什么是索引?
在数据库中,索引是单独的,物理的,有序的存储结构
为什么需要索引?
我们应为数据库时,查询的操作远比其它的多,所以要更快更有效的去查找数据
因此,我们使用了索引
索引就是提升查询效率最有效的手段
索引的实现原理:b+树 结构
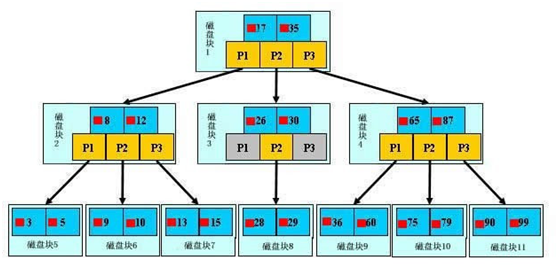
索引最终的目的是要尽可能降低io次数,减少查找的次数,以最少的io找到需要的数据,此时B+树闪亮登场
光有数据结构还不行,还需要有对应的算法做支持,就是二分查找法
应该尽可能的将数据量小的字段作为索引
索引的分类:
聚集索引:
特点:叶子节点保存了完整的一行记录
主键的索引是集束索引
没有主键,则找第一个not null 且unique的列作为索引
如果都没有,innodb会在内部自动产生一个聚集索引,它是自增的
辅助索引:
特点:叶子节点保存索引数据和主键值,innodb在用主键值使用聚集索引查找数
据
覆盖索引:指需要的数据就在辅助索引中
回表:所需的数据不在辅助索引中,就需要回表用主键值去查找
聚集索引 > 覆盖索引 > 非覆盖索引
联合索引:
联合索引最重要的是顺序 按照最左匹配原则 应该将区分度高的放在左边 区分度低的放到右边
案例:
create table usr(id int,name char(10),gender char(3),email char(30));
#准备数据
delimiter //
create procedure addData(in num int)
begin
declare i int default 0;
while i < num do
insert into usr values(i,"jack","m",concat("xxxx",i,"@qq.com"));
set i = i + 1;
end while;
end//
delimiter ;
#执行查询语句 观察查询时间
select count(*) from usr where id = 1;
# row in set (3.85 sec)
#时间在秒级别 比较慢
1.#添加主键
alter table usr add primary key(id);
#再次查询
select count(*) from usr where id = 1;
#1 row in set (0.00 sec)
#基本在毫秒级就能完成 提升非常大
2.#当条件为范围查询时
select count(*) from usr where id > 1;
#速度依然很慢 对于这种查询没有办法可以优化因为需要的数据就是那么多
#缩小查询范围 速度立马就快了
select count(*) from usr where id > 1 and id < 10;
#当查询语句中匹配字段没有索引时 效率测试
select count(*) from usr where name = "jack";
#1 row in set (2.85 sec)
# 速度慢
3.# 为name字段添加索引
create index name_index on usr(name);
# 再次查询
select count(*) from usr where name = "jack";
#1 row in set (3.89 sec)
# 速度反而降低了 为什么?
#由于name字段的区分度非常低 完全无法区分 ,因为值都相同 这样一来B+树会没有任何的子节点,像一根竹竿每一都匹配相当于,有几条记录就有几次io ,所有要注意 区分度低的字段不应该建立索引,不能加速查询反而降低写入效率,
#同理 性别字段也不应该建立索引,email字段更加适合建立索引
# 修改查询语句为
select count(*) from usr where name = "aaaaaaaaa";
#1 row in set (0.00 sec) 速度非常快因为在 树根位置就已经判断出树中没有这个数据 全部跳过了
# 模糊匹配时
select count(*) from usr where name like "xxx"; #快
select count(*) from usr where name like "xxx%"; #快
select count(*) from usr where name like "%xxx"; #慢
#由于索引是比较大小 会从左边开始匹配 很明显所有字符都能匹配% 所以全都匹配了一遍
4.索引字段不能参加运算
select count(*) from usr where id * 12 = 120;
#速度非常慢原因在于 mysql需要取出所有列的id 进行运算之后才能判断是否成立
#解决方案
select count(*) from usr where id = 120/12;
#速度提升了 因为在读取数据时 条件就一定固定了 相当于
select count(*) from usr where id = 10;
#速度自然快了
5.有多个匹配条件时 索引的执行顺序 and 和 or
#先看and
#先删除所有的索引
alter table usr drop primary key;
drop index name_index on usr;
#测试
select count(*) from usr where name = "jack" and gender = "m" and id = 1 and email = "xxxx2@qq.com";
#1 row in set (1.34 sec) 时间在秒级
#为name字段添加索引
create index name_index on usr(name);
#测试
select count(*) from usr where name = "jack" and gender = "m" and id = 1 and email = "xxxx2@qq.com";
#1 row in set (17.82 sec) 反而时间更长了
#为gender字段添加索引
create index gender_index on usr(gender);
#测试
select count(*) from usr where name = "jack" and gender = "m" and id = 1 and email = "xxxx2@qq.com";
#1 row in set (16.83 sec) gender字段任然不具备区分度
#为id加上索引
alter table usr add primary key(id);
#测试
select count(*) from usr where name = "jack" and gender = "m" and id = 1 and email = "xxxx1@qq.com";
#1 row in set (0.00 sec) id子弹区分度高 速度提升
#虽然三个字段都有索引 mysql并不是从左往右傻傻的去查 而是找出一个区分度高的字段优先匹配
#改为范围匹配
select count(*) from usr where name = "jack" and gender = "m" and id > 1 and email = "xxxx1@qq.com";
#速度变慢了
#删除id索引 为email建立索引
alter table usr drop primary key;
create index email_index on usr(email);
#测试
select count(*) from usr where name = "jack" and gender = "m" and id = 1 and email = "xxxx2@qq.com";
#1 row in set (0.00 sec) 速度非常快
#对于or条件 都是从左往右匹配
select count(*) from usr where name = "jackxxxx" or email = "xxxx0@qq.com";
#注意 必须or两边都有索引才会使用索引