导读:云原生时代的来临,与Java 开发者到底有什么联系?有人说,云原生压根不是为了 Java 存在的。然而,本文的作者却认为云原生时代,Java 依然可以胜任“巨人”的角色。作者希望通过一系列实验,开拓同学视野,提供有益思考。
在企业软件领域,Java 依然是绝对王者,但它让开发者既爱又恨。一方面因为其丰富的生态和完善的工具支持,可以极大提升了应用开发效率;但在运行时效率方面,Java 也背负着”内存吞噬者“,“CPU 撕裂者“的恶名,持续受到 NodeJS、Python、Golang 等新老语言的挑战。
在技术社区,我们经常看到有人在唱衰 Java 技术,认为其不再符合云原生计算发展的趋势。我们先抛开这些观点,首先思考一下云原生对应用运行时的不同需求。
- 体积更小 - 对于微服务分布式架构而言,更小的体积意味着更少的下载带宽,更快的分发下载速度。
- 启动速度更快 - 对于传统单体应用,启动速度与运行效率相比不是一个关键的指标。原因是,这些应用重启和发布频率相对较低。然而对于需要快速迭代、水平扩展的微服务应用而言,更快的的启动速度就意味着更高的交付效率,和更加快速的回滚。尤其当你需要发布一个有数百个副本的应用时,缓慢的启动速度就是时间杀手。对于Serverless 应用而言,端到端的冷启动速度则更为关键,即使底层容器技术可以实现百毫秒资源就绪,如果应用无法在500ms内完成启动,用户就会感知到访问延迟。
- 占用资源更少 - 运行时更低的资源占用,意味着更高的部署密度和更低的计算成本。同时,在JVM启动时需要消耗大量CPU资源对字节码进行编译,降低启动时资源消耗,可以减少资源争抢,更好保障其他应用SLA。
- 支持水平扩展 - JVM的内存管理方式导致其对大内存管理的相对低效,一般应用无法通过配置更大的heap size实现性能提升,很少有Java应用能够有效使用16G内存或者更高。另一方面,随着内存成本的下降和虚拟化的流行,大内存配比已经成为趋势。所以我们一般是采用水平扩展的方式,同时部署多个应用副本,在一个计算节点中可能运行一个应用的多个副本来提升资源利用率。
热身准备
熟悉Spring框架的开发者大多对 Spring Petclinic 不会陌生。本文将借助这个著名示例应用来演示如何让我们的Java应用变得更小,更快,更轻,更强大!
我们fork了IBM的Michael Thompson的示例,并做了一些调整。
$ git clone https://github.com/denverdino/adopt-openj9-spring-boot
$ cd adopt-openj9-spring-boot
首先,我们会为PetClinic应用构建一个Docker镜像。在Dockerfile中,我们利用OpenJDK作为基础镜像,安装Maven,下载、编译、打包Spring PetClinic应用,最后设置镜像的启动参数完成镜像构建。
$ cat Dockerfile.openjdk
FROM adoptopenjdk/openjdk8
RUN sed -i 's/archive.ubuntu.com/mirrors.aliyun.com/' /etc/apt/sources.list
RUN apt-get update
RUN apt-get install -y
git
maven
WORKDIR /tmp
RUN git clone https://github.com/spring-projects/spring-petclinic.git
WORKDIR /tmp/spring-petclinic
RUN mvn install
WORKDIR /tmp/spring-petclinic/target
CMD ["java","-jar","spring-petclinic-2.1.0.BUILD-SNAPSHOT.jar"]构建镜像并执行
$ docker build -t petclinic-openjdk-hotspot -f Dockerfile.openjdk .
$ docker run --name hotspot -p 8080:8080 --rm petclinic-openjdk-hotspot
| _,,,--,,_
/,`.-'`' ._ -;;,_
_______ __|,4- ) )_ .;.(__`'-'__ ___ __ _ ___ _______
| | '---''(_/._)-'(_\_) | | | | | | | | |
| _ | ___|_ _| | | | | |_| | | | __ _ _
| |_| | |___ | | | | | | | | | |
| ___| ___| | | | _| |___| | _ | | _|
| | | |___ | | | |_| | | | | | | |_ ) ) ) )
|___| |_______| |___| |_______|_______|___|_| |__|___|_______| / / / /
==================================================================/_/_/_/
...
