之前学习得是如何进行网络请求,现在开始学习如何进行数据提取
一、选取节点:
在火狐浏览器中,首先要有一个try xpath插件,
例如要找网页中所有得div,就在插件中搜索
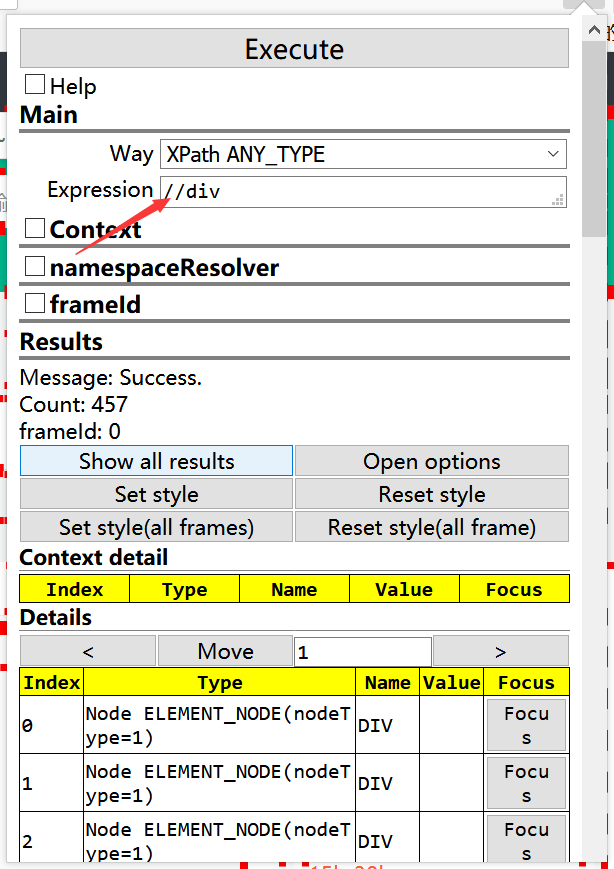
就会把所有的div圈出来:
1、/ 就是在根节点下查找元素(直接子元素) 例如:

根节点下没有div,所以数量为0.div为子孙节点,html为子节点,body为html的子节点

2、// :查找所有的子孙节点
3、@ :选取某个节点的属性,例如div下的id属性,选择拥有id的所有div节点:
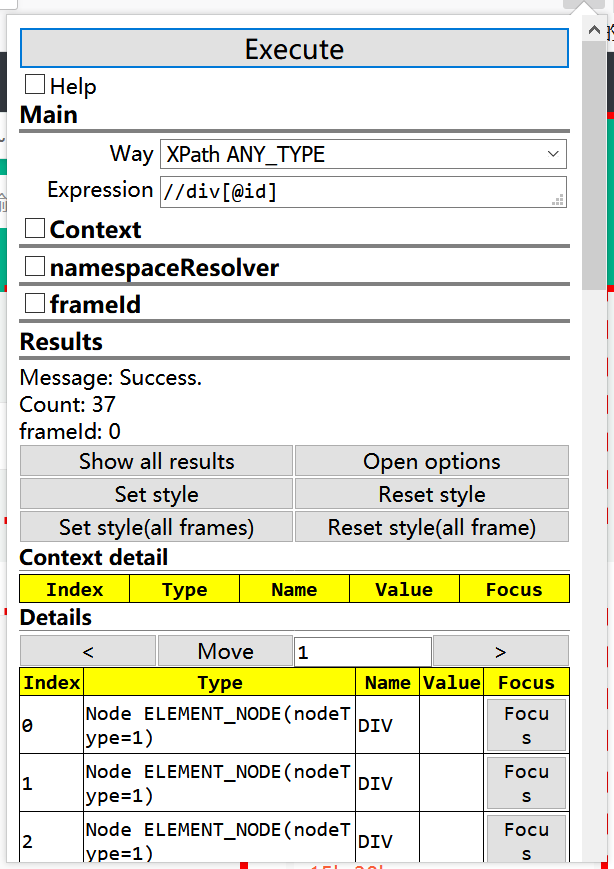
二、谓语:就是中括号里面的内容,作用是过滤掉一些节点
1、例如:要获取网页中的第一个Div元素
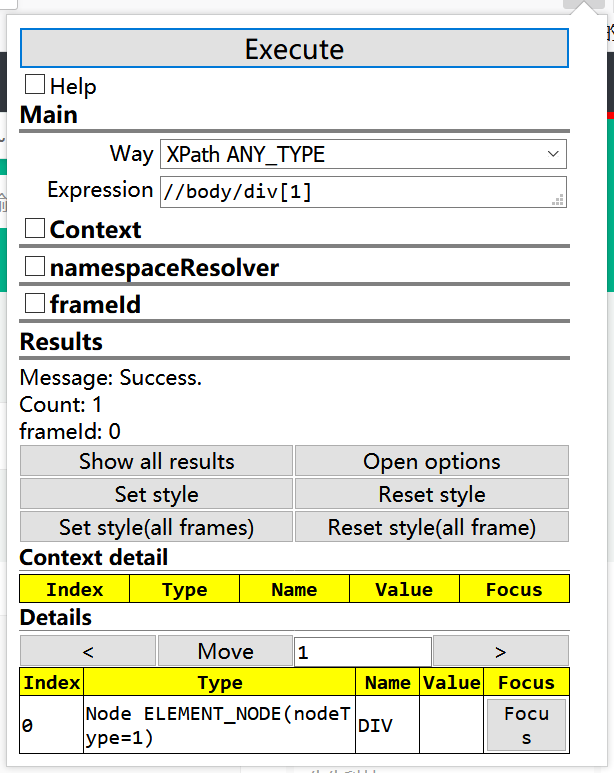

