MySQL数据库
数据库概述
数据存储阶段
- 人工管理阶段
缺点:数据无法共享,不能单独保持,数据存储量有限
- 文件管理阶段(.txt .doc .xls)
优点:数据可以长期保存,可以存储大量的数据,使用简单
缺点:数据一致性差,数据查找修改不方便,数据冗余度可能比较大 - 数据库管理阶段
优点:数据组织结构化降低了冗余度,提高了增删改查的效率,容易扩展,方便程序调用
缺点:需要使用sql或者其他特定的语句,相对比较复杂
数据库应用
融机构、游戏网站、购物网站、论坛网站......
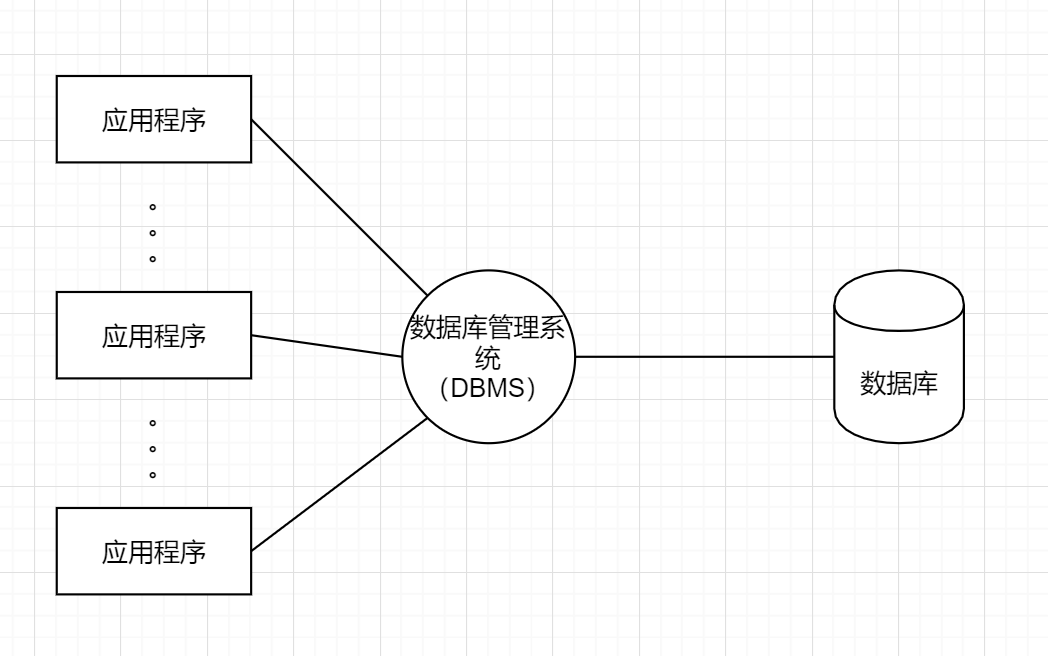
基础概念
数据:能够输入到计算机中并被识别处理的信息集合
数据结构:研究一个数据集合中数据之间的关系
数据库:按照数据结构,存储管理数据的仓库。数据库是在数据库管理系统管理和控制下,在一定介质上的数据集合
数据库管理系统:管理数据库的软件,用于建立和维护数据库
数据库系统:由数据库和数据库管理系统,开发工具等组成的集合
数据库分类和常见数据库
-
关系型数据库和非关系型数据库
关系型:采用关系型模型(二维表)来组织数据结构的数据库
非关系型:不采用关系型模型来组织数据结构的数据库
-
开源数据库和非开源数据库
开源:MySQL、SQLite、MongoDB
非开源:Oracle、DB2、SQL_Server
-
常见关系型数据库
MySQL、Oracle、SQL_Server、DB2、SQLite
-
常见非关系型数据库
Redis
认识关系型数据库和MySQL
-
数据库结构(图库结构)
数据元素 --> 记录 --> 数据表 --> 数据库
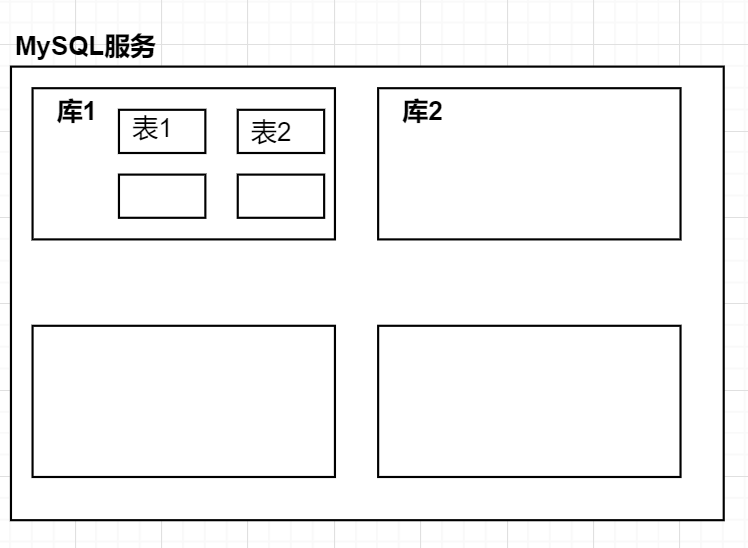
类似Excel
-
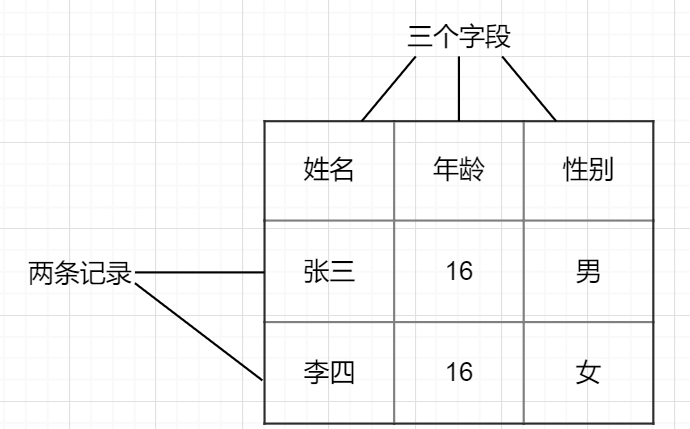
关系型数据库概念解析
数据表(table):存放数据的表格
字段(column):每个列,用来表示该列数据的含义
记录(row):每个行,表示一组完整的数据
-
MySQL特点
- 是开源数据库,使用C和C++编写
- 能够工作在众多不同的平台上
- 提供了用于C、C++、Python、Java、Perl、PHP、Ruby众多语言的API
- 储存结构优良,运行速度快
- 功能全面丰富
- MySQL安装
Ubuntu安装MySQL服务
安装服务端:sudo apt install mysql-server
安装客户端:sudo apt install mysql-client配置文件:/etc/mysql
命令集:/usr/bin
数据库存储目录:/var/lib/mysql
Windows安装MySQL
下载MySQL安装包https://dev.mysql.com/get/Downloads/MySQLInstaller/mysql-installer-community-8.0.21.0.msi
- 启动和连接MySQL服务
服务端启动
查看MySQL状态:sudo /etc/init.d/mysql status
启动 | 关闭 | 重启服务:sudo /etc/init.d/mysql start | stop | restart
