LeNet是卷积网络做识别的开山之作,虽然这篇论文的网络结构现在已经很少使用,但是它对后续卷积网络的发展起到了奠基作用,打下了很好的理论基础,所以这篇文章中我们看的不只是结构,而是卷积网络设计的思想。
1. 设计思想
所谓卷积网络设计的思想,一共有三方面:
1)局部感受野(local receptive fields): 基于图像局部相关的原理,保留了图像局部结构,同时减少了网络的权值。
2)权值共享(shared weights): 也是基于图像局部相关的原理,同时减少网络的权值参数。
3)下采样(sub-sampling):对平移和形变更加鲁棒,实现特征的不变性,同时起到了一定的降维的作用。
从以上三方面我们可以看出,卷积网络的目的就是减小参数并适应不同尺度,它之所以能实现的依据就是图像的局部相关原则,图像的像素是有规则的顺序排列,这是所有方法能够起作用的前提。之前对所有像素进行全连接的方法,也是因为没有充分利用这一点。
2. 网络结构
LeNet的网络结构如下图所示
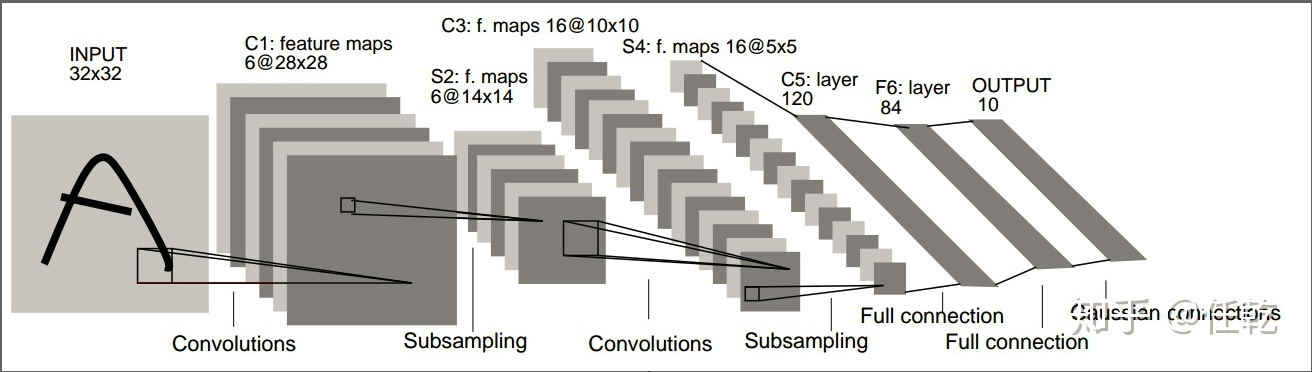
网络一共有5层,卷积1->池化1->卷积2->池化2->全连接。需要注意的是,此处的网络和后续的卷积网络不同的是,非线性激活函数只进行一次,并不是每次池化后面都跟一个。从下面这张图可以看出这一点:
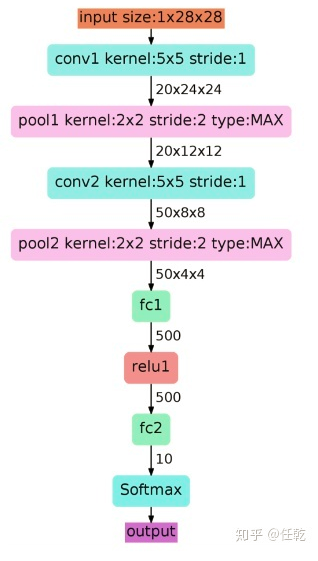
从理论上讲,非线性激活次数越多,网络的表达能力越强,此处之所以没有每个池化后面都加非线性激活,仍然能起到很好的效果,应该是因为这个手写数字识别的任务比较简单。
我们可以对每一层分别做一个分析:
1. 首先输入图像是单通道的28*28大小的图像,用矩阵表示就是[1,28,28]
2. 第一个卷积层conv1所用的卷积核尺寸为5*5,滑动步长为1,卷积核数目为20,那么经过该层后图像尺寸变为24,28-5+1=24,输出矩阵为[20,24,24]。
3. 第一个池化层pool核尺寸为2*2,步长2,这是没有重叠的max pooling
4. 池化操作后,图像尺寸减半,变为12×12,输出矩阵为[20,12,12]
5. 第二个卷积层conv2的卷积核尺寸为5*5,步长1,卷积核数目为50,卷积后图像尺寸变为8,这是因为12-5+1=8,输出矩阵为[50,8,8].
