本文开源学习地址见Github:https://github.com/datawhalechina/team-learning
赛事回顾
智慧海洋的竞赛介绍
原竞赛地址
https://tianchi.aliyun.com/competition/entrance/231768/information
本赛题基于船舶轨迹位置数据对海上目标进行智能识别和作业行为分析,要求选手通过分析渔船北斗设备位置数据,得出该船的生产作业行为,具体判断出是
- 拖网作业 (拖曳渔具在海底或海水中前进,对鱼类进行捕捞的作业方式。)
- 围网作业 (使用网具包围鱼群进行捕捞的作业方式)
- 流刺网作业 (将长带形的网列敷设于水域中,使鱼刺入网目或被网衣缠络后加以捕捞)
同时,希望选手通过数据可视分析,挖掘更多海洋通信导航设备的应用价值。
开源方案分享
比赛开源方案
-
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12586969.1002.3.163c24d1HiGiFo&postId=110644 (有源码,OTTO队伍)
-
https://tianchi.aliyun.com/forum/postDetail?postId=110932 (有源码,liu123的航空母舰)
-
https://tianchi.aliyun.com/forum/postDetail?postId=110928 (有源码,天才海神号)
-
https://tianchi.aliyun.com/forum/postDetail?postId=110710 (有源码,大白)
-
https://tianchi.aliyun.com/forum/postDetail?postId=108332 (有源码,初赛排名7,复赛排名12)
-
https://tianchi.aliyun.com/notebook-ai/detail?postId=114808 (有源码,蜗牛车,rank11)
-
https://tianchi.aliyun.com/forum/postDetail?postId=112041 (鱼佬)
-
https://tianchi.aliyun.com/forum/postDetail?postId=110943 (有源码,rank9)
Task1 地理数据分析常用工具
学习目标
1.了解和学习shapely和geopandas的基本功能,掌握用python中的这两个库实现几何对象之间的空间操作方法。
2.掌握folium和kepler.gl的数据可视化工具的使用。
3.学习与掌握geohash编码方法。
内容介绍
- shapely https://shapely.readthedocs.io/en/stable/project.html (python中开源的空间几何对象库,支持点线面等几何对象以及相关空间操作)
- 空间数据模型
- 几何对象的一些功能特性
- Point
- LineString
- LineRing
- Polygon
- 几何对象之间的关系
- geopandas
- Folium
- Kepler.gl
- GeoHash
- 注意事项
Shapely介绍
Shapely是python中开源的空间几何对象库,支持Point、Curve(曲线)和Surface等基本几何对象类型以及相关空间操作。另外,几何对象类型的特征分别有interior(内交)、boundary(相交)和exterior(外交)。
空间数据模型
- point类型对应的方法在Point类中。curve类型对应的方法在LineString和LinearRing类中。surface类型对应的方法在Polygon类中。
- point集合对应的方法在MultiPoint类中,curves集合对应的反方在MultiLineString类中,surface集合对应的方法在MultiPolygon类中。
几何对象的一些功能特性
Point、LineString和LinearRing有一些功能非常有用。
- 几何对象可以和numpy.array互相转换。
- 可以求线的长度(length),面的面积(area),对象之间的距离(distance),最小最大距离(hausdorff_distance),对象的bounds数组(minx, miny, maxx, maxy)
- 可以求几何对象之间的关系:相交(intersect),包含(contain),求相交区域(intersection)等。
- 可以对几何对象求几何中心(centroid),缓冲区(buffer),最小旋转外接矩形(minimum_rotated_rectangle)等。
- 可以求线的插值点(interpolate),可以求点投影到线的距离(project),可以求几何对象之间对应的最近点(nearestPoint)
- 可以对几何对象进行旋转(rotate)和缩放(scale)
from shapely import geometry as geo
from shapely import wkt
from shapely import ops
import numpy as np
点 Point (class Point)
# point有三种复制方式,具体如下:
point = geo.Point(0.5, 0.5)
point_2 = geo.Point((0,0))
point_3 = geo.Point(point)
# 其坐标可以通过coords或x,y,z得到
print(list(point_3.coords))
print(point_3.x)
print(point_3.y)
#批量进行可视化
geo.GeometryCollection([point,point_2])
#可以和np.array进行互相转换
print(np.array(point))
[(0.5, 0.5)]
0.5
0.5
[0.5 0.5]
LineString (线段组的操作)
class LineString(coordinates)
LineStrings构造函数传入参数是2个或多个点元组
#代码示例
arr=np.array([(0,0), (1,1), (1,0)])
line = geo.LineString(arr)
line

# 该方法即可求线线距离也可以求线点距离
print ('两个几何对象之间的距离:'+str(geo.Point(2,2).distance(line)))
# 该方法求得是点与线的最长距离
print ('两个几何对象之间的hausdorff_distance距离:'+str(geo.Point(2,2).hausdorff_distance(line)))
print('该几何对象的面积:'+str(line.area))
print('该几何对象的坐标范围:'+str(line.bounds))
print('该几何对象的长度:'+str(line.length))
print('该几何对象的几何类型:'+str(line.geom_type))
print('该几何对象的坐标系:'+str(list(line.coords)))
center = line.centroid #几何中心
geo.GeometryCollection([line,center])
print(center)
两个几何对象之间的距离:1.4142135623730951
两个几何对象之间的hausdorff_distance距离:2.8284271247461903
该几何对象的面积:0.0
该几何对象的坐标范围:(0.0, 0.0, 1.0, 1.0)
该几何对象的长度:2.414213562373095
该几何对象的几何类型:LineString
该几何对象的坐标系:[(0.0, 0.0), (1.0, 1.0), (1.0, 0.0)]
POINT (0.7071067811865476 0.5)
#envelope可以求几何对象的最小外接矩形
bbox = line.envelope #envelope可以求几何对象的最小外接矩形
