1,python中一个线程对应于c语言中的一个线程
gil使得同一个时刻只有一个线程在一个cpu上执行字节码, 无法将多个线程映射到多个cpu上执行
gil会根据执行的字节码行数以及时间片释放gil,gil在遇到io的操作时候主动释放
total = 0 def add(): #1. dosomething1 #2. io操作 # 1. dosomething3 global total for i in range(1000000): total += 1 def desc(): global total for i in range(1000000): total -= 1 import threading thread1 = threading.Thread(target=add) thread2 = threading.Thread(target=desc) thread1.start() thread2.start() thread1.join() thread2.join() print(total)
每一次运行的结果都会不一样,所以有GIL的python线程也不是安全的,但是python遇到io操作的话,会等到io操作时候主动释放GIL,
2,多线程编程
①对于io操作来说,多线程和多进程性能差别不大
----------------------------------------------------
方式1:
通过Thread类来实例化
import time import threading def get_detail_html(url): print("get detail html started") time.sleep(2) print("get detail html end") def get_detail_url(url): print("get detail url started") time.sleep(4) print("get detail url end") if __name__ =="__main__": thread1 = threading.Thread(target=get_detail_html, args=("",)) thread2 = threading.Thread(target=get_detail_url, args=("",)) start_time = time.time() thread1.start() thread2.start() print("last time {}".format(time.time()-start_time))
get detail html started get detail url started last time 0.0010006427764892578 get detail html end get detail url end
运行时间居然是0,两个线程并行时间不应该是2秒吗?其实实际上这是有3个线程,可以通过pycharm的IDE中进行debug
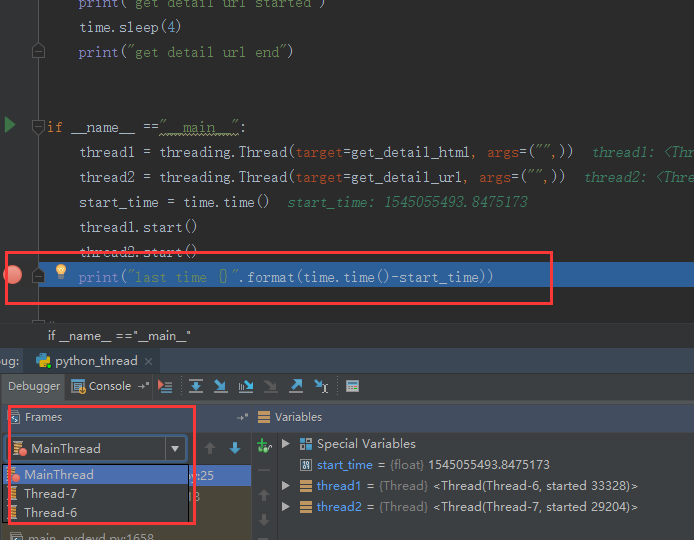 可以看得到其实是三个线程的
可以看得到其实是三个线程的
那就意味着三个线程并行,2个线程睡2秒,但第三个线程依旧可以继续向下进行,因为他们是并行的,因此,时间才会接近于0,
但是此时虽然主线程结束了,但是并没有退出!子线程依旧可以执行,如何设置主线程退出之后立即kill掉子线程呢?
thread1 = threading.Thread(target=get_detail_html, args=("",)) thread2 = threading.Thread(target=get_detail_url, args=("",)) start_time = time.time() thread1.setDaemon(True) # setDaemon 设置为True是将其设置为守护线程 thread2.setDaemon(True) thread1.start() thread2.start()
但是如何让这个主线程等待其余2个子线程结束之后再去执行呢?
