GIN介绍
在很多信息中,我们会根据各种维度字段过滤数据,比如订单状态、渠道来源、客户状态等等。而在这些字段上创建btree索引会导致效率非常低下,一般在oracle中即使要创建索引,也是使用位图索引,或者不创建索引。
虽然pg中不存在位图索引,但是根据GIN的性质,它可以被认为本质上和位图索引无区别。通常用于某个字段包含不止一个KEY,又经常被作为查询条件的字段。
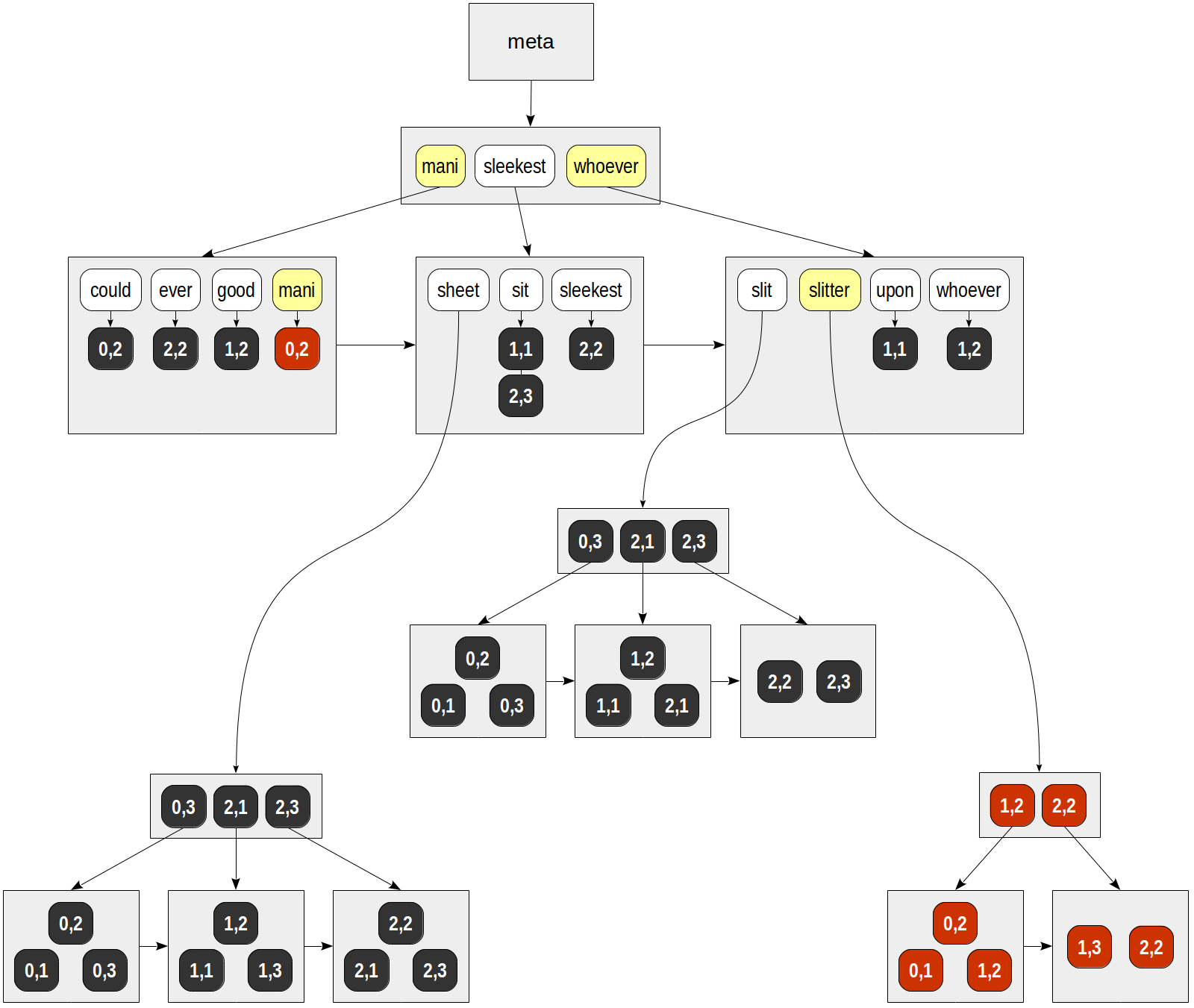
GIN本身叫做通用倒排索引,本身通过key->posting list/tree(pg索引中,如果一个key指向多个行,采用了一种列表数据结构叫做posting tree)实现。如下所示:
GIN索引默认支持JSON类型、数组类型,以及tsvector类型。PG内置了一个扩展btree_gin示例,可用于在多个字段上建立GIN索引,如下:
create table wide_table(id bigserial primary key,d_1_10 smallint,d_2_10 smallint,d_3_8 smallint,d_4_20 smallint,d_5_30 smallint,d_6_3 smallint,d_7_7 smallint,d_8_4 smallint,d_9_10 smallint,d_11_3 smallint,d_12_4 smallint,d_13_6 smallint,d_14_5 smallint,d_15_4 smallint,d_16_20 smallint,d_17_15 smallint,d_18_50 smallint,d_19_32 smallint,d_20_30 smallint,c_name varchar(50),c_desc varchar(50),c_en_name varchar(100)); insert into wide_table select x, ceil(random()*(11-1)+0), ceil(random()*(11-1)+0), ceil(random()*(9-1)+0), ceil(random()*(21-1)+0), ceil(random()*(31-1)+0), ceil(random()*(4-1)+0), ceil(random()*(8-1)+0), ceil(random()*(5-1)+0), ceil(random()*(11-1)+0), ceil(random()*(4-1)+0), ceil(random()*(5-1)+0), ceil(random()*(7-1)+0), ceil(random()*(6-1)+0), ceil(random()*(5-1)+0), ceil(random()*(21-1)+0), ceil(random()*(16-1)+0), ceil(random()*(51-1)+0), ceil(random()*(33-1)+0), ceil(random()*(31-1)+0), substr(uuid_generate_v4()::text,1,cast(ceil(random()*(16-1)+0) as int)), substr(uuid_generate_v4()::text,1,cast(ceil(random()*(32-1)+0) as int)), substr(uuid_generate_v4()::text,1,cast(ceil(random()*(50-1)+0) as int)) from generate_series(1,100000000) x; CREATE INDEX gin_idx_wide_table ON wide_table USING GIN (d_1_10 ,d_2_10 ,d_3_8 ,d_4_20 ,d_5_30 ,d_6_3 ,d_7_7 ,d_8_4 ,d_9_10 ,d_11_3 ,d_12_4 ,d_13_6 ,d_14_5 ,d_15_4 ,d_16_20 ,d_17_15 ,d_18_50 ,d_19_32 ,d_20_30) WITH (fastupdate = off); postgres=# explain select * from wide_table where d_2_10 in (2,4,5) and d_6_3 in (1,2) limit 10; QUERY PLAN ------------------------------------------------------------------------------------------------ Limit (cost=0.00..1.60 rows=10 width=94) -> Seq Scan on wide_table (cost=0.00..3197835.00 rows=19946097 width=94) Filter: ((d_6_3 = ANY ('{1,2}'::integer[])) AND (d_2_10 = ANY ('{2,4,5}'::integer[]))) (3 rows) postgres=# explain select * from wide_table where d_2_10 in (2,4,5) and d_6_3 in (1,2) and d_19_32 =3 limit 10; QUERY PLAN ------------------------------------------------------------------------------------------------------------------ Limit (cost=0.00..56.11 rows=10 width=94) -> Seq Scan on wide_table (cost=0.00..3447835.00 rows=614485 width=94) Filter: ((d_6_3 = ANY ('{1,2}'::integer[])) AND (d_19_32 = 3) AND (d_2_10 = ANY ('{2,4,5}'::integer[]))) (3 rows) postgres=# explain select * from wide_table where d_2_10 in (2,4,5) and d_6_3 in (1,2) and d_19_32 = 3 limit 10; QUERY PLAN ------------------------------------------------------------------------------------------------------------------ Limit (cost=0.00..56.11 rows=10 width=94) -> Seq Scan on wide_table (cost=0.00..3447835.00 rows=614485 width=94) Filter: ((d_6_3 = ANY ('{1,2}'::integer[])) AND (d_19_32 = 3) AND (d_2_10 = ANY ('{2,4,5}'::integer[]))) (3 rows) postgres=# explain select * from wide_table where d_2_10 in (2,4,5) and d_6_3 in (1,2) and d_19_32 = 3 order by id limit 10; QUERY PLAN ------------------------------------------------------------------------------------------------------------------ Limit (cost=0.57..69.28 rows=10 width=94) -> Index Scan using wide_table_pkey on wide_table (cost=0.57..4222023.57 rows=614485 width=94) Filter: ((d_6_3 = ANY ('{1,2}'::integer[])) AND (d_19_32 = 3) AND (d_2_10 = ANY ('{2,4,5}'::integer[]))) (3 rows) 上面的查询都没有走GIN索引
