多任务编程
概念
同一时间执行多个任务
执行方式
- 并发:在一段时间内交替执行任务(单核CPU)
- 并行:给CPU每个核分配任务(多核CPU,真正的多任务)
进程与线程
- 一个正在运行的程序或软件就是一个进程
- 注意:一个程序至少有一个进程,至少有一个线程
- 关系:进程就是一个公司,负责提供办公室、电脑...(向CPU索要资源),公司里的员工就是线程(真正负责干活的是线程)
多进程
1. 进程理论基础
- 定义:程序在计算机中的一次执行
- 程序是一个可执行的文件,是静态的占有磁盘
- 进程是一个动态的过程描述,占有计算机运行资源,有一定生命周期
-
系统中如何产生一个进程
【1】 用户空间通过调用程序接口或者命令发起请求
【2】 操作系统接收用户请求,开始创建进程
【3】 操作系统调配计算机资源,确定进程状态等
【4】 操作系统将创建的进程提供给用户使用 -
进程基本概念
- CPU时间片:如果一个进程占有CPU内核,则称这个进程在CPU时间片上
- PCB(进程控制模块):在内存中开辟的一块空间,用于存放进程的基本信息,也用于系统查找识别进程
- 进程ID(PID):系统为每个进程分配的一个大于0的整数,作为进程ID。每个进程ID不重复
Linux查看进程ID:ps -aux
- 父子进程:系统中每一个进程(除了系统初始化进程),都有唯一的父进程,可以有0个或多个子进程。父子进程关系便于进程管理
查看进程树:pstree
- 进程状态
- 三态
就绪态:进程具备执行条件,等待分配CPU资源
运行态:进程占有CPU时间片正在运行
阻塞态:进程不具备执行条件,等待条件满足
- 三态
2. 创建进程
【1】 进程类
import multiprocessing
【2】 参数
multiprocessing.Process(
group=None, # 指定进程组,一般不用
target=None, # 执行的目标任务名(函数)
name=None, # 进程名
args=(), # 以元组传参
kwargs={}, # 以字典传参
*,
daemon=None, # 守护进程
)
【3】 类方法(常用)
p = Process()
p.start() # 启动子进程
p.join() # 阻塞主进程直到子进程执行结束
p.terminate() # 中止子进程
p.daemon = True # 设为守护进程
【4】 创建进程的两种方法
- 一、实例化Process类
p = Process() - 二、继承并重写__init__和run方法
class MyProcess(Process): def __init__(self): ... def run(self): ...
实例1:
from multiprocessing import Process
from time import sleep
def do():
for i in range(3):
print('.........
',end='')
sleep(0.1)
def do2():
for i in range(3):
print('aaaaaaaaaaa
',end='')
sleep(0.1)
if __name__ == '__main__':
p1 = Process(target=do)
p2 = Process(target=do2)
p1.start()
p2.start()
运行结果:
.........
aaaaaaaaaaa
aaaaaaaaaaa
.........
aaaaaaaaaaa
.........
