早上10点左右,某台线上ECS服务器突然没响应。
查看日志,发现如下信息:
Aug 14 03:26:01 localhost rsyslogd: [origin software="rsyslogd" swVersion="5.8.10" x-pid="861" x-info="http://www.rsyslog.com"] rsyslogd was HUPed
Aug 16 09:54:19 localhost kernel: INFO: task mysqld:26208 blocked for more than 120 seconds.
Aug 16 09:54:29 localhost kernel: Not tainted 2.6.32-431.23.3.el6.x86_64 #1
Aug 16 09:54:29 localhost kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
Aug 16 09:54:29 localhost kernel: mysqld D 0000000000000003 0 26208 25840 0x00000000
Aug 16 09:54:29 localhost kernel: ffff8802097d1cc8 0000000000000082 0000000000000000 ffffffff8114a2e9
Aug 16 09:54:29 localhost kernel: 00000001de00c025 0000000000000000 0000000000000000 ffffea00071a1df0
Aug 16 09:54:29 localhost kernel: ffff88020963daf8 ffff8802097d1fd8 000000000000fbc8 ffff88020963daf8
Aug 16 09:54:29 localhost kernel: Call Trace:
Aug 16 09:54:29 localhost kernel: [<ffffffff8114a2e9>] ? __do_fault+0x469/0x530
Aug 16 09:54:29 localhost kernel: [<ffffffff8111f7e0>] ? sync_page+0x0/0x50
Aug 16 09:54:29 localhost kernel: [<ffffffff81529393>] io_schedule+0x73/0xc0
Aug 16 09:54:29 localhost kernel: [<ffffffff8111f81d>] sync_page+0x3d/0x50
Aug 16 09:54:29 localhost kernel: [<ffffffff81529e5f>] __wait_on_bit+0x5f/0x90
经查,是linux自身的一个限制所致:
By default Linux uses up to 40% of the available memory for file system caching. After this mark has been reached the file system flushes all outstanding data to disk causing all following IOs going synchronous. For flushing out this data to disk this there is a time limit of 120 seconds by default. In the case here the IO subsystem is not fast enough to flush the data withing 120 seconds.
看了下sar -r内存历史,如下:
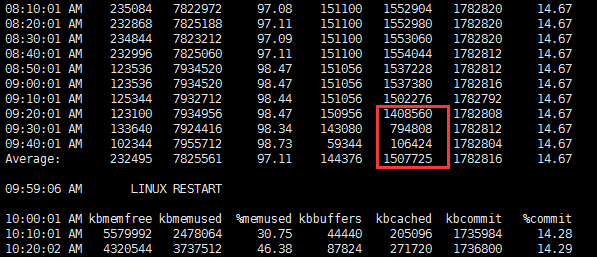
基本上可以认为确实为此问题导致。
缓解此问题的方法:
vim /etc/sysctrl.conf
vm.dirty_background_ratio = 5
vm.dirty_ratio = 10
因为是专用mysql服务器,故方法是适用的。
这个问题在实体机发生的概率应该是非常低的,在虚拟机中概率估计大大增加。