GIN在JSON方面的使用可参见postgresql----JSON类型、函数及全文检索的支持。
所以,GIN索引一般用于全文检索场景为主,其他场景默认使用较少。
GIN索引的缺点在于,每个文档通常包含许多要建立索引的词素。因此,当只添加或更新一个文档时,我们必须大规模地更新索引树。所以GIN索引中的数据插入或更新非常慢。适合于批处理场景,不适合于高密度的插入与更新,跟列式存储很像。
GIN索引有个选项fast update,用于支持快速更新,打开此参数后,更新将在一个单独的无序列表中累积(在各个连接的页上)。 当这个列表足够大或在vacuuming期间,所有累积的更新才会立即对索引进行。要考虑的列表«large enough»是由«gin_pending_list_limit»配置参数决定的,或者由索引的同名存储参数决定的。
这种方法也有缺点:首先,搜索速度变慢(因为除了树之外还需要查看无序列表),其次,如果无序列表已经溢出,下一次更新可能会意外地花费很多时间。
GIN对全文检索的支持
除了用于位图索引场景外,GIN还内置提供了对PG默认全文检索实现tsvector的支持,三方插件pg_trgm、hstore、btree_gin也支持GIN操作符,以前我们一般使用ES作为mysql/postgresql/oracle的全文检索前置,可参见Elasticsearch学习笔记、写给大忙人的Elasticsearch架构与概念,因为ES底层是使用java开发的,即使是主打搜索,因为理论相同,在pg 12版本后实现全文检索也不输给ES,包括数组字段、JSON字段以及中文搜索以及它们的组合。当然也有mongodb作为全文检索库的情况,不过基本上不如PG。对于全文检索引擎的选择,主要有下列依据:
- result relevance and ranking
- searching and indexing speed
- ease of use and ease of integration with java
- resource requirements – site will be hosted on a VPS, so ideally the search engine wouldn’t require a lot of RAM and CPU
- scalability
- EDIT: As for indexing needs, as users keep entering data into the site, those data would need to be indexed continuously. It doesn’t have to be real time, but ideally new data would show up in index with no more than 30 second delay
pg提供了很多函数用于全文检索,如:to_tsvector将文档解析为符号,并转化为词素或词位(词法分析是将输入内容分解为有意义的单词(也叫做词法分析记号(lexing tokens)或词位(lexemes))),然后返回词素在文档中的位置。如下:
SELECT to_tsvector('english', 'a fat cat sat on a mat - it ate a fat rats'); to_tsvector ----------------------------------------------------- 'ate':9 'cat':3 'fat':2,11 'mat':7 'rat':12 'sat':4 -- 它不同于纯粹的语法解析器,不需要记录字节偏移量
复数、过去式、进行时等会被统一处理为标准格式,the、a这些被去掉了,具体是否被忽略需要根据字典中被设置为忽略或包含或不存在而确定,字典列表可以参考https://www.postgresql.org/docs/current/textsearch-dictionaries.html。具体使用哪种解析器、哪种字典、哪些符号被索引是由全文检索配置确定的,这也是基础三大件。
setweight可以用来给tsvector中的词素或符号设置权重,权重分为A,B,C,D 4挡,一般也用于区分文档不同部分,如标题、正文,该信息最后被用于排序搜索结果,具体可见下文。
to_tsquery([ config regconfig, ] querytext text) returns tsquery:基于querytext创建tsquery值,当然querytext支持与、或、相邻、反等逻辑操作符。虽然还有其他函数如websearch_to_tsquery、plainto_tsquery(会进行解析和规范化,性能更低),但是to_tsquery最高效,querytext不需要二次处理。which accepts a list of words that will be checked against the normalized vector we created with to_tsvector(),即外部已做规范化。示例见下文。
创建全文检索索引:
CREATE INDEX idx_ts_gin ON test_ft USING GIN (to_tsvector('english',body)); -- 如果body本身就是tsvector,就不用加to_tsvector转换了。必须加'english'参数,不然受客户端参数default_text_search_config,默认是pg_catalog.simple影响,to_tsvector结果可变
安装中文词库,参考:https://github.com/hslightdb/zhparser。早期还有bamboo(基于mecab(基于CRF)做的中文分词,据说效果优于HMM,github上现在还有一个MeCab-Chinese,其介绍,15年之后也未更新了)
CREATE EXTENSION zhparser; CREATE TEXT SEARCH CONFIGURATION zhcfg (PARSER = zhparser); ALTER TEXT SEARCH CONFIGURATION zhcfg ADD MAPPING FOR n,v,a,i,e,l WITH simple;
一个全文检索实现包括4个部分:
- CREATE TEXT SEARCH PARSER — define a new text search parser,一般三方解析器实现的核心部分
- CREATE TEXT SEARCH CONFIGURATION — define a new text search configuration,依赖解析器,符号lex对应的字典以利于dictionary
- CREATE TEXT SEARCH DICTIONARY — define a new text search dictionary,依赖于模板 select * from pg_catalog.pg_ts_dict where dicttemplate = SIMPLE_TEMPALTE_ID;
- CREATE TEXT SEARCH TEMPLATE — define a new text search template,定义了初始化函数和lexize函数 select * from pg_catalog.pg_ts_template ptt; -- simple模板/字典对应的是src/backend/tsearch/dict_simple.c dsimple_init和dsimple_lexize函数
ALTER TABLE big_search_doc_new_ic ADD COLUMN tsvector_content tsvector GENERATED ALWAYS AS (to_tsvector('zhcfg', body)) STORED; -- PG 12的新特性 CREATE INDEX idx_tsvgin_content ON big_search_doc_new_ic USING GIN (tsvector_content);
