在面试过程中,关于Java的内存模型(侧重于:Java的并发原理)和JVM的内存模型并不是同一个问题,所以自己在通过查询资料之后对相关的知识点进行总结,如果有写得错误的地方,欢迎指出,也可以一起探讨。
基于计算机的内存设计结构,CPU在发展过程中,运行速度越来越快,内存的读写速度跟不上CPU的运行速度,因此提出来“缓存” 的概念。CPU在读写过程中,可以将数据先写入缓存中,然后缓存将数据刷新到主存中。因此,在多线程的场景下就会出现“缓存不一致的情况”,就是多个线程对同一个数据的缓存可能不一致。
基于数据的安全,需要满足原子性、可见性、有序性
再具体的关于CPU和内存之间的爱恨纠缠目前我就没有在深入,感兴趣的同学可以自己去了解一下
Java内存模型(JMM)
·· Java内存模型就是一种符合内存模型规范的,屏蔽了各种硬件和操作系统的访问差异,保证了Java程序在各种平台下对内存的访问都能保证其效果一致的机制和规范
首先提一下三个概念,基本上内存模型就是为了解决这三个问题
原子性:一个操作中CPU不能暂停、中断,要么执行完成,要么不执行
可见性:多个线程访问同一个变量时,一个线程对变量进行修改之后,其他线程能够立即看到修改后的值
有序性:程序按照顺序执行代码
总结:JMM是一种规范,用于处理多线程共享内存时存在内存和缓存数据不一致的问题
Java内存模型如何实现
Java中提供了一系列和并发相关的关键字,比如:volatile、synchronized、final、concurren
其实这些就是Java内存模型封装在底层中实现后提供给程序员使用的关键字
本文的重点在于了解JMM,所以不会对相关的关键字进行详细的介绍!!!!
synchronized 用于保证 原子性
volatile 用于保证可见性
volatile 和synchronized 都可以实现可见性
JVM内存模型
Java虚拟机將管理的内存分成了五大区域:
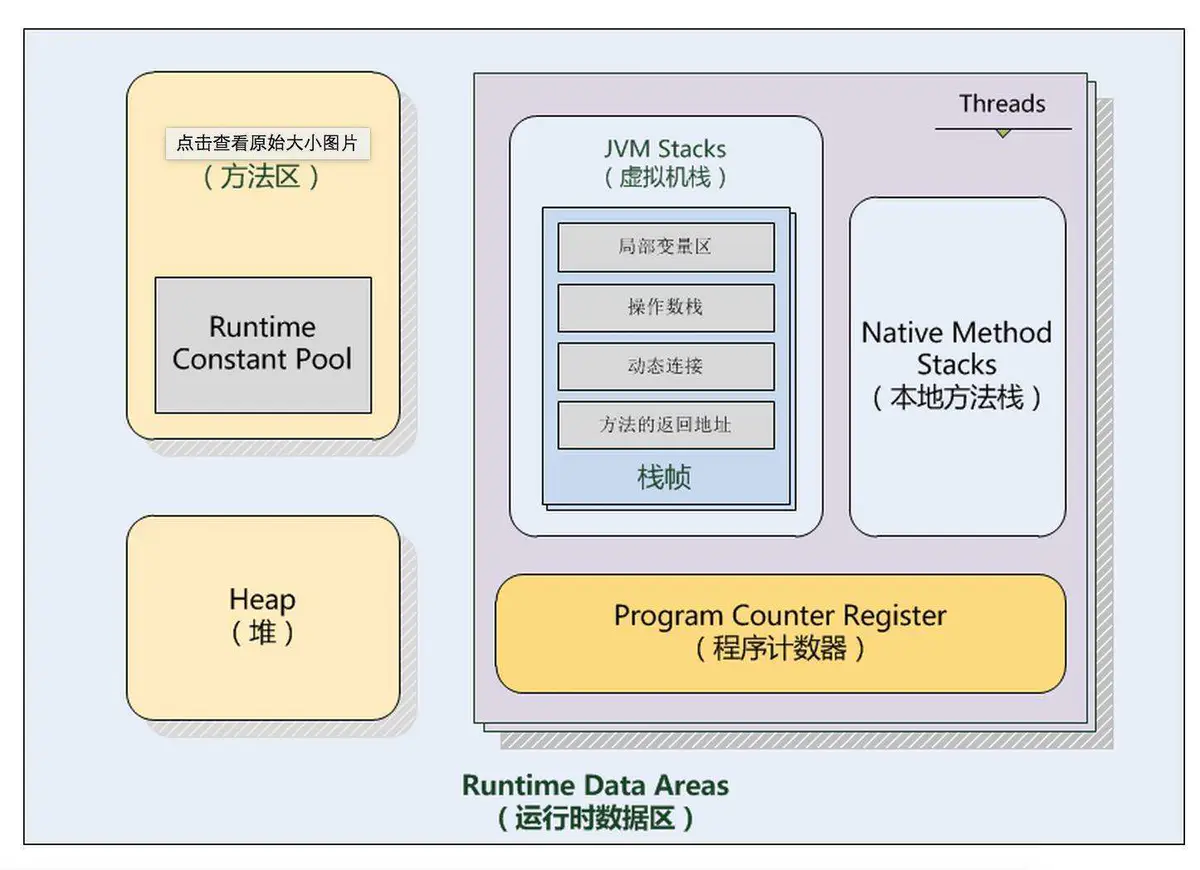
1.程序计数器
概念:程序计数器是一块很小的内存空间,它是线程私有的,可以认作为当前线程的行号指示器。
目的:CPU在执行多线程任务时,为了确保线程能够正常切换到正确的执行位置,每个线程都有一个独立的程序计数器,不同线程之间的程序计数器互不影响,独立存储。
