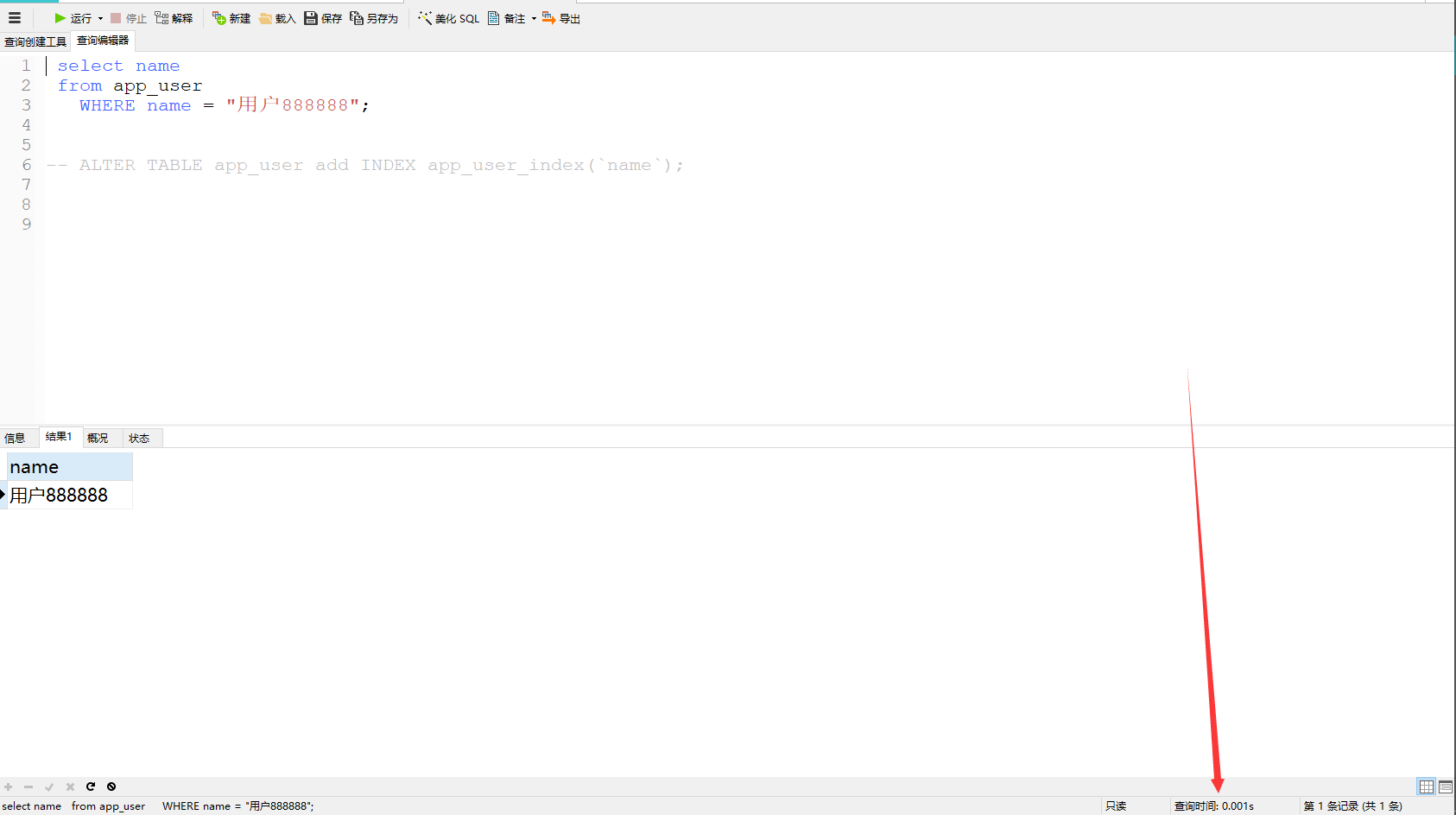
添加索引:
ALTER TABLE app_user add INDEX app_user_index(`name`);
添加索引后我们再来测试下查询数据需要多久:
索引的实现原理:
BTree索引和B+Tree索引
- BTree索引
BTree是平衡搜索多叉树,设树的度为2d(d>1),高度为h,那么BTree要满足以一下条件:
- 每个叶子结点的高度一样,等于h;
- 每个非叶子结点由n-1个key和n个指针point组成,其中d<=n<=2d,key和point相互间隔,结点两端一定是key;
- 叶子结点指针都为null;
- 非叶子结点的key都是[key,data]二元组,其中key表示作为索引的键,data为键值所在行的数据;
BTree的结构如下:
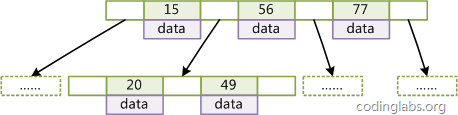
在BTree的机构下,就可以使用二分查找的查找方式,查找复杂度为h*log(n),一般来说树的高度是很小的,一般为3左右,因此BTree是一个非常高效的查找结构。
BTree的查询、插入、删除过程可以参考:https://blog.csdn.net/endlu/article/details/51720299
- B+Tree索引
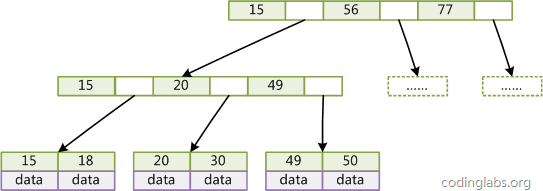
B+Tree是BTree的一个变种,设d为树的度数,h为树的高度,B+Tree和BTree的不同主要在于:
- B+Tree中的非叶子结点不存储数据,只存储键值;
- B+Tree的叶子结点没有指针,所有键值都会出现在叶子结点上,且key存储的键值对应data数据的物理地址;
- B+Tree的每个非叶子节点由n个键值key和n个指针point组成;
B+Tree的结构如下:
B+Tree对比BTree的优点:
1、磁盘读写代价更低
一般来说B+Tree比BTree更适合实现外存的索引结构,因为存储引擎的设计专家巧妙的利用了外存(磁盘)的存储结构,即磁盘的最小存储单位是扇区(sector),而操作系统的块(block)通常是整数倍的sector,操作系统以页(page)为单位管理内存,一页(page)通常默认为4K,数据库的页通常设置为操作系统页的整数倍,因此索引结构的节点被设计为一个页的大小,然后利用外存的“预读取”原则,每次读取的时候,把整个节点的数据读取到内存中,然后在内存中查找,已知内存的读取速度是外存读取I/O速度的几百倍,那么提升查找速度的关键就在于尽可能少的磁盘I/O,那么可以知道,每个节点中的key个数越多,那么树的高度越小,需要I/O的次数越少,因此一般来说B+Tree比BTree更快,因为B+Tree的非叶节点中不存储data,就可以存储更多的key。
2、查询速度更稳定
由于B+Tree非叶子节点不存储数据(data),因此所有的数据都要查询至叶子节点,而叶子节点的高度都是相同的,因此所有数据的查询速度都是一样的。
