格式化输出
print(f'{d}')
会把d代表的意义转化掉,和format差不多
%格式化形式
#这里只说明字典使用 dict1 = {"what": "this year", "year": 2016} print("%(what)s is %(year)d" % {"what": "this year", "year": 2016}) # 输出this year is 2016 print("%(what)s is %(year)d, %d" % (dict1,22) ) # 输出this year is 2016
format格式化形式
位置映射

#后面的元素可以多 print("{}:{}".format('192.168.0.100', 8888, 222)) #输出如下192.168.0.100:8888
关键字映射
print("{server}{1}:{0}".format(8888,'192.168.1.100',server='Web Server Info :')) #Web Server Info :192.168.1.100:8888
print('{name},{sex},{age}'.format(age=32,sex='male',name='zhangk')) #zhangk,male,32
元素访问


print("{0[0]}.{0[1]}".format(('baidu','com'))) #baidu.com
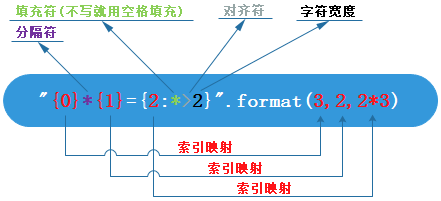
填充对齐
- ^、<、>分别是居中、左对齐、右对齐
精度设置
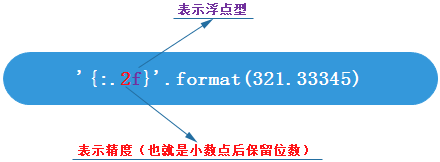
# 填充与对齐 # 填充常跟对齐一起使用 # ^、<、>分别是居中、左对齐、右对齐,后面带宽度 # :号后面带填充的字符,只能是一个字符,不指定的话默认是用空格填充 print('{:>8}'.format('zhang')) print('{:0>8}'.format('zhang')) print('{:a<8}'.format('zhang')) print('{:p^10}'.format('zhang')) # 精度与类型f # 精度常跟类型f一起使用 print('{:.2f}'.format(31.31412)) # 其他类型 # 主要就是进制了,b、d、o、x分别是二进制、十进制、八进制、十六进制 print('{:b}'.format(15)) print('{:d}'.format(15)) print('{:o}'.format(15)) print('{:x}'.format(15)) # 用逗号还能用来做金额的千位分隔符 print('{:,}'.format(123456789)) #输出如下: zhang 000zhang zhangaaa ppzhangppp 31.31 1111 15 17 f 123,456,789
进制及其他显示
b : 二进制
d :十进制
o :八进制
x :十六进制
!s :将对象格式化转换成字符串
!a :将对象格式化转换成ASCII
!r :将对象格式化转换成repr

其他情况
dict1 = {"one": 1, "two": 2, "three": 3}
list1 = ["one","two", "three"]
print("{}".format(dict1)) # 是字典
print("{0} {1} {2}".format(*dict1)) # 返回的是one two three
print('{one},{two},{three}'.format(**dict1)) # 返回的是元组对,
print('{one},{two},{three}'.format(one=1, two=2, three=3)) # 返回的是元组对,
print("{}".format(list1)) # 是序列
print("{0} {1} {2}".format(*list1)) # 返回的是one two three
class AssignValue(object):
def __init__(self, value):
self.value = value
my_value = AssignValue(6)
print('value 为: {0.value}'.format(my_value)) # "0" 是可选的,传入的是对象
#输出如下:
{'one': 1, 'two': 2, 'three': 3}
one two three
1,2,3
1,2,3
['one', 'two', 'three']
one two three
value 为: 6
函数
函数即变量,如果先使用fun(),然后在定义fun(),就会报错
函数基本形式
def 函数名(参数列表):
函数体
#直接调用 def hello(): print("hello,world") return hello() #返回函数 def hello1(x): def hello2(x): print(x, x) return hello2 a = hello1("1") a(1) #输出如下: hello,world 1 1
关键字参数,可变长参数
func1(m,n) #位置参数 func2(m=1) #默认参数,必须在位置参数后面,最好是不可变对象 func3(*args) #可变参数 func4(**kwargs) #关键字参数 func5(*args,a=1,b) #命名关键字参数
- 调用时候,位置参数一定在默认参数前面,否则报错function(one = 1,two = 2,3),也不可以调换顺序 错误例子
