1. 选题背景
1.1 选题概述
很早之前就想要写一个自己的博客了,趁着现在学校安排的web课设选题,决定把它给做出来,也顺便复习一下曾经学过的一些web技术和框架。
只有动手做完之后,才能发现不足之处,比如一些细节的处理,大体的表设计,业务逻辑接口的编写,以及一些bug的存在,还可以让自己更熟练的开发各种功能的网页。
1.2 技术选型
后端技术:Springboot + Spring + Mybatis + Druid + Swagger + 热部署 + Mysql
前端技术:html+css+js+Jquery+bootstrap+vue.js
2. 总体系统功能模块
2.1 需求分析
前端需求分析:
①简洁/美观——个人很喜欢像Mac那样的简洁风,越简单越好,当然也得好看;(首页轮播图+分类左右排版+导航栏+博文详情页)
②最好是单页面——单页面的目的一方面是为了简洁,另一方面也是为了实现起来比较简单;(单页面就不用vue.js做SPA了,还是通过a标签原地跳转的方式模拟单页面)
③自适应——至少能适配常见的手机分辨率吧,我可不希望自己的博客存在显示差异性的问题;(Bootstrap的栅格系统+CSS媒体查询+配合JS实现)
可能出现的页面如图:

图1
PS:留言页和关于页,简历页以后再实现

图2
PS:评论功能暂未实现,只实现了博文分类(CURD)和文章管理(常见的CURD)的功能
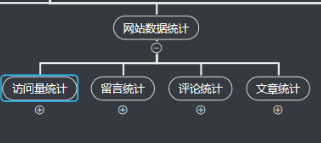
图3
PS:数据统计模块暂未实现
2.2 表结构设计
个人博客系统数据结构设计:

表1
PS:此图用Navicat 的表逆向模型 的功能实现
2.3 表结构分析
1)分类信息表(tbl_category_content):
CREATE TABLE `tbl_category_info` (
`id` bigint(40) NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL COMMENT '分类名称',
`number` tinyint(10) NOT NULL DEFAULT '0' COMMENT '该分类下的文章数量',
`create_by` datetime NOT NULL COMMENT '分类创建时间',
`modified_by` datetime NOT NULL COMMENT '分类修改时间',
`is_effective` tinyint(1) NOT NULL DEFAULT '1' COMMENT '是否有效,默认为1有效,为0无效',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
表2
2)文章内容表(tbl_article_content):
CREATE TABLE `tbl_article_content` (
`id` bigint(40) NOT NULL AUTO_INCREMENT,
`content` text NOT NULL,
`article_id` bigint(40) NOT NULL COMMENT '对应文章ID',
`create_by` datetime NOT NULL COMMENT '创建时间',
`modifield_by` datetime NOT NULL COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
表2
PS: 文章内容单独分一个表是因为要把MD格式的文章直接从后台添加到数据库中,属于大文本类型,不放在文章基础信息表中,是为了查询效率,不需要索引大文本域
3)文章信息表(tbl_article_info):
CREATE TABLE `tbl_article_info` (
`id` bigint(40) NOT NULL AUTO_INCREMENT COMMENT '主键',
`title` varchar(50) NOT NULL DEFAULT '' COMMENT '文章标题',
`summary` varchar(300) NOT NULL DEFAULT '' COMMENT '文章简介,默认100个汉字以内',
`is_top` tinyint(1) NOT NULL DEFAULT '0' COMMENT '文章是否置顶,0为否,1为是',
`traffic` int(10) NOT NULL DEFAULT '0' COMMENT '文章访问量',
`create_by` datetime NOT NULL COMMENT '创建时间',
`modified_by` datetime NOT NULL COMMENT '修改日期',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
表3
下面为关联表
PS:用关联表,是为了不让后端做多表连接查询,影响查询效率,所以也不需要建立外键,
让后端在Service层手动完成外键的功能,大大减少了数据库的压力。
4)文章分类表(tbl_article_category):
CREATE TABLE `tbl_article_category` (
`id` bigint(40) NOT NULL AUTO_INCREMENT,
`sort_id` bigint(40) NOT NULL COMMENT '分类id',
`article_id` bigint(40) NOT NULL COMMENT '文章id',
`create_by` datetime NOT NULL COMMENT '创建时间',
`modified_by` datetime NOT NULL COMMENT '更新时间',
`is_effective` tinyint(1) DEFAULT '1' COMMENT '表示当前数据是否有效,默认为1有效,0则无效',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
表4
5)文章题图表(tbl_article_picture):
CREATE TABLE `tbl_article_picture` (
`id` bigint(40) NOT NULL AUTO_INCREMENT,
`article_id` bigint(40) NOT NULL COMMENT '对应文章id',
`picture_url` varchar(100) NOT NULL DEFAULT '' COMMENT '图片url',
`create_by` datetime NOT NULL COMMENT '创建时间',
`modified_by` datetime NOT NULL COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='这张表用来保存题图url,每一篇文章都应该有题图';
表5
PS:题图用于前端首页的轮播图和文章详情页文章的配图
3. 原型参考
3.1 前端原型参考
首页:
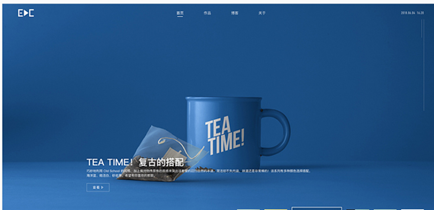
图4
文章分类页:
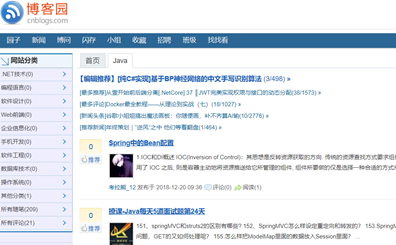
图5
文章详情页:

图6
3.2 后端原型参考
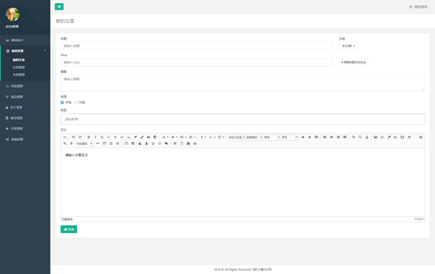
图7
4.项目搭建
4.1 Springboot项目配置
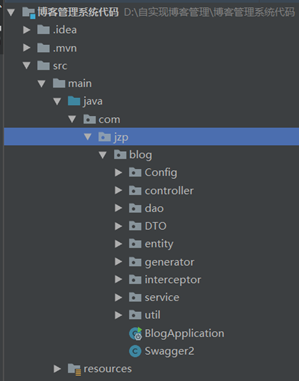
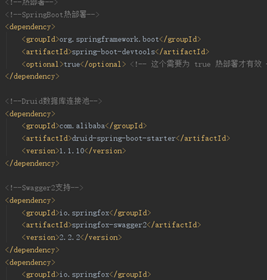
图8
PS:上图为从Springboot官网Springboot initializer 后搭建的Springboot项目,在上面进行
二次开发后,最后的开发的目录结构如上
Maven工程的依赖为:Pom文件如下

