何为回归?
“回归”一词是由达尔文的表兄弟Francis Galton发明的。Galton于1877年完成了第一次回归预测,目的是根据上一代豌豆种子(双亲)的尺寸来预测下一代豌豆种子(孩子)的尺寸。
Galton在大量对象上应用了回归分析,甚至包括人的身高预测。他注意到,如果双亲的高高度比平均高度高,他们的子女也倾向于比平均高度高,但尚不及双亲(笔者感觉未必,Galton并未考虑物质条件的发展会带来整体身高的增加,至少笔者感觉80,90的人普遍比父母高)。孩子的高度向着平均高度“回归”。
在软件测试方法论中有回归测试一说,大概是指保证原feature正确,没有收到改动的影响。
用线性回归找到最佳拟合直线
回归的目的是预测数值型的目标值。最直接的办法就是求得一个回归方程(regression equation),讲已知条件x代入方程得到预测结果y。
说道回归,一般都是指线性回归,线性回归意味着可以将输入项分别乘以一些常量,再将结果加起来得到输出。
如何求回归方程的主要步骤是求回归系数,一旦有了回归系数,就可以构造出回归方程。
假定输入数据存放在矩阵X中,而回归系数存放在向量w中,那么对于给定的数据X1,预测结果将会通过Y1=XT1w给出。
那么,如果通过已知的x和y关系集合,找到w呢?一个常用的方法就是找出使误差最小的w。这里的误差指的是预测y值和真实y值之间的差值。可以通过使用该误差的累加得出x,y关系集合的最佳w。可是由于累加将使正差值和负差值相互抵消,所以在计算的时候采用平方误差:
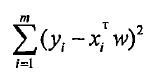
用矩阵表示还可以写作(y-Xw)T (y-Xw)。如果对w求导,得到XT(Y-Xw),令其等于0,解出w:
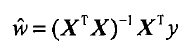
w上的小标记表示,这是当前可以估计出的w的最优解。
注意,上述公式中包含(XTX)-1,也就是需要对矩阵求逆。因此这个方程只在逆矩阵存在的情况下适用。
除了矩阵方法外,还有很多其他的方法可以求解w,比如“普通最小二乘法”。
求w的代码:
def loadDataSet(fileName): #general function to parse tab -delimited floats numFeat = len(open(fileName).readline().split(' ')) - 1 #get number of fields dataMat = []; labelMat = [] fr = open(fileName) for line in fr.readlines(): lineArr =[] curLine = line.strip().split(' ') for i in range(numFeat): lineArr.append(float(curLine[i])) dataMat.append(lineArr) labelMat.append(float(curLine[-1])) return dataMat,labelMat def standRegres(xArr,yArr): xMat = mat(xArr); yMat = mat(yArr).T xTx = xMat.T*xMat if linalg.det(xTx) == 0.0: #判断是否存在逆矩阵 print "This matrix is singular, cannot do inverse" return ws = xTx.I * (xMat.T*yMat) return ws
局部加权线性回归
线性回归的一个问题是有可能出现欠拟合现象,因为它要求的是具有最小均方误差的无偏估计。显而易见,如果模型欠拟合将不能取得最好的预测效果。所以有些方法允许在估计中引入一些偏差,从而降低预测的均方误差。
其中的一个方法是局部加权线性回归(Locally Weighted Linear Regression, LWLR)。在该算法中个,我们给待预测点的附近的每个点赋予一定的权重,在这个子集上基于最小均方差来进行普通的回归。与KNN一样,这种算法每次预测均需要事先取出对应的数据子集。该算法解除回归系数w的形式如下:
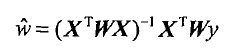
其中w是一个矩阵,用来给每个数据点赋予权重。
LWLR使用“核”来对附近的点赋予更高的权重。核的类型可以自由选择,最常用的核就是高斯核,高斯核对应的权重如下:
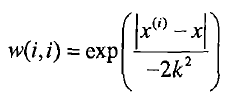
上述公式中包含了一个需要用户指定的参数K,它决定了对附近的点赋予多大的权重。
LWLR的实现代码:
def lwlr(testPoint,xArr,yArr,k=1.0): xMat = mat(xArr); yMat = mat(yArr).T m = shape(xMat)[0] weights = mat(eye((m))) for j in range(m): #next 2 lines create weights matrix diffMat = testPoint - xMat[j,:] # weights[j,j] = exp(diffMat*diffMat.T/(-2.0*k**2)) xTx = xMat.T * (weights * xMat) if linalg.det(xTx) == 0.0: print "This matrix is singular, cannot do inverse" return ws = xTx.I * (xMat.T * (weights * yMat)) return testPoint * ws def lwlrTest(testArr,xArr,yArr,k=1.0): #loops over all the data points and applies lwlr to each one m = shape(testArr)[0] yHat = zeros(m) for i in range(m): yHat[i] = lwlr(testArr[i],xArr,yArr,k) return yHat