geo.GeometryCollection([line,bbox])

#最小旋转外接矩形
rect = line.minimum_rotated_rectangle #最小旋转外接矩形
geo.GeometryCollection([line,rect])

#插值
pt_half = line.interpolate(0.5,normalized=True)
geo.GeometryCollection([line,pt_half])

# project()方法是和interpolate方法互逆的
ratio = line.project(pt_half,normalized=True)
print(ratio)
0.5
DouglasPucker算法
下面这个是DouglasPucker算法的应用,在轨迹分析中经常会用得到
# 返回由Douglas-Peucker算法产生的简化几何
line1 = geo.LineString([(0,0),(1,-0.2),(2,0.3),(3,-0.5),(5,0.2),(7,0)])
line1_simplify = line1.simplify(0.4, preserve_topology=False) #Douglas-Pucker算法
print(line1)
print(line1_simplify)
LINESTRING (0 0, 1 -0.2, 2 0.3, 3 -0.5, 5 0.2, 7 0)
LINESTRING (0 0, 2 0.3, 3 -0.5, 5 0.2, 7 0)
# 端点按照半圆扩展
buffer_with_circle = line1.buffer(0.2)
geo.GeometryCollection([line1,buffer_with_circle])

LinearRing (线段环的操作)
class LinearRing(coordinates)
LinearRing构造函数传入参数是2个或多个点元组
元组序列可以通过在第一个和最后一个索引中传递相同的值来显式关闭。否则,将第一个元组复制到最后一个索引,从而隐式关闭序列。
与LineString一样,元组序列中的重复点是允许的,但可能会导致性能上的损失,应该避免在序列中设置重复点。
from shapely.geometry.polygon import LinearRing
ring = geo.polygon.LinearRing([(0,0), (1,1), (1,0)])
#相比于刚才的LineString的代码示例,其长度现在是3.41,是因为其序列是闭合的
print(ring.length)
print(ring.area)
# 构建geo的几何集合
geo.GeometryCollection([ring])
3.414213562373095
0.0

Polygon
class Polygon(shell[, holes=None])
Polygon接受两个位置参数,第一个位置参数是和LinearRing一样,是一个有序的point元组。第二个位置参数是可选的序列,其用来指定内部的边界.
from shapely.geometry import Polygon
polygon1 = Polygon([(0, 0), (1, 1), (1, 0)])
exter = [(0, 0), (0, 2), (2, 2), (2, 0), (0, 0)]
inter = [(1, 0), (0.5, 0.5), (1, 1), (1.5, 0.5), (1, 0)]
polygon2 = Polygon(exter, [inter])
print(polygon1.area)
print(polygon1.length)
print(polygon2.area)#其面积是ext的面积减去int的面积
print(polygon2.length)#其长度是ext的长度加上int的长度
print(np.array(polygon2.exterior)) #外围坐标点
geo.GeometryCollection([polygon2])
0.5
3.414213562373095
3.5
10.82842712474619
[[0. 0.]
[0. 2.]
[2. 2.]
[2. 0.]
[0. 0.]]

MultiPoint、MultiLineString、MultiPolygon
与之前介绍的类似,MultiPoint、MultiLineString、MultiPolygon分别指的是多个点、多个linestring和多个polygon形成的集合。
几何对象关系
一个几何对象特征分别有interior、boundary和exterior。下面的叙述直接用内部、边界和外部等名词概述
简要API
- object.contains(other)
如果object的外部没有其他点,或者至少有一个点在该object的内部,则返回True
a. contains(b)与 b.within(a)的表达是等价的
from shapely.geometry import LineString,Point
coords = [(0, 0), (1, 1)]
print(LineString(coords).contains(Point(0.5, 0.5)))#线与点的关系
print(LineString(coords).contains(Point(1.0, 1.0)))#因为line的边界不是属于在该对象的内部,所以返回是False
True
False
polygon1 = Polygon( [(0, 0), (0, 2), (2, 2), (2, 0), (0, 0)])
print(polygon1.contains(Point(1.0, 1.0)))#面与点的关系
#同理这个contains方法也可以扩展到面与线的关系以及面与面的关系
geo.GeometryCollection([polygon1,Point(1.0, 1.0)])
True

- object.crosses(other)
如果一个object与另一个object是内部相交的关系而不是包含的关系,则返回True - object.disjoint(other)
如果该对象与另一个对象的内部和边界都不相交则返回True - object.intersects(other)
如果该几何对象与另一个几何对象只要相交则返回True。 - object.convex_hull
返回包含对象中所有点的最小凸多边形(凸包, 舍去内部可能被包含的点) - difference 计算差集
- union 返回对象与对象之间的并集
- object.intersection 返回对象与对象之间的交集
6.与numpy和python数组之间的关系
point、LineRing和LineString提供numpy数组接口,可以进行转换numpy数组
from shapely.geometry import asPoint,asLineString,asMultiPoint,asPolygon
import numpy as np
pa = asPoint(np.array([0.0, 0.0]))#将numpy数组转换成point格式
la = asLineString(np.array([[1.0, 2.0], [3.0, 4.0]]))#将numpy数组转换成LineString格式
ma = asMultiPoint(np.array([[1.1, 2.2], [3.3, 4.4], [5.5, 6.6]]))#将numpy数组转换成multipoint集合
pg = asPolygon(np.array([[1.1, 2.2], [3.3, 4.4], [5.5, 6.6]]))#将numpy数组转换成polygon
print(type(pa), np.array(pa))#将Point转换成numpy格式
<class 'shapely.geometry.point.PointAdapter'> [0. 0.]