2019-09-11 01:58:23.156 INFO 1 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path ''
2019-09-11 01:58:23.158 INFO 1 --- [ main] o.s.s.petclinic.PetClinicApplication : Started PetClinicApplication in 7.458 seconds (JVM running for 8.187)可以通过 http://localhost:8080/ 访问应用界面。
检查一下构建出的Docker镜像, ”petclinic-openjdk-openj9“ 的大小为871MB,而基础镜像 ”adoptopenjdk/openjdk8“ 仅有 300MB!这货也太膨胀了!
$ docker images petclinic-openjdk-hotspot
REPOSITORY TAG IMAGE ID CREATED SIZE
petclinic-openjdk-hotspot latest 469f73967d03 26 hours ago 871MB原因是:为了构建Spring应用,我们在镜像中引入了一系列编译时依赖,如 Git,Maven等,并产生了大量临时的文件。然而这些内容在运行时是不需要的。
在著名的软件12要素 第五条明确指出了,”Strictly separate build and run stages.“ 严格分离构建和运行阶段,不但可以帮助我们提升应用的可追溯性,保障应用交付的一致性,同时也可以减少应用分发的体积,减少安全风险。
镜像瘦身
Docker提供了Multi-stage Build(多阶段构建),可以实现镜像瘦身。
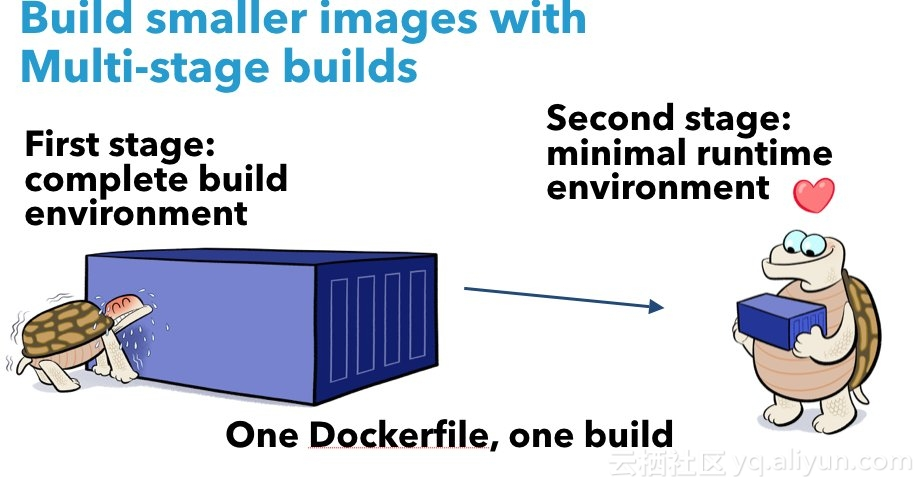
我们将镜像构建分成两个阶段:
- 在 ”build“ 阶段依然采用JDK作为基础镜像,并利用Maven进行应用构建;
- 在最终发布的镜像中,我们会采用JRE版本作为基础镜像,并从”build“ 镜像中直接拷贝出生成的jar文件。这意味着在最终发布的镜像中,只包含运行时所需必要内容,不包含任何编译时依赖,大大减少了镜像体积。
$ cat Dockerfile.openjdk-slim
FROM adoptopenjdk/openjdk8 AS build
RUN sed -i 's/archive.ubuntu.com/mirrors.aliyun.com/' /etc/apt/sources.list
RUN apt-get update
RUN apt-get install -y
git
maven
WORKDIR /tmp
RUN git clone https://github.com/spring-projects/spring-petclinic.git
WORKDIR /tmp/spring-petclinic
RUN mvn install
FROM adoptopenjdk/openjdk8:jre8u222-b10-alpine-jre
COPY --from=build /tmp/spring-petclinic/target/spring-petclinic-2.1.0.BUILD-SNAPSHOT.jar spring-petclinic-2.1.0.BUILD-SNAPSHOT.jar
CMD ["java","-jar","spring-petclinic-2.1.0.BUILD-SNAPSHOT.jar"]查看一下新镜像大小,从 871MB 减少到 167MB!
$ docker build -t petclinic-openjdk-hotspot-slim -f Dockerfile.openjdk-slim .
...
$ docker images petclinic-openjdk-hotspot-slim
REPOSITORY TAG IMAGE ID CREATED SIZE
petclinic-openjdk-hotspot-slim latest d1f1ca316ec0 26 hours ago 167MB镜像瘦身之后将大大加速应用分发速度,我们是否有办法优化应用的启动速度呢?