6. 第二个池化层pool2核尺寸为2*2,步长2,这是没有重叠的max pooling,池化操作后,图像尺寸减半,变为4×4,输出矩阵为[50,4,4]。
7. pool2后面接全连接层fc1,神经元数目为500,再接relu激活函数;
8. 再接fc2,神经元个数为10,得到10维的特征向量,用于10个数字的分类训练,送入softmaxt分类,得到分类结果的概率output。
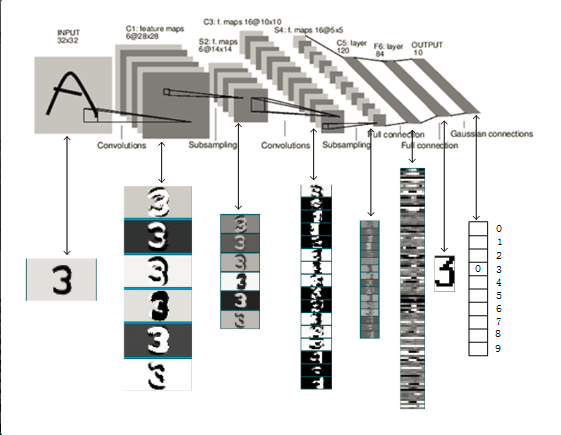
图1 LeNet-5识别数字3的过程。
三、总结
- LeNet-5是一种用于手写体字符识别的非常高效的卷积神经网络。
- 卷积神经网络能够很好的利用图像的结构信息。
- 卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定
四、pytorch的训练代码


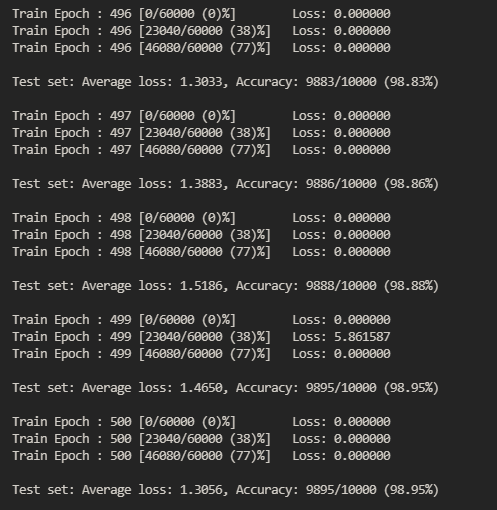
1 import gzip, struct 2 import math 3 import numpy as np 4 from torch.nn.modules.activation import SELU 5 from torch.nn.modules.batchnorm import BatchNorm2d 6 7 8 def _read(image, label): 9 minist_dir = './MNIST_data/' 10 11 # 使用gzip模块完成对文件的解压 12 with gzip.open(minist_dir+label) as flabel: 13 14 # struct提供用format specifier方式对数据进行打包和解包(Packing and Unpacking) 15 magic, num= struct.unpack(">II", flabel.read(8)) 16 label =np.fromstring(flabel.read(), dtype=np.int8) 17 18 with gzip.open(minist_dir+image, 'rb') as fimg: 19 20 magic, num, rows, cols = struct.unpack(">IIII", fimg.read(16)) 21 image = np.fromstring(fimg.read(), dtype=np.uint8).reshape(len(label), rows, cols) 22 23 return image, label 24 25 26 def get_data(): 27 28 train_img, train_label = _read( 29 'train-images-idx3-ubyte.gz', 30 'train-labels-idx1-ubyte.gz') 31 32 test_img,test_label = _read( 33 't10k-images-idx3-ubyte.gz', 34 't10k-labels-idx1-ubyte.gz') 35 36 return [train_img, train_label, test_img, test_label] 37 38 39 from torch import nn 40 from torch.nn import functional as F 41 from torch.autograd import Variable 42 43 import torch 44 45 class LeNet5(nn.Module): 46 47 def __init__(self): 48 super().__init__() 49 50 self.conv1 = nn.Conv2d(1, 6, 5,padding=2) 51 self.conv2 = nn.Conv2d(6, 16, 5) 52 self.fc1 = nn.Linear(16*5*5,120) 53 self.fc2 = nn.Linear(120, 84) 54 self.fc3 = nn.Linear(84, 10) 55 56 def forward(self, x): 57 x = F.max_pool2d(F.relu(self.conv1(x)),(2,2)) 58 x = F.max_pool2d( F.relu(self.conv2(x)),(2,2)) 59 x = x.view(-1, self.num_flat_features(x)) 60 x = F.relu(self.fc1(x)) 61 x = F.relu(self.fc2(x)) 62 x = self.fc3(x) 63 64 return x 65 66 67 def num_flat_features(self, x): 68 size = x.size()[1:] 69 num_features = 1 70 71 for s in size: 72 num_features*=s 73 74 return num_features 75 76 77 78 #使用pytorch封装的dataloader进行训练和预测 79 from torch.utils.data import TensorDataset,DataLoader, dataloader, dataset 80 from torchvision import transforms 81 82 83 def custom_normalization(data, std, mean): 84 return (data-mean)/std 85 86 use_gpu = torch.cuda.is_available() 87 88 batch_size = 256 89 90 kwargs = {'num_workers':2, 'pin_memory':True} if use_gpu else {} 91 92 X, y, Xt, yt = get_data() 93 94 95 # 主要进行标准化处理 96 # mean, std = X.mean(), X.std() 97 # X = custom_normalization(X, mean, std) 98 # Xt = custom_normalization(Xt, mean, std) 99 100 train_x, train_y = torch.from_numpy(X.reshape(-1, 1, 28, 28)).float(), torch.from_numpy(y.astype(int)) 101 test_x, test_y = [ 102 torch.from_numpy(Xt.reshape(-1,1,28,28)).float(), 103 torch.from_numpy(yt.astype(int)) 104 ] 105 106 train_dataset = TensorDataset(train_x, train_y) 107 test_dataset = TensorDataset(test_x, test_y) 108 109 train_loader = DataLoader(dataset=train_dataset, shuffle= True, batch_size=batch_size, **kwargs) 110 test_loader = DataLoader(dataset= test_dataset, shuffle = True, batch_size= batch_size, **kwargs) 111 112 model = LeNet5() 113 114 if use_gpu: 115 model = model.cuda() 116 print('USE GPU') 117 else: 118 print('USE CPU') 119 120 121 criterion = nn.CrossEntropyLoss(size_average=False) 122 # optimizer = torch.optim.SGD(model.parameters(), lr = 0.001) 123 optimizer = torch.optim.Adam(model.parameters(),lr=1e-3, betas=(0.9, 0.99)) 124 125 def weight_init(m): 126 127 # 使用isinstance来判断m属于什么类型 128 if isinstance(m, nn.Conv2d): 129 n = m.kernel_size[0]*m.kernel_size[1] * m.out_channels 130 m.weight.data.normal_(0, math.sqrt(2./n)) 131 132 elif isinstance(m, nn.BatchNorm2d): 133 # m中的weight,bias其实都是Variable,为了能学习参数以及后向传播 134 m.weight.data.fill_(1) 135 m.bias.data.zero_() 136 137 model.apply(weight_init) 138 139 def train(epoch): 140 141 model.train() 142 143 for batch_idx, (data, target) in enumerate(train_loader): 144 145 if use_gpu: 146 data, target = data.cuda(), target.cuda() 147 148 data, target = Variable(data), Variable(target) 149 optimizer.zero_grad() 150 151 output = model(data) 152 153 target = target.long() 154 loss = criterion(output, target) 155 156 loss.backward() 157 158 optimizer.step() 159 160 if batch_idx %90 ==0: 161 162 print('Train Epoch : {} [{}/{} ({:.0f})%]\tLoss: {:.6f}'.format( 163 epoch, batch_idx*len(data), len(train_loader.dataset), 164 100.*batch_idx/len(train_loader), loss.item())) 165 166 def test(): 167 model.eval() 168 test_loss = 0 169 correct = 0 170 for data, target in test_loader: 171 if use_gpu: 172 data, target = data.cuda(), target.cuda() 173 data, target = Variable(data, volatile=True), Variable(target) 174 output = model(data) 175 target1 = target.long() 176 test_loss += criterion(output, target1).item() # sum up batch loss 177 pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability 178 correct += pred.eq(target.data.view_as(pred)).cpu().sum() 179 180 test_loss /= len(test_loader.dataset) 181 print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n'.format( 182 test_loss, correct, len(test_loader.dataset), 183 100. * correct / len(test_loader.dataset))) 184 185 186 187 for epoch in range(1, 501): 188 train(epoch) 189 test()
参考:https://cuijiahua.com/blog/2018/01/dl_3.html
https://zhuanlan.zhihu.com/p/74176427
训练参考:https://www.cnblogs.com/wj-1314/p/11858502.html
https://github.com/sloth2012/LeNet5