其他api
另外还有一些非常有用但是不属于某个类方法的函数,如有需要可以在官网查阅
- ops.nearest_points 求最近点
- ops.split 分割线
- ops.substring 求子串
- affinity.rotate 旋转几何体
- affinity.scale 缩放几何体
- affinity.translate 平移几何体
geopandas的简介 (几何版本的pandas)
GeoPandas提供了地理空间数据的高级接口,它让使用python处理地理空间数据变得更容易。
GeoPandas扩展了pandas,GeoPandas的目标是使使用python处理地理空间数据更容易。它结合了熊猫和shape的功能,提供了熊猫的地理空间操作和shape的多个几何图形的高级接口。GeoPandas使您能够轻松地在python中进行操作,否则将需要空间数据库(如PostGIS)。
使用的数据类型,允许对几何类型进行空间操作。几何运算由shapely执行。Geopandas进一步依赖fiona进行文件访问,依赖matplotlib进行绘图。
geopandas和pandas一样,一共有两种数据类型:
- GeoSeries
- GeoDataFrame
它们继承了pandas数据结构的大部分方法。这两个数据结构可以当做地理空间数据的存储器,shapefile文件的pandas呈现。
Shapefile文件用于描述几何体对象:点,折线与多边形。例如,Shapefile文件可以存储井、河流、湖泊等空间对象的几何位置。除了几何位置,shp文件也可以存储这些空间对象的属性,例如一条河流的名字,一个城市的温度等等。
示例绘制世界地图
例如,当安装geopandas库后,便可通过matplotlib直接画出当安装geopandas数据集中的世界地图
import pandas as pd
import geopandas
import matplotlib.pyplot as plt
world = geopandas.read_file(geopandas.datasets.get_path('naturalearth_lowres'))#read_file方法可以读取shape文件,转化为GeoSeries和GeoDataFrame数据类型。
world.plot()#将GeoDataFrame变成图形展示出来,得到世界地图
plt.show()

world.head(2)
| pop_est | continent | name | iso_a3 | gdp_md_est | geometry | |
|---|---|---|---|---|---|---|
| 0 | 920938 | Oceania | Fiji | FJI | 8374.0 | MULTIPOLYGON (((180.00000 -16.06713, 180.00000... |
| 1 | 53950935 | Africa | Tanzania | TZA | 150600.0 | POLYGON ((33.90371 -0.95000, 34.07262 -1.05982... |
由以上geodataframe的实例world可知,其最后一列是geometry。其几何对象包括了MULTIPOLYGON 、POLYGON,那么便同样可以用刚才介绍的shapely库进行分析。
具体的geopadandas常用的方法可以参考这篇文章
geopdandas的相关中文案例和分析可参考这个集锦,了解一下具体使用情况
Folium 绘制高频可视化场景
folium可以满足我们平时常用的热力图、填充地图、路径图、散点标记等高频可视化场景.folium也可以通过flask让地图和我们的数据在网页上显示,极其便利。
folium的其他使用可以参考知乎的这篇文章,较为全面。
https://www.zhihu.com/question/33783546
Kepler.gl (图形化的数据可视化工具)
Kepler.gl与folium类似,也是是一个图形化的数据可视化工具,基于Uber的大数据可视化开源项目deck.gl创建的demo app。目前支持3种数据格式:CSV、JSON、GeoJSON。
Kepler.gl官网提供了可视化图形案例,分别是Arc(弧)、Line(线)、Hexagon(六边形)、Point(点)、Heatmap(等高线图)、GeoJSON、Buildings(建筑)。
下面用本赛题的数据进行简单的数据处理和基本的kepler.gl的使用
import pandas as pd
import geopandas as gpd
from pyproj import Proj
from keplergl import KeplerGl
from tqdm import tqdm
import os
import matplotlib.pyplot as plt
import shapely
import numpy as np
from datetime import datetime
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] = ['SimSun'] # 指定默认字体为新宋体。
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像时 负号'-' 显示为方块和报错的问题。
1. 获取文件夹中的数据
def get_data(file_path,model):
assert model in ['train', 'test'], '{} Not Support this type of file'.format(model)
paths = os.listdir(file_path)
# print(len(paths))
tmp = []
for t in tqdm(range(len(paths))):
p = paths[t]
with open('{}/{}'.format(file_path, p), encoding='utf-8') as f:
next(f)
for line in f.readlines():
tmp.append(line.strip().split(','))
tmp_df = pd.DataFrame(tmp)
if model == 'train':
tmp_df.columns = ['ID', 'lat', 'lon', 'speed', 'direction', 'time', 'type']
else:
tmp_df['type'] = 'unknown'
tmp_df.columns = ['ID', 'lat', 'lon', 'speed', 'direction', 'time', 'type']
tmp_df['lat'] = tmp_df['lat'].astype(float)
tmp_df['lon'] = tmp_df['lon'].astype(float)
tmp_df['speed'] = tmp_df['speed'].astype(float)
tmp_df['direction'] = tmp_df['direction'].astype(int)#如果该行代码运行失败,请尝试更新pandas的版本
return tmp_df
2.平面坐标转经纬度,供初赛数据使用
选择标准为NAD83 / California zone 6 (ftUS) (EPSG:2230),查询链接:https://mygeodata.cloud/cs2cs/
def transform_xy2lonlat(df):
x = df['lat'].values
y = df['lon'].values
p=Proj('+proj=lcc +lat_1=33.88333333333333 +lat_2=32.78333333333333 +lat_0=32.16666666666666 +lon_0=-116.25 +x_0=2000000.0001016 +y_0=500000.0001016001 +datum=NAD83 +units=us-ft +no_defs ')
df['lon'], df['lat'] = p(y, x, inverse=True)
return df
#修改数据的时间格式
def reformat_strtime(time_str=None, START_YEAR="2019"):
"""Reformat the strtime with the form '08 14' to 'START_YEAR-08-14' """
time_str_split = time_str.split(" ")
time_str_reformat = START_YEAR + "-" + time_str_split[0][:2] + "-" + time_str_split[0][2:4]
time_str_reformat = time_str_reformat + " " + time_str_split[1]
# time_reformat=datetime.strptime(time_str_reformat,'%Y-%m-%d %H:%M:%S')
return time_str_reformat
#计算两个点的距离
def haversine_np(lon1, lat1, lon2, lat2):
lon1, lat1, lon2, lat2 = map(np.radians, [lon1, lat1, lon2, lat2])
dlon = lon2 - lon1
dlat = lat2 - lat1
a = np.sin(dlat/2.0)**2 + np.cos(lat1) * np.cos(lat2) * np.sin(dlon/2.0)**2
c = 2 * np.arcsin(np.sqrt(a))
km = 6367 * c
return km * 1000
def compute_traj_diff_time_distance(traj=None):
"""Compute the sampling time and the coordinate distance."""