thread1 = threading.Thread(target=get_detail_html, args=("",)) thread2 = threading.Thread(target=get_detail_url, args=("",)) start_time = time.time() thread1.start() thread2.start() thread1.join() thread2.join()
join()就是设置主线程必须等待子线程结束之后才能够退出,注意:必须在start()之后写
那如何简化多线程编程呢?(继承Thread类)
②通过继承Thread来实现多线程
class GetDetailHtml(threading.Thread): def __init__(self, name): super().__init__(name=name) def run(self): 重载run方法 print("get detail html started") time.sleep(2) print("get detail html end") class GetDetailUrl(threading.Thread): def __init__(self, name): super().__init__(name=name) def run(self): print("get detail url started") time.sleep(4) print("get detail url end")
if __name__ == "__main__": thread1 = GetDetailHtml("get_detail_html") thread2 = GetDetailUrl("get_detail_url") start_time = time.time() thread1.start() thread2.start() thread1.join() thread2.join() # 当主线程退出的时候, 子线程kill掉 print("last time: {}".format(time.time() - start_time))
那归根到底就能够自定义很多复杂的逻辑了
---------------------------------------------------------
线程间的通信和共享变量
从第一个例子中我们就公用了同一个total变量
但是共享变量会导致变量被反复修改
# 通过queue的方式进行线程间同步 from queue import Queue import time import threading def get_detail_html(queue): # 爬取文章详情页 while True: url = queue.get() # queue是一个阻塞方法,队列中没有值得时候他会一直阻塞 # for url in detail_url_list: print("get detail html started") time.sleep(2) print("get detail html end") def get_detail_url(queue): # 爬取文章列表页 while True: print("get detail url started") time.sleep(4) for i in range(20): queue.put("http://projectsedu.com/{id}".format(id=i)) # 队列满了也会阻塞住 print("get detail url end") # 1. 线程通信方式- 共享变量 if __name__ == "__main__": detail_url_queue = Queue(maxsize=1000) # 声明最大值的消息队列,线程是安全的 thread_detail_url = threading.Thread(target=get_detail_url, args=(detail_url_queue,)) for i in range(10): html_thread = threading.Thread(target=get_detail_html, args=(detail_url_queue,)) html_thread.start() # # thread2 = GetDetailUrl("get_detail_url") start_time = time.time() # thread_detail_url.start() # thread_detail_url1.start() # # thread1.join() # thread2.join() detail_url_queue.task_done() # 必须调用 detail_url_queue.join() # 和线程一致 # 当主线程退出的时候, 子线程kill掉 print("last time: {}".format(time.time() - start_time))
因此,当涉及到共享变量的时候,首先推荐采用queue来完成
1,线程安全
2,对于可以采用task_done 随时停止
-----------------------------------------------------------------------------------------
4,线程同步:(锁机制)
# -*- coding:UTF-8 -*- __autor__ = 'zhouli' __date__ = '2018/12/18 21:44' from threading import Lock total = 0 lock = RLock() def add(): # 1. dosomething1 # 2. io操作 # 1. dosomething3 global lock global total for i in range(1000000): lock.acquire() total += 1 lock.release() def desc(): global total global lock for i in range(1000000): lock.acquire() total -= 1 lock.release() import threading thread1 = threading.Thread(target=add) thread2 = threading.Thread(target=desc) thread1.start() thread2.start() # thread1.join() thread2.join() print(total) # 1. 用锁会影响性能 # 2. 锁会引起死锁 # 死锁的情况 A(a,b)
加锁一定要释放!!否则死锁!!
因为使用锁的情况下会很绕,所以python给我们重新定义了一个Rlock(可重入的锁)
# 在同一个线程里面,可以连续调用多次acquire, 一定要注意acquire的次数要和release的次数相等
代码修改如下:
from threading import Lock, RLock, Condition # 可重入的锁 # 在同一个线程里面,可以连续调用多次acquire, 一定要注意acquire的次数要和release的次数相等 total = 0 lock = RLock() def add(): # 1. dosomething1 # 2. io操作 # 1. dosomething3 global lock global total for i in range(1000000): lock.acquire() lock.acquire() total += 1 lock.release() lock.release() def desc(): global total global lock for i in range(1000000): lock.acquire() total -= 1 lock.release() import threading thread1 = threading.Thread(target=add) thread2 = threading.Thread(target=desc) thread1.start() thread2.start() # thread1.join() thread2.join() print(total) # 1. 用锁会影响性能 # 2. 锁会引起死锁 # 死锁的情况 A(a,b) """ A(a、b) acquire (a) acquire (b) B(a、b) acquire (a) acquire (b) """
在同一个线程里面才是如此,不同线程之间还是一个互相竞争的关系!