客户端连接
命令格式
mysql -h主机地址 -u用户名 -p密码
本地连接可省略-h选项:mysql -uroot -p123456
关闭连接
Ctrl+D exit
- 更改密码
mysqladmin -uroot -p password
SQL语句
什么是SQL
结构化查询语言,一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统
SQL语句使用特点
- SQL语句基本上独立于数据库本身
- 各种不同的数据库对于SQL语言的支持与标准存在细微的不同
- 每条命令必须以;结尾
- SQL命令关键字不区分字母大小
建立数据库和数据表
数据库操作
一定要加;号
-
查看已有库
show databases;
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | +--------------------+ 4 rows in set (0.05 sec) -
创建库(指定字符集)
create database 库名 [character set utf8];
注意这里是database,没有s
e.g. 创建stu数据库,编码为utf-8, 在MySQL8.0以后,默认编码为UTF-8, 这之前的默认编码不支持中文 mysql> create database stu charset=utf8; Query OK, 1 row affected, 1 warning (0.01 sec) mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | stu | | sys | +--------------------+ 5 rows in set (0.01 sec) mysql> create database `zjy` character set utf8; Query OK, 1 row affected, 1 warning (0.01 sec) mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | stu | | sys | | zjy | +--------------------+ 6 rows in set (0.01 sec)一般创建的库名用``包裹起来,防止和关键字等冲突
-
查看创建库的语句(字符集)
show create database 库名;
e.g. 查看stu创建方法 mysql> show create database stu; +----------+-------------------------------------------------------------------------------------------------+ | Database | Create Database | +----------+-------------------------------------------------------------------------------------------------+ | stu | CREATE DATABASE `stu` /*!40100 DEFAULT CHARACTER SET utf8 */ /*!80016 DEFAULT ENCRYPTION='N' */ | +----------+-------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) -
查看当前所在库
select database();
mysql> select database(); +------------+ | database() | +------------+ | NULL | +------------+ 1 row in set (0.01 sec) -
切换库
use 库名;
mysql> use zjy; Database changed -
删除库
drop database 库名;
提示:删库要谨慎!!!mysql> drop database stu; Query OK, 0 rows affected (0.01 sec) mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | | zjy | +--------------------+ 5 rows in set (0.00 sec) -
库名的命名规则
- 数字、字母、下划线,但不能用纯数字
- 库名区分大小写
- 不能使用特殊字符和MySQL关键字
数据表的管理
表结构设计初步
【1】 分析存储内容
【2】 确定字段构成
【3】 设计字段类型
数据类型支持
数字类型:
整数类型(精确值)- integer、int、smallint、tinyint、mediumint、bigint
定点类型(精确值)- decimal
浮点类型(近似值)- float、double
比特值类型 - bit

对于精度比较高的东西,比如money,用decimal类型提高精度减少误差。列的声明语法是decimal(M,D)
M是数字的最大位数(精度),其范围是1~65,M的默认值是10
D是小数点右侧数字的数目(标度),其范围是0~30,但不得超过M
比如decimal(6,2)最多存6位数字,小数点后占2位。取值范围-9999.99到9999.99
比特类型指0、1表达2种情况,如真、假
字符串类型:
char和varchar类型
blob和text类型
enum和set类型

- char和varchar
char:定长,效率高,一般用于固定长度的表单提交数据存储,默认1字符
varchar:不定长:效率偏低,但是节省空间 - text和blob
text用来存储非二进制文本
blob用来存储二进制字节串 - enum和set
enum用来存储给出的一个值
set用来存储给出的值中一个或多个值
-
表的基本操作
查看表
show tables;
查看表结构
desc 表名;
mysql> show tables; Empty set (0.00 sec)创建表(指定字符集)
create table 表名 (
字段名 数据类型,
字段名 数据类型,
字段名 数据类型,
...
