High Performance Visual Tracking with Siamese Region Proposal Network
商汤
提出双孪生位置建议网络(Siamese-RPN)
proposed Siamese region proposal network (Siamese-RPN)
特点:
1.有别于生成响应图,直接生成目标位置回归
2.速度快,精度好
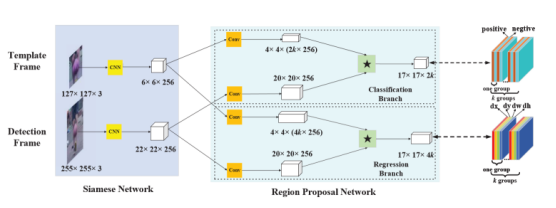
网络结构:
网络主干选择AlexNet(较早)
1.分别对模板帧(第一帧)和检测帧做特征提取
2.对于目标置信回归,取两个特征图,各自经过一次卷积,用小的特征图对大的特征图做卷积,卷积结果(通道数2*k个,k是anchor数量)用来预测不同长框比的anchor下是否有目标(具体看下代码)
3.同理,位置回归得到4*k个通道的特征图
损失函数:和大多数的检测一样,分类回归用的是交叉熵损失,位置回归用平滑L1损失

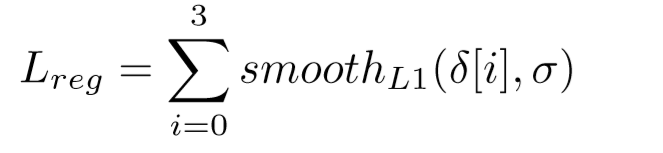
训练集:
ILSVRC (4000个训练集和550个验证集)
Youtube-BB 100000(太大了,没有完全统计)
训练方式:SGD(现在好像也比较少用)
训练时IOU阈值:
0.6以上为正样本,只取16个训练
0.3以下为负样本,只取64个训练
训练label
模板:
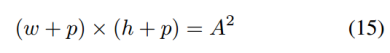

以目标为中心取A*A大小的patch,缩放到127*127
搜索区域:
2A*2A,缩放到255*255
视频帧的挑选帧号距离不大于100
训练机器1060,epoch50,10-2到10-6(0.0005衰减)
测试上,两种选取机制
1.只看中间7*7
2.加惩罚项:cos窗+尺度长宽比惩罚
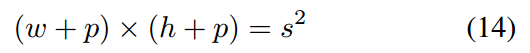
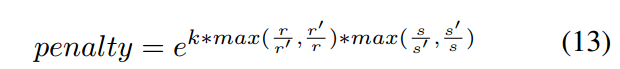
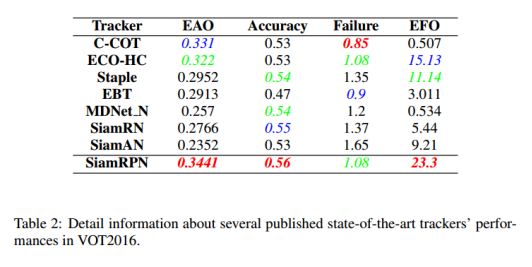
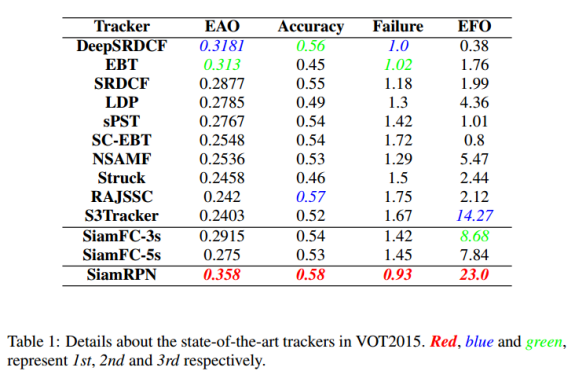
实验结果(160FPS)
后续:
DaSiamRPN:训练集加入COCO与VOC,训练负样本;长程跟踪机制
SiamRPN++:ResNet、特征融合
SiamMask:掩码
RPN的生成
每个点分类是否为目标,回归x,y,w,h,其中x与y为目标中心坐标,而不是目标左上角坐标
分类:2*k个,2代表是目标不是目标,最后通过softmax做预测与训练
位置回归:x,y,w,h是最终计算的结果,不是直接回归的结果(CNN做卷积的时候都不知道自己卷的是哪里),回归的是相对的值

label生成准备
参数
base=64#anchor的基础大小
stride=16#anchor滑动的步长,输入图像与输出图像的比例
scale=[1/3,1/2,1,2,3]#anchor的长宽比
anchor:每个像素点打k个格子,k为scale长度,
每个格子有固定的长宽比,计算方式:
s=base*base
w=sqrt(s/scale)
h=w*scale
保证w*h=base*base
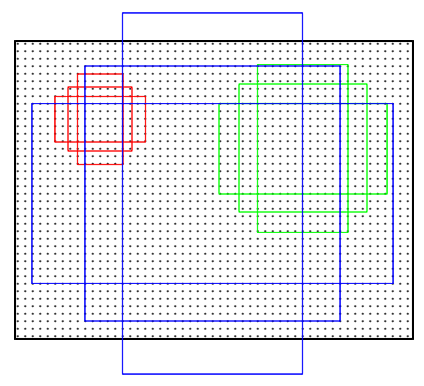
每个像素点都有k个anchor,n*n的特征图就有n*n*k个anchor(这里检测anchors)
每个anchor都有各自的Xa,Ya,Wa,Ha->Xa0,Ya0,Xa1,Ya1
label生成
分类label:给一个目标GT,Xg,Yg,Wg,Hg -> Xg0,Yg0,Xg1,Yg1计算与每个anchor的IOU,大于Th=0.7为正样本,小于Tl=0.3为负样本
回归label:
diff_anchors=np.zeros_like(anchors).astype(np.float32)
diff_anchors[:,0]=(gt[0]-anchors[:,0])/(anchors[:,2]+0.01)
diff_anchors[:,1]=(gt[1]-anchors[:,1])/(anchors[:,3]+0.01)
diff_anchors[:,2]=np.log(gt[2]/(anchors[:,2]+0.01))
diff_anchors[:,3]=np.log(gt[3]/(anchors[:,3]+0.01))
预测:
输出2*k+4*k个通道的特征图,无BN层,无激活函数
bboxes=np.zeros_like(delta)
bboxes[:,0]=delta[:,0]*self.anchors[:,2]+self.anchors[:,0]
bboxes[:,1]=delta[:,1]*self.anchors[:,3]+self.anchors[:,1]
bboxes[:,2]=np.exp(delta[:,2])*self.anchors[:,2]
bboxes[:,3]=np.exp(delta[:,3])*self.anchors[:,3]#[x,y,w,h]