图9
对项目目录结构进行简要说明:
- controller:控制器 (MVC的C模块,用于处理url映射请求以及ResfulAPI的设计)
- dao:实际上这个包可以改名叫mapper,因为里面放的应该是MyBatis逆向工程自动生成之后的mapper类。(就是数据访问对象层,访问数据库的,增删改查的方法都在这里)
- entity:实体类,(MVC中M模块,Model,对应表的JavaBean)还会有一些MyBatis生成的example
- generator:MyBatis逆向工程生成类
- interceptor:SpringBoot 拦截器 (拦截后台管理系统的请求,判断有无管理员登陆的权限)
- service:Service层,里面还有一层impl目录 (业务逻辑接口的开发都在这里)
- util:一些工具类可以放在里面 (Markdown格式转html的工具类也在这里)
- mapper:用于存放MyBatis逆向工程生成的.xml映射文件
- static:这个目录存放一些静态文件,简单了解了一下Vue的前后端分离,前台文件以后也需要放在这个目录下面(放网页和JS,CSS,image的地方)
4.2 Mybatis框架集成配置
1. Springboot继承Mybatis是通过依赖starter来集成Mybatis框架的
Pom依赖如下:
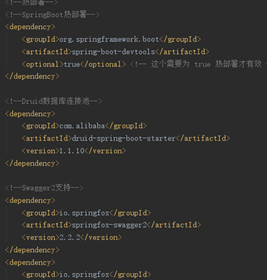
图10
2. Mybatis逆向工程:
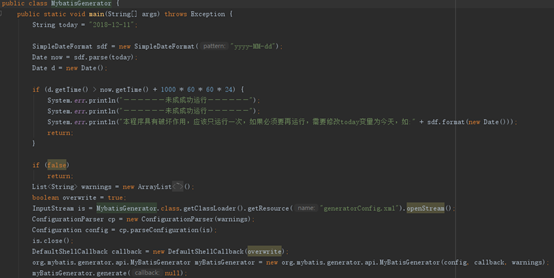
图11
PS:逆向工程用于自动根据配置的数据库来生成Entity类,和mapper映射文件和mapper映射接口(用来操作数据库的),相当于自动生成了一大堆的sql语句(增删改查),上一层直接调用DAO层的接口即可访问数据库 (松耦合)
4.3 Restful设计与Swagger2配置
1.概要:RestfulAPI是一种HTTP请求的规范,可以用到put请求表示更新数据,
Delete请求表示删除数据,post请求表示添加数据,get请求表示查询数据,合理的运用
HTTP方法来完成请求,避免了以前WEB开发只用get 和post请求的这种不规范设计
格式为下图:
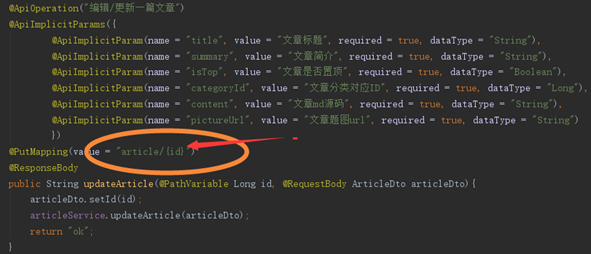
图12
2. Swaager文档用于图形化RestfulAPI风格的接口,效果如下图:
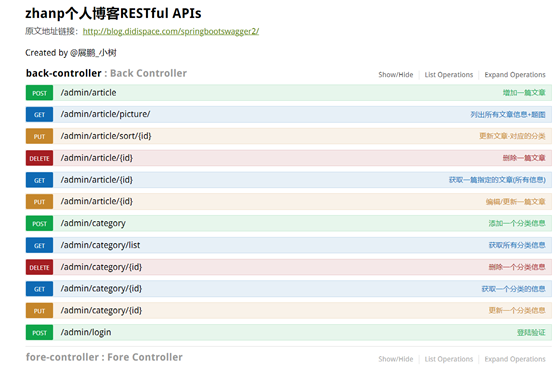
图13
4.4 数据库连接池配置和日志配置
1. 采用了Druid数据库连接池(当今最实用,效率也很高的阿里巴巴的连接池)
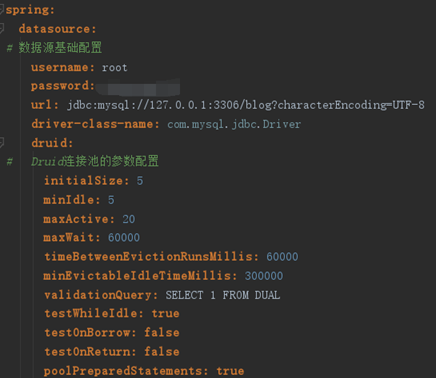
图14
2. 日志配置: Springboot天生集成了logback日志,所以不需要再重新导入新的日志框架,
直接复制日志配置文件即可,但注意名字要按格式来,才能被加载,如图:
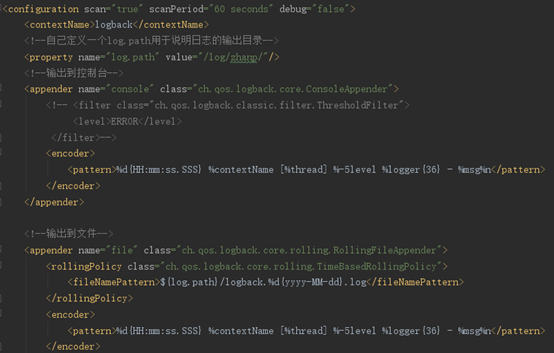
图15
4.5 拦截器配置
登陆拦截器代码如下:(还用Cookie实现了30分钟有效期的自动登陆)
public class BackInterceptor implements HandlerInterceptor {
@Override
public boolean
preHandle(HttpServletRequest request, HttpServletResponse response, Object
handler) throws Exception {
//通过session判断是否已经登陆
String username =
(String)request.getSession().getAttribute("username");
String name = "zhanp";
//传输的加密先放一边,后面再看下
//先判断Session不为空,说明已经登陆了
if(StringUtils.isEmpty(username)){
Cookie[] cookies =
request.getCookies();
//判断cookie中有没有自动登陆的凭证
if(cookies!=null){
for(Cookie cookie:cookies){
if(!StringUtils.isEmpty(cookie)&&cookie.getName().equals(name)){
return true;
}
}
}else{
return false;
}
}
return true;
}
}
5. 后端开发过程
5.1 Entity层开发