字段名 数据类型
);- 如果你想设置数字为无符号则加上unsigned
- 如果你不想字段为null 可以设置字段属性为not null,在操作数据库时如果输入该字段的数据为null,就会报错
- default表示设置一个字段的默认值
- auto_increment定义列为自增的属性,一般用于主键,数值会自动加1
primary key关键字用于定义列为主键。主键的值不能重复,且不能为空
查看已有表的字符集
show create table 表名;
删除表
drop table 表名;
mysql> create table 班级 (id int unsigned auto_increment primary key,姓名 varchar(32) not null,年龄 tinyint,性别 enum('男','女'),成绩 int); Query OK, 0 rows affected (0.04 sec) mysql> show tables; +---------------+ | Tables_in_zjy | +---------------+ | 班级 | +---------------+ 1 row in set (0.00 sec) mysql> desc 班级; +--------+-------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------------+------+-----+---------+----------------+ | id | int unsigned | NO | PRI | NULL | auto_increment | | 姓名 | varchar(32) | NO | | NULL | | | 年龄 | tinyint | YES | | NULL | | | 性别 | enum('男','女') | YES | | NULL | | | 成绩 | int | YES | | NULL | | +--------+-------------------+------+-----+---------+----------------+ 5 rows in set (0.00 sec) mysql> desc 班级; +--------+-------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------------+------+-----+---------+----------------+ | id | int unsigned | NO | PRI | NULL | auto_increment | | 姓名 | varchar(32) | NO | | NULL | | | 年龄 | tinyint | YES | | NULL | | | 性别 | enum('男','女') | YES | | NULL | | | 成绩 | int | YES | | NULL | | +--------+-------------------+------+-----+---------+----------------+ 5 rows in set (0.00 sec) mysql> show create table 班级; +--------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Table | Create Table | +--------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | 班级 | CREATE TABLE `班级` ( `id` int unsigned NOT NULL AUTO_INCREMENT, `姓名` varchar(32) NOT NULL, `年龄` tinyint DEFAULT NULL, `性别` enum('男','女') DEFAULT NULL, `成绩` int DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 | +--------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec)
数据操作基础
插入(insert)
insert into 表名 values(值1),(值2),...;
insert into 表名(字段1,...) values(值1),...;
e.g.
mysql> insert into 班级 values(1,'Baron',16,'男',100),(2,'Amy',13,'女',90);
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> insert into 班级(id,姓名,年龄,性别) values(3,'Allen',14,'男');
Query OK, 1 row affected (0.01 sec)
mysql> select * from 班级;
+----+--------+--------+--------+--------+
| id | 姓名 | 年龄 | 性别 | 成绩 |
+----+--------+--------+--------+--------+
| 1 | Baron | 16 | 男 | 100 |
| 2 | Amy | 13 | 女 | 90 |
| 3 | Allen | 14 | 男 | NULL |
+----+--------+--------+--------+--------+
3 rows in set (0.00 sec)
查询(select)
select * from 表名 [where 条件];
select 字段1,字段2 from 表名 [where 条件];
mysql> select * from 班级;
+----+--------+--------+--------+--------+
| id | 姓名 | 年龄 | 性别 | 成绩 |
+----+--------+--------+--------+--------+
| 1 | Baron | 16 | 男 | 100 |
| 2 | Amy | 13 | 女 | 90 |
| 3 | Allen | 14 | 男 | NULL |
+----+--------+--------+--------+--------+
3 rows in set (0.00 sec)
