学习参考:Python3网络爬虫开发实战
问题:requests抓取的页面信息和浏览器中看到的不一样。
原因:requests获取的都是原始的HTML文档,浏览器中的页面很多都是经过javascript数据处理后的结果,这些数据可能通过AJax加载的,也可能是通过其他特定算法计算得到的
解决:对于通过Ajax加载的,叫异步加载,这种可以在web开发上做到前后端分离,降低服务器直接渲染页面带来的压力,如果遇到requests无法获取有效数据,需要进一步分析网页后台向接口发送的Ajax请求,然后用requests来模拟Ajax请求,就可以成功获取了
6.1 什么是 Ajax
Ajax是利用Javascript在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。
2. 基本原理
发送请求、解析内容、渲染网页
6.2 Ajax 分析方法
1. 查看请求
jax其实有其特殊的请求类型,它叫作 xhr ,Request Headers中有一个信息为 X-Requested-With:XMLHt甲Request,这就标记了此请求是 Ajax请求
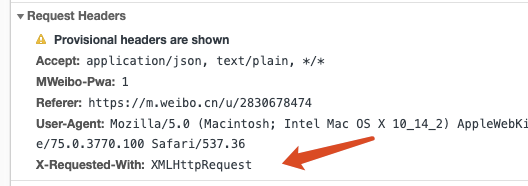
在response里面可以找到真实的数据。
2. 过滤请求

6.3 Ajax 结果提取
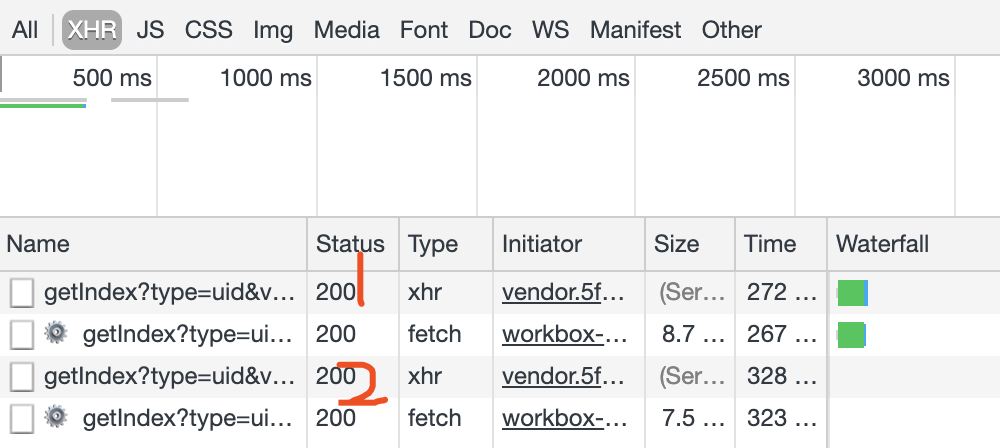
点击第一个,可以发现,这是一个 GET类型的请求,请求链接为 https://m.weibo.cn/api/container/getIndex?type=uid&value=2830678474&containerid=1076032830678474&page=2。 请求的参数有 4 个: type、 value、 containerid 和 page。
点开第二个,请求链接为:https://m.weibo.cn/api/container/getIndex?type=uid&value=2830678474&containerid=1076032830678474&page=3
2. 分析响应

可以看到,最关键 的两部分信息就是 cardlistlnfo 和 cards:前者包含一个 比较重要的信息 total,观察后可以发现, 它其实是微博的总数量,我们可以根据这个数字来估算分页数;后者则是一个列表,它包含 10 个元 素 ,展开其中 一个看一下,

