先了解下面几个概念:
a container
an iterable
an iterator
a generator
a generator expression
a {list, set, dict} comprehension
在了解Python的数据结构时,容器(container)、可迭代对象(iterable)、迭代器(iterator)、生成器(generator)、列表/集合/字典推导式(list,set,dict comprehension)众多概念参杂在一起,现在看一下这张图:
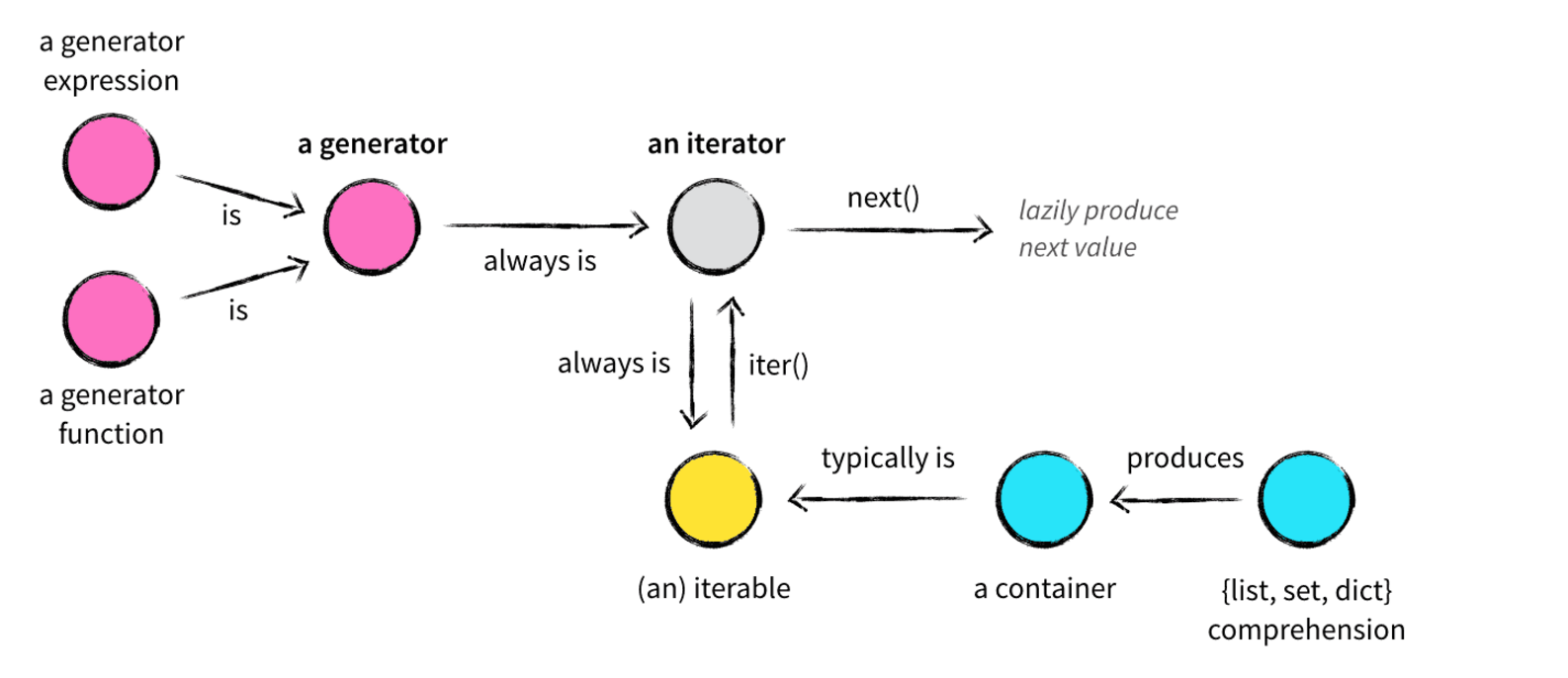
容器(container)
容器是一种把多个元素组织在一起的数据结构,容器中的元素可以逐个地迭代获取,可以用 in , not in 关键字判断元素是否包含在容器中。通常这类数据结构把所有的元素存储在内存中(也有一些特列并不是所有的元素都放在内存)在Python中,常见的容器对象有:
list, deque, ....
set, frozensets, ....
dict, defaultdict, OrderedDict, Counter, ....