# 计算时间的差值
time_diff_array = (traj["time"].iloc[1:].reset_index(drop=True) - traj[
"time"].iloc[:-1].reset_index(drop=True)).dt.total_seconds() / 60
# 计算坐标之间的距离
dist_diff_array = haversine_np(traj["lon"].values[1:], # lon_0
traj["lat"].values[1:], # lat_0
traj["lon"].values[:-1], # lon_1
traj["lat"].values[:-1] # lat_1
)
# 填充第一个值
time_diff_array = [time_diff_array.mean()] + time_diff_array.tolist()
dist_diff_array = [dist_diff_array.mean()] + dist_diff_array.tolist()
traj.loc[list(traj.index),'time_array'] = time_diff_array
traj.loc[list(traj.index),'dist_array'] = dist_diff_array
return traj
对轨迹进行异常点的剔除
#对轨迹进行异常点的剔除
def assign_traj_anomaly_points_nan(traj=None, speed_maximum=23,
time_interval_maximum=200,
coord_speed_maximum=700):
"""Assign the anomaly points in traj to np.nan."""
def thigma_data(data_y,n):
data_x =[i for i in range(len(data_y))]
ymean = np.mean(data_y)
ystd = np.std(data_y)
threshold1 = ymean - n * ystd
threshold2 = ymean + n * ystd
judge=[]
for data in data_y:
if (data < threshold1)|(data> threshold2):
judge.append(True)
else:
judge.append(False)
return judge
# Step 1: The speed anomaly repairing
is_speed_anomaly = (traj["speed"] > speed_maximum) | (traj["speed"] < 0)
traj["speed"][is_speed_anomaly] = np.nan
# Step 2: 根据距离和时间计算速度
is_anomaly = np.array([False] * len(traj))
traj["coord_speed"] = traj["dist_array"] / traj["time_array"]
# Condition 1: 根据3-sigma算法剔除coord speed以及较大时间间隔的点
is_anomaly_tmp = pd.Series(thigma_data(traj["time_array"],3)) | pd.Series(thigma_data(traj["coord_speed"],3))
is_anomaly = is_anomaly | is_anomaly_tmp
is_anomaly.index=traj.index
# Condition 2: 轨迹点的3-sigma异常处理
traj = traj[~is_anomaly].reset_index(drop=True)
is_anomaly = np.array([False] * len(traj))
if len(traj) != 0:
lon_std, lon_mean = traj["lon"].std(), traj["lon"].mean()
lat_std, lat_mean = traj["lat"].std(), traj["lat"].mean()
lon_low, lon_high = lon_mean - 3 * lon_std, lon_mean + 3 * lon_std
lat_low, lat_high = lat_mean - 3 * lat_std, lat_mean + 3 * lat_std
is_anomaly = is_anomaly | (traj["lon"] > lon_high) | ((traj["lon"] < lon_low))
is_anomaly = is_anomaly | (traj["lat"] > lat_high) | ((traj["lat"] < lat_low))
traj = traj[~is_anomaly].reset_index(drop=True)
return traj, [len(is_speed_anomaly) - len(traj)]
df=get_data(r'hy_round1_train_20200102','train')
df=transform_xy2lonlat(df)
df['time']=df['time'].apply(reformat_strtime)
df['time']=df['time'].apply(lambda x: datetime.strptime(x,'%Y-%m-%d %H:%M:%S'))
这一个cell的代码不用运行,DF.csv该数据已经放到了github上面给出的附件数据里面
对轨迹进行异常点剔除,对nan值进行线性插值
ID_list=list(pd.DataFrame(df['ID'].value_counts()).index)
DF_NEW=[]
Anomaly_count=[]
for ID in tqdm(ID_list):
df_id=compute_traj_diff_time_distance(df[df['ID']==ID])
df_new,count=assign_traj_anomaly_points_nan(df_id)
df_new["speed"] = df_new["speed"].interpolate(method="linear", axis=0)
df_new = df_new.fillna(method="bfill")
df_new = df_new.fillna(method="ffill")
df_new["speed"] = df_new["speed"].clip(0, 23)
Anomaly_count.append(count)#统计每个id异常点的数量有多少
DF_NEW.append(df_new)
DF=pd.concat(DF_NEW)
win_file_path = 'E:\competition-data\017_wisdomOcean\'
#读取github的数据
DF = pd.read_csv(win_file_path + 'DF.csv')
DF
| Unnamed: 0 | ID | lat | lon | speed | direction | time | type | time_array | dist_array | coord_speed | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 4924 | 44.878993 | -121.048498 | 0.38 | 103 | 2019-11-13 23:59:30 | 围网 | -1.088487 | 19.788529 | -18.179848 |
| 1 | 1 | 4924 | 44.878993 | -121.048498 | 0.05 | 0 | 2019-11-13 23:58:27 | 围网 | -1.050000 | 0.000000 | -0.000000 |
| 2 | 2 | 4924 | 44.878993 | -121.048498 | 0.00 | 0 | 2019-11-13 23:57:24 | 围网 | -1.050000 | 0.000000 | -0.000000 |
| 3 | 3 | 4924 | 44.878993 | -121.048498 | 0.05 | 0 | 2019-11-13 23:56:20 | 围网 | -1.066667 | 0.000000 | -0.000000 |
| 4 | 4 | 4924 | 44.878993 | -121.048498 | 0.05 | 0 | 2019-11-13 23:55:17 | 围网 | -1.050000 | 0.000000 | -0.000000 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2551981 | 6 | 5034 | 44.792269 | -121.068256 | 0.59 | 0 | 2019-11-19 22:01:34 | 刺网 | -39.416667 | 0.000000 | -0.000000 |