这个元素有一个比较重要的字段 mblog。 展开它,可以发现它包含的正是微博的一些 信息,比如 attitudes count (赞数目)、 comments_count (评论数目)、 reposts_count (转发数目)、 created at (发布时间)、 text (微博正文)等,而且它们都是-些格式化的内容 。
3. 实战演练
用程序模拟这些 Ajax请求,将前 10页微博全部爬取下来。
import requests
from urllib.parse import urlencode
from pyquery import PyQuery as pq
base_url = 'https://m.weibo.cn/api/container/getIndex?' # 这里要换成对应Ajax请求中的链接
headers = {
'Host':'m.weibo.cn',
'Referer':'https://m.weibo.cn/u/2830678474',
'X-Requested-With':'XMLHttpRequest',
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
} # 不同于简单的requests,只需要传入客户端信息就好了
def get_page(page):
params = {
'type':'uid',
'value':'2830678474',
'containerid':'1076032830678474',
'page':page
}
url = base_url + urlencode(params)
try:
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.json() # 解析内容为json返回
except requests.ConnectionError as e:
print('Error',e.args) #输出异常信息
def parse_page(json):
if json:
items = json.get('data').get('cards')
for item in items:
item = item.get('mblog')
weibo = {}
weibo['id'] = item.get('id')
weibo['text'] = pq(item.get('text')).text() # 这里面的文字内容又进行了一层解析,将正文里面的html标签去掉
weibo['attitudes'] = item.get('attitudes_count')
weibo['comments'] = item.get('comments_count')
weibo['reposts'] = item.get('reposts_count')
yield weibo
if __name__ =='__main__': # 本脚本窗口下的程序名字就叫做main,且这样写在别的程序调用该脚本文件的函数时不会受到影响
for page in range(1,11):
json = get_page(page)
results = parse_page(json)
for result in results:
print(result)
结果:

6.4 分析 Ajax爬取今日头条街拍美图
抓取今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来。
import requests
from urllib.parse import urlencode
import os
from hashlib import md5
from multiprocessing.pool import Pool
def get_page(offset):
params = {
'aid':'24',
'app_name':'web_search',
'offset':offset,
'format':'json',
'keyword':'街拍',
'autoload':'true',
'count':'20',
'en_qc':'1',
'cur_tab':'1',
'from':'search_tab',
'pd':'synthesis',
'timestamp':'1562248846140'
}
header = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'x-requested-with':'XMLHttpRequest',
'referer':'https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D',
'cookie':'tt_webid=6709993811802818062; WEATHER_CITY=%E5%8C%97%E4%BA%AC; tt_webid=6709993811802818062; UM_distinctid=16bbfdeff8f460-0e02d1b4d98e6d-37607e02-1fa400-16bbfdeff90492; CNZZDATA1259612802=558541297-1562289443-https%253A%252F%252Fwww.google.com%252F%7C1562289443; __tasessionId=aorag2kb71562292191190; csrftoken=e4aae62081d10a9bb97fb5cd48e5cfa7; s_v_web_id=03c096aa5abb1e5a2f9edc5b4be5e8f3'
}
url = 'https://www.toutiao.com/api/search/content/?'+urlencode(params)
try:
response = requests.get(url,headers=header)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error',e.args)
# return None
def get_images(json):
if json.get('data'):
items = json.get('data')
for item in items:
title = item.get('title')
images = item.get('image_list')
for image in images:
yield {
'image':image.get('url'),
'title':title # 没明白这个title 是怎么来的
}
def save_image(item):
if not os.path.exists(item.get('title')):
os.mkdir(item.get('title'))
try:
response = requests.get(item.get('image')) # 请求图片链接,获取二进制数据
if response.status_code == 200:
file_path = '{0}/{1}.{2}'.format(item.get('title'),md5(response.content).hexdigest(),'jpg') # md5的哈希值
print(file_path)
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(response.content)
else:
print("Already Downloaded",file_path)
except requests.ConnectionError as e:
print("Failed to Save Image")
def main(offset):
json = get_page(offset)
for item in get_images(json):
print(item)
save_image(item)
# GROUP_START = 1
# GROUP_END = 20
#
# if __name__=="__main__":
# pool = Pool() #实例化
# groups = ([x *20 for x in range(GROUP_START,GROUP_END+1)])
# pool.map(main,groups)
# pool.close()
# pool.join()
main(20)
结果:
