在使用Kettle进行数据同步的时候, 共有
1.使用时间戳进行数据增量更新
2.使用数据库日志进行数据增量更新
3.使用触发器+快照表 进行数据增量更新
今天要介绍的是第3中方法。
实验的思路是这样的,在进行数据同步的时候,
源数据表为A表, A表要对 目标表(target table) B 表和C表进行数据的同步更新。
即A表中的对应字段发生变化之后,
会通过触发器将对应变化的字段在A表中的主键值写入到一个临时表temp中(该表作为快照表使用)。
快照表中只有两个字段,一个是temp_id,是快照表的主键,另一个是 A_id,记录的是在A表中发生变化的字段对应的主键的值。
temp( temp_id int primary key auto_increment , A_id int );
接下来,通过对快照表temp进行扫描,把在B表和C表中出现的与temp表中与A_id相匹配的字段,
从B,C两个目标表中进行移除。
在接下来,让A表作为源 让B和C作为目标 对B,C做插入/更新操作;
这样就实现了A表对B,C两个表的更新,在后续的操作中可以使用SQL语句将 temp表, 以及触发器进行 drop操作,以免其浪费内存资源。
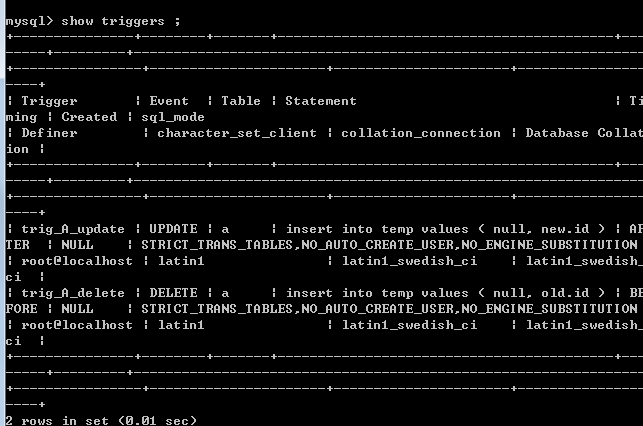
在创建 trigger的时候,只要针对A表的 删除、 更新操作进行创建trigger 即可。
下面来分析一下,对A表进行的不同操作的情况:
1.如果是向A表中插入一行数据: 没有对应的触发器,新插入A表的recorder 并没有被记录到temp 快照表中,
所以不会对B,C表中对应的字段进行移除操作。(不对 A 表的Insert 操作创建 trigger
可以避免 如果对 A表进行插入的 主键值 在 B, C表中 根本找不到,
这样的话无法 根据temp 中记录的 主键值 对B,C表中的字段进行移除 )
即便不建立触发器,后续操作中仍旧会因为有 插入/更新的这个 step,对B 表 和 C表进行插入操作的。
2.如果是向A表删除一行数据的话, 对应创建的触发器会将 A表中被删除的 主键 字段写入到 temp这个快照表中去,
接下来,会依照temp表中的字段对B 表和 C 表中的记录进行移除操作。
而在后续的插入更新操作中,A表中已经将该记录进行移除了,所以没有对应的记录对B,C两张表进行插入操作。