tuple, namedtuple, …
str
从技术角度来说,当它可以用来询问某个元素是否包含在其中时,那么这个对象就可以认为是一个容器。可以对列表、集合或元组进行类似的成员测试::
>>> assert 1 in [1, 2, 3] # lists
>>> assert 4 not in [1, 2, 3]
>>> assert 1 in {1, 2, 3} # sets
>>> assert 4 not in {1, 2, 3}
>>> assert 1 in (1, 2, 3) # tuples
>>> assert 4 not in (1, 2, 3)
assert:
一般用法:
assert condition
用来让程序测试这个condition,如果condition为false,那么raise一个AssertionError出来。逻辑上等同于:
if not condition:
raise AssertionError()
询问某元素是否在dict中用dict的中key:
>>> d = {1: 'foo', 2: 'bar', 3: 'qux'}
>>> assert 1 in d
>>> assert 'foo' not in d # 'foo' 不是dict中的元素
询问某substring是否在string中:
>>> s = 'foobar'
>>> assert 'b' in s
>>> assert 'x' not in s
>>> assert 'foo' in s
尽管绝大多数容器都提供了某种方式来获取其中的每一个元素,但这并不是容器本身提供的能力,而是 可迭代对象 赋予了容器这种能力,当然并不是所有的容器都是可迭代的。
可迭代对象(iterable)
如果给定一个list或tuple,我们可以通过for循环来遍历这个list或tuple,这种遍历我们称为迭代(Iteration)。
刚才说过,很多容器都是可迭代对象,此外还有更多的对象同样也是可迭代对象,比如处于打开状态的files,sockets等等。但凡是可以返回一个 迭代器 的对象都可称之为可迭代对象,听起来可能有点困惑,没关系,可迭代对象与迭代器有一个非常重要的区别。先看一个例子:

这里 x 是一个可迭代对象,可迭代对象和容器一样是一种通俗的叫法,并不是指某种具体的数据类型,list是可迭代对象,dict是可迭代对象,set也是可迭代对象。 y 和 z 是两个独立的迭代器,迭代器内部持有一个状态,该状态用于记录当前迭代所在的位置,以方便下次迭代的时候获取正确的元素。迭代器有一种具体的迭代器类型,比如 list_iterator , set_iterator 。可迭代对象实现了 __iter__ 和 __next__ 方法。
注意:python2中是 next 方法,python3是 __next__ 方法,这两个方法对应内置函数 iter() 和 next() 。
__iter__ 方法返回可迭代对象本身,这使得他既是一个可迭代对象同时也是一个迭代器。
迭代器
那么什么迭代器呢?它是一个带状态的对象,他能在你调用 next() 方法的时候返回容器中的下一个值,任何实现了 __next__() (python2中实现 next() )方法的对象都是迭代器,至于它是如何实现的这并不重要。
现在我们就以斐波那契数列()为例,学习为何创建以及如何创建一个迭代器:
著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:
1, 1, 2, 3, 5, 8, 13, 21, 34, ...
def fab(max): n, a, b = 0, 0, 1 while n < max: print b a, b = b, a + b n = n + 1
直接在函数fab(max)中用print打印会导致函数的可复用性变差,因为fab返回None。其他函数无法获得fab函数返回的数列。
def fab(max): L = [] n, a, b = 0, 0, 1 while n < max: L.append(b) a, b = b, a + b n = n + 1 return L
代码2满足了可复用性的需求,但是占用了内存空间,最好不要。
对比for i in range(1000): pass和for i in xrange(1000): pass,前一个返回1000个元素的列表,而后一个在每次迭代中返回一个元素,因此可以使用迭代器来解决复用可占空间的问题
class Fab(object): def __init__(self, max): self.max = max self.n, self.a, self.b = 0, 0, 1 def __iter__(self): return self def next(self): if self.n < self.max: r = self.b self.a, self.b = self.b, self.a + self.b self.n = self.n + 1 return r raise StopIteration() ''' >>> for key in Fabs(5): print key 1 1 2 3 5 '''
Fabs 类通过 next() 不断返回数列的下一个数,内存占用始终为常数
Fib既是一个可迭代对象(因为它实现了 __iter__ 方法),又是一个迭代器(因为实现了 __next__ 方法)。实例变量 self .a 和 self.b 用户维护迭代器内部的状态。每次调用 next() 方法的时候做两件事:
为下一次调用 next() 方法修改状态
为当前这次调用生成返回结果
迭代器就像一个懒加载的工厂,等到有人需要的时候才给它生成值返回,没调用的时候就处于休眠状态等待下一次调用。
Python 还提供了一整个 itertools 模块, 它包含各种有用的迭代器
生成无限序列:
>>> from itertools import count
>>> counter = count(start=13)
>>> next(counter)
13
>>> next(counter)
14
从一个有限序列中生成无限序列:
>>> from itertools import cycle
>>> colors = cycle(['red', 'white', 'blue'])
>>> next(colors)
'red'
>>> next(colors)
'white'
>>> next(colors)
'blue'
>>> next(colors)
'red'
从无限的序列中生成有限序列:
>>> from itertools import islice
>>> colors = cycle(['red', 'white', 'blue']) # infinite,无穷的
>>> limited = islice(colors, 0, 4) # finite,有限的
>>> for x in limited:
... print(x)
red
white
blue
red
使用迭代器的优点
对于原生支持随机访问的数据结构(如tuple、list),迭代器和经典for循环的索引访问相比并无优势,反而丢失了索引值(可以使用内建函数enumerate()找回这个索引值)。但对于无法随机访问的数据结构(比如set)而言,迭代器是唯一的访问元素的方式。
另外,迭代器的一大优点是不要求事先准备好整个迭代过程中所有的元素。迭代器仅仅在迭代到某个元素时才计算该元素,而在这之前或之后,元素可以不存在或者被销毁。这个特点使得它特别适合用于遍历一些巨大的或是无限的集合,比如几个G的文件,或是斐波那契数列等等。
迭代器更大的功劳是提供了一个统一的访问集合的接口,只要定义了__iter__()方法对象,就可以使用迭代器访问。
限制:
1.你不能向后移动, 不能回到开始, 也不能复制一个迭代器
2.如果你要再次(或者是同时)迭代同个对象, 你只能去创建另一个迭代器对象
可以使用isinstance()判断一个对象是否是Iterable对象:
>>> from collections import Iterable
>>> isinstance([], Iterable)
True
>>> isinstance({}, Iterable)
True
>>> isinstance('abc', Iterable)
True
>>> isinstance((x for x in range(10)), Iterable)
True
>>> isinstance(100, Iterable)
False
*可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:
from collections import Iterator
>>> isinstance(iter([]), Iterator) True >>> isinstance(iter('abc'), Iterator) True
小结
凡是可作用于for循环的对象都是Iterable类型;
凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
Python的for循环本质上就是通过不断调用next()函数实现的,例如:
for x in [1, 2, 3, 4, 5]:
pass
实际上完全等价于:
# 首先获得Iterator对象:
it = iter([1, 2, 3, 4, 5])
# 循环:
while True:
try:
# 获得下一个值:
x = next(it)
except StopIteration:
# 遇到StopIteration就退出循环
break
for i in (iterable)的内部实现
在大多数情况下,我们不会一次次调用next方法去取值,而是通过 for i in (iterable),
x = [1, 2, 3]
for elem in x:
...