从 JIT 到 AOT - 启动提速
为了解决Java启动的性能瓶颈,我们首先需要理解JVM的实现原理。为了实现“一次编写,随处运行”的能力,Java程序会被编译成实现架构无关的字节码。JVM在运行时将字节码转换成本地机器码执行。这个转换过程决定了Java应用的启动和运行速度。为了提升执行效率,JVM引入了JIT compiler(Just in Time Compiler,即时编译器),其中Sun/Oracle公司的HotSpot是最著名JIT编译器实现。它提供了自适应优化器,可以动态分析、发现代码执行过程中的关键路径,并进行编译优化。HotSpot的出现极大提升了Java应用的执行效率,在Java 1.4以后成为了缺省的VM实现。但是HotSpot VM在启动时才对字节码进行编译,一方面导致启动时执行效率不高,一方面编译和优化需要很多的CPU资源,拖慢了启动速度。我们是否可以优化这个过程,提升启动速度呢?
熟悉Java江湖历史的同学应该会知道IBM J9 VM,它是用于IBM企业级软件产品的一款高性能的JVM,帮助IBM奠定了商业应用平台中间件的霸主地位。2017年9月,IBM 将 J9 捐献给 Eclipse 基金会,并更名 Eclipse OpenJ9,开启开源之旅。
OpenJ9 提供了Shared Class Cache (SCC 共享类缓存) 和 Ahead-of-Time (AOT 提前编译) 技术,显著减少了Java应用启动时间。
SCC 是一个内存映射文件,包含了J9 VM对字节码的执行分析信息和已经编译生成的本地代码。开启 AOT 编译后,会将JVM编译结果保存在 SCC 中,在后续 JVM 启动中可以直接重用。与启动时进行的 JIT 编译相比,从 SCC 加载预编译的实现要快得多,而且消耗的资源要更少。启动时间可以得到明显改善。
我们开始构建一个包含AOT优化的Docker应用镜像
$cat Dockerfile.openj9.warmed
FROM adoptopenjdk/openjdk8-openj9 AS build
RUN sed -i 's/archive.ubuntu.com/mirrors.aliyun.com/' /etc/apt/sources.list
RUN apt-get update
RUN apt-get install -y
git
maven
WORKDIR /tmp
RUN git clone https://github.com/spring-projects/spring-petclinic.git
WORKDIR /tmp/spring-petclinic
RUN mvn install
FROM adoptopenjdk/openjdk8-openj9:jre8u222-b10_openj9-0.15.1-alpine
COPY --from=build /tmp/spring-petclinic/target/spring-petclinic-2.1.0.BUILD-SNAPSHOT.jar spring-petclinic-2.1.0.BUILD-SNAPSHOT.jar
# Start and stop the JVM to pre-warm the class cache
RUN /bin/sh -c 'java -Xscmx50M -Xshareclasses -Xquickstart -jar spring-petclinic-2.1.0.BUILD-SNAPSHOT.jar &' ; sleep 20 ; ps aux | grep java | grep petclinic | awk '{print $1}' | xargs kill -1
CMD ["java","-Xscmx50M","-Xshareclasses","-Xquickstart", "-jar","spring-petclinic-2.1.0.BUILD-SNAPSHOT.jar"]其中 Java 参数 -Xshareclasses 开启SCC,-Xquickstart 开启AOT。
在Dockerfile中,我们运用了一个技巧来预热SCC。在构建过程中启动JVM加载应用,并开启SCC和AOT,在应用启动后停止JVM。这样就在Docker镜像中包含了生成的SCC文件。
然后,我们来构建Docker镜像并启动测试应用,
$ docker build -t petclinic-openjdk-openj9-warmed-slim -f Dockerfile.openj9.warmed-slim .
$ docker run --name hotspot -p 8080:8080 --rm petclinic-openjdk-openj9-warmed-slim
...
2019-09-11 03:35:20.192 INFO 1 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path ''
2019-09-11 03:35:20.193 INFO 1 --- [ main] o.s.s.petclinic.PetClinicApplication : Started PetClinicApplication in 3.691 seconds (JVM running for 3.952)
...可以看到,启动时间已经从之前的 8.2s 减少到 4s,提升近50%。
在这个方案中,我们一方面将耗时耗能的编译优化过程转移到构建时完成,一方面采用以空间换时间的方法,将预编译的SCC缓存保存到Docker镜像中。在容器启动时,JVM可以直接使用内存映射文件来加载SCC,优化了启动速度和资源占用。
这个方法另外一个优势是:由于Docker镜像采用分层存储,同一个宿主机上的多个Docker应用实例会共享同一份SCC内存映射,可以大大减少在单机高密度部署时的内存消耗。
下面我们做一下资源消耗的比较,我们首先利用基于HotSpot VM的镜像,同时启动4个Docker应用实例,30s后利用docker stats查看资源消耗
$ ./run-hotspot-4.sh
...