- **接受的是字典,*接受的元组,调用时候如果有元组,列表,字典调用*,则添加*解包,调用**参数,字典用**解包
- 参数定义的顺序必须是:必选参数–>默认参数–>可变参数–>命名关键字参数–>关键字参数
- 命名关键字参数必须是a=2,这样指定
参数后面的冒号和->
def f(ham: str, eggs: str = 'eggs') -> str :
print("Annotations:", f.__annotations__)
print("Arguments:", ham, eggs)
return ham + ' and ' + eggs
f.__annotations__(显示参数注释和返回值注释) {'ham': <class 'str'>, 'eggs': <class 'str'>, 'return': <class 'str'>}
其实只是提醒,并没有指定参数类型
内置函数
abs() #绝对值
all() #如果全是真或者假,返回true,否则返回false 0,"",false 为假,其他为真
any() #一真为真,全假为假
ascii() #返回对应的ascii, 类似于repr() 和chr差不多,和ord相反,64会变成4
bin() #oct() hex() 接受一个10进制数字,不可以是字符串,转为相对应的进制
bool #返回相对应的bool值,None,0,“”,{},【】,()为false
bytes() #把字符串转为相对应的字节,第一个是要转化的字符串,第一个参数是按什么编码,是不可变序列,
bytearray() #可以如果bytes,但是是可变序列,也可以直接添加参数bytearray(str.encode())
classmethod() staticmethod() #函数修饰符 和普通函数区别详见 普通函数是实例的, classmethod是对象的 staticmethod是不绑定参数的
callable:函数用于检查一个对象是否是可调用的。如果返回True,object仍然可能调用失败;但如果返回False,调用对象ojbect绝对不会成功。
complie() #讲.py或者str变成可执行的语句,详见
float() int() complex() #转为相对应的类型
getattr() hasattr() setattr() delattr() #详见 对应获取属性, 查询属性 设置 删除
dict() len() list() str() set() max() min() pow() print()#比较简单不说了
dir() #接收对象作为参数,返回该对象的所有属性和方法 和__dict__区别,__dict__是字典,dir()是列表,__dict__是dir()的子集 __annotation__是函数注释
help() #以树状形式返回所有的属性和方法,还有注释,这个不错哦
divmod(100,3) #返回一个(33,1)元组,第一个是商,第二个是余数
enumerate() #枚举可迭代对象,用于获取他的索引和值,for index,value in enumerate(list1):
eval() 和exec() #变成可执行代码, eval支持一行,有返回,exec支持多行,无返回
filter,format #参见本文的filter和上一篇的format
frozenset() #转换为不可变的集合
globals() # 返回一个字典,包括所有的全局变量与它的值所组成的键值对
locals() # 返回一个字典,包括所有的局部变量与它的值所组成的键值对
vars() #返回当前模块中的所有变量
hash() # 传入一个对象,返回相对应的hash值
id() #返回内存地址,可用于查看两个变量是否指向相同一块内存地址
input() #提示用户输入,接受字符串类型
isinstance() issubclass() #如名字
iter() #转为迭代器
next() #迭代器的下一个项目,和iter互用
map() #详见本文的map
memoryview() #查看内存对象,
open: #函数用于打开一个文件,创建一个 file 对象,相关的方法才可以调用它进行读写。
propetry() #把某个方法变成属性,详见
range() #创建一个range()对象,可以迭代,可以转为列表
repr() #原形毕露
reversed() #将序列翻转,返回迭代器
round() #返回数字整数部分
slice(start,stop,stride) #相当于做一个切片模板,别人用就这么切
sorted() #详见本文
super() #调用父类的方法,顺序按照__mro__
type() #返回对象类型
zip() #打包成元组,zip(x1,x2,x3,x4) 把x1,x2,x3,x4中对应的元素打包成元组,哪个没有就停止
__import__:函数用于动态加载类和函数 。
高级函数
高阶函数:就是把函数当成参数传递的一种函数;例如
def add(x:int, y, f): return f(x) + f(y) print(add(1.1, 2, abs)) #输出3.1
包含函数:
name = "1" def outer(func): name="2" func() #这里相当于调用,而不是内部函数 def show(): print(name) outer(show) #输出如下: 1
map,filter,reduce,sorted
map,filter在python3中返回的是迭代对象,reduce在functools中,sorted没有了cmp
map()函数
python内置的一个高阶函数,它接收一个函数f和一个list,并且把list的元素以此传递给函数f,然后返回一个函数f处理完所有list元素的列表,如下:
a = [1,2,3,4,5] def f(x): return abs(x-3) print(map(f, a)) #<map object at 0x00CABDF0> 返回的是迭代对象,所以可以用for循环,循环完就里面就没有东西了 print(list(map(f,a))) #[2, 1, 0, 1, 2]
reduce()函数
reduce()函数也是python的内置高阶函数,reduce()函数接收的的参数和map()类似,一个函数f,一个list,但行为和map()不同,reduce()传入的参数f必须接受2个参数,
第一次调用是把list的前两个元素传递给f,第二次调用时,就是把前两个list元素的计算结果当成第一个参数,list的第三个元素当成第二个参数,传入f进行操作,以此类推,并最终返回结果;
from functools import reduce #在python3里面不是内置,需要导 def f(x,y): return x+y print(reduce(f,[1,2,3,4,5])) #15
注解:
1,计算a=f(1,2)的值为3
2,计算b=f(a,3)的值为6
3,计算c=f(b,4)的值为10
4,计算d=f(c,5)的值为15
filter()函数
filter()函数是python内置的另一个有用的高阶函数,filter()函数接收一个函数f和一个list,这个函数f的作用是对每个元素进行判断,返回true或false,filter()根据判断结果自动过滤掉不符合条件的元素,返回由符合条件的元素组成的list;例
a = [1,2,3,4,5] def f(x): return x % 2 == 1 print(filter(f, a)) #<filter object at 0x00C6BD70> print(list(filter(f, a))) #[1,3,5]
返回的是迭代对象,需要用list转换成列表
注解:
1.llist元素以此传入到函数f
2.f判断每个元素是否符合条件,把符合条件的留下,不符合条件的舍弃
3.把最终符合条件的元素组成一个新的列表
sorted()函数
sorted() 函数对所有可迭代的对象进行排序操作。
sort 与 sorted 区别:
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
sorted 语法:
sorted(iterable, key=None, reverse=False)
参数说明:
- iterable -- 可迭代对象。
- key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。 可以是变量,可以是函数或者lambda
- reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
- 多级排序,使用operator.itemgetter例如:sorted(list1, key=itemgetter(0,1)) 先用第0个,再用第一个排序
返回重新排序的列表。
以下实例展示了 sorted 的使用方法:
>>>a = [5,7,6,3,4,1,2]
>>> b = sorted(a) # 保留原列表
>>> a [5, 7, 6, 3, 4, 1, 2]
>>> b [1, 2, 3, 4, 5, 6, 7]
>>> L=[('b',2),('a',1),('c',3),('d',4)]
>>> sorted(L, cmp=lambda x,y:cmp(x[1],y[1])) # 利用cmp函数
[('a', 1), ('b', 2), ('c', 3), ('d', 4)]
>>> sorted(L, key=lambda x:x[1]) # 利用key
[('a', 1), ('b', 2), ('c', 3), ('d', 4)]
匿名函数
忘了哪里说的尽量少用
ython 使用 lambda 来创建匿名函数。
- lambda只是一个表达式,函数体比def简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
语法
lambda函数的语法只包含一个语句,如下:
lambda [arg1 [,arg2,.....argn]]:expression
如下实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 可写函数说明
sum = lambda arg1, arg2: arg1 + arg2;
# 调用sum函数
print "相加后的值为 : ", sum( 10, 20 )
print "相加后的值为 : ", sum( 20, 20 )
以上实例输出结果:
相加后的值为 : 30 相加后的值为 : 40
lambda多重调用:和偏函数对比
x = lambda x:(lambda y : x/y) print(x(1)(1)) #1.0 print(x(2)(1)) #2.0
函数面试题
1、默认参数
默认参数在程序开始时候,装载完毕,如果是可变参数,内部引用的时候会不再开辟新的空间,用的是func.__deflaut__的值,,但如果不是可变参数,每次变化都是新的空间,如None
def f(arg, li =[]): li.append(arg) return li v1 = f(1) #用的是默认参数【】的空间 print(v1) v2 = f(2,[]) #这是【】是新的空间 print(v2) v3= f(3) print(v3) #用的是默认参数【】的空间,尽量默认参数不要用可变列表 print(v1) #参数变化 [1] [2] [1, 3] [1, 3]