| 2551982 | 7 | 5034 | 44.792269 | -121.068256 | 3.56 | 0 | 2019-11-19 10:11:36 | 刺网 | -709.966667 | 0.000000 | -0.000000 |
| 2551983 | 8 | 5034 | 44.792269 | -121.068256 | 5.67 | 180 | 2019-11-19 09:20:56 | 刺网 | -50.666667 | 0.000000 | -0.000000 |
| 2551984 | 9 | 5034 | 44.792269 | -121.068256 | 0.16 | 0 | 2019-11-19 06:11:01 | 刺网 | -189.916667 | 0.000000 | -0.000000 |
| 2551985 | 10 | 5034 | 44.792269 | -121.068256 | 1.30 | 84 | 2019-11-18 08:11:22 | 刺网 | -1319.650000 | 0.000000 | -0.000000 |
2551986 rows × 11 columns
由于数据量过大,如果直接将轨迹异常点剔除的数据用kepler.gl展示则在程序运行时会出现卡顿,或者无法运行的情况,此时可尝试利用geopandas对数据利用douglas-peucker算法进行简化。有效简化后的矢量数据可以在不损失太多视觉感知到的准确度的同时,带来巨大的性能提升。
#douglas-peucker案例,由该案例可以看出针对相同ID的轨迹,可以先用geopandas将其进行简化和数据压缩
line= shapely.geometry.LineString(np.array(df[df['ID']=='11'][['lon','lat']]))
ax=gpd.GeoSeries([line]).plot(color='red')
ax = gpd.GeoSeries([line]).simplify(tolerance=0.000000001).plot(color='blue',
ax=ax,
linestyle='--')
LegendElement = [plt.Line2D([], [], color='red', label='简化前'),
plt.Line2D([], [], color='blue', linestyle='--', label='简化后')]
# 将制作好的图例映射对象列表导入legend()中,并配置相关参数
ax.legend(handles = LegendElement,
loc='upper left',
fontsize=10)
# ax.set_ylim((-2.1, 1))
# ax.axis('off')
print('化简前数据长度:'+str(len(np.array(gpd.GeoSeries([line])[0]))))
print('化简后数据长度:'+str(len(np.array(gpd.GeoSeries([line]).simplify(tolerance=0.000000001)[0]))))
定义数据简化函数。即通过shapely库将经纬度转换成LineString格式
然后放入GeoSeries数据结构中并进行简化,最后再将所有数据放入GeoDataFrame中
def simplify_dataframe(df):
line_list=[]
for i in tqdm(dict(list(df.groupby('ID')))):
line_dict={}
lat_lon=dict(list(df.groupby('ID')))[i][['lon','lat']]
line=shapely.geometry.LineString(np.array(lat_lon))
line_dict['ID']=dict(list(df.groupby('ID')))[i].iloc[0]['ID']
line_dict['type']=dict(list(df.groupby('ID')))[i].iloc[0]['type']
line_dict['geometry']=gpd.GeoSeries([line]).simplify(tolerance=0.000000001)[0]
line_list.append(line_dict)
return gpd.GeoDataFrame(line_list)
df_gpd_change=simplify_dataframe(DF)
df_gpd_change.pkl是将异常处理之后的数据进行douglas-peucker算法进行压缩之后的数据。该数据已经放到了github上面给出的附件数据里面
#读取github的数据
# DF = pd.read_csv(win_file_path + 'DF.csv')
# DF
# df_gpd_change = pd.read_pickle(win_file_path + 'df_gpd_change.pkl')
df_gpd_change = pd.read_csv(win_file_path + 'df_gpd_change.csv')
df_gpd_change
| ID | type | geometry | |
|---|---|---|---|
| 0 | 0 | 拖网 | LINESTRING (-121.6133375263958 44.292814486328... |
| 1 | 1 | 拖网 | LINESTRING (-121.863106945724 44.1696051156698... |
| 2 | 2 | 拖网 | LINESTRING (-121.3898724542208 44.474984884055... |
| 3 | 3 | 拖网 | LINESTRING (-123.3394334359053 41.811143217304... |
| 4 | 4 | 围网 | LINESTRING (-117.9455099065786 46.906676924576... |
| ... | ... | ... | ... |
| 6995 | 6995 | 拖网 | LINESTRING (-121.4085667575275 44.874129768717... |
| 6996 | 6996 | 围网 | LINESTRING (-120.4834215663279 45.243287511492... |
| 6997 | 6997 | 拖网 | LINESTRING (-123.3398160072373 41.811105753051... |
| 6998 | 6998 | 拖网 | LINESTRING (-120.759049504848 45.0304010690245... |
| 6999 | 6999 | 拖网 | LINESTRING (-121.2645749480828 44.624246991430... |
7000 rows × 3 columns
map1=KeplerGl(height=800)#zoom_start与这个height类似,表示地图的缩放程度
map1.add_data(data=df_gpd_change,name='data')
#当运行该代码后,下面会有一个kepler.gl使用说明的链接,可以根据该链接进行学习参考
map1
User Guide: https://docs.kepler.gl/docs/keplergl-jupyter
KeplerGl(data={'data': {'index': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21…
另外,kepler.gl最近新增「增量时间窗口」功能功能对时间序列数据的可视化提供了很好的帮助。当我们的数据集带有时间类型字段时,在添加对应的Filters之后,显示出的时间窗口如下图所示
略 (需要在web页面渲染)
然后此时可以点击播放按钮,然后将默认的「Moving Time Window」模式切换到「Incremental Time Window」模式,此时就可以使用增量时间窗口模式看到画面中的数据会从起点开始持续叠加:
略(需要在web页面渲染)
如果你对dash有所了解,那么纯Python快速开发出一个嵌入kepler.gl的交互式web应用将会变得非常容易。具体内容可参考该链接
GeoHash (网格内地理编码)
参考文献:https://blog.csdn.net/zhufenghao/article/details/85568340
在对于经纬度进行数据分析和特征提取时常用到的是GeoHash编码,该编码方式可以将地理经纬度坐标编码为由字母和数字所构成的短字符串,它具有如下特性:
- 层级空间数据结构,将地理位置用矩形网格划分,同一网格内地理编码相同
- 只要编码长度足够长,可以表示任意精度的地理位置坐标
- 编码前缀匹配的越长,地理位置越邻近。
下图对北京中关村软件园附近进行6位的GeoHash编码结果,9个网格相互邻近且具有相同的前缀.