Wait a while ...
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
0fa58df1a291 instance4 0.15% 597.1MiB / 5.811GiB 10.03% 726B / 0B 0B / 0B 33
48f021d728bb instance3 0.13% 648.6MiB / 5.811GiB 10.90% 726B / 0B 0B / 0B 33
a3abb10078ef instance2 0.26% 549MiB / 5.811GiB 9.23% 726B / 0B 0B / 0B 33
6a65cb1e0fe5 instance1 0.15% 641.6MiB / 5.811GiB 10.78% 906B / 0B 0B / 0B 33
...然后使用基于OpenJ9 VM的镜像,同时启动4个Docker应用实例,并查看资源消耗
$ ./run-openj9-warmed-4.sh
...
Wait a while ...
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
3a0ba6103425 instance4 0.09% 119.5MiB / 5.811GiB 2.01% 1.19kB / 0B 0B / 446MB 39
c07ca769c3e7 instance3 0.19% 119.7MiB / 5.811GiB 2.01% 1.19kB / 0B 16.4kB / 120MB 39
0c19b0cf9fc2 instance2 0.15% 112.1MiB / 5.811GiB 1.88% 1.2kB / 0B 22.8MB / 23.8MB 39
95a9c4dec3d6 instance1 0.15% 108.6MiB / 5.811GiB 1.83% 1.45kB / 0B 102MB / 414MB 39
...与HotSpot VM相比,OpenJ9的场景下应用内存占用从平均 600MB 下降到 120MB。惊喜不惊喜?
通常而言,HotSpot JIT比AOT可以进行更加全面和深入的执行路径优化,从而有更高的运行效率。为了解决这个矛盾,OpenJ9 的AOT SCC只在启动阶段生效,在后续运行中会继续利用JIT进行分支预测、代码内联等深度编译优化。
更多关于 OpenJ9 SCC和AOT的技术介绍,请参考
- https://www.ibm.com/developerworks/cn/java/j-class-sharing-openj9/index.html
- https://www.ibm.com/developerworks/cn/java/j-optimize-jvm-startup-with-eclipse-openjj9/index.html
- HotSpot在Class Data Sharing (CDS)和AOT方面也有了很大进展,但是IBM J9在这方面更加成熟。期待阿里的Dragonwell也提供相应的优化支持。
思考:与C/C++,Golang, Rust等静态编译语言不同,Java采用VM方式运行,提升了应用可移植性的同时牺牲了部分性能。我们是否可以将AOT做到极致?完全移除字节码到本地代码的编译过程?
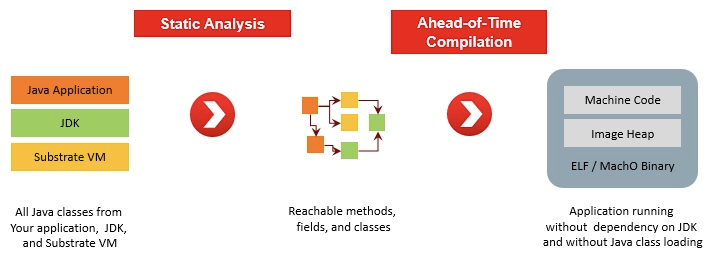
原生代码编译
为了将Java应用编译成本地可执行代码,我们首先要解决JVM和应用框架在运行时的动态性挑战。JVM提供了灵活的类加载机制,Spring的依赖注入(DI,Dependency-injection)可以实现运行时动态类加载和绑定。在Spring框架中,反射,Annotation 运行时处理器等技术也被广泛应用。这些动态性一方面提升了应用架构的灵活性和易用性,另一方面也降低了应用的启动速度,使得AOT原生编译和优化变得非常复杂。
为了解决这些挑战,社区有很多有趣的探索,Micronaut 是其中一个优秀代表。与Spring框架序不同,Micronaut提供了编译时的依赖注入和AOP处理能力,并最小化反射和动态代理的使用。Micronaut 应用有着更快的启动速度和更低的内存占用。更加让我们更感兴趣的是Micronaut支持与Graal VM配合,可以将Java应用编译成为本地执行代码全速运行。注:GraalVM是Oracle推出的一种新型通用虚拟机,支持多种语言,可以将Java应用程序编译为本地原生应用。
下面开始我们的探险,我们利用Mitz提供的Micronaut版本PetClinic示例工程并做了一点点调整。(使用Graal VM 19.2)
$ git clone https://github.com/denverdino/micronaut-petclinic
$ cd micronaut-petclinic其中Docker镜像的内容如下
$ cat Dockerfile
FROM maven:3.6.1-jdk-8 as build
COPY ./ /micronaut-petclinic/
WORKDIR /micronaut-petclinic
RUN mvn package
FROM oracle/graalvm-ce:19.2.0 as graalvm
RUN gu install native-image
WORKDIR /work
COPY --from=build /micronaut-petclinic/target/micronaut-petclinic-*.jar .