注意!进程执行是无序的
【4】进程相关操作
os.getpid() # 获取当前进程编号
os.getppid() # 获取父进程编号
os.kill(pid,9) # 杀死进程(Linux)
os.popen(f'taskkill /pid {pid}') # 杀死进程(Windows)
multiprocessing.current_process() # 获取进程对象
multiprocessing.cpu_count() # 获取CPU内核数
【5】 注意事项
- 进程会把if name == 'main'上面的所有代码复制一遍,因此必须加上if name == 'main'
- 子进程是父进程的拷贝,因此进程间不共享全局变量
- 守护进程会随主进程的结束而销毁
3. 进程池
-
必要性
【1】 进程的创建和销毁过程消耗的资源较多
【2】 当任务众多时,每个任务在很短的时间内完成时,需要频繁地创建和销毁进程。此时对计算机压力较大
【3】 进程池技术很好的解决了以上问题 -
原理
创建一定数量的进程来处理事件,事件处理完进程不退出而是继续处理其他事件,直到所有事件全部处理完毕统一销毁。增加进程的重复利用,降低资源消耗
-
进程池实现
【1】 创建进程池对象,放入适当的进程
from multiprocessing import Pool Pool(processes) 功能:创建进程池对象 参数:指定进程数量,默认根据系统自动判定【2】 将事件加入进程池队列执行
pool.apply_async(func,args,kwds) 功能:使用进程池执行func事件 参数:func 事件函数 args 元组 给func按位置传参 kwds 字典 给func按照键值传参【3】 关闭进程池
pool.close() 功能:关闭进程池,无法再向进程池中加入进程【4】 回收进程池中进程
pool.join() 功能:回收进程池中进程 -
实例
from multiprocessing import Pool import os from time import sleep,ctime def do(): for i in range(3): print(f'{os.getpid()}:hhhhhhhhh {ctime()} ',end='') sleep(0.01) if __name__ == '__main__': pool = Pool(10) # 创建进程池 for i in range(10): # 向进程池中加入事件 pool.apply_async(func=do) pool.close() # 关闭进程池 pool.join() # 回收进程,阻塞主进程 print('主进程结束')运行结果:
15552:hhhhhhhhh Thu Aug 20 19:46:36 2020 7544:hhhhhhhhh Thu Aug 20 19:46:36 2020 15552:hhhhhhhhh Thu Aug 20 19:46:36 2020 4400:hhhhhhhhh Thu Aug 20 19:46:36 2020 4400:hhhhhhhhh Thu Aug 20 19:46:36 2020 15552:hhhhhhhhh Thu Aug 20 19:46:36 2020 7544:hhhhhhhhh Thu Aug 20 19:46:36 2020 11988:hhhhhhhhh Thu Aug 20 19:46:36 2020 1824:hhhhhhhhh Thu Aug 20 19:46:36 2020 11456:hhhhhhhhh Thu Aug 20 19:46:36 2020 11988:hhhhhhhhh Thu Aug 20 19:46:36 2020 7544:hhhhhhhhh Thu Aug 20 19:46:36 2020 4400:hhhhhhhhh Thu Aug 20 19:46:36 2020 15552:hhhhhhhhh Thu Aug 20 19:46:36 2020 4596:hhhhhhhhh Thu Aug 20 19:46:36 2020 8532:hhhhhhhhh Thu Aug 20 19:46:36 2020 15552:hhhhhhhhh Thu Aug 20 19:46:36 2020 11988:hhhhhhhhh Thu Aug 20 19:46:36 2020 4400:hhhhhhhhh Thu Aug 20 19:46:36 2020 11456:hhhhhhhhh Thu Aug 20 19:46:36 2020 1824:hhhhhhhhh Thu Aug 20 19:46:36 2020 1824:hhhhhhhhh Thu Aug 20 19:46:36 2020 11456:hhhhhhhhh Thu Aug 20 19:46:36 2020 4400:hhhhhhhhh Thu Aug 20 19:46:36 2020 15552:hhhhhhhhh Thu Aug 20 19:46:36 2020 8532:hhhhhhhhh Thu Aug 20 19:46:36 2020 4596:hhhhhhhhh Thu Aug 20 19:46:36 2020 4596:hhhhhhhhh Thu Aug 20 19:46:36 2020 4400:hhhhhhhhh Thu Aug 20 19:46:36 2020 8532:hhhhhhhhh Thu Aug 20 19:46:36 2020 主进程结束
