练习场景:在某个网页上有一些字段是我们感兴趣的,我们希望摘取出来,进行其他操作。但是这些字段可能在网页的不同地方。例如,我们需要在关于百度页面上摘取全部邮箱。

思路拆分:
1.首先,需要得到当前页面的source内容,例如,打开一个页面,右键-查看页面源代码。
2.找出规律,通过正则表达式去摘取匹配的字段,存储到一个字典或者列表。
3.循环打印字典或列表中内容,Python中用for语句实现。
技术角度实现相关方法:
1.查看页面的源代码,在Selenium中有drive.page_source 这个方法得到;
2.Python中利用正则,需要导读re模块;
3.for email in emails:
print email
一、具体代码:
from selenium import webdriver
import re
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(6)
driver.get("http://home.baidu.com/contact.html")
# 得到页面源代码
doc = driver.page_source
emails = re.findall(r'[w]+@[w.-]+',doc)
# 利用正则表达式,找出XXX@.XXX.XXX
for email in emails: # 循环打印匹配的邮箱
print(email)
解释:
在python正则表达式语法中,Python中字符串前面加上r表示原生字符串,用w表示匹配字母数字及下划线。re模块下findall方法返回的是一个匹配子字符串的列表。
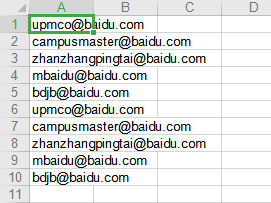
运行结果:

二、进阶版
from selenium import webdriver
import re,time,pprint,xlwt
wb = xlwt.Workbook()
ws = wb.add_sheet('E-mails')
driver = webdriver.Chrome()
driver.maximize_window()
time.sleep(2)
driver.get('https://www.baidu.com/')
driver.find_element_by_xpath("//*[@class='lh']/a[text()='关于百度']").click()
print(driver.current_window_handle)
handles = driver.window_handles
for handle in handles:
if handle != driver.current_window_handle:
driver.close()
print("马上切换到新页面", handle)
driver.switch_to.window(handle)
driver.find_element_by_xpath("//*[@id='indexAdmin']/div[1]/div/div/div/div[2]/ul/li[4]/a").click()
# /html/body/div[1]/div/div/div/div[2]/ul/li[4]/a
print(driver.current_window_handle)
handles = driver.window_handles
print(handles)
for handle in handles:
if handle!=driver.current_window_handle:
driver.close() # 关闭第一个窗口
print('马上切换到新标签页',handle)
driver.switch_to.window(handle) # 切换到第二个窗口
# 得到页面源代码
doc = driver.page_source
emiles = re.findall(r'[w]+@[w.-]+',doc)
for index,emile in enumerate(emiles):
ws.write(index,0,emile)
print(emile)
wb.save('百度联系邮箱.xls')
print('提取完成')
driver.close()
运行结果:
参考文章:https://blog.csdn.net/u011541946/article/details/68485981