select summary ,docid,filename from big_search_doc_new_ic sdni where sdni.tsvector_content @@ to_tsquery('恒顺') limit 20;
全文检索相关度与权重管理
全文检索默认的相关度算法使用BM25算法,与词频、逆文档频率高度相关。
除了搜索性能、索引更新性能、DML性能外,全文检索非常重要的一个功能就是权重管理。比如有多个字段支持全文检索,标题比正文权重高,最近日期的权重比更久远的权重高。当然各个字段都有个计算权重的公式,它不是简单的order by。
UPDATE tt SET ti = setweight(to_tsvector(coalesce(title,'')), 'A') || setweight(to_tsvector(coalesce(keyword,'')), 'B') || setweight(to_tsvector(coalesce(abstract,'')), 'C') || setweight(to_tsvector(coalesce(body,'')), 'D');
一般的做法动态计算列包含权重,如下:
ALTER TABLE se_details ADD COLUMN ts tsvector GENERATED ALWAYS AS (setweight(to_tsvector('english', coalesce(event_narrative, '')), 'A') || setweight(to_tsvector('english', coalesce(episode_narrative, '')), 'B')) STORED;
返回的结果和to_tsvector一样,也是一个tsvector,只不过它对每个词素都做了打分A或B,用于后面计算rank使用。
select ts from search_doc_new_ic sdni limit 10;
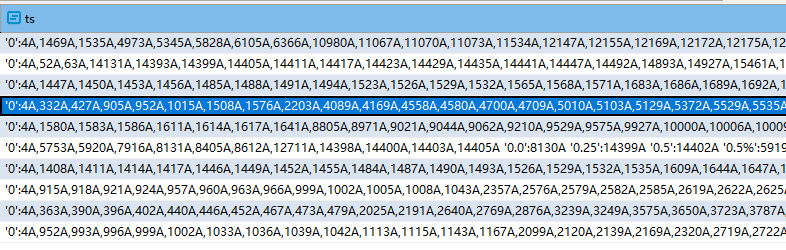
生成的每个tsvector语素之后都有一个权重A。所以一个tsvector只能设置一个权重,想要为标题、摘要、正文设置不同权重的话,就需要不同的字段。
PG的全文检索排序考虑了文档不同部分的权重、词素的精确程度、出现频率维度(TF和IDF,Term Frequency-Inverse Document Frequency, 词频-逆文件频率)来计算相关性,不同的应用有不同的算法,甚至考虑文档的时效性,内置的排序函数仅提供了参考,作为自定义的样例。
ts_rank([ weights float4[], ] vector tsvector, query tsquery [, normalization integer ]) returns float4 根据词素匹配相关性,normalization用于控制文档长度的影响。weights控制每种类别的单词的权重。is a score based on word frequency
ts_rank_cd([ weights float4[], ] vector tsvector, query tsquery [, normalization integer ]) returns float4。is based on frequency but also coverage distance - which is basically how far words are apart in a query。
ts_rank返回的是浮点数,具体公式要看实现(日后再补)。
SELECT ts_rank(ts, to_tsquery('english', 'tornado')),... ORDER BY ts_rank(ts, to_tsquery('english', 'tornado')) DESC;
select docid, industryname , reporttype, ts_rank(tsvector_content, f) x from search_doc_new_ic t, to_tsquery('东方 & 财智') f where tsvector_content @@ f order by x desc limit 10; docid |industryname|reporttype|x | --------------------------------+------------+----------+---------+ 0ea4e3e190a34d49a82ceeeca4cf1f3c| |其他研报 |0.9996409| 0ea4e3e190a34d49a82ceeeca4cf1f3c| |其他研报 |0.9996409| 0ea4e3e190a34d49a82ceeeca4cf1f3c| |其他研报 |0.9996409| 0ea4e3e190a34d49a82ceeeca4cf1f3c| |其他研报 |0.9996409| 0ea4e3e190a34d49a82ceeeca4cf1f3c| |其他研报 |0.9996409| 0ea4e3e190a34d49a82ceeeca4cf1f3c| |其他研报 |0.9996409| 0ea4e3e190a34d49a82ceeeca4cf1f3c| |其他研报 |0.9996409| 0ea4e3e190a34d49a82ceeeca4cf1f3c| |其他研报 |0.9996409| e533b6f0c53f44cc84e6b3deb81a74b5|电子 |策略研报 |0.9965925| e533b6f0c53f44cc84e6b3deb81a74b5|电子 |策略研报 |0.9965925|
因为权重需要访问每个符合条件的文档,因此性能很容易受到影响,大多数情况下,ts_rank足够。
下面来看一下一个由标题、摘要、正文组成的全文检索,标题权重A,摘要B,正文C。
其中日期就相当于应用了ES里面的相关度控制function_score,其中的boost_mode就是个逻辑函数,加减乘除、取大取小。
全文检索词库自定义
最后一个核心功能是,自定义词库,甚至不同的字段不同的词库。 因为很多公司、地点、流行词不在通用标注词库中,所以会降低搜索精确度,尤其是行业术语。所以,灵活、高效的调整词库、非中断式重建索引是很重要的。
网上有zhprs_sync_dict_xdb()、insert into pg_ts_custom_word values ('保障房资');、要确保使用的是2.0的新版本,从git下载最新,1.0没有这些函数和内置表。注:zhparser已经很久更新,https://github.com/hslightdb/zhparser会根据需要更新。
还有一种做法(正式的生产做法)是:
- 准备词库源文件 mydict.txt:词库文件的内容每一行的格式为
词 TF IDF 词性,词是必须的,而TF 词频(Term Frequency)、IDF 反文档频率(Inverse Document Frequency) 和 词性都是可选的,除非确定自己的词典资料是对的且符合 scws 的配置,不然最好还是留空,让 scws 自已确定;
TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文件频率)
是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF(计算相关度必备,否则不需要)是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。词频通常会被做归一化(TFNORM:token frequency normalized)
上述引用总结就是, 一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章.