mysql> select id from 班级;
+----+
| id |
+----+
| 1 |
| 2 |
| 3 |
+----+
3 rows in set (0.00 sec)
mysql> select 姓名,年龄,性别 from 班级;
+--------+--------+--------+
| 姓名 | 年龄 | 性别 |
+--------+--------+--------+
| Baron | 16 | 男 |
| Amy | 13 | 女 |
| Allen | 14 | 男 |
+--------+--------+--------+
3 rows in set (0.01 sec)
mysql> select 姓名 from 班级 where 成绩 > 90;
+--------+
| 姓名 |
+--------+
| Baron |
+--------+
1 row in set (0.00 sec)
where子句
MySQL主要有一下几种运算符
算术运算符
比较运算符
逻辑运算符
位运算符
算术运算符
| 符号 | 作用 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
| % | 取余 |
比较运算符
| 符号 | 作用 | 备注 |
|---|---|---|
| = | 等于 | |
| != | 不等于 | |
| > | 大于 | |
| < | 小于 | |
| <= | 小于等于 | |
| >= | 大于等于 | |
| between | 在两值之间 | >=min&&<=max |
| not between | 不在两值之间 | |
| in | 在集合中 | |
| not in | 不在集合中 | |
| <=> | 严格比较两个NULL是否相等 | 两个操作码皆为NULL时,其所得的值 |
| like | 模糊匹配 | |
| regexp 或 rlike | 正则匹配 | |
| is null | 为空 | |
| is not null | 不为空 |
逻辑运算符
| 符号 | 作用 | 备注 |
|---|---|---|
| not 或 ! | 逻辑非 | |
| and | 逻辑与 | |
| or | 逻辑或 | |
| xor | 逻辑异或 | 一真一假则为真 |
位运算符
| 符号 | 作用 |
|---|---|
| & | 按位与 |
| | | 按位或 |
| ^ | 按位或异 |
| ! | 取反 |
| << | 左移 |
| >> | 右移 |
mysql> select * from 班级;
+----+--------+--------+--------+--------+
| id | 姓名 | 年龄 | 性别 | 成绩 |
+----+--------+--------+--------+--------+
| 1 | Baron | 16 | 男 | 100 |
| 2 | Amy | 13 | 女 | 90 |
| 3 | Allen | 14 | 男 | NULL |
| 4 | Ben | 18 | 男 | 99 |
| 5 | Emma | 14 | 女 | 10 |
| 6 | Jack | 18 | 男 | 80 |
| 7 | Ava | 16 | 女 | 75 |
+----+--------+--------+--------+--------+
7 rows in set (0.00 sec)
mysql> select * from 班级 where 年龄 <= 14;
+----+--------+--------+--------+--------+
| id | 姓名 | 年龄 | 性别 | 成绩 |
+----+--------+--------+--------+--------+
| 2 | Amy | 13 | 女 | 90 |
| 3 | Allen | 14 | 男 | NULL |
| 5 | Emma | 14 | 女 | 10 |
+----+--------+--------+--------+--------+
3 rows in set (0.00 sec)
mysql> select * from 班级 where 成绩 between 80 and 100;
+----+--------+--------+--------+--------+
| id | 姓名 | 年龄 | 性别 | 成绩 |
+----+--------+--------+--------+--------+
| 1 | Baron | 16 | 男 | 100 |
| 2 | Amy | 13 | 女 | 90 |
| 4 | Ben | 18 | 男 | 99 |
| 6 | Jack | 18 | 男 | 80 |
+----+--------+--------+--------+--------+
4 rows in set (0.00 sec)
mysql> select * from 班级 where 成绩 in (100,90,80);
+----+--------+--------+--------+--------+
| id | 姓名 | 年龄 | 性别 | 成绩 |
+----+--------+--------+--------+--------+
| 1 | Baron | 16 | 男 | 100 |
| 2 | Amy | 13 | 女 | 90 |
| 6 | Jack | 18 | 男 | 80 |
+----+--------+--------+--------+--------+
3 rows in set (0.00 sec)
mysql> select * from 班级 where 成绩 is null;
+----+--------+--------+--------+--------+
| id | 姓名 | 年龄 | 性别 | 成绩 |
+----+--------+--------+--------+--------+
| 3 | Allen | 14 | 男 | NULL |
+----+--------+--------+--------+--------+
1 row in set (0.00 sec)
mysql> select * from 班级 where 成绩 is not null;
+----+--------+--------+--------+--------+