略
那么GeoHash算法是怎么对经纬度坐标进行编码的呢?总的来说,它采用的是二分法不断缩小经度和纬度的区间来进行二进制编码,最后将经纬度分别产生的编码奇偶位交叉合并,再用字母数字表示。举例来说,对于一个坐标116.29513,40.04920的经度执行算法:
- 将地球经度区间[-180,180]二分为[-180,0]和[0,180],116.29513在右区间,记1;
- 将[0,180]二分为[0,90]和[90,180],116.29513在右区间,记1;
- 将[90,180]二分为[90,135]和[135,180],116.29513在左区间,记0;
- 递归上述过程(左区间记0,右区间记1)直到所需要的精度,得到一串二进制编码11010 01010 11001。
同理将地球纬度区间[-90,90]根据纬度40.04920进行递归二分得到二进制编码10111 00011 11010,接着生成新的二进制数,它的偶数位放经度,奇数位放纬度,得到11100 11101 00100 01101 11110 00110,最后使用32个数字和字母(字母去掉a、i、l、o这4个)进行32进制编码,即先将二进制数每5位转化为十进制28 29 4 13 30 6,然后对应着编码表进行映射得到wy4ey6。
对这样的GeoHash编码大小排序后,是按照Z形曲线来填充空间的,后来又衍生出多种填充曲线且具有多种特性,由于没有Z形曲线简单通用,这里就不赘述了。
另外还有一些其他曲线可以填充空间,比如著名的希尔伯特曲线,感兴趣的可以看bilibili这个视频,了解一下,还是蛮有趣的~
https://www.bilibili.com/video/BV1Sf4y147J9?from=search&seid=12367619856156226126
注意事项
GeoHash的主要价值在于将二维的经纬度坐标信息编码到了一维的字符串中,在做地理位置索引时只需要匹配字符串即可,便于缓存、信息压缩。在使用大数据工具(例如Spark)进行数据挖掘聚类时,GeoHash显得更加便捷和高效。
但是使用GeoHash还有一些注意事项:
- 由于GeoHash使用Z形曲线来顺序填充空间的,而Z形曲线在拐角处会有突变,这表现在有些相邻的网格的编码前缀比其他网格相差较多,因此利用前缀匹配可以找到一部分邻近的区域,但同时也会漏掉一些。
- 一个网格内部所有点会共用一个GeoHash值,在网格的边缘点会匹配到可能较远但是GeoHash值相同的点,而本来距离较近的点却没有匹配到。这种问题可以这样解决:适当增加GeoHash编码长度,并使用周围的8个近邻编码来参与,因为往往只使用一个GeoHash编码可能会有严重风险!
作业
基础作业:
1.尝试去使用kepler.gl可视化来分析不同类型船舶AIS数据的分布情况,并为接下来的特征工程的提取建立基础
import pandas as pd
import matplotlib.pyplot as plt
from pyproj import Proj
from keplergl import KeplerGl
win_file_path = 'E:\competition-data\017_wisdomOcean\'
df_gpd_change = pd.read_csv(win_file_path + 'df_gpd_change.csv')
df_gpd_change
| ID | type | geometry | |
|---|---|---|---|
| 0 | 0 | 拖网 | LINESTRING (-121.6133375263958 44.292814486328... |
| 1 | 1 | 拖网 | LINESTRING (-121.863106945724 44.1696051156698... |
| 2 | 2 | 拖网 | LINESTRING (-121.3898724542208 44.474984884055... |
| 3 | 3 | 拖网 | LINESTRING (-123.3394334359053 41.811143217304... |
| 4 | 4 | 围网 | LINESTRING (-117.9455099065786 46.906676924576... |
| ... | ... | ... | ... |
| 6995 | 6995 | 拖网 | LINESTRING (-121.4085667575275 44.874129768717... |
| 6996 | 6996 | 围网 | LINESTRING (-120.4834215663279 45.243287511492... |
| 6997 | 6997 | 拖网 | LINESTRING (-123.3398160072373 41.811105753051... |
| 6998 | 6998 | 拖网 | LINESTRING (-120.759049504848 45.0304010690245... |