这就是实际发生的情况:
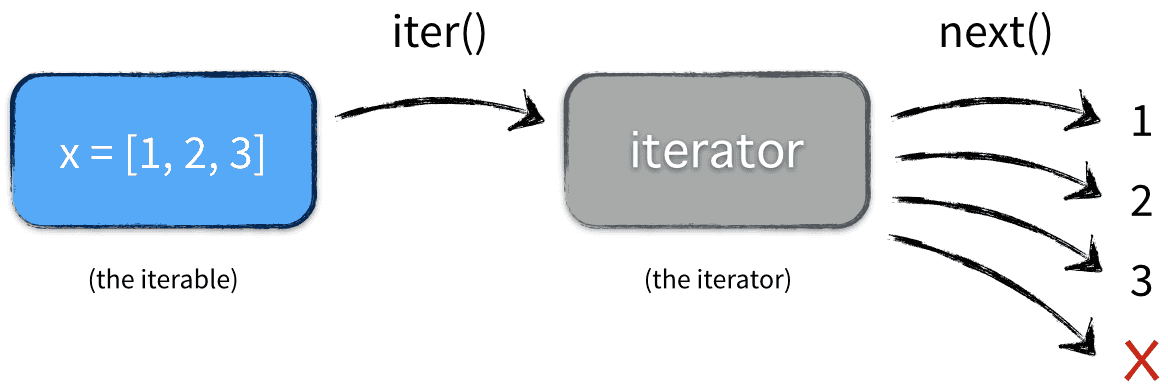
注意:in后面的对象如果是一个迭代器,内部因为有iter方法才可以进行操作,所以,迭代器协议里面有iter和next两个方法,否则for语句无法应用。
for i in range(10):
print i :定时垃圾回收机制:没有引用指向这个对象,则被回收
总结:
1.容器是一系列元素的集合,str、list、set、dict、file、sockets对象都可以看作是容器,容器都可以被迭代(用在for,while等语句中),因此他们被称为可迭代对象。
2.可迭代对象实现了__iter__方法,该方法返回一个迭代器对象。
3.迭代器持有一个内部状态的字段,用于记录下次迭代返回值,它实现了__next__和__iter__方法,迭代器不会一次性把所有元素加载到内存,而是需要的时候才生成返回结果
生成器
生成器处理值序列时允许序列中的每一个值只在需要时才计算,而不是像传统列表那样,一定要提前计算列表中的值。
在恰当的地方使用生成器能节省大量内存,因为大的数据集没必要完全存入内存。与之相似,生成器能够处理一些无法由列表准确表示的序列形式。
我们知道的迭代器有两种:一种是调用方法直接返回的,一种是可迭代对象通过执行iter方法得到的,迭代器有的好处是可以节省内存。
如果在某些情况下,我们也需要节省内存,就只能自己写。我们自己写的这个能实现迭代器功能的东西就叫生成器。
Python中提供的生成器:
1.生成器函数:常规函数定义,但使用yield语句而不是return语句返回结果。yield语句一次返回一个结果,在每个结果中间,挂起函数的状态,以便下次重它离开的地方继续执行
2.生成器表达式:类似于列表推导,但是,生成器返回按需产生结果的一个对象,而不是一次构建一个结果列表
生成器Generator:
本质:迭代器(所以自带了__iter__方法和__next__方法,不需要我们去实现)
特点:惰性运算,开发者自定义
理解生成器
生成器是一个函数,它并不执行并返回一个单一值,而是按照顺序返回一个或多个值。
生成器函数执行直到被通过输出一个值,然后会继续执行知道再次被通知输出值。这会持续直到函数完成或生成器之上的迭代终止。
如果完全没有终止生成器的显式要求;生成器可以表现为一个无限序列。
定义生成器
1.生成器函数的特征就是在函数内部有一个或多个yield语句,而不是return语句
2.yield的功能:一个函数或者子程序只返回一次,但一个生成器能暂停执行并返回一个中间的结果
3.yield 语句返回一个值给调用者并暂停执行
4.当生成器的next()方法被调用的时候,它会准确地从离开地方继续
5.与迭代器相似,生成器以另外的方式来运作
6.当到达一个真正的返回或者函数结束没有更多的值返回,StopIteration异常就会被抛出
>>> def simpGen():
... yield '1'
... yield '2 -> punch'
>>> mygen = simpGen()
>>> mygen.next()
'1'
>>> mygen.next()
'2 -> punch'
>>> mygen.next()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
注意:
1.在Python2中,yield语句和return语句不能在同一个函数中共存。
2.在python3中,两者可以同时存在
创建生成器
方法1:把一个列表生成式的[]改成()
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
#列表生成式
>>> L = [x * x for x in range(10)] >>> L [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
#生成器 >>> g = (x * x for x in range(10)) >>> g <generator object <genexpr> at 0x1022ef630>
创建L和g的区别仅在于最外层的[]和(),L是一个list,而g是一个generator。
我们可以直接打印出list的每一个元素,但我们怎么打印出generator的每一个元素呢?
如果要一个一个打印出来,可以通过next()函数获得generator的下一个返回值:
>>> next(g)
0
>>> next(g)
1
>>> next(g)
4
>>> next(g)
9
>>> next(g)
16
>>> next(g)
25
>>> next(g)
36
>>> next(g)
49
>>> next(g)
64
>>> next(g)
81
>>> next(g)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
generator保存的是算法,每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。
当然,上面这种不断调用next(g)实在是太变态了,正确的方法是使用for循环,因为generator也是可迭代对象:
>>> g = (x * x for x in range(10))
>>> for n in g:
... print(n)
...
0
1
4
9
16
25
36
49
64
81
所以,我们创建了一个generator后,基本上永远不会调用next(),而是通过for循环来迭代它,并且不需要关心StopIteration的错误。
generator非常强大。如果推算的算法比较复杂,用类似列表生成式的for循环无法实现的时候,还可以用函数来实现。
比如,著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:1, 1, 2, 3, 5, 8, 13, 21, 34, ...
斐波拉契数列用列表生成式写不出来,但是,用函数把它打印出来却很容易:
def fib(max):
n, a, b = 0, 0, 1
while n < max:
print(b)
a, b = b, a + b
n = n + 1
#return 'done' #若是不指定的话,最后返回None
上面的函数可以输出斐波那契数列的前N个数:
>>> fib(10)
1
1
2
3
5
8
13
21
34
55
None
结果没有问题,但有经验的开发者会指出,直接在 fab 函数中用 print 打印数字会导致该函数可复用性较差,因为 fab 函数返回 None,其他函数无法获得该函数生成的数列。
要提高 fab 函数的可复用性,最好不要直接打印出数列,而是返回一个 List。以下是 fab 函数改写后的第二个版本:
def fab(max):
n, a, b = 0, 0, 1
L = []
while n < max:
L.append(b)
a, b = b, a + b
n = n + 1
return L
可以使用如下方式打印出 fab 函数返回的 List:
>>> for n in fab(5):
... print n
...
1
1
2
3
5
改写后的 fab 函数通过返回 List 能满足复用性的要求,但是更有经验的开发者会指出,该函数在运行中占用的内存会随着参数 max 的增大而增大,如果要控制内存占用,最好不要用 List
来保存中间结果,而是通过 iterable 对象来迭代。
for i in range(1000): pass
会导致生成一个 1000 个元素的 List,而代码:
for i in xrange(1000): pass
则不会生成一个 1000 个元素的 List,而是在每次迭代中返回下一个数值,内存空间占用很小。因为 xrange 不返回 List,而是返回一个 iterable 对象。
利用 iterable 我们可以把 fab 函数改写为一个支持 iterable 的 class,以下是第三个版本的 Fab:
class Fab(object):
def __init__(self, max):
self.max = max
self.n, self.a, self.b = 0, 0, 1
def __iter__(self):
return self
def next(self):
if self.n < self.max:
r = self.b
self.a, self.b = self.b, self.a + self.b
self.n = self.n + 1
return r
raise StopIteration()
Fab 类通过 next() 不断返回数列的下一个数,内存占用始终为常数:
>>> for n in Fab(5):
... print n
...
1
1
2
3
5
然而,使用 class 改写的这个版本,代码远远没有第一版的 fab 函数来得简洁。如果我们想要保持第一版 fab 函数的简洁性,同时又要获得 iterable 的效果,yield 就派上用场了:
方法2:使用yield
yield是一个语法糖,内部实现了迭代器协议,同时保持状态可以挂起
使用 yield 的第四版
def fib(max):
n,a,b = 0,0,1
while n < max:
#print(b)
yield b
a,b = b,a+b
n += 1
这就是定义generator的另一种方法。如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator:
>>> f = fib(6)
>>> f
<generator object fib at 0x104feaaa0>
第四个版本的 fab 和第一版相比,仅仅把 print b 改为了 yield b,就在保持简洁性的同时获得了 iterable 的效果
调用第四版的 fab 和第二版的 fab 完全一致:
>>> for n in fab(5):
... print n
...