图16
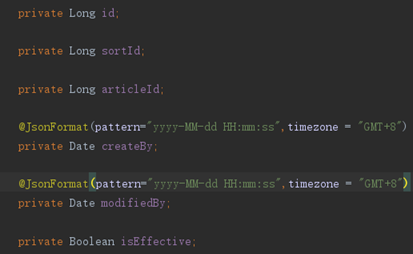
图17
这些实体类对应的是Mysql中建立的表的名字,属性名字为表的字段名
5.2 Service层开发
图18
1. 比如文章的业务接口开发有
1.1 添加文章->要填充文章内容表,文章-分类表,文章-题图表,文章信息表,还要修改相应分类下的文章数目
public void addArticle(ArticleDto articleDto)
{
//1.填充文章信息表----title/summary/isTop
// 前端不可能给你Id的,这是后端自动生产的,要在后端获取Id
// Long id = articleDto.getId();
String title =
articleDto.getTitle();
String summary =
articleDto.getSummary();
Boolean isTop = articleDto.getIsTop();
ArticleInfo articleInfo = new
ArticleInfo();
articleInfo.setTitle(title);
articleInfo.setSummary(summary);
articleInfo.setIsTop(isTop);
//1.1 写入文章信息表中
//1.2 并查询新增的文章Id。。。因为返回主键也需要select和插入处于同一事务,所以不会返回正确的插入后的主键
articleInfoMapper.insertSelective(articleInfo) ;
//从参数里返回主键
Long id = articleInfo.getId();
//2. 填充文章-内容表----文章Id/content
ArticleContent articleContent =
new ArticleContent();
articleContent.setArticleId(id);
articleContent.setContent(articleDto.getContent());
//2.1 写入文章-内容表
articleContentMapper.insertSelective(articleContent);
//3. 填充文章 - 分类表---文章Id/分类Id
ArticleCategory articleCategory =
new ArticleCategory();
articleCategory.setArticleId(id);
articleCategory.setSortId(articleDto.getCategoryId());
//3.1 写入文章 - 分类表
articleCategoryMapper.insertSelective(articleCategory);
//3.2 分类下的文章信息 + 1
Long sortId =
articleCategory.getSortId();
//查询你源分类信息条目
CategoryInfo categoryInfo =
categoryInfoMapper.selectByPrimaryKey(sortId);
//文章+1
categoryInfo.setNumber((byte)
(categoryInfo.getNumber()+1));
categoryInfoMapper.updateByPrimaryKeySelective(categoryInfo);
//4. 填充文章-题图表 ---文章Id/图片url
ArticlePicture articlePicture =
new ArticlePicture();
articlePicture.setArticleId(id);
articlePicture.setPictureUrl(articleDto.getPictureUrl());
//4.1写入 文章-题图表
articlePictureMapper.insertSelective(articlePicture);
}
1.2 更新文章:
* 根据封装的ArticleDto参数 选择性的更新文章
* warning: ArticleDto参数后台按实际情况应该只有文章基础信息的Id,和图片url,内容content,分类Id这种,
* 而不会有从表的主键Id,所以除了文章信息表外,其他从表需要根据文章Id关联查询出来
* 比如更新文章基础信息(title,summary,isTop)
* 更新文章-分类表的信息
* 更新文章-题图表的信息
*
* 还有更新文章时分类信息改了的话,要调用分类文章-的api
updateArticleCategory()去重新统计分类下的数目,这个写漏了
@Override
public void updateArticle(ArticleDto articleDto) {
Long id = articleDto.getId();
//1.文章基础信息表
//1.1 填充ArticleInfo参数
ArticleInfo articleInfo = new
ArticleInfo();
articleInfo.setId(id);
articleInfo.setSummary(articleDto.getSummary());
articleInfo.setIsTop(articleDto.getIsTop());
articleInfo.setTitle(articleDto.getTitle());
articleInfo.setTraffic(articleDto.getTraffic());
articleInfoMapper.updateByPrimaryKeySelective(articleInfo);
//2. 文章-分类表
//根据文章Id----找出对应的文章分类表 的条目
ArticleCategoryExample
articleCategoryExample = new ArticleCategoryExample();