https://blog.csdn.net/zrc199021/article/details/53728499很好地解释了TF-IDF。
根据TF-IDF的定义,词频和逆文档频率是动态计算的,为什么要填写?(jieba-analysis也包含了词频,通过分析com.huaban.analysis.jieba.JiebaSegmenter#calc可知,其用于计算基准词频,但是分词的时候没看到用到,因为SegToken只包含了位置、没有包含词频(PGWordEntryIN也没有包含,虽然词频和offset都是可以维护的)(逆文档频率是全局的,解析词库时没有意义)。es ik则没有这个字段) swcs内置的词库里面也包含了词频,如下:
# WORD TF IDF ATTR
帕克蒂亚 11.26 14.12 nr
雁门 13.33 14.19 ns
早退 13.52 8.34 v
胭脂粉 12.61 11.24 n
熟道 11.19 13.55 n
七宝池 12.22 12.08 nz
罕有 13.65 7.96 a
交城 13.12 15.06 nr
警卫车 10.25 15.41 n
空子 13.65 7.97 n
吉永 12.69 10.48 nr
侧门 13.36 8.79 n唯一有参考的是《现代汉语频率词典》,但是对不上。需要看scws源码来确定。
2. 在 postgresql.conf 中设置 zhparser.extra_dicts = "mydict.txt" ,可选的设置 zhparser.dict_in_memory = true;
例如:mydict.txt包含如下。
“词语"(由中文字或3个以下的字母合成), "TF", "IDF", "词性"
恒生电子 1.0 1.0 @ 黄金杠杆合约 1.0 1.0 @ ⅲ类账户 1.0 1.0 @
重启pg或lightdb实例。
再查询:
SELECT * FROM ts_parse('zhparser', '为什么NVMe/TCP是数据中心的更优选择恒黄金杠杆合约生电子股份有限公ⅲ类账户司在杭州滨江');
tokid|token|
-----+-----+
114|为什么 |
101|NVMe |
117|/ |
101|TCP |
118|是 |
110|数据中心 |
117|的 |
100|更 |
110|优 |
118|选择 |
110|恒 |
110|黄金 |
110|杠杆 |
110|合约 |
118|生 |
110|电子 |
108|股份有限 |
98|公 |
117|ⅲ |
110|类 |
110|账户 |
110|司 |
112|在 |
110|杭州 |
110|滨江 |
SELECT * FROM to_tsquery('testzhcfg', '为什么NVMe/TCP是数据中心的更优选择恒黄金杠杆合约生电子股份有限公ⅲ类账户司在杭州滨江');
to_tsquery |
----------------------------------------------------------------------------------------------------------------------------+
'nvme' & 'tcp' & '是' & '数据中心' & '优' & '选择' & '恒' & '黄金' & '杠杆' & '合约' & '生' & '电子' & '股份有限' & '类' & '账户' & '司' & '杭州' & '滨江'|
SELECT * FROM to_tsvector('testzhcfg', '恒生电子股份有限公司在杭州滨江');
to_tsvector |
-------------------------------------------+
'恒生':1 '有限公司':4 '杭州':5 '滨江':6 '电子':2 '股份':3|
3. 标准词库可以在创建好文本词库后,使用工具phptool_for_scws_xdb(需要安装php,连接中已打包windows绿色版,链接:https://pan.baidu.com/s/1OTietRQEGNdvHduHOhClzA 提取码: nn2c )生成。如下所示:
1. 词典导出:dump_xdb_file.php 在命令行模式下运行
php dump_xdb_file.php <要导出的.xdb文件> [存入的文本文件]
第二参数省略则直接输出到标准输出。
2. 词典生成:make_xdb_file.php 同样是在命令行模式下运行(需要安装 mbstring 扩展)
默认是处理 gbk 编码的文本,如果你的文本是 utf8,则需要修改该程序的第一行,把
define('IS_UTF8_TXT', false); 改为 true
php make_xdb_file.php <要生成的.xdb> [导入的文本文件]
高亮搜索结果部分
ts_headline([ config regconfig, ] document text, query tsquery [, options text ]) returns text
SELECT ts_headline('English','This Commercial Bank does not have any Equity in Europe but European Commercial Bank does', phraseto_tsquery('English','European Commercial Bank')::tsquery); ts_headline | ----------------------------------------------------------------------------------------------------------------------------+ This <b>Commercial</b> <b>Bank</b> does not have any Equity in Europe but <b>European</b> <b>Commercial</b> <b>Bank</b> does|
中文的话,必须加上config,即zhcfg。
select docid,industryname ,reporttype,ts_headline('zhcfg',content, to_tsquery('报告'),'StartSel=<b>, StopSel=</b>,HighlightAll=TRUE') from search_doc_new_ic t
where tsvector_content @@ to_tsquery('报告')
-- order by ts_rank(tsvector_content,'参阅 & 声明')
limit 10;
--- 默认选项为:
StartSel=<b>, StopSel=</b>,
MaxWords=35, MinWords=15, ShortWord=3, HighlightAll=FALSE,
MaxFragments=0, FragmentDelimiter=" ... "
