---恢复内容开始---
Softmax函数,或称归一化指数函数
是逻辑函数的一种推广。它能将一个含任意实数的K维向量 



wiki的资料看完了,就感觉softmax的作用只有归一化。
cross-entropy loss : cost = -1 / m * np.sum(Y * np.log(A) + (1 - Y) * np.log(1 - A)) 最后要除以m也就是样本个数,所以每一次不管用的batch多大,都是可以的
Coursera 深度学习系列5课程,第一个课程的视频我刷完了,现在正在刷第二个的。
就从第二个开始记笔记吧,目的就是整理一些最基本的知识点。
第二期课程
Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization
第一周
Title: Normalizing Input
1,所有都减去均值,zero-mean
2.将方差归一化
对训练集和测试集使用同样的均值和方差进行归一化,指数值上的同样
当输入数据在不同维度上取值范围相差很大,梯度下降会运行的很慢,就需要归一化。
Title: Vanishing/ exploding gradinets 梯度的消失和爆炸
很深的神经网络里,参数W里面的值不断乘起来,可能爆炸,也可能消失,对应的梯度也是一样
Title: Weights initialization for DNN
有几个常见的设置初始参数的方法,让W的方差等于1/n,n是输入神经元的数量
Title: gradient check
用公式计算一遍dtheta, 再用数值的方法计算一遍dtheta,比较是否大致相等,看看求导的部分有没有做错。数值方法不需要你自己计算导数的,数值法使用J(w+e),J(w-e)
最后算两个结果的欧氏距离
title: mini-batch gradient decent
把大的训练集分成小的batch,用一个for循环对每个batch进行计算
min-batch的大小设为训练集大小时,就是batch gradient decent,批梯度下降,每一步运行的噪声相对小,很慢
设为1时,就变成随机梯度下降,每一步运行的噪声相对大,但是总体还是下降的,一般不会收敛。运算没有利用向量化加速的优点。
一般选择64到512作为mini-batch-size,取2的幂算起来更快一些
这也算是一个超参数了
title: exponentially weighted average 指数加权平均
y哇这个东西和互补滤波那个一样的,移动平均滤波里,y = theta * y(-1) + (1-theta)x(0)
这时候的y近似于前 1/(1-theta) 个数据的平均
这里以1/e为一个基准,判断这个数据有没有被算入平均
title: bias correction
一开始使用指数加权平均的时候,y(0) = 0会造成开始的那部分数据的偏差
那么把 y = y ( 1 - theta^t) t代表index,这种估计能把一开始的偏差给减少
title: gradient decent with momentum
Vdw(t = 0) = theta * Vdw(t= -1) + (1-theta)dw
Vdb(t = 0) = theta * Vdb(t = -1) + (1-theta)db
title: RMSprop
dw = dw / ||w||2
db = db / ||b||2
基本上效果都好于直接的梯度下降,举得例子的原理还是避免某个维度的梯度一直震荡的问题
title: Adam optimization (很多优化算法被提出,很多不general,adam被证明是比较general和效果好的
adam是momentua+RMSprop
theta参数分别有推荐值0.9,0.99
title: learning rate decay
为了避免在最后的部分的震荡和噪声
一种衰减模型learning rate: alpha = 1 / (1 + decay * iterationindex) * alpha(0)
也可以有其他的模型比如指数衰减
title: problem of local optimal
深度学习中,遇到的梯度为0的点,不太可能是极大极小或者最大最小值,而应该是鞍点,在某些维度上是极大,某些维度上极小
低维空间里的直觉并不都适用于高维空间
停滞区,导数一直为0的一块区域。算法会在停滞区消耗很长时间来找到下一个坡进行下降,这里我没怎么看懂其实。反正鞍点肯定是要越过去的把。
我们的算法遇到鞍点会停下吗?
---恢复内容结束---
第一周作业部分:
sigmoid with numpy, numpy操作对不同维度的数据都可以进行,以element-wise的模式
sigmoid的导数,sig = s, dervite = s* (1-s)
reshape((shape))
按行归一化,如果矩阵[[1,2],[3,4]], 先求x_norm = x_norm = np.linalg.norm(x,axis = 1, keepdims = True)
也就是[[sqrt(5)], [5]]这样一个列向量,然后矩阵除以norm,根据broadcasting的性质可以归一化
Note that np.dot() performs a matrix-matrix or matrix-vector multiplication. This is different from np.multiply() and the * operator (which is equivalent to .* in Matlab/Octave), which performs an element-wise multiplication.
np.dot是正常的矩阵乘法,multiply和乘号是元素是element-wise形式的乘法
L1 LOSS: loss = np.sum(abs(yhat - y))
L2 LOSS: loss = np.sum(np.square(yhat - y))
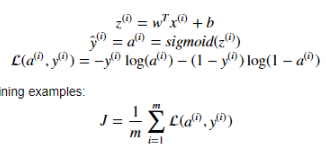
cross-entropy loss