ArticleCategoryExample.Criteria
articleCategoryExampleCriteria = articleCategoryExample.createCriteria();
articleCategoryExampleCriteria.andArticleIdEqualTo(id);
List<ArticleCategory>
articleCategoryList = articleCategoryMapper.selectByExample(articleCategoryExample);
ArticleCategory category =
articleCategoryList.get(0);
//2.1 先检查源分类Id与更新过来的分类Id是否相等
// 如果分类被修改过了,那么分类下的文章数目也要修改
//前者是源Id,后者是更新过来的Id
Long sourceSortId =
category.getSortId();
Long categoryId =
articleDto.getCategoryId();
if(!sourceSortId.equals(categoryId)){
//2.3 更新分类下的文章信息
updateArticleCategory(id,categoryId);
}
//3.文章-题图表
ArticlePictureExample
articlePictureExample = new ArticlePictureExample();
articlePictureExample.or().andArticleIdEqualTo(id);
List<ArticlePicture>
pictureList = articlePictureMapper.selectByExample(articlePictureExample);
ArticlePicture articlePicture =
pictureList.get(0);
articlePicture.setPictureUrl(articleDto.getPictureUrl());
articlePictureMapper.updateByPrimaryKeySelective(articlePicture);
//4.文章-内容表
ArticleContentExample
articleContentExample = new ArticleContentExample();
articleContentExample.or().andArticleIdEqualTo(id);
List<ArticleContent>
contentList = articleContentMapper.selectByExample(articleContentExample);
ArticleContent articleContent =
contentList.get(0);
articleContent.setContent(articleDto.getContent());
articleContentMapper.updateByPrimaryKeyWithBLOBs(articleContent);
}
1.3 获取一篇文章(根据文章Id)
@Override
public ArticleDto
getOneById(Long id) {
ArticleDto articleDto = new
ArticleDto();
//1. 文章信息表内的信息 填充
到 Dto
ArticleInfo articleInfo =
articleInfoMapper.selectByPrimaryKey(id);
//1.1 增加浏览量 + 1
ArticleInfo info = new ArticleInfo();
info.setId(id);
info.setTraffic(articleInfo.getTraffic()+1);
articleInfoMapper.updateByPrimaryKeySelective(info);
articleDto.setId(id);
articleDto.setTitle(articleInfo.getTitle());
articleDto.setSummary(articleInfo.getSummary());
articleDto.setIsTop(articleInfo.getIsTop());
//没用到缓存,所以访问量统计还是在SQL操作这里增加把(一个博客,做啥缓存啊)
articleDto.setCreateBy(articleInfo.getCreateBy());
articleDto.setTraffic(articleInfo.getTraffic()+1);
//2. 文章内容表内的信息 填充
到 Dto
ArticleContentExample
articleContentExample = new ArticleContentExample();
articleContentExample.or().andArticleIdEqualTo(id);
List<ArticleContent>
contentList =
articleContentMapper.selectByExampleWithBLOBs(articleContentExample);
ArticleContent articleContent = contentList.get(0);
articleDto.setContent(articleContent.getContent());
//填充关联表的主键,其他业务可能通过调用getOneById 拿到Dto里的这个主键
articleDto.setArticleContentId(articleContent.getId());
//3.文章-分类表内的信息 填充 到 Dto
ArticleCategoryExample