docid |industryname|reporttype|ts_headline | --------------------------------+------------+----------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ a03d8d77ffce4a87b03ddfe3af68339c|公用事业 |行业研报 |[{"page_no":0,"paragraphs":["","敬请参阅<b>报告</b>结尾处的免责声明东方财智兴盛之源","DONGXINGSECURITIES","行 业 研 究","","东 兴 证 券 股 份 有 限 公 司 证 券 研 究 报 告","","公用事业及环保行业:《固废法》修 订通过,环保攻坚战持续发力"," 2020年05月06日"," 看好/维持"," 公用事业及环保行业报告","","","投资摘要:","4月29日,十三届全| a03d8d77ffce4a87b03ddfe3af68339c|公用事业 |行业研报 |[{"page_no":0,"paragraphs":["","敬请参阅<b>报告</b>结尾处的免责声明东方财智兴盛之源","DONGXINGSECURITIES","行 业 研 究","","东 兴 证 券 股 份 有 限 公 司 证 券 研 究 报 告","","公用事业及环保行业:《固废法》修 订通过,环保攻坚战持续发力"," 2020年05月06日"," 看好/维持"," 公用事业及环保行业报告","","","投资摘要:","4月29日,十三届全| a03d8d77ffce4a87b03ddfe3af68339c|公用事业 |行业研报 |[{"page_no":0,"paragraphs":["","敬请参阅<b>报告</b>结尾处的免责声明东方财智兴盛之源","DONGXINGSECURITIES","行 业 研 究","","东 兴 证 券 股 份 有 限 公 司 证 券 研 究 报 告","","公用事业及环保行业:《固废法》修 订通过,环保攻坚战持续发力"," 2020年05月06日"," 看好/维持"," 公用事业及环保行业报告","","","投资摘要:","4月29日,十三届全| fcb891c18df747b3ab32c3fde1266d0a| |其他研报 |[{"page_no":0,"paragraphs":["优塾:发布于2020.6.24财务分析和财务建模领域专业研究机构","","帝欧家居财务建模工程经销齐发力","","","今天,我们建模的这家公司,于2016年5月上市,连拉19个涨停板,从4.25元/股,上涨至32.8元/股,涨幅670%。但是,更加夺人眼球的是,其上市5个月,就宣布停牌筹划重大资产重组,而且并购标的的体量是其3倍,如果收购成功,算得上不折不扣的蛇吞象。","","","图:股价(单位:元)","来源:wind","","201| a03d8d77ffce4a87b03ddfe3af68339c|公用事业 |行业研报 |[{"page_no":0,"paragraphs":["","敬请参阅<b>报告</b>结尾处的免责声明东方财智兴盛之源","DONGXINGSECURITIES","行 业 研 究","","东 兴 证 券 股 份 有 限 公 司 证 券 研 究 报 告","","公用事业及环保行业:《固废法》修 订通过,环保攻坚战持续发力"," 2020年05月06日"," 看好/维持"," 公用事业及环保行业报告","","","投资摘要:","4月29日,十三届全| b43f0a804646451cb1ac3cd7ee5b9e48|有色金属 |行业研报 |[{"page_no":0,"paragraphs":["","","","","","最近一年行业指数走势","","-15%","-7%","0%","7%","15%","22%","29%","37%","2019-052019-092020-01","上证指数深证成指","事 件 点 评","","公 司 研 究","","财 通 证 券 研 究 所","","","投资评级:增持(维持)","","表1:重点公司投资评级","代码公司","总市值","(亿元)","收盘| b43f0a804646451cb1ac3cd7ee5b9e48|有色金属 |行业研报 |[{"page_no":0,"paragraphs":["","","","","","最近一年行业指数走势","","-15%","-7%","0%","7%","15%","22%","29%","37%","2019-052019-092020-01","上证指数深证成指","事 件 点 评","","公 司 研 究","","财 通 证 券 研 究 所","","","投资评级:增持(维持)","","表1:重点公司投资评级","代码公司","总市值","(亿元)","收盘| b43f0a804646451cb1ac3cd7ee5b9e48|有色金属 |行业研报 |[{"page_no":0,"paragraphs":["","","","","","最近一年行业指数走势","","-15%","-7%","0%","7%","15%","22%","29%","37%","2019-052019-092020-01","上证指数深证成指","事 件 点 评","","公 司 研 究","","财 通 证 券 研 究 所","","","投资评级:增持(维持)","","表1:重点公司投资评级","代码公司","总市值","(亿元)","收盘| a03d8d77ffce4a87b03ddfe3af68339c|公用事业 |行业研报 |[{"page_no":0,"paragraphs":["","敬请参阅<b>报告</b>结尾处的免责声明东方财智兴盛之源","DONGXINGSECURITIES","行 业 研 究","","东 兴 证 券 股 份 有 限 公 司 证 券 研 究 报 告","","公用事业及环保行业:《固废法》修 订通过,环保攻坚战持续发力"," 2020年05月06日"," 看好/维持"," 公用事业及环保行业报告","","","投资摘要:","4月29日,十三届全| b43f0a804646451cb1ac3cd7ee5b9e48|有色金属 |行业研报 |[{"page_no":0,"paragraphs":["","","","","","最近一年行业指数走势","","-15%","-7%","0%","7%","15%","22%","29%","37%","2019-052019-092020-01","上证指数深证成指","事 件 点 评","","公 司 研 究","","财 通 证 券 研 究 所","","","投资评级:增持(维持)","","表1:重点公司投资评级","代码公司","总市值","(亿元)","收盘|
单字匹配问题
出现单字匹配的原因是字典里面就包含了单字,所以生成的tsvector就包含单字语素,因此在ts_query的时候自然也就有这个情况,不仅影响结果,单字也影响的索引、搜索的速度,LightDB 21.2将包含三种选项:包含单字、不包含单字、不包含特定单字。
性能优化
对全文检索来说,GIN索引和动态生成列是不可或缺的。字典最小化也是不可或缺的,尤其是单字。
GIN indexes are not lossy for standard queries, but their performance depends logarithmically on the number of unique words. (However, GIN indexes store only the words (lexemes) of tsvector values, and not their weight labels. Thus a table row recheck is needed when using a query that involves weights.)