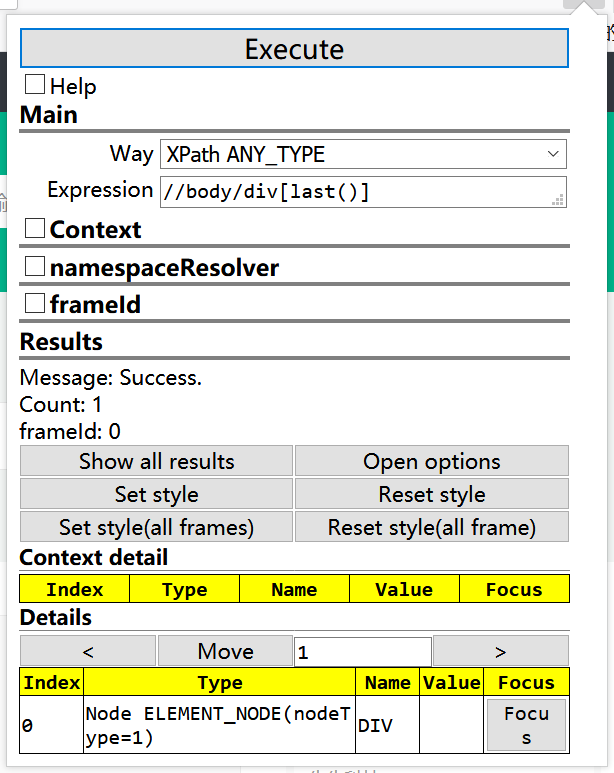
2、获得最后一个div元素
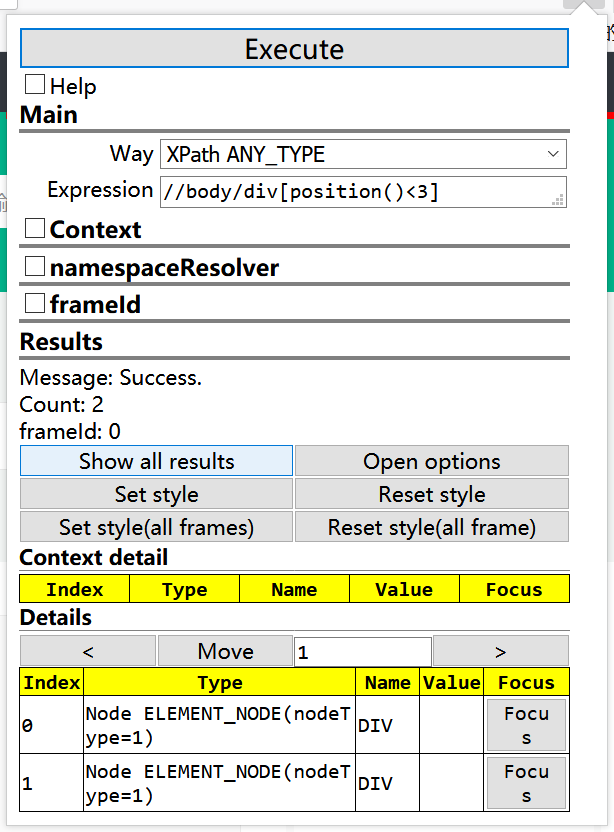
3、获取前两个div元素
4、获取id等于serverTime的input元素

5、模糊匹配

就是找到class等于的值中有fl的div
三、通配符
1、 * :查看节点下所有的元素个数
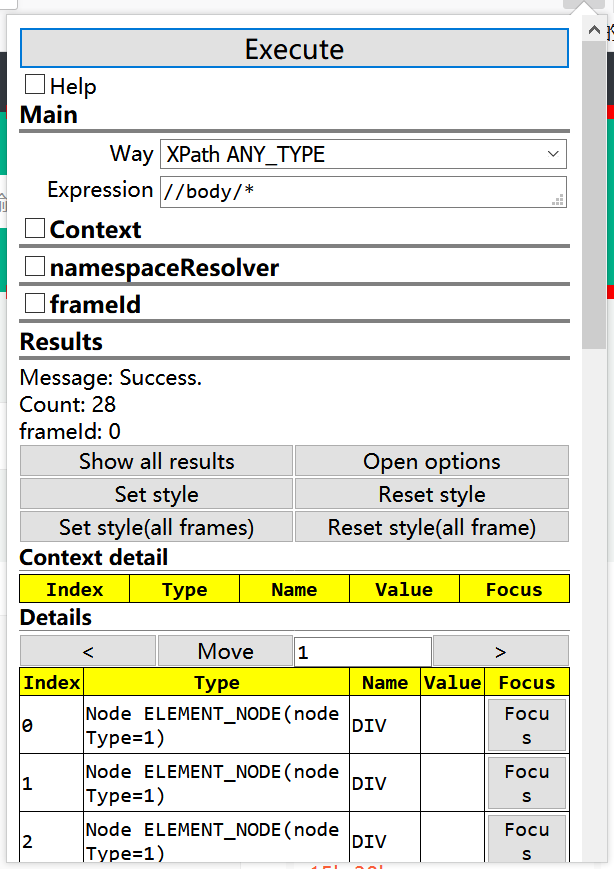
2、@* :查看拥有属性的div元素

四、选取多个路径
//dd[@class="job_bt"]||//dd[@class="job-adwantage"]