articleCategoryExample = new ArticleCategoryExample();
articleCategoryExample.or().andArticleIdEqualTo(id);
List<ArticleCategory>
articleCategories =
articleCategoryMapper.selectByExample(articleCategoryExample);
ArticleCategory articleCategory =
articleCategories.get(0);
//3.1设置文章所属的分类Id+
从表主键 --从表
Long sortId =
articleCategory.getSortId();
articleDto.setCategoryId(sortId);
articleDto.setArticleCategoryId(articleCategory.getId());
//3.2找分类主表 --设置分类信息
CategoryInfo categoryInfo = categoryInfoMapper.selectByPrimaryKey(sortId);
articleDto.setCategoryName(categoryInfo.getName());
articleDto.setCategoryNumber(categoryInfo.getNumber());
//4.文章-题图表
ArticlePictureExample
articlePictureExample = new ArticlePictureExample();
articlePictureExample.or().andArticleIdEqualTo(id);
List<ArticlePicture>
articlePictures = articlePictureMapper.selectByExample(articlePictureExample);
ArticlePicture picture =
articlePictures.get(0);
//4.1设置图片Dto
articleDto.setArticlePictureId(picture.getId());
articleDto.setPictureUrl(picture.getPictureUrl());
return articleDto;
}
1.4 找出分类下所有的文章信息
@Override
public List<ArticleWithPictureDto> listByCategoryId(Long id) {
//1. 先找出分类下所有的文章
ArticleCategoryExample articleCategoryExample
= new ArticleCategoryExample();
articleCategoryExample.or().andSortIdEqualTo(id);
List<ArticleCategory>
articleCategories =
articleCategoryMapper.selectByExample(articleCategoryExample);
ArrayList<ArticleWithPictureDto> list = new ArrayList<>();
//1.1遍历
for(ArticleCategory
articleCategory:articleCategories){
ArticleWithPictureDto
articleWithPictureDto = new ArticleWithPictureDto();
//1.1.1 取出文章
Long articleId =
articleCategory.getArticleId();
ArticleInfo articleInfo =
articleInfoMapper.selectByPrimaryKey(articleId);
//1.1.2 取出文章对应的图片url
ArticlePictureExample
articlePictureExample = new ArticlePictureExample();
articlePictureExample.or().andArticleIdEqualTo(articleId);
List<ArticlePicture> articlePictures
= articlePictureMapper.selectByExample(articlePictureExample);
ArticlePicture picture =
articlePictures.get(0);
articleWithPictureDto.setId(articleId);
articleWithPictureDto.setArticlePictureId(picture.getId());
articleWithPictureDto.setTitle(articleInfo.getTitle());
articleWithPictureDto.setSummary(articleInfo.getSummary());
articleWithPictureDto.setIsTop(articleInfo.getIsTop());
articleWithPictureDto.setTraffic(articleInfo.getTraffic());
articleWithPictureDto.setPictureUrl(picture.getPictureUrl());
list.add(articleWithPictureDto);
}
return list;
}
PS:还有一系列的接口开发在源码中查看吧
5.3 DTO层开发
图19
用于封装了多个实体类的属性,用于前后端交互的整体属性封装,便捷实用的进行
JSON数据交互
5.4 Controller层开发