1
1
2
3
5
简单地讲,yield 的作用就是把一个函数变成一个 generator,带有 yield 的函数不再是一个普通函数,Python 解释器会将其视为一个 generator,调用 fab(5) 不会执行 fab 函数,而是返回一个 iterable 对象!在 for 循环执行时,每次循环都会执行 fab 函数内部的代码,执行到 yield b 时,fab 函数就返回一个迭代值,下次迭代时,代码从 yield b 的下一条语句继续执行,而函数的本地变量看起来和上次中断执行前是完全一样的,于是函数继续执行,直到再次遇到 yield。
也可以手动调用 fab(5) 的 next() 方法(因为 fab(5) 是一个 generator 对象,该对象具有 next() 方法),这样我们就可以更清楚地看到 fab 的执行流程:
>>> f = fab(5)
>>> f.next()
1
>>> f.next()
1
>>> f.next()
2
>>> f.next()
3
>>> f.next()
5
>>> f.next()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
当函数执行结束时,generator 自动抛出 StopIteration 异常,表示迭代完成。在 for 循环里,无需处理 StopIteration 异常,循环会正常结束。
这里,最难理解的就是generator和函数的执行流程不一样。函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
python3:
data = fib(10)
print(data)
print(data.__next__())
print(data.__next__())
print("干点别的事")
print(data.__next__())
print(data.__next__())
print(data.__next__())
print(data.__next__())
print(data.__next__())
#输出
<generator object fib at 0x101be02b0>
1
1
干点别的事
2
3
5
8
13
或者:python2
#!/usr/bin/env python #-*- coding:utf-8 -*- def fib(max): n,a,b = 0,0,1 while n < max: #print(b) yield b a,b = b,a+b n += 1 data = fib(10) print(data) print data.next() print data.next() print "干点别的事" print data.next() print data.next() print data.next() print data.next() print data.next() print data.next()
在上面fib的例子,我们在循环过程中不断调用yield,就会不断中断。当然要给循环设置一个条件来退出循环,不然就会产生一个无限数列出来。
同样的,把函数改成generator后,我们基本上从来不会用next()来获取下一个返回值,而是直接使用for循环来迭代:
>>> for n in fib(6):
... print(n)
...
1
1
2
3
5
8
但是用for循环调用generator时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中:
>>> g = fib(6)
>>> while True:
... try:
... x = next(g)
... print('g:', x)
... except StopIteration as e:
... print('Generator return value:', e.value)
... break
...
g: 1
g: 1
g: 2
g: 3
g: 5
g: 8
Generator return value: done
还可通过yield实现在单线程的情况下实现并发运算的效果
#_*_coding:utf-8_*_
__author__ = 'Alex Li'
import time
def consumer(name):
print("%s 准备吃包子啦!" %name)
while True:
baozi = yield
print("包子[%s]来了,被[%s]吃了!" %(baozi,name))
def producer(name):
c = consumer('A')
c2 = consumer('B')
c.__next__()
c2.__next__()
print("老子开始准备做包子啦!")
for i in range(10):
time.sleep(1)
print("做了2个包子!")
c.send(i)
c2.send(i)
producer("alex")
或者:
#!/usr/bin/env python #-*- coding:utf-8 -*- #_*_coding:utf-8_*_ __author__ = 'Alex Li' import time def consumer(name): print("%s 准备吃包子啦!" %name) while True: baozi = yield print("包子[%s]来了,被[%s]吃了!" %(baozi,name)) def producer(name): c = consumer('A') c2 = consumer('B') c.next() c2.next() print("老子开始准备做包子啦!") for i in range(10): time.sleep(1) print("做了2个包子!") c.send(i) c2.send(i) producer("alex")
我们可以得出以下结论:
一个带有 yield 的函数就是一个 generator,它和普通函数不同,生成一个 generator 看起来像函数调用,但不会执行任何函数代码,直到对其调用 next()
(在 for 循环中会自动调用 next())才开始执行。虽然执行流程仍按函数的流程执行,但每执行到一个 yield 语句就会中断,并返回一个迭代值,
下次执行时从 yield 的下一个语句继续执行。看起来就好像一个函数在正常执行的过程中被 yield 中断了数次,每次中断都会通过 yield 返回当前的迭代值。
yield 的好处是显而易见的,把一个函数改写为一个 generator 就获得了迭代能力,比起用类的实例保存状态来计算下一个 next() 的值,不仅代码简洁,而且执行流程异常清晰。
对yield的总结
(1):通常的for..in...循环中,in后面是一个数组,这个数组就是一个可迭代对象,类似的还有链表,字符串,文件。
他可以是a = [1,2,3],也可以是a = [x*x for x in range(3)]。
它的缺点也很明显,就是所有数据都在内存里面,如果有海量的数据,将会非常耗内存。
(2)生成器是可以迭代的,但是只可以读取它一次。因为用的时候才生成,比如a = (x*x for x in range(3))。!!!!注意这里是小括号而不是方括号。
(3)生成器(generator)能够迭代的关键是他有next()方法,工作原理就是通过重复调用next()方法,直到捕获一个异常。
(4)带有yield的函数不再是一个普通的函数,而是一个生成器generator,可用于迭代
(5)yield是一个类似return 的关键字,迭代一次遇到yield的时候就返回yield后面或者右面的值。而且下一次迭代的时候,
从上一次迭代遇到的yield后面的代码开始执行
(6)yield就是return返回的一个值,并且记住这个返回的位置。下一次迭代就从这个位置开始。
(7)带有yield的函数不仅仅是只用于for循环,而且可用于某个函数的参数,只要这个函数的参数也允许迭代参数。
(8)send()和next()的区别就在于send可传递参数给yield表达式,这时候传递的参数就会作为yield表达式的值,而yield的参数是返回给调用者的值,
也就是说send可以强行修改上一个yield表达式值。
(9)send()和next()都有返回值,他们的返回值是当前迭代遇到的yield的时候,yield后面表达式的值,其实就是当前迭代yield后面的参数。
(10)第一次调用时候必须先next()或send(),否则会报错,send后之所以为None是因为这时候没有上一个yield,所以也可以认为next()等同于send(None)
如何判断一个函数是否是一个特殊的 generator 函数?可以利用 isgeneratorfunction 判断:
>>> from inspect import isgeneratorfunction
>>> isgeneratorfunction(fab)
True
要注意区分 fab 和 fab(5),fab 是一个 generator function,而 fab(5) 是调用 fab 返回的一个 generator,好比类的定义和类的实例的区别:
>>> import types
>>> isinstance(fab, types.GeneratorType)
False
>>> isinstance(fab(5), types.GeneratorType)
True
fab 是无法迭代的,而 fab(5) 是可迭代的:
>>> from collections import Iterable
>>> isinstance(fab, Iterable)
False
>>> isinstance(fab(5), Iterable)
True
每次调用 fab 函数都会生成一个新的 generator 实例,各实例互不影响:
>>> f1 = fab(3)
>>> f2 = fab(5)
>>> print 'f1:', f1.next()
f1: 1
>>> print 'f2:', f2.next()
f2: 1
>>> print 'f1:', f1.next()
f1: 1
>>> print 'f2:', f2.next()
f2: 1
>>> print 'f1:', f1.next()
f1: 2
>>> print 'f2:', f2.next()
f2: 2
>>> print 'f2:', f2.next()
f2: 3
>>> print 'f2:', f2.next()
f2: 5
return作用
在一个生成器中,如果没有return,则默认执行到函数完毕;如果遇到return,如果在执行过程中 return,则直接抛出 StopIteration 终止迭代.