注意:如果线程执行的是个java方法,那么计数器记录虚拟机字节码指令的地址。如果为native【底层方法】,那么计数器为空。这块内存区域是虚拟机规范中唯一没有OutOfMemoryError的区域
2.Java栈(虚拟机栈)
概念:栈描述的是Java方法执行的内存模型,每个方法在被执行的时候都会创建一个自己的内存栈用于存放局部的变量等相关信息,存放的方式是逐个存放,所以这里有个栈先进后出的过程。
当方法执行完成之后,内存栈被销毁,所以方法中定义的变量都是放置在内存栈中。
3.堆
概念:堆是Java虚拟机中内存最大的一个块内存区域,因为堆存放的对象是线程共享的,所以多线程的时候也需要同步机制。所有的对象实例及数组大多数都是在堆上分配内存,之所以不是都是这样,原因在于JIT编译器技术的成熟,这个说法不是这么绝对了。
注意:为什么会有栈和堆之分:
当一个方法执行时,每个方法都是建立自己的内存栈用于存放方法中定义的变量,在方法结束后进行销毁,但是在程序中创建一个对象时,这个对象将被保存在堆中(也可以称为:运行时数据区,堆是其中的一部分),方便可以反复的使用,这是因为创建对象的成本通常会比较的大。既让这样,那么在堆内存的中的对象就不会随着方法的结束而销毁,当这个对象被一个方法引用完了之后还可能被其他的引用变量使用,则这个对象就不会被销毁。只有在一个对象没有任何的引用变量引用他时,系统的垃圾回收机制才会在合适的时候回收他(是不是听起来很熟悉,特别的像GC)
4.方法区
概念: 方法区和堆的概念比较类似,就是所有线程共享的内存,为了和堆进行区分,又被称为了“非堆”
目的:用于存储已被虚拟机加载的类信息、常量、静态变量
5.本地方法栈
概念:本地方法栈是与虚拟机栈发挥的作用十分相似,区别是虚拟机栈执行的是Java方法(也就是字节码)服务,而本地方法栈则为虚拟机使用到的native方法服务,可能底层调用的c或者c++,我们打开jdk安装目录可以看到也有很多用c编写的文件,可能就是native方法所调用的c代码。
GC:java GC泛指java的垃圾回收机制,该机制是java与C/C++的主要区别之一
目的:为了解决内存泄露的问题(尽量解决,毕竟该泄露的还是会泄露)
GC这边我就不做详细的介绍了,毕竟自己也在学习过程中,GC是可以拿出来讲好久的内容,目前我还没有进行总结。