| id | 姓名 | 年龄 | 性别 | 成绩 |
+----+--------+--------+--------+--------+
| 1 | Baron | 16 | 男 | 100 |
| 2 | Amy | 13 | 女 | 90 |
| 4 | Ben | 18 | 男 | 99 |
| 5 | Emma | 14 | 女 | 10 |
| 6 | Jack | 18 | 男 | 80 |
| 7 | Ava | 16 | 女 | 75 |
+----+--------+--------+--------+--------+
6 rows in set (0.00 sec)
mysql> select * from 班级 where 成绩 > 80 xor 性别 = '女';
+----+--------+--------+--------+--------+
| id | 姓名 | 年龄 | 性别 | 成绩 |
+----+--------+--------+--------+--------+
| 1 | Baron | 16 | 男 | 100 |
| 4 | Ben | 18 | 男 | 99 |
| 5 | Emma | 14 | 女 | 10 |
| 7 | Ava | 16 | 女 | 75 |
+----+--------+--------+--------+--------+
4 rows in set (0.01 sec)
更新表记录
update 表名 set 字段1=值1,字段2=值2,... where 条件;
mysql> update 班级 set 成绩=100 where 姓名='Ava';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from 班级;
+----+--------+--------+--------+--------+
| id | 姓名 | 年龄 | 性别 | 成绩 |
+----+--------+--------+--------+--------+
| 1 | Baron | 16 | 男 | 100 |
| 2 | Amy | 13 | 女 | 90 |
| 3 | Allen | 14 | 男 | NULL |
| 4 | Ben | 18 | 男 | 99 |
| 5 | Emma | 14 | 女 | 10 |
| 6 | Jack | 18 | 男 | 80 |
| 7 | Ava | 16 | 女 | 100 |
+----+--------+--------+--------+--------+
7 rows in set (0.00 sec)
删除表记录
delete from 表名 where 条件;
注意!delete语句后面如果不加where条件,所有记录全部清空!!!
mysql> delete from 班级 where 姓名 = 'Allen';
Query OK, 1 row affected (0.04 sec)
mysql> select * from 班级;
+----+--------+--------+--------+--------+
| id | 姓名 | 年龄 | 性别 | 成绩 |
+----+--------+--------+--------+--------+
| 1 | Baron | 16 | 男 | 100 |
| 2 | Amy | 13 | 女 | 90 |
| 4 | Ben | 18 | 男 | 99 |
| 5 | Emma | 14 | 女 | 10 |
| 6 | Jack | 18 | 男 | 80 |
| 7 | Ava | 16 | 女 | 100 |
+----+--------+--------+--------+--------+
6 rows in set (0.00 sec)
删除要谨慎再谨慎!!!
表字段的操作(alter)
语法:alter table 表名 执行动作;
* 添加字段(add)
alter table 表名 add 字段名 数据类型;
alter table 表名 add 字段名 数据类型 first;
alter table 表名 add 字段名 数据类型 after 字段名;
* 删除字段(drop)
alter table 表名 drop 字段名;
* 修改数据类型(modify)
alter table 表名 modify 字段名 新数据类型;
* 修改字段名(change)
alter table 表名 change 旧字段名 新字段名 新数据类型;
* 表重命名(rename)
alter table 表名 rename 新表名;
mysql> alter table 班级 add 爱好 varchar(32);
Query OK, 0 rows affected (0.04 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> desc 班级;
+--------+-------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+-------------------+------+-----+---------+----------------+
| id | int unsigned | NO | PRI | NULL | auto_increment |
| 姓名 | varchar(32) | NO | | NULL | |
| 年龄 | tinyint | YES | | NULL | |
| 性别 | enum('男','女') | YES | | NULL | |
| 成绩 | int | YES | | NULL | |
| 爱好 | varchar(32) | YES | | NULL | |
+--------+-------------------+------+-----+---------+----------------+
6 rows in set (0.00 sec)
mysql> select * from 班级;
+----+--------+--------+--------+--------+--------+
| id | 姓名 | 年龄 | 性别 | 成绩 | 爱好 |
+----+--------+--------+--------+--------+--------+
| 1 | Baron | 16 | 男 | 100 | NULL |