3. 如果对A表中的某一条记录 进行 Update 更新操作的话 ,对应Update进行创建的触发器会 把A表中被更新的记录
所对应的主键值 写入到快照表 temp中去,
接下来会根据temp表中的主键值,对表B 表 C 中的字段进行移除,
然后对B表 C表 依照 A表中的字段进行 插入更新操作。
插入更新操作是这样的,
如果是主键值相等的话, 目标表对应字段 与 源表对应字段 不相同,
就会对目标表字段进行依照 源表进行更新,
如果是某条记录的 主键值 在源表中出现,但是在目标表中没有出现的话,
则对目标表进行相应的插入操作。(依照源表)
========================================================================
接下来,简单介绍一下实验数据:
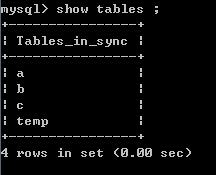
首先,在Mysql中创建3个表, A B C 表,
对应的字段都是一样的,对应的数据也都是一样的(为了简便......)。
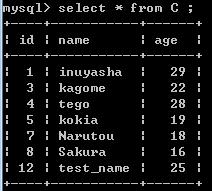
接下来,在Kettle的Spoon中创建下面的流程:
Main
主流程中需要注意的是,在整个流程中,前段的prepare 和 后续 finish 只需要执行一次,
中间的syn是需要重复循环的,至少LZ是这样设计的,这样可以使得在循环的这段时期中,
若是A表中的相关字段发生变化的话,会实时地将变化同步到 B C两个表中。
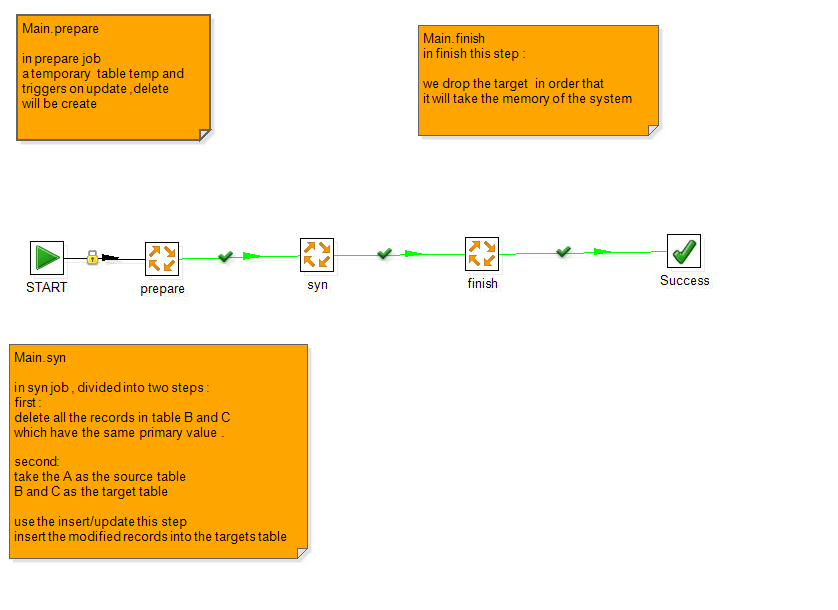
Main.prepare
在创建触发器的时候需要注意一下,LZ在实验的时候,
发现如果触发器若想触发 多条操作的时候,
是要写
" DELIMITER + 分隔符号 "
begin
commands
end
分隔符号
但是,kettle目前的版本是不支持 delimiter的, 也就是写上之后会报错,
不写上,若是执行多条命令语句 后面是必须要加 分号 ";" 来结尾的,
不加分号,也会报错,
若加上之后,触发器会默认为 到分号 触发内容就会结束, 也是出错的,
LZ的这个步骤之所以没有出错是因为,LZ创建的 触发器只有一条触发语句,所以没有用到 delimiter。
如果您想写多条 触发语句的话,在delimiter这里要注意一下吧~