索引的使用场景:
什么时候要使用索引?
- 主键自动建立唯一索引;
- 经常作为查询条件在WHERE或者ORDER BY 语句中出现的列要建立索引;
- 作为排序的列要建立索引;
- 查询中与其他表关联的字段,外键关系建立索引
- 高并发条件下倾向组合索引;
- 用于聚合函数的列可以建立索引,例如使用了max(column_1)或者count(column_1)时的column_1就需要建立索引
什么时候不要使用索引?
- 经常增删改的列不要建立索引;
- 有大量重复的列不建立索引;
- 表记录太少不要建立索引。只有当数据库里已经有了足够多的测试数据时,它的性能测试结果才有实际参考价值。如果在测试数据库里只有几百条数据记录,它们往往在执行完第一条查询命令之后就被全部加载到内存里,这将使后续的查询命令都执行得非常快--不管有没有使用索引。只有当数据库里的记录超过了1000条、数据总量也超过了MySQL服务器上的内存总量时,数据库的性能测试结果才有意义。
索引失效的情况:
- 在组合索引中不能有列的值为NULL,如果有,那么这一列对组合索引就是无效的。
- 在一个SELECT语句中,索引只能使用一次,如果在WHERE中使用了,那么在ORDER BY中就不要用了。
- LIKE操作中,'%aaa%'不会使用索引,也就是索引会失效,但是‘aaa%’可以使用索引。
- 在索引的列上使用表达式或者函数会使索引失效,例如:select * from users where YEAR(adddate)<2007,将在每个行上进行运算,这将导致索引失效而进行全表扫描,因此我们可以改成:select * from users where adddate<’2007-01-01′。其它通配符同样,也就是说,在查询条件中使用正则表达式时,只有在搜索模板的第一个字符不是通配符的情况下才能使用索引。
- 在查询条件中使用不等于,包括<符号、>符号和!=会导致索引失效。特别的是如果对主键索引使用!=则不会使索引失效,如果对主键索引或者整数类型的索引使用<符号或者>符号不会使索引失效。(,不等于,包括<符号、>符号和!,如果占总记录的比例很小的话,也不会失效)
- 在查询条件中使用IS NULL或者IS NOT NULL会导致索引失效。
- 字符串不加单引号会导致索引失效。更准确的说是类型不一致会导致失效,比如字段email是字符串类型的,使用WHERE email=99999 则会导致失败,应该改为WHERE email='99999'。
- 在查询条件中使用OR连接多个条件会导致索引失效,除非OR链接的每个条件都加上索引,这时应该改为两次查询,然后用UNION ALL连接起来。
- 如果排序的字段使用了索引,那么select的字段也要是索引字段,否则索引失效。特别的是如果排序的是主键索引则select * 也不会导致索引失效。
- 尽量不要包括多列排序,如果一定要,最好为这队列构建组合索引;