def f():
yield 5
print("ooo")
return
yield 6
print("ppp")
# if str(tem)=='None':
# print("ok")
f=f()
# print(f.__next__())
# print(f.__next__())
for i in f:
print(i)
'''
return即迭代结束
for不报错的原因是内部处理了迭代结束的这种情况
'''
执行结果:
5
ooo
执行步骤:
1.执行def f():语句
2.执行f=f()
3.执行for i in f:
4.执行def f():语句的yield 5
5.执行for i in f:语句下的print(i) #得到结果5
6.返回到 yield 5
7.执行def f():语句的print("ooo") #得到ooo
8.执行return,迭代结束
注意:

例子1:在一个生成器中,如果没有return,则默认执行到函数完毕时返回StopIteration;
>>> def g1():
... yield 1
...
>>> g=g1()
>>> next(g) #第一次调用next(g)时,会在执行完yield语句后挂起,所以此时程序并没有执行结束。
1
>>> next(g) #程序试图从yield语句的下一条语句开始执行,发现已经到了结尾,所以抛出StopIteration异常。
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
>>>
例子2:如果遇到return,如果在执行过程中 return,则直接抛出 StopIteration 终止迭代。
>>> def g2():
... yield 'a'
... return
... yield 'b'
...
>>> g=g2()
>>> next(g) #程序停留在执行完yield 'a'语句后的位置。
'a'
>>> next(g) #程序发现下一条语句是return,所以抛出StopIteration异常,这样yield 'b'语句永远也不会执行。
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
如果在return后返回一个值,那么这个值为StopIteration异常的说明,不是程序的返回值
生成器没有办法使用return来返回值。
>>> def g3():
... yield 'hello'
... return 'world'
...
>>> g=g3()
>>> next(g)
'hello'
>>> next(g)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration: world
close()
这个生成器是永远运行的,所以如果你想要终结它,调用 close()方法
手动关闭生成器函数,后面的调用会直接返回StopIteration异常。
>>> def g4():
... yield 1
... yield 2
... yield 3
...
>>> g=g4()
>>> next(g)
1
>>> g.close()
>>> next(g) #关闭后,yield 2和yield 3语句将不再起作用
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
send()
生成器函数最大的特点是可以接受外部传入的一个变量,并根据变量内容计算结果后返回。
用户可以通过send()将值回送给生成器,还可以在生成器中抛出异常,以及要求生成器退出
def gen():
value=0
while True:
receive=yield value
if receive=='e':
break
value = 'got: %s' % receive
g=gen()
print(g.send(None))
print(g.send('aaa'))
print(g.send(3))
print(g.send('e'))
执行流程:
1.通过g.send(None)或者next(g)可以启动生成器函数,并执行到第一个yield语句结束的位置。此时,执行完了yield语句,但是没有给receive赋值。yield value会输出初始值0。注意:在启动生成器函数时只能send(None),如果试图输入其它的值都会得到错误提示信息。
2.通过g.send('aaa'),会传入aaa,并赋值给receive,然后计算出value的值,并回到while头部,执行yield value语句有停止。此时yield value会输出”got: aaa”,然后挂起。
3.通过g.send(3),会重复第2步,最后输出结果为”got: 3″
4.当我们g.send('e')时,程序会执行break然后推出循环,最后整个函数执行完毕,所以会得到StopIteration异常。
最后的执行结果如下:
0
got: aaa
got: 3
Traceback (most recent call last):
File "h.py", line 14, in <module>
print(g.send('e'))
StopIteration
send的例子2:
def f():
print("ok")
s=yield 7
print(s)
yield 8
f=f()
print(f.send(None))
print(next(f))
#print(f.send(None))等同于print(next(f)),执行流程:打印ok,yield7,当再next进来时:将None赋值给s,然后返回8,可以通过断点来观察
执行结果:
ok
7
None
8
send的例子3:
#!/usr/bin/env python
#coding:utf8
def gen():
for x in range(4):
tmp = yield x
if tmp == "hello":
print("world")
else:
print(str(tmp))
g = gen()
print(next(g)) # 0
print(next(g)) # None 1
print(g.send("hello")) #world 2
throw()
用来向生成器函数送入一个异常,可以结束系统定义的异常,或者自定义的异常。
throw()后直接跑出异常并结束程序,或者消耗掉一个yield,或者在没有下一个yield的时候直接进行到程序的结尾。
def gen():
while True:
try:
yield 'normal value'
yield 'normal value 2'
print('here')
except ValueError:
print('we got ValueError here')
except TypeError:
break
g=gen()
print(next(g))
print(g.throw(ValueError))
print(next(g))
print(g.throw(TypeError))
输出结果为:
normal value
we got ValueError here
normal value
normal value 2
Traceback (most recent call last):