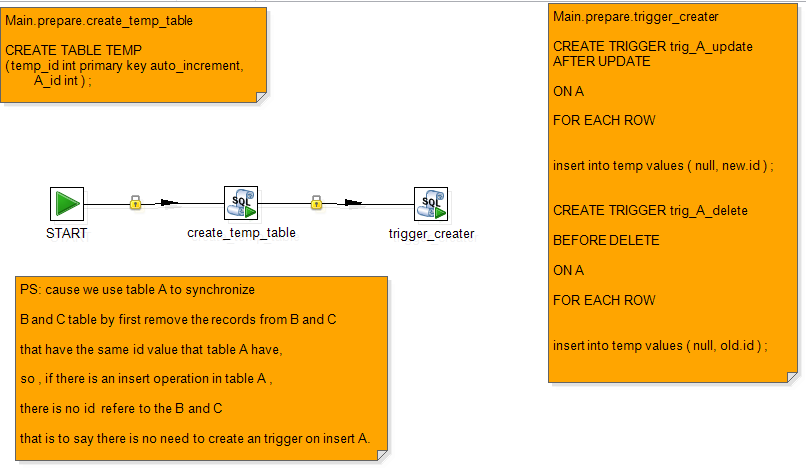
Main.syn
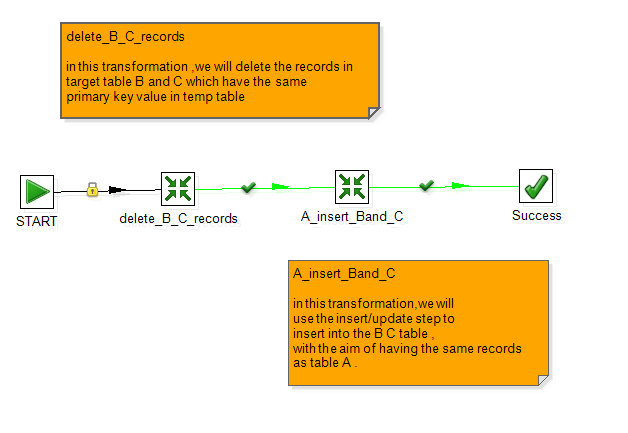
Main.syn.delete_B_C_records
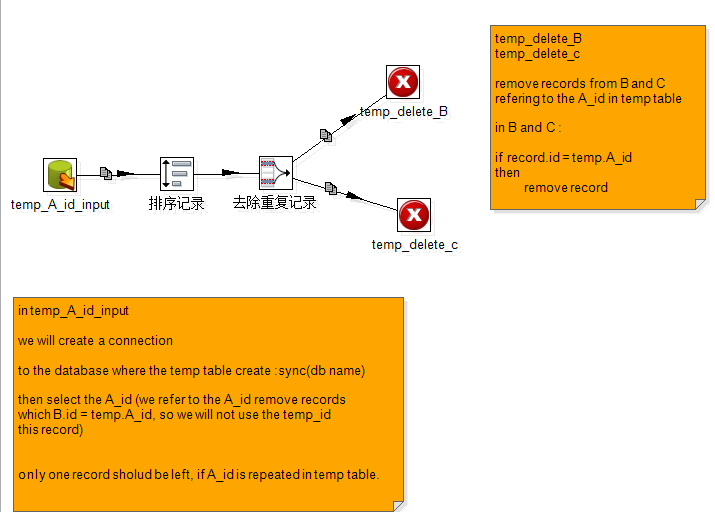
Main.syn.A_insert_BandC
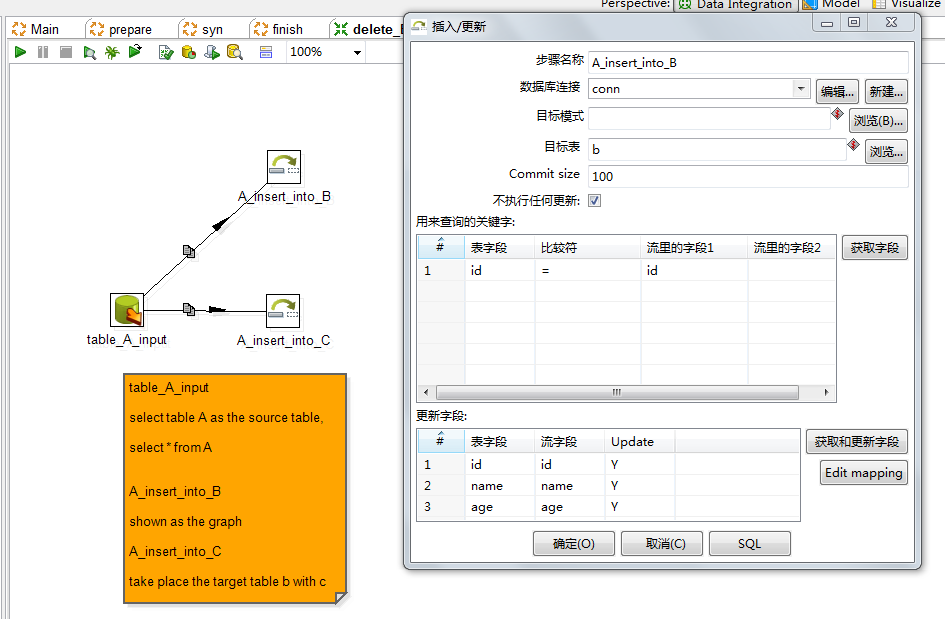
这里需要注意的是,在A_insert_into_C这个步骤的时候,对应的目标表中要选择为c表。
而且,使用触发器+快照表 进行数据增量更新 主要是通过 :先根据源表中变化(update delete)的记录 对应删除目标表中的字段,
然后再,将A表中变化的字段插入到目标表中; 所以整个过程不存在 使用源表 对 目标表进行更新 操作。所以"不执行任何更新" 要勾选 .
Main.finish
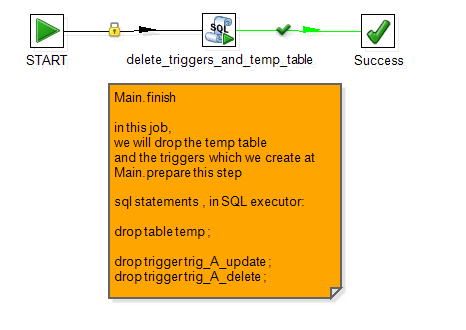
收尾工作,主要回收资源,调用Sql语句,执行删除 快照表、触发器工作。
接下来我们向A表中,
1.insert 一条记录,
2.delete一条 同时存在于 A B C表中的记录,
3.update 一条A表中的记录。
4.然后对 A表中的 同一条 记录 先 update 再 delete 它 看结果如何
5.(元数据) A表中还有上一次实验被存入的,但是B C两张表中所没有的 记录:
原A:
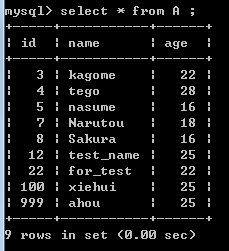
原B:
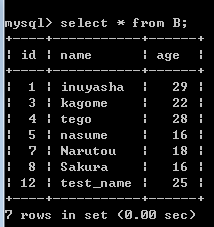
原C:
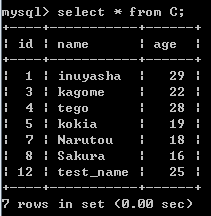
after prepare:
modify A :
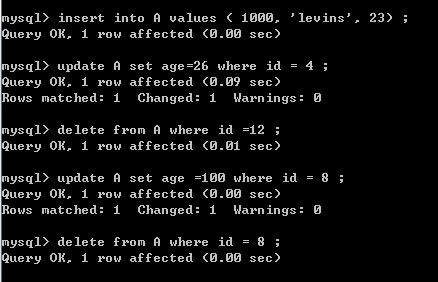
执行上述的 1 2 3 4 操作后:
A:
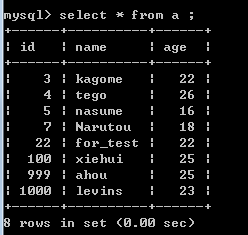
snapshot table temp :
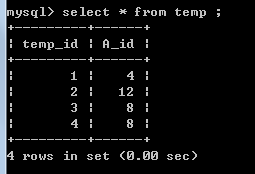
对A表的 id=8 进行一次update 一次 delete,