多线程的难点:condition(条件变量)
他是多线程中用于复杂的多线程通信中的锁,条件变量
通过源码可知其中的wait和notify方法
其中wait()方法是等待线程的的启动,notify去通知另一个线程的启动
import threading # 条件变量, 用于复杂的线程间同步 # class XiaoAi(threading.Thread): # def __init__(self, lock): # super().__init__(name="小爱") # self.lock = lock # # def run(self): # self.lock.acquire() # print("{} : 在 ".format(self.name)) # self.lock.release() # # self.lock.acquire() # print("{} : 好啊 ".format(self.name)) # self.lock.release() # # # class TianMao(threading.Thread): # def __init__(self, lock): # super().__init__(name="天猫精灵") # self.lock = lock # # def run(self): # self.lock.acquire() # print("{} : 小爱同学 ".format(self.name)) # self.lock.release() # # self.lock.acquire() # print("{} : 我们来对古诗吧 ".format(self.name)) # self.lock.release() # 通过condition完成协同读诗 class XiaoAi(threading.Thread): def __init__(self, cond): super().__init__(name="小爱") self.cond = cond def run(self): with self.cond: # 一定要使用with语句 self.cond.wait() # 后说话使用先要等待 print("{} : 在 ".format(self.name)) self.cond.notify() # 去通知 self.cond.wait() print("{} : 好啊 ".format(self.name)) self.cond.notify() self.cond.wait() print("{} : 君住长江尾 ".format(self.name)) self.cond.notify() self.cond.wait() print("{} : 共饮长江水 ".format(self.name)) self.cond.notify() self.cond.wait() print("{} : 此恨何时已 ".format(self.name)) self.cond.notify() self.cond.wait() print("{} : 定不负相思意 ".format(self.name)) self.cond.notify() class TianMao(threading.Thread): def __init__(self, cond): super().__init__(name="天猫精灵") self.cond = cond def run(self): with self.cond: print("{} : 小爱同学 ".format(self.name)) self.cond.notify() # 先去通知 self.cond.wait() # 等待 print("{} : 我们来对古诗吧 ".format(self.name)) self.cond.notify() self.cond.wait() print("{} : 我住长江头 ".format(self.name)) self.cond.notify() self.cond.wait() print("{} : 日日思君不见君 ".format(self.name)) self.cond.notify() self.cond.wait() print("{} : 此水几时休 ".format(self.name)) self.cond.notify() self.cond.wait() print("{} : 只愿君心似我心 ".format(self.name)) self.cond.notify() self.cond.wait() if __name__ == "__main__": from concurrent import futures cond = threading.Condition() xiaoai = XiaoAi(cond) tianmao = TianMao(cond) # 启动顺序很重要 # 在调用with cond之后才能调用wait或者notify方法 # condition有两层锁, 一把底层锁会在线程调用了wait方法的时候释放, 上面的锁会在每次调用wait的时候分配一把并放入到cond的等待队列中,等到notify方法的唤醒 xiaoai.start() tianmao.start()
5,Semaphore的使用
# Semaphore 是用于控制进入数量的锁 # 文件, 读、写, 写一般只是用于一个线程写,读可以允许有多个 # 做爬虫 import threading import time class HtmlSpider(threading.Thread): def __init__(self, url, sem): super().__init__() self.url = url self.sem = sem def run(self): time.sleep(2) print("got html text success") self.sem.release() # 一定要注意锁的释放的位置,一旦锁被释放sem就会增加1 class UrlProducer(threading.Thread): def __init__(self, sem): super().__init__() self.sem = sem def run(self): for i in range(20): self.sem.acquire() html_thread = HtmlSpider("https://baidu.com/{}".format(i), self.sem) html_thread.start() if __name__ == "__main__": sem = threading.Semaphore(3) url_producer = UrlProducer(sem) url_producer.start()
6,线程池
from concurrent.futures import ThreadPoolExecutor
为什么要线程池?