File "h.py", line 15, in <module>
print(g.throw(TypeError))
StopIteration
解释:
1.print(next(g)):会输出normal value,并停留在yield ‘normal value 2’之前。
2.由于执行了g.throw(ValueError),所以会跳过所有后续的try语句,也就是说yield ‘normal value 2’不会被执行,然后进入到except语句,打印出we got ValueError here。然后再次进入到while语句部分,消耗一个yield,所以会输出normal value。
3.print(next(g)),会执行yield ‘normal value 2’语句,并停留在执行完该语句后的位置。
4.g.throw(TypeError):会跳出try语句,从而print(‘here’)不会被执行,然后执行break语句,跳出while循环,然后到达程序结尾,所以跑出StopIteration异常。
例子1:
#!/usr/bin/env python
#coding:utf8
def stop_immediately(name):
if name == "skycrab":
yield "okok"
else:
print("nono")
s = stop_immediately('sky')
print(type(s))
s.__next__()
执行结果:
Traceback (most recent call last):
<class 'generator'>
File "G:/PycharmProject/fullstack2/week1/star.py", line 12, in <module>
nono
s.__next__()
StopIteration
由于没有额外的yield,所以将直接抛出StopIteration。
例子3:
#!/usr/bin/env python
#coding:utf8
def mygen():
try:
yield "soemthing"
except ValueError:
yield "value error"
finally:
print("clean") #一定会被执行
gg = mygen()
print(gg.__next__())
print(gg.throw(ValueError)) #value error clean
执行结果:
soemthing
value error
clean
文件读取
def read_file(fpath):
BLOCK_SIZE = 1024
with open(fpath, 'rb') as f:
while True:
block = f.read(BLOCK_SIZE)
if block:
yield block
else:
return
如果直接对文件对象调用 read() 方法,会导致不可预测的内存占用。好的方法是利用固定长度的缓冲区来不断读取文件内容。通过 yield,我们不再需要编写读文件的迭代类,就可以轻松实现文件读取。
注意:生成器对象就是一种特殊的迭代器对象,满足迭代器协议,可以调用next;对生成器对象for 循环时,调用iter方法返回了生成器对象,然后再不断next迭代,而iter和next都是在yield内部实现的。
练习1:使用文件读取,找出文件中最长的行的?
max(len(x.strip()) for x in open('/hello/abc','r'))
练习2:
def add(s, x):
return s + x
def gen():
for i in range(4):
yield i
base = gen()
for n in [1, 10]:
base = (add(i, n) for i in base)
print list(base)
解析:
'''
核心语句就是:
for n in [1, 10]:
base = (add(i, n) for i in base)
在执行list(base)的时候,开始检索,然后生成器开始运算了。关键是,这个循环次数是2,也就是说,有两次生成器表达
式的过程。必须牢牢把握住这一点。
生成器返回去开始运算,n = 10而不是1没问题吧,这个在上面提到的文章中已经提到了,就是add(i, n)绑定的是n这个
变量,而不是它当时的数值。
然后首先是第一次生成器表达式的执行过程:base = (10 + 0, 10 + 1, 10 + 2, 10 +3),这是第一次循环的结
果(形象表示,其实已经计算出来了(10,11,12,3)),然后第二次,
base = (10 + 10, 11 + 10, 12 + 10, 13 + 10) ,终于得到结果了[20, 21, 22, 23].
'''
练习3:自定义range
#!/usr/bin/env python
#coding:utf8
class Myrange(object):
def __init__(self,n):
self.idx = 0
self.n = n
def __iter__(self):
return self
def __next__(self):
if self.idx < self.n:
val = self.idx
self.idx += 1
return val
else:
raise StopIteration()
print(Myrange(4).__iter__().__next__())
for i in Myrange(4):
print(i)
执行结果:
0
0
1
2
3
标准库中的生成器
range
这个range对象的迭代器是个生成器。他返回序列值,这些值从range对象的底层值开始到它的顶端值。默认情况下,它的序列就是让每一个当前值加1并作为下一个值输出。但是range函数还有一个可选的第三方参数step,能让你指定不同的增量(包括负值)。
dict.items及其家族
在python中,内置的字典类包括3个允许迭代所有字典的方法,并且这3个方法都是迭代器,也是生成器的迭代对象:keys、values和items
注意:
在Python 2中,这3个方法被称为iterkeys、itervalues和iteritems
这些方法的目的是允许迭代键、值或包含一个字典中键与值的二元组条目:
例如:
>>> Dict1 = {'foo':'bar','bar':'bacon'}
>>> iter1 = iter(Dict1.items())
>>> next(iter1)
('foo', 'bar')
>>> next(iter1)
('bar', 'bacon')
>>>
在此使用生成器的一项价值是防止需要以另一种格式创建一个额外的字典副本(或部分字典)。dict.items并不需要将整个字典重新为包含二元组
的列表。被请求时,它仅仅一次返回一个二元组。
如果在迭代期间试图修改字典,可能会看到副作用,如下所示:
>>> Dict1 = {'foo':'bar','bar':'bacon'}
>>> iter1 = iter(Dict1.items())
>>> next(iter1)
('foo', 'bar')
>>> Dict1['spam'] = 'eggs'