这个temp表需要对A_id进行去除重复记录操作,这也是为什么要在syn.delete_B_C_records中
去除重复记录的原因。
为了将整个流程分解,我们来调用Main.syn.delete_B_C_record 这个transformation:
之后显示的
B:
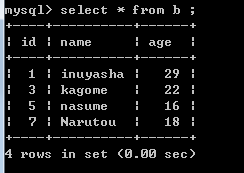
C:
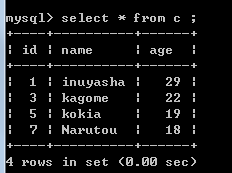
接下来,使用A表对B,C两表进行 插入/更新步骤 即 Main.syn.A_insert_BandC
B: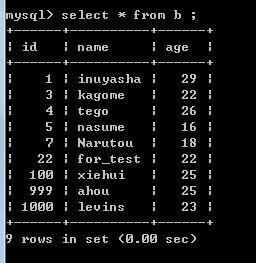 C:
C: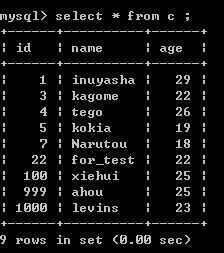
这样的话,不仅实现了更新,删除,同步操作,而且同样把A表中的原来的字段同步到B C两张表中去了。
如果,不希望将A表中原有数据同步到B,C表中的话,可以通过字段选择来实现。
| id | name | age | id | name | age | id | name | age | ||
| 1 | inuyasha | 29 | 1 | inuyasha | 29 | 1 | inuyasha | 29 | ||
| 3 | kagome | 22 | 3 | kagome | 22 | 3 | kagome | 22 | ||
| 4 | tego | 28 | 4 | tego | 28 | 4 | tego | 28 | ||
| 5 | kokia | 19 | 5 | kokia | 19 | 5 | kokia | 19 | ||
| 7 | Narutou | 18 | 7 | Narutou | 18 | 7 | Narutou | 18 | ||
| 8 | Sakura | 16 | 8 | Sakura | 16 | 8 | Sakura | 16 | ||
| 12 | test_name | 25 | 12 | test_name | 25 | 12 | test_name | 25 | ||
| id | name | age | id | name | age | id | name | age | ||
| 3 | kagome | 22 | 1 | inuyasha | 29 | 1 | inuyasha | 29 | ||
