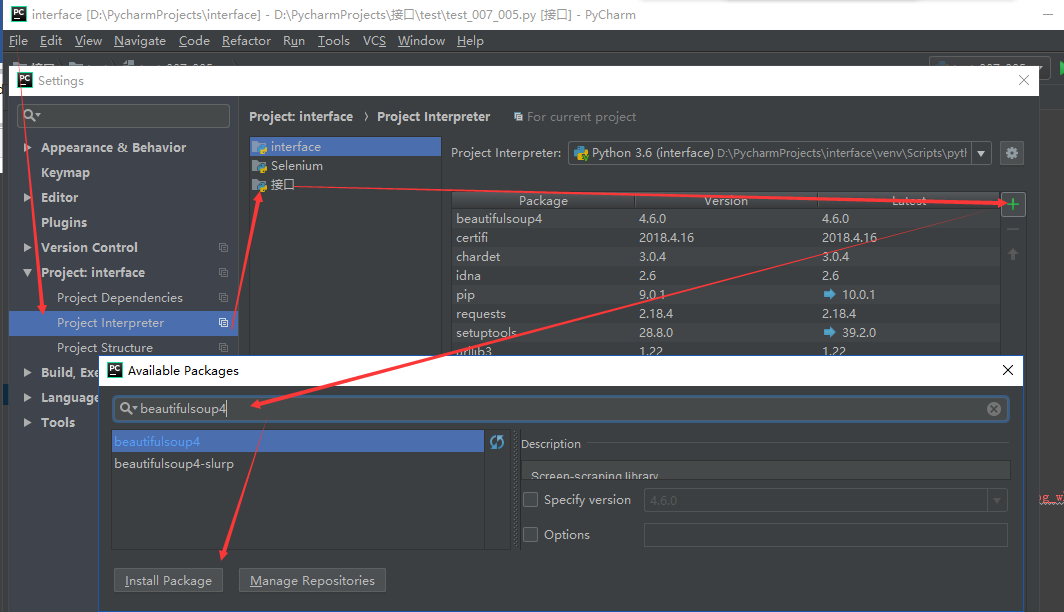
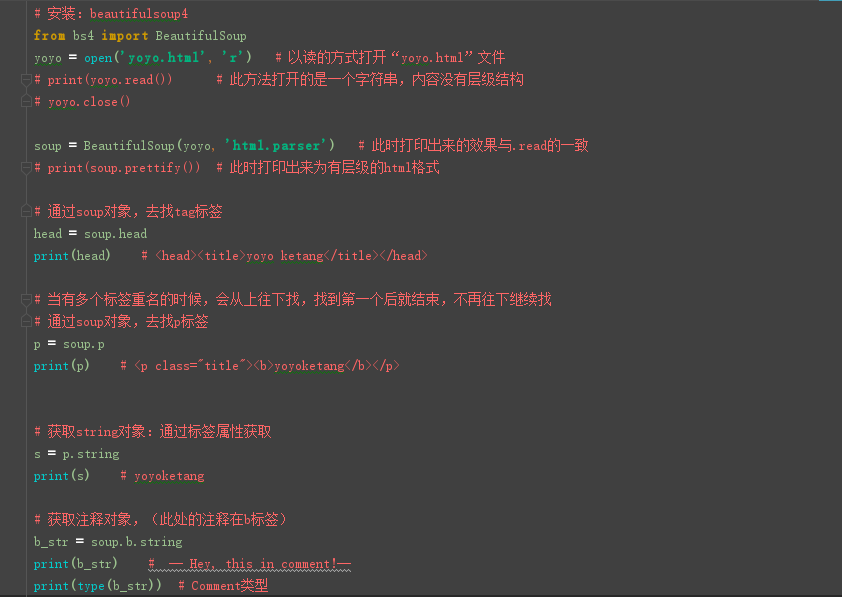
安装:beautifulsoup4
from
bs4 import BeautifulSoup
yoyo = open('yoyo.html', 'r') # 以读的方式打开“yoyo.html”文件
# print(yoyo.read()) # 此方法打开的是一个字符串,内容没有层级结构
# yoyo.close()
soup
= BeautifulSoup(yoyo, 'html.parser') # 此时打印出来的效果与.read的一致
# print(soup.prettify()) # 此时打印出来为有层级的html格式
# 通过soup对象,去找tag标签
head
= soup.head
print(head) # <head><title>yoyo
ketang</title></head>
# 当有多个标签重名的时候,会从上往下找,找到第一个后就结束,不再往下继续找
# 通过soup对象,去找p标签
p = soup.p
print(p) # <p
class="title"><b>yoyoketang</b></p>
# 获取string对象:通过标签属性获取
s = p.string
print(s) # yoyoketang
# 获取注释对象,(此处的注释在b标签)
b_str
= soup.b.string
print(b_str) #
-- Hey, this in comment!--
print(type(b_str)) # Comment类型
# 标签属性
from bs4 import BeautifulSoup
yoyo = open('yoyo.html', 'r') # 以读的方式打开“yoyo.html”文件
# print(yoyo.read()) # 此方法打开的是一个字符串,内容没有层级结构
# yoyo.close()
soup = BeautifulSoup(yoyo, 'html.parser')
p = soup.p # p 标签
print(p) # <p class="title"><b>yoyoketang</b></p>
# 获取标签属性
value = p.attrs['class'] # tag对象,可以当成字典取值
print(value) # ['title'] list属性
# calss属性有多重属性,返回的值是list
# class="clearfix sdk 十分广泛广泛的
# value = p.attrs['class']
# print(value) # ['clearfix', 'sdk', '十分广泛广泛的']

# 查找所有文本
from bs4 import BeautifulSoup
yoyo = open('yoyo.html', 'r') # 以读的方式打开“yoyo.html”文件
# print(yoyo.read()) # 此方法打开的是一个字符串,内容没有层级结构
# yoyo.close()
soup = BeautifulSoup(yoyo, 'html.parser')
# 获取body对象内容
body = soup.body
print(body)
# 只获取body里面的文本信息
get_text = body.get_text() # 获取当前标签下的,所有子孙节点的string
print(get_text)