>>> next(iter1)
Traceback (most recent call last):
File "<pyshell#4>", line 1, in <module>
next(iter1)
RuntimeError: dictionary changed size during iteration
>>>
注意:这个只在python 3生效。
因为items迭代器是一个仅从引用的字典中读取数据的生成器,如果运行时字典表发生了变化,它将不知道自己应该做什么。面对这种模糊性,它会拒绝可能的猜测,并且抛出一个RuntimeError的错误。
看一下在python2的结果:
>>> Dict1 = {'foo':'bar','bar':'bacon'}
>>> iter1 = iter(Dict1.items())
>>> next(iter1)
('foo', 'bar')
>>> Dict1['spam'] = 'eggs'
>>> next(iter1)
('bar', 'bacon')
>>>
zip
Python包含了一个名为zip的内置函数,该函数有多种可迭代对象并且一起迭代所有的对象,输出每个迭代对象(在元组中)的第一个元素,接着
第二个元素,然后输出第三个元素,以此类推,直到到达最短的迭代对象的最后一个元素。
例如:
>>> z = zip(['a','b','c','d'],['x','y','z'])
>>> next(z)
('a', 'x')
>>> next(z)
('b', 'y')
>>> next(z)
('c', 'z')
>>> next(z)
Traceback (most recent call last):
File "<pyshell#4>", line 1, in <module>
next(z)
StopIteration
>>>
注意:这个只在python 3生效。
使用zip的原因与使用dict.items及其家庭的原因相似。它的目的就是在不同的结果中输出其迭代对象的返回成员,一次输出一个集合。
如果将所有数据都复制到内存并不是必须的,那么将缓解对内存的需求。
看一下在python2的结果:
>>> z = zip(['a','b','c','d'],[])
>>> z = zip(['a','b','c','d'],['x','y','z'])
>>> next(z)
Traceback (most recent call last):
File "<pyshell#9>", line 1, in <module>
next(z)
TypeError: list object is not an iterator
map
内置函数map将一个能接受N个参数和N个迭代器对象的函数作为参数,并且计算每个迭代器对象的序列成员的函数结果,当它被到达最短的迭代对象的最后一个元素时停止。
与zip相似,生成器在这里被用作迭代器,这是因为它不适合提前计算所有值,毕竟这些数据可能需要也可能不需要。当且仅当每个值被请求时,才会计算值。
例如:
>>> m = map(lambda x,y:max([x,y]),[4,1,7],[3,4,5])
>>> next(m)
4
>>> next(m)
4
>>> next(m)
7
>>> next(m)
Traceback (most recent call last):
File "<pyshell#10>", line 1, in <module>
next(m)
StopIteration
>>>
注意:这个只在python 3生效。
处理小的迭代对象时,这依然是一个无关紧要的操作。但是,如果制定一个更大的数据结构,利用生成器可以节省大量的时间和避免内存消耗,
因为不需要一次性转换和计算整个结构。
看一下在python2的结果:
>>> m = map(lambda x,y:max([x,y]),[4,1,7],[3,4,5])
>>> next(m)
Traceback (most recent call last):
File "<pyshell#16>", line 1, in <module>
next(m)
TypeError: list object is not an iterator
>>>
协程应用:
所谓协同程序也就是是可以挂起,恢复,有多个进入点。其实说白了,也就是说多个函数可以同时进行,可以相互之间发送消息等。
import queue
def tt():
for x in range(4):
print ('tt'+str(x) )
yield
def gg():
for x in range(4):
print ('xx'+str(x) )
yield
class Task():
def __init__(self):
self._queue = queue.Queue()
def add(self,gen):
self._queue.put(gen)
def run(self):
while not self._queue.empty():
for i in range(self._queue.qsize()):
try:
gen= self._queue.get()
gen.send(None)
except StopIteration:
pass
else:
self._queue.put(gen)
t=Task()
t.add(tt())
t.add(gg())
t.run()
# tt0
# xx0
# tt1
# xx1
# tt2
# xx2
# tt3
# xx3
补充:
1、协同程序是可以运行的独立函数调用,可以暂停或者挂起,并从程序离开的地方继续或者重新开始
2、在有调用者和(被调用的)协同程序也有通信
3、当协同程序暂停的时候,我们能从其中获得一个中间的返回值,当调用回到程序中时,能够传入额外或者改变了的参数,但仍能够从我们上次离开的地方继续,并且所有状态完整
4、挂起返回出中间值并多次继续的协同程序被称为生成器
总结:
1.按照鸭子模型理论,生成器就是一种迭代器,可以使用for进行迭代。
2.第一次执行next(generator)时,会执行完yield语句后程序进行挂起,所有的参数和状态会进行保存。再一次执行next(generator)时,会从挂起的状态开始往后执行。在遇到程序的结尾或者遇到StopIteration时,循环结束。
3.可以通过generator.send(arg)来传入参数,这是协程模型。
4.可以通过generator.throw(exception)来传入一个异常。throw语句会消耗掉一个yield。可以通过generator.close()来手动关闭生成器。
5.next()等价于send(None)
参考:
http://nvie.com/posts/iterators-vs-generators/
http://www.cnblogs.com/yuanchenqi/articles/5769491.html
http://www.cnblogs.com/alex3714/articles/5765046.html
https://www.ibm.com/developerworks/cn/opensource/os-cn-python-yield/
http://python.jobbole.com/81911/