4.进程间通信(IPC)
- 必要性:进程空间独立,资源不共享,此时在需要进程间数据传输时就需要特定的手段进行数据通信
- 常用进程通信方法
管道、消息队列、共享内存、信号、信号量、套接字
消息队列
-
通信原理
在内存中建立队列模型,进程通过队列将消息存入,或者从队列中取出完成进程间通信
注意!消息队列应在主进程中创建
-
实现方法
from multiprocessing import Queue q = Queue(maxsize=0) 功能:创建队列对象 参数:最多存放消息个数 返回值:队列对象 q.put(data,[block,timeout]) 功能:向队列存入消息 参数:data 要存入的内容 block 设置是否阻塞 False为非阻塞, 如果block为True,当消息队列满了时就会阻塞, 如果block为False,则会直接报错queue.Full timeout 超时检测(最多阻塞的时间) q.get([block,timeout]) 功能:从队列取出消息 注意!队列中的消息是先进先出 参数:block 设置是否阻塞 False为非阻塞 timeout 超时检测 返回值:获取到的内容 q.full() # 判断队列是否为满 q.empty() # 判断队列是否为空 q.qsize() # 获取队列中消息个数 q.close() # 关闭队列 -
实例
from multiprocessing import Queue,Process from time import sleep ''' 消息队列演示 注意!多个进程需要使用同一个消息队列 ''' def request(q1,q2): print('使用wx登录?') q1.put('请求用户名密码') # 写消息队列 data = q2.get() print(f'获取到信息:{data}') def handler(q1,q2): data = q1.get() # 读消息队列 print('收到请求:',data) sleep(0.1) q2.put({'name':'Zhang','passwd':'123'}) if __name__ == '__main__': # 消息队列 q1 = Queue(3) q2 = Queue(3) p1 = Process(target=request,args=(q1,q2)) p2 = Process(target=handler,args=(q1,q2)) p1.start() p2.start() p1.join() p2.join()运行结果:
使用wx登录? 收到请求: 请求用户名密码 获取到信息:{'name': 'Zhang', 'passwd': '123'}在实际应用中,一般会创建多个消息队列分别用于读、写,或是一个进程只读,另一个进程只写
僵尸进程(Linux)
僵尸进程是当子进程比父进程先结束,而父进程又没有回收子进程,释放子进程占用的资源,此时子进程将成为一个僵尸进程(有害)。如果父进程先退出 ,子进程(孤儿进程,无害)被init接管,子进程退出后init会回收其占用的相关资源
注意!僵尸进程无法通过 kill 命令来清除
示例:
from multiprocessing import Process, current_process
import logging
import os
import time
logging.basicConfig(
level=logging.DEBUG,
format='%(asctime)-15s - %(levelname)s - %(message)s'
)
def run():
logging.info('exit child process %s', current_process().pid)
os._exit(3)
if __name__ == '__main__':
p = Process(target=run)
p.start()
time.sleep(100)
运行结果:
2020-08-21 18:36:17,783 - INFO - exit child process 13972
清理僵尸进程方法:
- 第一种方法就是结束父进程。当父进程退出的时候僵尸进程随后也会被清除。
- 第二种方法就是通过 wait 调用来读取子进程退出状态。我们可以通过处理 SIGCHLD 信号,在处理程序中调用 wait 系统调用来清除僵尸进程
- 第三种办法就说把进程变成孤儿进程,这样进程就会自动交由 init 进程(pid 为 1 的进程)来处理,一般 init 进程都包含对僵尸进程进行处理的逻辑。(这里有个坑,那就是 docker 容器中一般 pid 为 1 进程就是主程序的进程,而不是我们预期的 init 进程。如果要使用这种方法的话,需要注意一下类似的场景)
多线程
线程基本概念
- 什么是线程
【1】 线程被称为轻量级的进程
【2】 线程也可以使用计算机多核资源,是多任务编程方式
【3】 线程是系统分配内核的最小单元
【4】 线程可以理解为进程的分支任务 - 线程特征
【1】 一个进程中可以包括多个线程
【2】 线程也是一个运行行为,消耗计算机资源
【3】 一个进程中的所有线程共享这个进程的资源
【4】 多个线程之间的运行互不影响各自运行
【5】 线程的创建和销毁消耗资源远小于进程
threading模块创建线程
【1】 创建线程
from threading import Thread
t = Thread()
功能:创建线程对象
参数:target 绑定线程函数
args 元组 给线程函数位置传参
kwargs 字典 给线程函数键值传参
【2】 启动线程
t.start()
【3】 回收线程
t.join([timeout])
功能:阻塞主线程直到子线程执行结束
线程对象属性
t.name 线程名称
t.setName() 设置线程名称
t.getName() 获取线程名称
t.daemon = True 设置为守护线程,即主线程执行完后自动销毁守护线程
实例1:
from threading import Thread
from time import sleep,ctime
def do(id):
for i in range(3):
sleep(0.1)
print(f'线程{id}:{ctime()}
',end='')
if __name__ == '__main__':
t1 = Thread(target=do,args=(1,))
t2 = Thread(target=do, args=(2,))
t1.start()
t2.start()
实例2:
from threading import Thread
from time import sleep,ctime
def do(id):
for i in range(3):
sleep(0.1)
print(f'线程{id}:{ctime()}
',end='')
class MyThread(Thread):
def __init__(self,id):
self.id = id
Thread.__init__(self)
def run(self):
do(self.id)
if __name__ == '__main__':
t1 = MyThread(1)
t2 = MyThread(2)
t1.start()
t2.start()
运行结果:
线程2:Thu Aug 20 21:22:35 2020
线程1:Thu Aug 20 21:22:35 2020
线程1:Thu Aug 20 21:22:36 2020
线程2:Thu Aug 20 21:22:36 2020
线程2:Thu Aug 20 21:22:36 2020
线程1:Thu Aug 20 21:22:36 2020
显然,线程的执行也是无序的
实例3:
from threading import Thread
data = ''
def write():
global data
data = 'write'
def read():
global data
print(f'data = {data}')
if __name__ == '__main__':
t1 = Thread(target=write)
t2 = Thread(target=read)
t1.start()
t2.start()
运行结果:
data = write
这个例子说明:线程之间共享全局变量
同步互斥
线程之间的通信方法
- 通信方法
线程之间使用全局变量进行通信
- 共享资源争夺
- 共享资源:多个进程或线程都可以操作的资源被称为共享资源。对共享资源的操作代码段称为临界区
- 影响:对共享资源的无序操作可能会带来数据的混乱(脏数据)或者操作错误。此时往往需要同步互斥机制协调操作顺序
- 同步互斥机制
同步:同步是一种协作关系,为完成操作,多进程或者线程间形成一种协调,按照必要的步骤有序执行操作

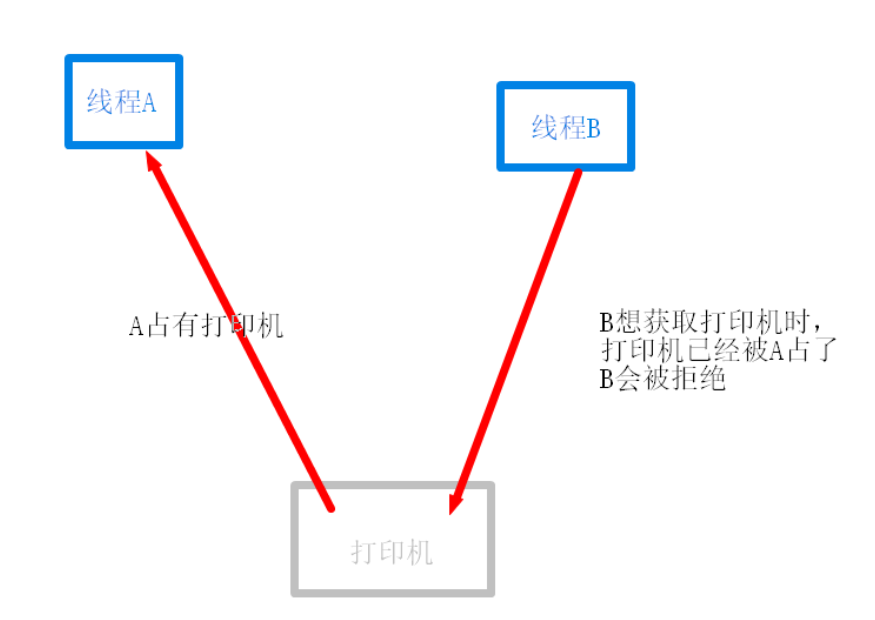
互斥是一种制约关系,当一个进程或线程占有资源时会进行加锁处理,此时其他进程线程就无法操作该资源,直到解锁后才能操作
线程Event
from threading import Event
e = Event() # 创建线程Event对象
e.wait([timeout]) # 阻塞等待e被set,timeout为超时时间
e.set() # 设置e,使wait结束阻塞
e.clear() # 使e回到未被设置状态
e.is_set() # 查看当前e是否被设置

实例:
from threading import Event,Thread
'''
Event互斥方法
'''
s = None # 用于通信
e = Event()
def yzr():
print('杨子荣前来拜山头
',end='')
# 临界区
global s
s = '天王盖地虎'
e.set() # 解除wait阻塞
if __name__ == '__main__':
t = Thread(target=yzr)
t.start()
print('说对口令就是自己人')
e.wait(3) # 阻塞等待说口令
if s == '天王盖地虎':
print('宝塔镇河妖')
print('确认过眼神,你是自己人')
else:
print('兄弟们,打死他')
运行结果:
杨子荣前来拜山头
说对口令就是自己人
宝塔镇河妖
确认过眼神,你是自己人
线程锁Lock
- 多个线程会去抢锁,抢到的先执行
from threading import Lock
lock = Lock() # 创建锁
lock.acquire() # 上锁
lock.release() # 解锁
with lock: # 上锁
...
# with代码块结束自动解锁
实例:
from threading import Thread,Lock
from random import random
value = 0
lock = Lock() # 创建锁
def js():
for i in range(10000):
x = random()
y = random()
if (x**2 + y**2)**0.5 < 1:
lock.acquire()
global value
value += 1
lock.release()
'''
with lock:
value += 1
'''
else:
continue
if __name__ == '__main__':
thread_list = []
for i in range(1000):
t = Thread(target=js)
t.start()
thread_list.append(t)
for i in thread_list:
i.join()
print(f'π ≈ {value/10000000 * 4}')
运行结果:
π ≈ 3.1417504
死锁及其处理
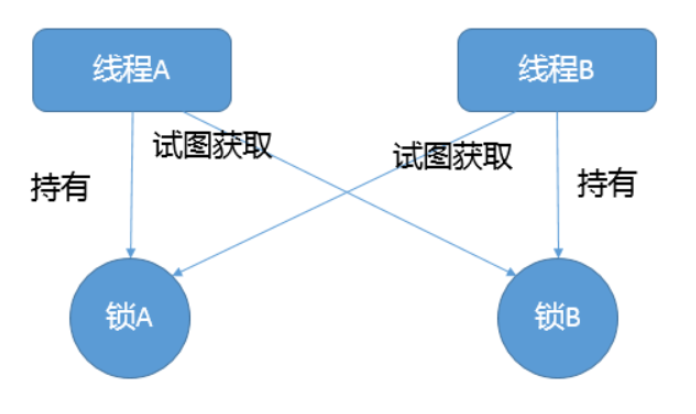
- 定义
死锁是指两个或两个以上的线程在执行过程中,由于竞争资源或者彼此通信而造成的一种阻塞现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁
-
死锁产生条件
死锁发生的必要条件
-
互斥条件:进程要求对所分配的资源(如打印机)进行排他性控制,即在一段时间内某资源仅为一个进程所占有。此时若有其他进程请求该资源,则请求进程只能等待
-
请求和保持条件:进程已经保持了至少一个资源,但又提出了新的资源请求,而该资源已被其他进程占有,此时请求进程被阻塞,但对自己已获得的资源保持不放
-
不剥夺条件:进程所获得的资源在未使用完毕之前,不能被其他进程强行夺走,即只能由获得该资源的进程自己来释放,通常CPU内存资源是可以被系统强行调配剥夺的
-
环路等待条件:指在发生死锁时,必然存在一个进程——资源的环形链,即进程集合{P0,P1,P2,···,Pn}中的P0正在等待一个P1占用的资源;P1正在等待P2占用的资源,……,Pn正在等待已被P0占用的资源
死锁的产生原因
简单来说造成死锁的原因可以概括成三句话:
- 当前线程拥有其他线程需要的资源
- 当前线程等待其他线程已拥有的资源
- 都不放弃自己拥有的资源。
-
-
如何避免死锁
死锁是我们非常不愿意看到的一种现象,我们要尽可能避免死锁的情况发生。通过设置某些限制条件,去破坏产生死锁的四个必要条件中的一个或几个,来预防发生死锁。预防死锁是一种较易实现的方法,但由于所施加的限制条件往往太严格,可能会导致系统资源利用率低。
Python线程GIL
-
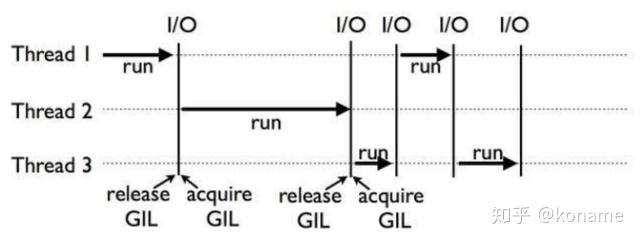
Python线程GIL问题(全局解释器锁)
什么是GIL:由于Python解释器设计中加入了解释器锁,导致Python解释器同一时刻只能解释执行一个线程。大大降低了线程的执行效率。
导致后果:因为遇到阻塞时,线程会自动让出解释器去解释其它线程,所以Python多线程在执行多阻塞高延迟IO时可以提升程序效率。其他情况并不能对效率有所提升。
单核CPU:
多核CPU:

GIL问题建议
- 尽量使用进程完成无阻塞的并发行为
- 不使用C作为解释器(Java C#)
-
结论:在无阻塞状态下,多线程程序和单线程程序执行效率几乎差不多,甚至还不如单线程效率。但是多进程运行相同内容却可以有明显的效率提升。
常见网络通信模型
-
循环服务器模型:循环接收客户端请求,处理请求。同一时刻只能处理一个请求,处理完毕后再处理下一个。
优点:实现简单,占用资源少
缺点:无法同时处理多个客户端请求
适用情况:处理的任务可以很快完成,客户端无需长期占用服务端程序。UDP比TCP更适合循环
-
多进程/线程网络并发模型:每当一个客户端连接服务器就创建一个新的进程/线程为该客户端服务。客户端退出时再销毁该进程/线程。
优点:能同时满足多个客户端长期占有服务端需求,可以处理各种请求。
缺点:资源消耗较大
使用情况:客户端同时连接量较少,需要处理行为较复杂情况。
-
IO并发模型:利用IO多路复用,异步IO等技术,同时处理多个客户端IO请求
优点:资源消耗较少,能同时高效处理多个IO行为。
缺点:只能处理并发产生的IO事件,无法处理CPU计算。
IO并发
IO分类
阻塞IO,非阻塞IO,IO多路复用,异步IO等
阻塞IO
-
定义:在执行IO操作时如果执行条件不满足则阻塞。阻塞是IO的默认状态。
-
效率:阻塞IO是效率很低的一种IO,但是由于逻辑简单,所以是默认IO行为。
-
阻塞情况:
-
因为某种执行条件没有满足造成的函数阻塞
-
处理IO的时间较长产生的阻塞状态,如:网络传输、大文件读写
非阻塞IO
- 定义:通过修改IO属性行为,使原本阻塞的IO变为非阻塞的状态。
-
设置套接字为非阻塞IO
sockfd.setblocking(bool)
功能:设置套接字为非阻塞IO
参数:默认为True,表示套接字为阻塞IO;设置为Falsw则套接字IO变为非阻塞
-
超时检测:设置一个最长阻塞时间,超过该时间后则不再阻塞等待。
sockfd.settimeout(timeout)
实例:
# test.py
import socket
from time import sleep
import logging
logging.basicConfig(
level=logging.DEBUG,
format='%(asctime)s - %(name)s - %(levelname)s - %(lineno)d - %(module)s - %(message)s',
datefmt='%Y/%m/%d %H:%M:%S',
filename='output.log',
filemode='w'
)
if __name__ == '__main__':
logger = logging.getLogger(__name__)
sockfd = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
sockfd.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,True)
sockfd.setblocking(False)
sockfd.bind(("",9090))
sockfd.listen(1)
while True:
print('Waiting for connect...')
try:
connfd,addr = sockfd.accept()
except BlockingIOError as e:
sleep(1)
logger.error(f'报错:{e}')
运行结果:
Waiting for connect...
Waiting for connect...
Waiting for connect...