In choosing which index type to use, GiST、GIN or BRIN, consider these performance differences:
- GIN index lookups are about three times faster than GiST
- GIN indexes take about three times longer to build than GiST
- GIN indexes are moderately slower to update than GiST indexes, but about 10 times slower if fast-update support was disabled (see GIN Fast Update Technique in the PostgreSQL documentation for details)
- GIN indexes are two-to-three times larger than GiST indexes
- BRIN store summaries about the values stored in consecutive physical block ranges of a table, index For data types that have a linear sort order, the indexed data corresponds to the minimum and maximum values of the values in the column for each block range.
As a rule of thumb, GIN indexes are best for static data because lookups are faster. For dynamic data, GiST indexes are faster to update. Specifically, GiST indexes are very good for dynamic data and fast if the number of unique words (lexemes) is under 100,000, while GIN indexes will handle 100,000+ lexemes better but are slower to update.
Note that GIN index build time can often be improved by increasing maintenance_work_mem, while GiST index build time is not sensitive to that parameter.
Partitioning of big collections and the proper use of GiST and GIN indexes allows the implementation of very fast searches with online update. Partitioning can be done at the database level using table inheritance, or by distributing documents over servers and collecting search results using dblink. The latter is possible because ranking functions use only local information.
pg对TF和IDF的支持
在当前版本的默认实现中,pg仅采用了TF,没有采用IDF,但是smlar插件(RDS和阿里商品导购平台都采用这个搜索技术)支持类似IDF的特性。可参见:
https://machinelearnit.com/2019/06/10/1332/ 功能比较、但是明显作者对PG不够掌握
https://stackoverflow.com/questions/18296444/does-postgresql-use-tf-idf
https://www.sohu.com/a/163084568_612370
https://partners-intl.aliyun.com/help/doc-detail/164554.htm
https://programming.vip/docs/massive-data-smlar-aliyun-rds-posgresql-best-practice.html
zhparser全文检索词库的底层实现scws
zhparser底层是通过调用scws库实现的,主要的对外接口封装在TEXT SEARCH PARSER中,包括start、gettoken、end、lextypes。如下:
CREATE FUNCTION zhprs_start(internal, int4) RETURNS internal AS 'MODULE_PATHNAME' LANGUAGE C STRICT; CREATE FUNCTION zhprs_getlexeme(internal, internal, internal) RETURNS internal AS 'MODULE_PATHNAME' LANGUAGE C STRICT; CREATE FUNCTION zhprs_end(internal) RETURNS void AS 'MODULE_PATHNAME' LANGUAGE C STRICT; CREATE FUNCTION zhprs_lextype(internal) RETURNS internal AS 'MODULE_PATHNAME' LANGUAGE C STRICT; CREATE TEXT SEARCH PARSER zhparser ( START = zhprs_start, GETTOKEN = zhprs_getlexeme, END = zhprs_end, HEADLINE = pg_catalog.prsd_headline, LEXTYPES = zhprs_lextype );
Datum zhprs_start(PG_FUNCTION_ARGS) { ParserState *pst = &parser_state; int multi_mode = 0x0; if(scws == NULL) init(); pst -> scws = scws; pst -> buffer = (char *) PG_GETARG_POINTER(0); pst -> len = PG_GETARG_INT32(1); pst -> pos = 0; scws_set_ignore(scws, (int)punctuation_ignore); scws_set_duality(scws,(int)seg_with_duality); if(multi_short){ multi_mode |= SCWS_MULTI_SHORT; } if(multi_duality){ multi_mode |= SCWS_MULTI_DUALITY; } if(multi_zmain){ multi_mode |= SCWS_MULTI_ZMAIN; } if(multi_zall){ multi_mode |= SCWS_MULTI_ZALL; } scws_set_multi(scws,multi_mode); scws_send_text(pst -> scws, pst -> buffer, pst -> len); (pst -> head) = (pst -> curr) = scws_get_result(pst -> scws); PG_RETURN_POINTER(pst); } Datum zhprs_getlexeme(PG_FUNCTION_ARGS) { ParserState *pst = (ParserState *) PG_GETARG_POINTER(0); char **t = (char **) PG_GETARG_POINTER(1); int *tlen = (int *) PG_GETARG_POINTER(2); int type = -1; if((pst -> head) == NULL ) /* already done the work,or no sentence */ { *tlen = 0; type = 0; } /* have results */ else if(pst -> curr != NULL) { scws_res_t curr = pst -> curr; /* * check the first char to determine the lextype * if out of [0,25],then set to 'x',mean unknown type * so for Ag,Dg,Ng,Tg,Vg,the type will be unknown * for full attr explanation,visit http://www.xunsearch.com/scws/docs.php#attr */ type = (int)(curr -> attr)[0]; if(type > (int)'x' || type < (int)'a') type = (int)'x'; *tlen = curr -> len; *t = pst -> buffer + curr -> off; pst -> curr = curr -> next; /* fetch the next sentence */ if(pst -> curr == NULL ){ scws_free_result(pst -> head); (pst -> head) = (pst -> curr) = scws_get_result(pst -> scws); } } PG_RETURN_INT32(type); } Datum zhprs_end(PG_FUNCTION_ARGS) { PG_RETURN_VOID(); } Datum zhprs_lextype(PG_FUNCTION_ARGS) { LexDescr *descr = (LexDescr *) palloc(sizeof(LexDescr) * (26 + 1)); init_type(descr); PG_RETURN_POINTER(descr); }