| 6999 | 6999 | 拖网 | LINESTRING (-121.2645749480828 44.624246991430... |
7000 rows × 3 columns
map1=KeplerGl(height=400)#zoom_start与这个height类似,表示地图的缩放程度
map1.add_data(data=df_gpd_change,name='所有数据类型')
#当运行该代码后,下面会有一个kepler.gl使用说明的链接,可以根据该链接进行学习参考
map1
User Guide: https://docs.kepler.gl/docs/keplergl-jupyter
KeplerGl(data={'所有数据类型': {'index': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, …
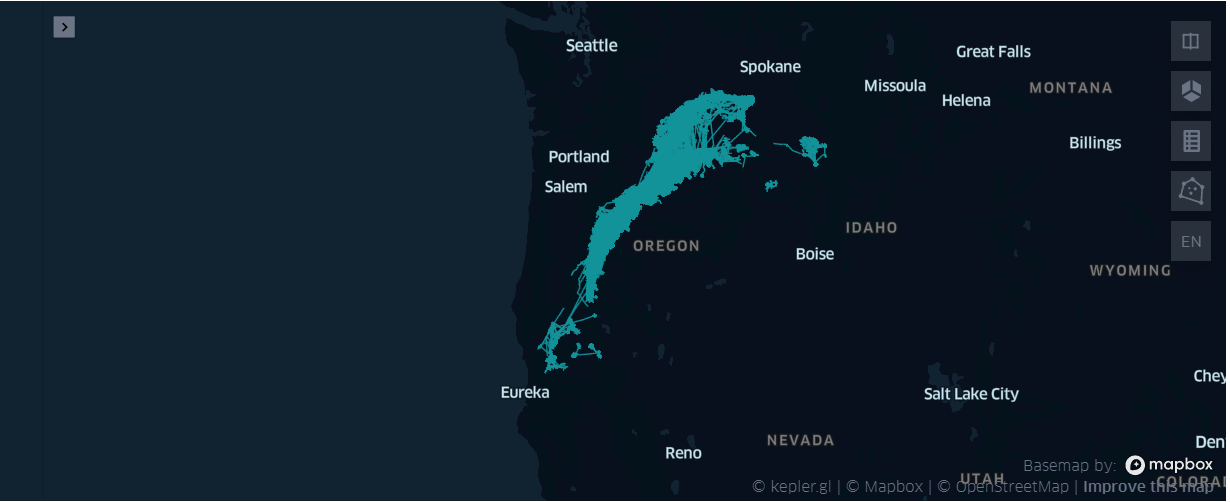
# 计算不同的类别,进行去重
set(df_gpd_change['type'])
{'刺网', '围网', '拖网'}
map2=KeplerGl(height=400)
map2.add_data(data=df_gpd_change[df_gpd_change['type']=='刺网'],name='刺网')
map2
User Guide: https://docs.kepler.gl/docs/keplergl-jupyter
KeplerGl(data={'刺网': {'index': [13, 35, 46, 48, 53, 54, 57, 60, 64, 72, 77, 83, 87, 113, 116, 125, 126, 127, 1…
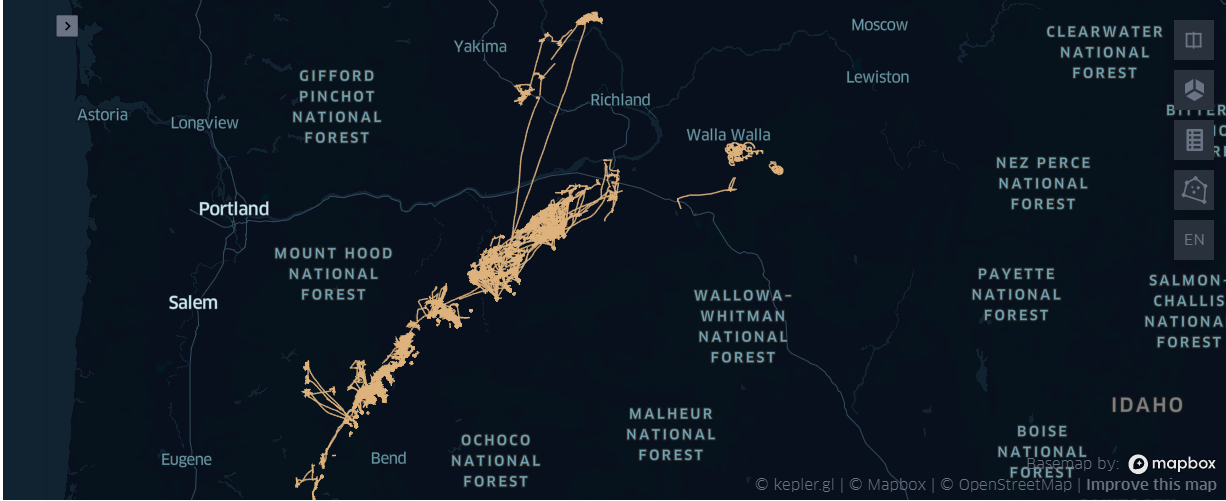
map3=KeplerGl(height=400)
map3.add_data(data=df_gpd_change[df_gpd_change['type']=='围网'],name='围网')
map3
User Guide: https://docs.kepler.gl/docs/keplergl-jupyter
KeplerGl(data={'围网': {'index': [4, 7, 15, 19, 20, 23, 25, 26, 31, 34, 36, 37, 40, 42, 45, 47, 49, 50, 52, 55, …
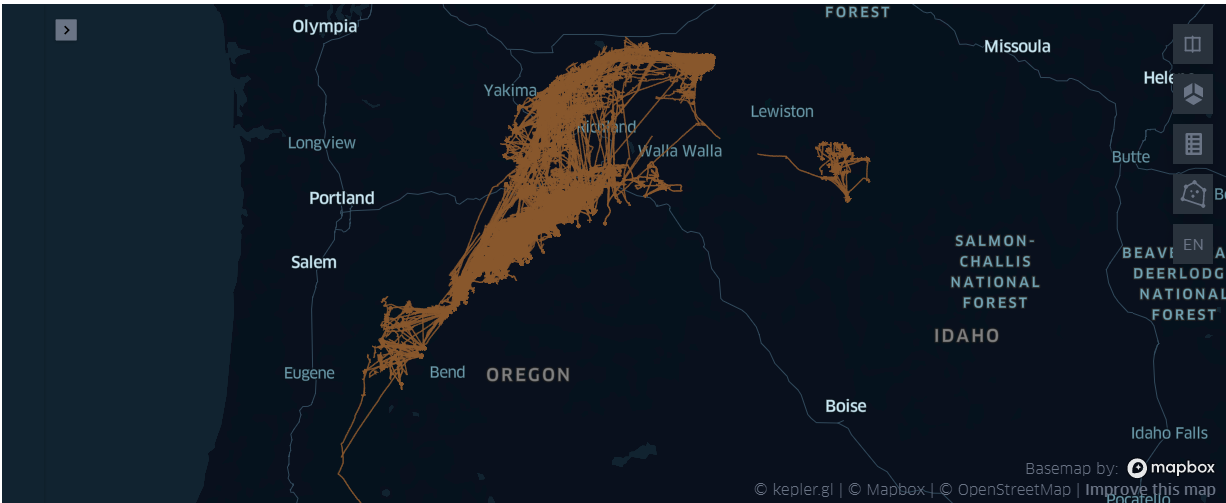
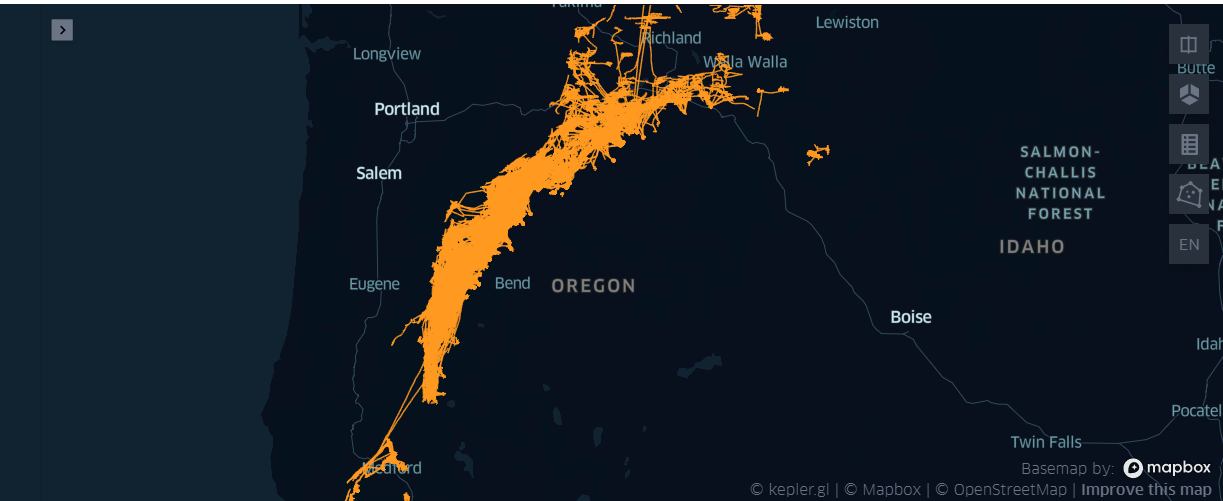
map4=KeplerGl(height=400)
map4.add_data(data=df_gpd_change[df_gpd_change['type']=='拖网'],name='拖网')
map4
User Guide: https://docs.kepler.gl/docs/keplergl-jupyter
KeplerGl(data={'拖网': {'index': [0, 1, 2, 3, 5, 6, 8, 9, 10, 11, 12, 14, 16, 17, 18, 21, 22, 24, 27, 28, 29, 30…
作业一的数据分析小结
- 在{'刺网', '围网', '拖网'} 中不同的作业, 总体看上都很稠密, 刺网的图相对 '薄'了一点
- 鼠标放到图上后,具体观察有所不同
- '刺网'大多在路径上回构成几个
死疙瘩状的线疙瘩 - '围网'会构成一个口袋装,留一个进口——应该是朝着洋流的方向,效率最高
- '拖网'的路线,部分路线整体的大部分相对比较平滑——呈线性趋势
- '刺网'大多在路径上回构成几个
进阶作业:
2.在这个模块中,我们介绍了各种库以及他们常用的方法。如果可以,请同学们尝试在原有剔除异常点的数据(DF)中保留douglas-peucker算法所识别的关键点的数据,删除douglas-peucker未保存的数据,并尝试对这些坐标点进行geohash编码
import pandas as pd
#读取github的数据 (剔除异常点的数据(DF))
win_file_path = 'E:\competition-data\017_wisdomOcean\'
DF = pd.read_csv(win_file_path + 'DF.csv')
DF.head(2)
| Unnamed: 0 | ID | lat | lon | speed | direction | time | type | time_array | dist_array | coord_speed | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 4924 | 44.878993 | -121.048498 | 0.38 | 103 | 2019-11-13 23:59:30 | 围网 | -1.088487 | 19.788529 | -18.179848 |