| 4 | tego | 28 | 3 | kagome | 22 | 3 | kagome | 22 | ||
| 5 | nasume | 16 | 4 | tego | 28 | 4 | tego | 28 | ||
| 7 | Narutou | 18 | 5 | nasume | 16 | 5 | kokia | 19 | ||
| 8 | Sakura | 16 | 7 | Narutou | 18 | 7 | Narutou | 18 | ||
| 12 | test_name | 25 | 8 | Sakura | 16 | 8 | Sakura | 16 | ||
| 22 | for_test | 22 | 12 | test_name | 25 | 12 | test_name | 25 | ||
| 100 | xiehui | 25 | ||||||||
| 999 | ahou | 25 | ||||||||
| id | name | age | id | name | age | id | name | age | ||
| 3 | kagome | 22 | 1 | inuyasha | 29 | 1 | inuyasha | 29 | ||
| 4 | tego | 26 | 3 | kagome | 22 | 3 | kagome | 22 | ||
| 5 | nasume | 16 | 5 | nasume | 16 | 5 | kokia | 19 | ||
| 7 | Narutou | 18 | 7 | Narutou | 18 | 7 | Narutou | 18 | ||
| 22 | for_test | 22 | ||||||||
| 100 | xiehui | 25 | ||||||||
| 999 | ahou | 25 | ||||||||
| 1000 | levins | 23 | ||||||||
| temp_id | A_id | |||||||||
| 1 | 4 | |||||||||
| 2 | 12 | |||||||||
| 3 | 8 | |||||||||
| 4 | 8 |
当然在具体业务中的情况要比实验内容复杂得多,这里仅提供简单的思路,
如果有不恰当之处,敬请指正。