图20
BaseController为后台控制器
ForeController为前台控制器
比如更新文章的Controller
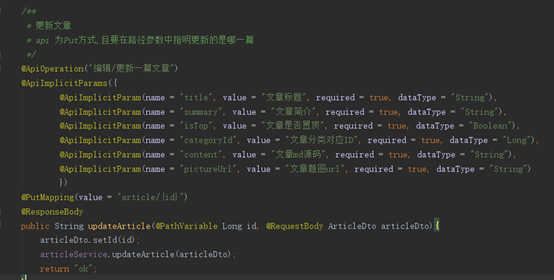
图21

图22

图23
6. 前端开发过程
6.1 登陆页开发
Login.html


图24

图25
效果如下:

图26
还用了轮播图的形式
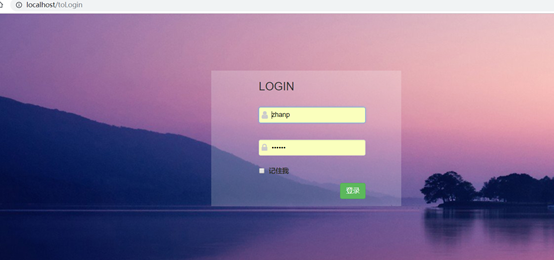
图27
url:为toLogin,代码实现为:

图28
6.2 分类管理页开发

图29
Category.html
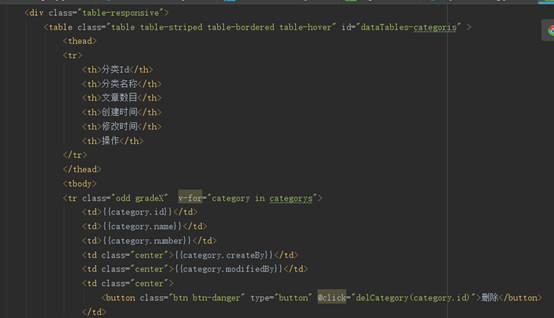
图30
图31
图32
效果如下:
图33
6.3博文管理页开发

图34
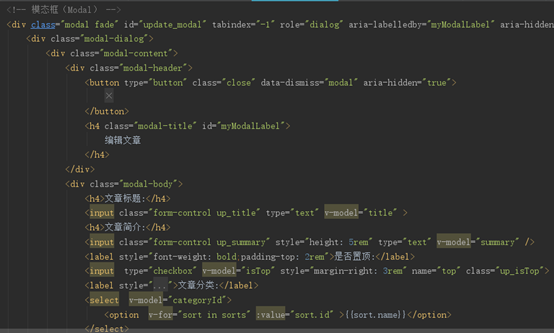
图35
效果如下:

图36
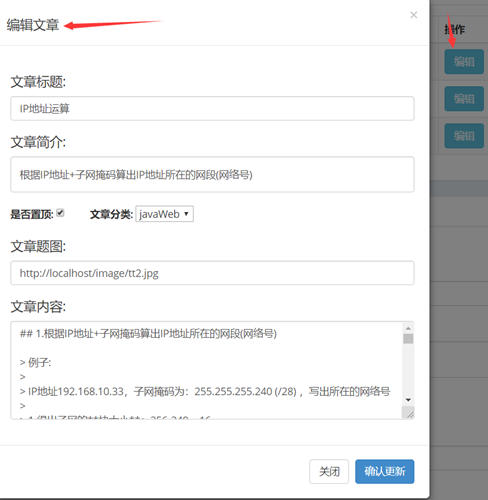
图37
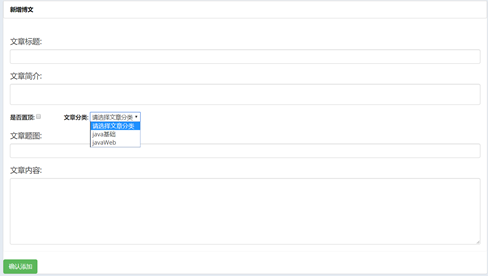
PS:还用了动态的placeholder来保存更新前的数据,在此上面做修改。这个是模态框
图38
PS:这些分类都是动态从数据库里拉过来的,不是静态的!!!
6.4 博客首页开发