主线程中可以获取某一个线程的状态或者某一个任务的状态,以及返回值
当一个线程完成的时候我们主线程能立即知道
futures可以让多线程和多进程编码接口一致
from concurrent.futures import ThreadPoolExecutor, as_completed, wait, FIRST_COMPLETED # 未来对象,task的返回容器 # 线程池, 为什么要线程池 # 主线程中可以获取某一个线程的状态或者某一个任务的状态,以及返回值 # 当一个线程完成的时候我们主线程能立即知道 # futures可以让多线程和多进程编码接口一致 import time def get_html(times): time.sleep(times) print("get page {} success".format(times)) return times executor = ThreadPoolExecutor(max_workers=2) # 通过submit函数提交执行的函数到线程池中, submit 是立即返回 task1 = executor.submit(get_html, (3,)) # 第一个参数是函数名称,第二个参数是参数 task2 = executor.submit(get_html, (2,)) # submit的返回时是非常重要,用于判断是否执行成功等 print(task1.done) # 判断任务是否完成
 结果
结果
当然task1.result()方法也是可以的,查看task的结果
实际上我们也可以将某一个任务关闭掉,但是要注意,任务在执行中或者是执行完成时是无法取消的,只有未开始执行才会被cancel()掉
# 要获取已经成功的task的返回 urls = [3, 2, 4] all_task = [executor.submit(get_html, (url,)) for url in urls] for future in as_completed(all_task): # as_completed 实际上是一个生成器,将已经完成的返回 data = future.result() print("get {} page".format(data))
这个执行结果顺序是谁先完成任务谁先出来
或者
# 要获取已经成功的task的返回 urls = [3, 2, 4] all_task = [executor.submit(get_html, (url,)) for url in urls] # for future in as_completed(all_task): # as_completed 实际上是一个生成器,将已经完成的返回 # data = future.result() # print("get {} page".format(data)) # 通过executor的map获取已经完成的task的值 for data in executor.map(get_html, urls): # map方法更加简单 print("get {} page".format(data))
但是这样和上面的不一样的是,这边直接返回的就是结果了,也就是data = future.result()这一步被省略了
而且map方法返回的顺序是列表的顺序
wait 方法:(让主线程进行阻塞)
# 要获取已经成功的task的返回 urls = [3, 2, 4] all_task = [executor.submit(get_html, (url,)) for url in urls] wait(all_task, return_when=FIRST_COMPLETED) # 让主线程阻塞,如果没有return_when参数 默认是等待全部任务结束放行 print("main") # for future in as_completed(all_task): # as_completed 实际上是一个生成器,将已经完成的返回 # data = future.result() # print("get {} page".format(data)) # 通过executor的map获取已经完成的task的值 for data in executor.map(get_html, urls): # map方法更加简单 print("get {} page".format(data))
放上完整版
from concurrent.futures import ThreadPoolExecutor, as_completed, wait, FIRST_COMPLETED from concurrent.futures import Future from multiprocessing import Pool # 未来对象,task的返回容器 # 线程池, 为什么要线程池 # 主线程中可以获取某一个线程的状态或者某一个任务的状态,以及返回值 # 当一个线程完成的时候我们主线程能立即知道 # futures可以让多线程和多进程编码接口一致 import time def get_html(times): time.sleep(times) print("get page {} success".format(times)) return times executor = ThreadPoolExecutor(max_workers=2) # 通过submit函数提交执行的函数到线程池中, submit 是立即返回 task1 = executor.submit(get_html, (3,)) # 第一个参数是函数名称,第二个参数是参数 task2 = executor.submit(get_html, (2,)) # submit的返回时是非常重要,用于判断是否执行成功等 # 要获取已经成功的task的返回 urls = [3, 2, 4] all_task = [executor.submit(get_html, (url,)) for url in urls] wait(all_task, return_when=FIRST_COMPLETED) # 让主线程阻塞,如果没有return_when参数 默认是等待全部任务结束放行 print("main") # for future in as_completed(all_task): # as_completed 实际上是一个生成器,将已经完成的返回 # data = future.result() # print("get {} page".format(data)) # 通过executor的map获取已经完成的task的值 for data in executor.map(get_html, urls): # map方法更加简单 print("get {} page".format(data)) # #done方法用于判定某个任务是否完成 # print(task1.done()) # print(task2.cancel()) # time.sleep(3) # print(task1.done()) # # #result方法可以获取task的执行结果 # print(task1.result())