RUN native-image --no-server -cp micronaut-petclinic-*.jar
FROM frolvlad/alpine-glibc
EXPOSE 8080
WORKDIR /app
COPY --from=graalvm /work/petclinic .
CMD ["/app/petclinic"]其中
- 在 "build" 阶段,利用Maven构建 Micronaut 版本的 PetClinic 应用,
- 在 "graalvm" 阶段,我们通过
native-image将PetClinic jar文件转化成可执行文件。 - 在最终阶段,将本地可执行文件加入一个Alpine Linux基础镜像
构建应用
$ docker-compose build启动测试数据库
$ docker-compose up db启动测试应用
$ docker-compose up app
micronaut-petclinic_db_1 is up-to-date
Starting micronaut-petclinic_app_1 ... done
Attaching to micronaut-petclinic_app_1
app_1 | 04:57:47.571 [main] INFO org.hibernate.dialect.Dialect - HHH000400: Using dialect: org.hibernate.dialect.PostgreSQL95Dialect
app_1 | 04:57:47.649 [main] INFO org.hibernate.type.BasicTypeRegistry - HHH000270: Type registration [java.util.UUID] overrides previous : org.hibernate.type.UUIDBinaryType@5f4e0f0
app_1 | 04:57:47.653 [main] INFO o.h.tuple.entity.EntityMetamodel - HHH000157: Lazy property fetching available for: com.example.micronaut.petclinic.owner.Owner
app_1 | 04:57:47.656 [main] INFO o.h.e.t.j.p.i.JtaPlatformInitiator - HHH000490: Using JtaPlatform implementation: [org.hibernate.engine.transaction.jta.platform.internal.NoJtaPlatform]
app_1 | 04:57:47.672 [main] INFO io.micronaut.runtime.Micronaut - Startup completed in 159ms. Server Running: http://1285c42bfcd5:8080应用启动速度如闪电般提升至 159ms,仅有HotSpot VM的1/50!
Micronaut和Graal VM还在快速发展中,迁移一个Spring应用还有不少工作需要考虑。此外Graal VM的调试、监控等工具链还不够完善。但是这已经让我们看到了曙光,Java应用和Serverless的世界不再遥远。由于篇幅有限,对Graal VM和Micronaut有兴趣的同学可以参考
- https://docs.micronaut.io/latest/guide/index.html#graal
- https://www.exoscale.com/syslog/how-to-integrate-spring-with-micronaut/
总结与后记
作为进击的巨人,Java技术在云原生时代也在不停地进化。在JDK 8u191和JDK 10之后,JVM增强了在Docker容器中对资源的感知。同时社区也在多个不同方向探索Java技术栈的边界。JVM OpenJ9作为传统VM的一员,在对现有Java应用保持高度兼容的同时,对启动速度和内存占用做了细致的优化,比较适于与现有Spring等微服务架构配合使用。而Micronaut/Graal VM则另辟蹊径,通过改变编程模型和编译过程,将应用的动态性尽可能提前到编译时期处理,极大优化了应用启动时间,在Serverless领域前景可期。这些设计思路都值得我们借鉴。
在云原生时代,我们要能够在横向的应用开发生命周期中,将开发、交付、运维过程进行有效的分割和重组,提升研发协同效率;并且要能在整个纵向软件技术栈中,在编程模型、应用运行时和基础设施等多层面进行系统优化,实现radical simplification,提升系统效率。
本文完成于在参加阿里集团20周年的火车旅途上,9/10阿里年会是非常难忘的经历。感谢马老师,感谢阿里,感谢这个时代,感谢所有帮助和支持我们的小伙伴,感谢所有追梦的技术人,我们一起开拓云原生的未来。
本文作者:易立
本文为云栖社区原创内容,未经允许不得转载。