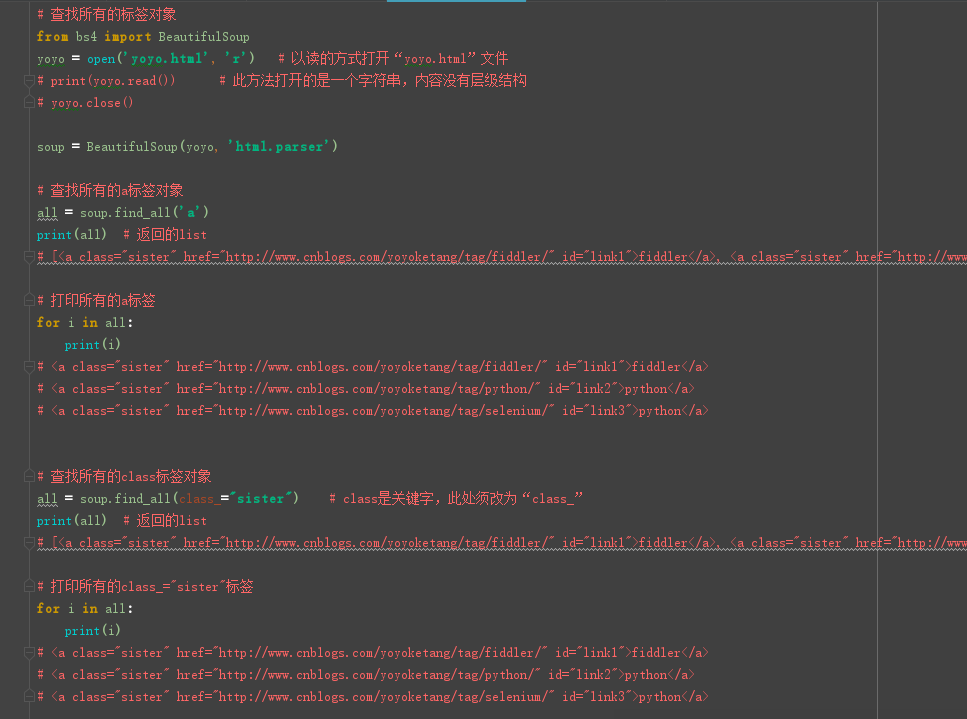
# 查找所有的标签对象
from bs4 import BeautifulSoup
yoyo = open('yoyo.html', 'r') # 以读的方式打开“yoyo.html”文件
# print(yoyo.read()) # 此方法打开的是一个字符串,内容没有层级结构
# yoyo.close()
soup = BeautifulSoup(yoyo, 'html.parser')
# 查找所有的a标签对象
all = soup.find_all('a')
print(all) # 返回的list
# [<a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/fiddler/" id="link1">fiddler</a>, <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/python/" id="link2">python</a>, <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/selenium/" id="link3">python</a>]
# 打印所有的a标签
for i in all:
print(i)
# <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/fiddler/" id="link1">fiddler</a>
# <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/python/" id="link2">python</a>
# <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/selenium/" id="link3">python</a>
# 查找所有的class标签对象
all = soup.find_all(class_="sister") # class是关键字,此处须改为“class_”
print(all) # 返回的list
# [<a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/fiddler/" id="link1">fiddler</a>, <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/python/" id="link2">python</a>, <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/selenium/" id="link3">python</a>]
# 打印所有的class_="sister"标签
for i in all:
print(i)
# <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/fiddler/" id="link1">fiddler</a>
# <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/python/" id="link2">python</a>
# <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/selenium/" id="link3">python</a>