| 1 | 1 | 4924 | 44.878993 | -121.048498 | 0.05 | 0 | 2019-11-13 23:58:27 | 围网 | -1.050000 | 0.000000 | -0.000000 |
DF.shape
(2551986, 11)
# 保留douglas-peucker算法所识别的关键点的数据
# 删除douglas-peucker未保存的数据
import shapely
import geopandas as gpd
import numpy as np
lines = shapely.geometry.LineString(np.array(DF[['lon','lat']]))
ax = gpd.GeoSeries([lines]).plot(color='red')
DF_lines_simplify = gpd.GeoSeries([lines]).simplify(tolerance=0.000000001)
DF_lines_simplify
# ax = DF_lines_simplify.plot(color='blue', ax=ax, linestyle='--')
# LegendElement = [plt.Line2D([], [], color='red', label='简化前'),
# plt.Line2D([], [], color='blue', linestyle='--',
# label='简化后')]
#
# # 将制作好的图例映射对象列表导入legend()中,并配置相关参数
# ax.legend(handles = LegendElement,
# loc='upper left',
# fontsize=10)
# # ax.set_ylim((-2.1, 1))
# # ax.axis('off')
# print('化简前数据长度:'+str(len(np.array(gpd.GeoSeries([line])[0]))))
# print('化简后数据长度:'+str(len(np.array(gpd.GeoSeries([line]).simplify(tolerance=0.000000001)[0]))))
# 尝试对这些坐标点进行geohash编码
def geohash_encode(latitude, longitude, precision=12):
"""
Encode a position given in float arguments latitude, longitude to
a geohash which will have the character count precision.
"""
lat_interval, lon_interval = (-90.0, 90.0), (-180.0, 180.0)
base32 = '0123456789bcdefghjkmnpqrstuvwxyz'
geohash = []
bits = [16, 8, 4, 2, 1]
bit = 0
ch = 0
even = True
while len(geohash) < precision:
if even:
mid = (lon_interval[0] + lon_interval[1]) / 2
if longitude > mid:
ch |= bits[bit]
lon_interval = (mid, lon_interval[1])
else:
lon_interval = (lon_interval[0], mid)
else:
mid = (lat_interval[0] + lat_interval[1]) / 2
if latitude > mid:
ch |= bits[bit]
lat_interval = (mid, lat_interval[1])
else:
lat_interval = (lat_interval[0], mid)
even = not even
if bit < 4:
bit += 1
else:
geohash += base32[ch]
bit = 0
ch = 0
return ''.join(geohash)
#调用Geohash函数
print(type(DF_lines_simplify))
geohash_gpd_simplify_DF = DF_lines_simplify.apply(lambda x: geohash_encode(x['lat'], x['lon'], 7), axis=1)
geohash_gpd_simplify_DF
跑不动, 暂时放弃