Waiting for connect...
output.log:
2020/08/21 20:59:58 - __main__ - ERROR - 26 - test - 报错:[WinError 10035] 无法立即完成一个非阻止性套接字操作。
2020/08/21 20:59:59 - __main__ - ERROR - 26 - test - 报错:[WinError 10035] 无法立即完成一个非阻止性套接字操作。
2020/08/21 21:00:00 - __main__ - ERROR - 26 - test - 报错:[WinError 10035] 无法立即完成一个非阻止性套接字操作。
IO多路复用
-
定义
同时监控多个IO事件,当哪个IO事件准备就绪,就执行哪个IO事件。以此形成可以同时处理多个IO的行为,避免一个IO阻塞造成其他IO均无法执行。提高了IO执行效率。
-
具体方案
select方法:Windows、Linux、Unix
poll方法:Linux、Unix
epoll方法:Linux
select方法
import select
rs, ws, xs = select.select(rlist, wlist, xlist[, timeout])
功能:监控IO事件,阻塞等待IO发生
参数:rlist 列表 存放关注的等待发生的IO事件
wlist 列表 存放关注的要主动处理的IO事件
xlist 列表 存放关注的出现异常要处理的IO
timeout int 超时时间
返回值:rs 列表 rlist中准备就绪的IO
ws 列表 wlist中准备就绪的IO
xs 列表 xlist中准备就绪的IO
注意
wlist中如果存在IO事件,则select立即返回给ws
处理IO过程中不要出现死循环占有服务端的情况
IO多路复用消耗资源较少,效率较高
实例:
# 多路复用.py
'''
1. 所有的IO使用select监控
2. 每个IO发生时进行处理,没有发生时即进入监控状态
3. 每个IO不会长期阻塞服务器端执行
'''
from socket import *
from select import select
import logging
logger = logging.basicConfig(
filename='output.log',
filemode='w',
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
level=logging.NOTSET,
datefmt='%Y/%m/%d %H:%M:%S'
)
if __name__ == '__main__':
logger = logging.getLogger(__name__)
# 创建套接字,作为关注的IO
sockfd = socket(AF_INET,SOCK_STREAM)
sockfd.setsockopt(SOL_SOCKET,SO_REUSEADDR,True)
sockfd.bind(("",9090))
sockfd.listen(3)
logger.info('开始监听')
# 将关注IO放入列表
rlist = [sockfd]
wlist = []
xlist = []
# 监控IO发生
while True:
rs, ws, xs = select(rlist, wlist, xlist)
logger.info(f'rlist : {rlist}')
for r in rs:
# 将取出的IO根据不同情况进行处理
if r is sockfd:
c, addr = r.accept()
logger.info(f'Connect from {addr}')
rlist.append(c) # 将c和addr加入监控列表
else:
# 有客户端发消息
data = r.recv(1024).decode('gbk')
if not data:
rlist.remove(r)
logger.info(f'{r}断开连接')
else:
logger.info(f'来自{r}的消息:{data}')
for w in ws:
pass
output.log:
2020/08/21 21:41:39 - __main__ - INFO - 开始监听
2020/08/21 21:41:41 - __main__ - INFO - rlist : [<socket.socket fd=544, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('0.0.0.0', 9090)>]
2020/08/21 21:41:41 - __main__ - INFO - Connect from ('127.0.0.1', 58832)
2020/08/21 21:41:41 - __main__ - INFO - rlist : [<socket.socket fd=544, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('0.0.0.0', 9090)>, <socket.socket fd=568, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 9090), raddr=('127.0.0.1', 58832)>]
2020/08/21 21:41:41 - __main__ - INFO - 来自<socket.socket fd=568, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 9090), raddr=('127.0.0.1', 58832)>的消息:傻子
2020/08/21 21:41:41 - __main__ - INFO - rlist : [<socket.socket fd=544, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('0.0.0.0', 9090)>, <socket.socket fd=568, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 9090), raddr=('127.0.0.1', 58832)>]
2020/08/21 21:41:41 - __main__ - INFO - <socket.socket fd=568, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 9090), raddr=('127.0.0.1', 58832)>断开连接