图39

图40
导航栏 + 最新几篇文章的轮播图(点击可进入文章详情页)
6.5 博客文章详情页开发
代码如下:
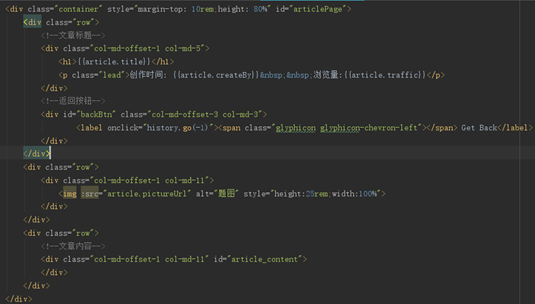
图41
效果如下:
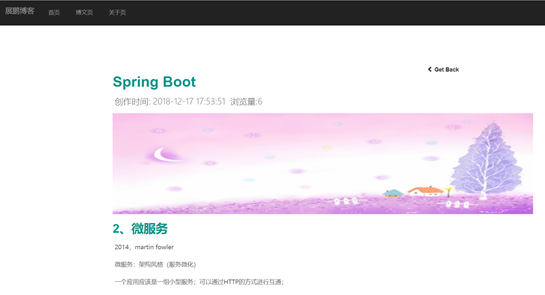
图42
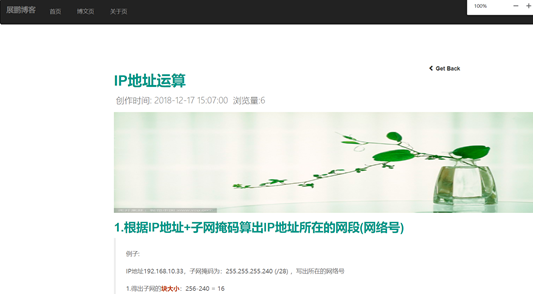
图43
PS:这些都是动态的,非静态页面,静态就没有意义了
6.6 博文分类页面

图44
效果如下:
图45

图46

图47
PS:还设置了动态的分类选中效果,根据不同的分类显示不同的文章信息,点击文章信息,即可进入文章详情页
7. 项目心得总结
1. 以后要多加练习,多做项目来熟悉一般web项目的整个开发流程,比如搭建项目的环境,相应框架的配置。
2. 还要多总结开发过程中遇到的bug和一些细节的处理,比如这个效果怎么实现,这个功能用什么方法实现,要写个笔记好好记录一下,方便以后的开发,
不需要再次查询百度或谷歌。
3. 还要重视数据库,不要以为只会写几条增删改查的sql语句即可,关键是
对数据库的设计,对表的编排,关联表的运用,如何设计表结构让程序跑的更快,开发更方便。还要重视数据库的索引技术,分表分库,以后都可以深造
4. 不要停留在只知道这个技术,而不去动手实践,这些知识不实践就会忘。
比如Mybatis配置文件和框架整合,或Spring的配置,或Springboot的错误处理页面的定制,或者Thymeleaf模板引擎的熟练使用(虽然前后端分离以及不用这种类似JSP的模板引擎了),或者是事务的添加,又或者前后端密码校验的加密处理,以及前端CSS的布局,样式的熟练掌握,bootstrap常用的样式的实现,vue.js的细节和bug等等。
5.但是又不能停留在只会用这些表面的框架和技术,而不懂其原理,基础和原理是很重要的,对于后期的debug排查错误,对原理熟悉的,可以很快的找寻出是哪方面导致的问题。而且Spring框架的IOC和AOP概念贯穿了整个Spring全家桶的产品,所以一定要深刻理解和练习,还有对于Java基础的提高,比如反射技术(对应于Spring中的AOP实现,事务的实现,自动配置类的加载,动态代理等等)都用到反射技术。