对应各个函数为c函数,各zhparser函数里面的实现调用scws库的函数,所以全文检索解析(搜索本身那是GIN和tsvector的实现,跟scws无关,后续有空研究搜索和GIN存储)实现都在scws中,zhparser就是做了一下封装。如下:
SCWS 自带函数详解
mixed scws_new(void)
功能: 创建并返回一个 SimpleCWS 类操作对象。
返回值: 成功返回类操作句柄,失败返回 false。
mixed scws_open(void)
功能: 创建并返回一个分词操作句柄。
返回值: 成功返回 scws 操作句柄,失败返回 false。
bool scws_close(resource scws_handle)
功能: 关闭一个已打开的 scws 分词操作句柄。
参数: scws_handle 即之前由 scws_open 打开的返回值。
返回值: 始终为 true
bool scws_set_charset(resource scws_handle, string charset)
功能: 设定分词词典、规则集、欲分文本字符串的字符集。
参数: charset 要新设定的字符集,只支持 utf8 和 gbk。(默认为 gbk,utf8不要写成utf-8)。
返回值: 始终为 true
bool scws_add_dict(resource scws_handle, string dict_path [, int mode])
功能: 添加分词所用的词典,新加入的优先查找。
参数: dict_path 词典的路径,可以是相对路径或完全路径(遵循安全模式下的 open_basedir)。
参数: mode 可选,表示加载的方式,其值有:
- SCWS_XDICT_TXT 表示要读取的词典文件是文本格式,可以和后2项结合用
- SCWS_XDICT_XDB 表示直接读取 xdb 文件(此为默认值)
- SCWS_XDICT_MEM 表示将 xdb 文件全部加载到内存中,以 XTree 结构存放,可用异或结合另外2个使用。
返回值: 成功返回 true 失败返回 false
bool scws_set_dict(resource scws_handle, string dict_path [, int mode])
功能: 设定分词所用的词典并清除已存在的词典列表
参数: dict_path 词典的路径,可以是相对路径或完全路径(遵循安全模式下的 open_basedir)。
参数: mode 可选,表示加载的方式。参见 scws_add_dict
返回值: 成功返回 true 失败返回 false
bool scws_set_rule(resource scws_handle, string rule_path)
功能: 设定分词所用的新词识别规则集(用于人名、地名、数字时间年代等识别)。
参数: rule_path 规则集的路径,可以是相对路径或完全路径(遵循安全模式下的 open_basedir)。
参数: mode 表示加载的方式。参见 scws_add_dict
返回值: 成功返回 true 失败返回 false
bool scws_set_ignore(resource scws_handle, bool yes)
功能: 设定分词返回结果时是否去除一些特殊的标点符号之类。
参数: yes 如果为 true 则结果中不返回标点符号,如果为 false 则会返回,缺省为 false。
返回值: 始终为 true
bool scws_set_multi(resource scws_handle, int mode)
功能: 设定分词返回结果时是否复式分割,如“中国人”返回“中国+人+中国人”三个词。
参数: mode 复合分词法的级别,缺省不复合分词。取值由下面几个常量异或组合(也可用 1-15 来表示):
- SCWS_MULTI_SHORT (1)短词
- SCWS_MULTI_DUALITY (2)二元(将相邻的2个单字组合成一个词)
- SCWS_MULTI_ZMAIN (4)重要单字
- SCWS_MULTI_ZALL (8)全部单字
返回值: 始终为 true
bool scws_set_duality(resource scws_handle, bool yes)
功能: 设定是否将闲散文字自动以二字分词法聚合
参数: yes 设定值,如果为 true 则结果中多个单字会自动按二分法聚分,如果为 false 则不处理,缺省为 false。
返回值: 始终为 true
bool scws_send_text(resource scws_handle, string text)
功能: 发送设定分词所要切割的文本。
参数: text 要切分的文本的内容。
返回值: 成功返回 true 失败返回 false
注意: 系统底层处理方式为对该文本增加一个引用,故不论多长的文本并不会造成内存浪费;执行本函数时,若未加载任何词典和规则集,则会自动试图在 ini 指定的缺省目录下查找缺省字符集的词典和规则集。
mixed scws_get_result(resource scws_handle)
功能: 根据 send_text 设定的文本内容,返回一系列切好的词汇。
返回值: 成功返回切好的词汇组成的数组,若无更多词汇,返回 false。返回的词汇包含的键值如下:
- word string 词本身
- idf float 逆文本词频
- off int 该词在原文本路的位置
- attr string 词性
注意: 每次切词后本函数应该循环调用,直到返回 false 为止,因为程序每次返回的词数是不确定的。
mixed scws_get_tops(resource scws_handle [, int limit [, string attr]])
功能: 根据 send_text 设定的文本内容,返回系统计算出来的最关键词汇列表。
参数: limit 可选参数,返回的词的最大数量,缺省是 10 。
参数: attr 可选参数,是一系列词性组成的字符串,各词性之间以半角的逗号隔开,这表示返回的词性必须在列表中,如果以~开头,则表示取反,词性必须不在列表中,缺省为NULL,返回全部词性,不过滤。
返回值: 成功返回统计好的的词汇组成的数组,返回 false。返回的词汇包含的键值如下:
- word string 词本身
- times int 词在文本中出现的次数
- weight float 该词计算后的权重
- attr string 词性
mixed scws_get_words(resource scws_handle, string attr)
功能: 根据 send_text 设定的文本内容,返回系统中词性符合要求的关键词汇。
参数: attr 是一系列词性组成的字符串,各词性之间以半角的逗号隔开,这表示返回的词性必须在列表中,如果以~开头,则表示取反,词性必须不在列表中,若为空则返回全部词。
返回值: 成功返回符合要求词汇组成的数组,返回 false。返回的词汇包含的键值参见 scws_get_result
bool scws_has_word(resource scws_handle, string attr)
功能: 根据 send_text 设定的文本内容,返回系统中是否包括符合词性要求的关键词。
参数: attr 是一系列词性组成的字符串,各词性之间以半角的逗号隔开,这表示返回的词性必须在列表中,如果以~开头,则表示取反,词性必须不在列表中,若为空则返回全部词。
返回值: 如果有则返回 true,没有就返回 false。
string scws_version(void)
功能: 返回 scws 版本号名称信息(字符串)。
返回值: 返回string,scws 版本号名称信息。
=======================
测试分词可以通过select to_tsvector('zhcfg','2021年中华人民共和国国庆');,因为to_tsvector是内置函数,所以通过to_tsany.c中的to_tsvector_byid函数进入,其又调用ts_parse.c的parsetext(Oid cfgId, ParsedText *prs, char *buf, int buflen)函数进行分词解析,根据传递的cfgId调用通过函数指针调用上述zhparser的start、getlexeme、end函数。如下:
/* * Parse string and lexize words. * * prs will be filled in. */ void parsetext(Oid cfgId, ParsedText *prs, char *buf, int buflen) { int type, lenlemm; char *lemm = NULL; LexizeData ldata; TSLexeme *norms; TSConfigCacheEntry *cfg; TSParserCacheEntry *prsobj; void *prsdata; cfg = lookup_ts_config_cache(cfgId); prsobj = lookup_ts_parser_cache(cfg->prsId); prsdata = (void *) DatumGetPointer(FunctionCall2(&prsobj->prsstart, PointerGetDatum(buf), Int32GetDatum(buflen))); LexizeInit(&ldata, cfg); do { type = DatumGetInt32(FunctionCall3(&(prsobj->prstoken), PointerGetDatum(prsdata), PointerGetDatum(&lemm), PointerGetDatum(&lenlemm))); if (type > 0 && lenlemm >= MAXSTRLEN) { #ifdef IGNORE_LONGLEXEME ereport(NOTICE, (errcode(ERRCODE_PROGRAM_LIMIT_EXCEEDED), errmsg("word is too long to be indexed"), errdetail("Words longer than %d characters are ignored.", MAXSTRLEN))); continue; #else ereport(ERROR, (errcode(ERRCODE_PROGRAM_LIMIT_EXCEEDED), errmsg("word is too long to be indexed"), errdetail("Words longer than %d characters are ignored.", MAXSTRLEN))); #endif } LexizeAddLemm(&ldata, type, lemm, lenlemm); while ((norms = LexizeExec(&ldata, NULL)) != NULL) { TSLexeme *ptr = norms; prs->pos++; /* set pos */ while (ptr->lexeme) { if (prs->curwords == prs->lenwords) { prs->lenwords *= 2; prs->words = (ParsedWord *) repalloc((void *) prs->words, prs->lenwords * sizeof(ParsedWord)); } if (ptr->flags & TSL_ADDPOS) prs->pos++; prs->words[prs->curwords].len = strlen(ptr->lexeme); prs->words[prs->curwords].word = ptr->lexeme; prs->words[prs->curwords].nvariant = ptr->nvariant; prs->words[prs->curwords].flags = ptr->flags & TSL_PREFIX; prs->words[prs->curwords].alen = 0; prs->words[prs->curwords].pos.pos = LIMITPOS(prs->pos); ptr++; prs->curwords++; } pfree(norms); } } while (type > 0); FunctionCall1(&(prsobj->prsend), PointerGetDatum(prsdata)); }
重复词素合并工作是在pg ts中统一实现的,在make_tsvector中。
Datum to_tsvector_byid(PG_FUNCTION_ARGS) { Oid cfgId = PG_GETARG_OID(0); text *in = PG_GETARG_TEXT_PP(1); ParsedText prs; TSVector out; prs.lenwords = VARSIZE_ANY_EXHDR(in) / 6; /* just estimation of word's * number */ if (prs.lenwords < 2) prs.lenwords = 2; prs.curwords = 0; prs.pos = 0; prs.words = (ParsedWord *) palloc(sizeof(ParsedWord) * prs.lenwords); parsetext(cfgId, &prs, VARDATA_ANY(in), VARSIZE_ANY_EXHDR(in)); PG_FREE_IF_COPY(in, 1); out = make_tsvector(&prs); PG_RETURN_TSVECTOR(out); } /* * make value of tsvector, given parsed text * * Note: frees prs->words and subsidiary data. */ TSVector make_tsvector(ParsedText *prs) { int i, j, lenstr = 0, totallen; TSVector in; WordEntry *ptr; char *str; int stroff; /* Merge duplicate words */ if (prs->curwords > 0) prs->curwords = uniqueWORD(prs->words, prs->curwords); /* Determine space needed */ for (i = 0; i < prs->curwords; i++) { lenstr += prs->words[i].len; if (prs->words[i].alen) { lenstr = SHORTALIGN(lenstr); lenstr += sizeof(uint16) + prs->words[i].pos.apos[0] * sizeof(WordEntryPos); } } if (lenstr > MAXSTRPOS) ereport(ERROR, (errcode(ERRCODE_PROGRAM_LIMIT_EXCEEDED), errmsg("string is too long for tsvector (%d bytes, max %d bytes)", lenstr, MAXSTRPOS))); totallen = CALCDATASIZE(prs->curwords, lenstr); in = (TSVector) palloc0(totallen); SET_VARSIZE(in, totallen); in->size = prs->curwords; ptr = ARRPTR(in); str = STRPTR(in); stroff = 0; for (i = 0; i < prs->curwords; i++) { ptr->len = prs->words[i].len; ptr->pos = stroff; memcpy(str + stroff, prs->words[i].word, prs->words[i].len); stroff += prs->words[i].len; pfree(prs->words[i].word); if (prs->words[i].alen) { int k = prs->words[i].pos.apos[0]; WordEntryPos *wptr; if (k > 0xFFFF) elog(ERROR, "positions array too long"); ptr->haspos = 1; stroff = SHORTALIGN(stroff); *(uint16 *) (str + stroff) = (uint16) k; wptr = POSDATAPTR(in, ptr); for (j = 0; j < k; j++) { WEP_SETWEIGHT(wptr[j], 0); WEP_SETPOS(wptr[j], prs->words[i].pos.apos[j + 1]); } stroff += sizeof(uint16) + k * sizeof(WordEntryPos); pfree(prs->words[i].pos.apos); } else ptr->haspos = 0; ptr++; } if (prs->words) pfree(prs->words); return in; }
这样整个完整的分词解析过程就很清晰了。
问题
word is too long to be indexed,点击取消后报:SQL 错误 [25P02]: ERROR: current transaction is aborted, commands ignored until end of transaction block
解决方法:先对text字段to_tsvector,单独字段存储。然后执行查询。
https://www.postgresql.org/docs/current/textsearch-controls.html
https://www.postgresql.org/docs/current/textsearch-debugging.html --调试ts
https://www.cnblogs.com/zhenbianshu/p/7795247.html
https://github.com/hslightdb/zhparser
https://www.postgresql.org/docs/13/sql-altertsconfig.html
https://www.compose.com/articles/mastering-postgresql-tools-full-text-search-and-phrase-search/
生产案例 https://www.skypyb.com/2020/12/jishu/1705/?ivk_sa=1021577g
基于CRF的中文分词 https://blog.csdn.net/weixin_33909059/article/details/86057099
CRF简介入门 https://blog.csdn.net/noter16/article/details/52439918