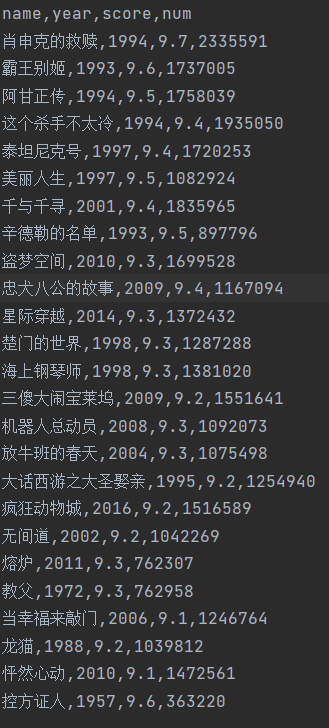
re练习⼿刃⾖瓣TOP250电影信息
import requests headers = { "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36" } url = "https://movie.douban.com/top250? start=0&filter=" resp = requests.get(url, headers=headers) print(resp.text) obj = re.compile(r'<li>.*?<div class="item">.*? <div class="pic">.*?<em class="">(?P<num>d+) </em>' r'.*?<span class="title">(? P<name>.*?)</span>' r'.*?<p class="">.*?<br> (? P<year>.*?) ' r'.*?property="v:average">(? P<average>.*?)</span>' r'.*?<span>(?P<people>d+)⼈评价 </span>', re.S) it = obj.finditer(resp.text) with open("movie.csv", mode="w", encoding="utf-8") as f: csvwriter = csv.writer(f) # 创建csv⽂件写⼊⼯具, 也可以直接f.write() for item in it: dic = item.groupdict() dic['year'] = dic['year'].strip() csvwriter.writerow(dic.values()) # 写⼊数据