| 2 | Amy | 13 | 女 | 90 | NULL |
| 4 | Ben | 18 | 男 | 99 | NULL |
| 5 | Emma | 14 | 女 | 10 | NULL |
| 6 | Jack | 18 | 男 | 80 | NULL |
| 7 | Ava | 16 | 女 | 100 | NULL |
+----+--------+--------+--------+--------+--------+
6 rows in set (0.00 sec)
mysql> alter table 班级 add 性格 varchar(32) not null;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from 班级;
+----+--------+--------+--------+--------+--------+--------+
| id | 姓名 | 年龄 | 性别 | 成绩 | 爱好 | 性格 |
+----+--------+--------+--------+--------+--------+--------+
| 1 | Baron | 16 | 男 | 100 | NULL | |
| 2 | Amy | 13 | 女 | 90 | NULL | |
| 4 | Ben | 18 | 男 | 99 | NULL | |
| 5 | Emma | 14 | 女 | 10 | NULL | |
| 6 | Jack | 18 | 男 | 80 | NULL | |
| 7 | Ava | 16 | 女 | 100 | NULL | |
+----+--------+--------+--------+--------+--------+--------+
6 rows in set (0.00 sec)
mysql> alter table 班级 drop 性格;
Query OK, 0 rows affected (0.07 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from 班级;
+----+--------+--------+--------+--------+--------+
| id | 姓名 | 年龄 | 性别 | 成绩 | 爱好 |
+----+--------+--------+--------+--------+--------+
| 1 | Baron | 16 | 男 | 100 | NULL |
| 2 | Amy | 13 | 女 | 90 | NULL |
| 4 | Ben | 18 | 男 | 99 | NULL |
| 5 | Emma | 14 | 女 | 10 | NULL |
| 6 | Jack | 18 | 男 | 80 | NULL |
| 7 | Ava | 16 | 女 | 100 | NULL |
+----+--------+--------+--------+--------+--------+
6 rows in set (0.00 sec)
mysql> alter table 班级 change id 座位号 int unsigned NOT NULL AUTO_INCREMENT;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from 班级;
+-----------+--------+--------+--------+--------+--------+
| 座位号 | 姓名 | 年龄 | 性别 | 成绩 | 爱好 |
+-----------+--------+--------+--------+--------+--------+
| 1 | Baron | 16 | 男 | 100 | NULL |
| 2 | Amy | 13 | 女 | 90 | NULL |
| 4 | Ben | 18 | 男 | 99 | NULL |
| 5 | Emma | 14 | 女 | 10 | NULL |
| 6 | Jack | 18 | 男 | 80 | NULL |
| 7 | Ava | 16 | 女 | 100 | NULL |
+-----------+--------+--------+--------+--------+--------+
6 rows in set (0.00 sec)
mysql> alter table 班级 add 性格 varchar(32) not null after 性别;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from 班级;
+-----------+--------+--------+--------+--------+--------+--------+
| 座位号 | 姓名 | 年龄 | 性别 | 性格 | 成绩 | 爱好 |
+-----------+--------+--------+--------+--------+--------+--------+
| 1 | Baron | 16 | 男 | | 100 | NULL |
| 2 | Amy | 13 | 女 | | 90 | NULL |
| 4 | Ben | 18 | 男 | | 99 | NULL |
| 5 | Emma | 14 | 女 | | 10 | NULL |
| 6 | Jack | 18 | 男 | | 80 | NULL |
| 7 | Ava | 16 | 女 | | 100 | NULL |
+-----------+--------+--------+--------+--------+--------+--------+
6 rows in set (0.00 sec)
mysql> alter table 班级 rename 4班;
Query OK, 0 rows affected (0.01 sec)
mysql> show tables;
+---------------+
| Tables_in_zjy |
+---------------+
| 4班 |
+---------------+
1 row in set (0.00 sec)
mysql> select * from 4班;
+-----------+--------+--------+--------+--------+--------+--------+
| 座位号 | 姓名 | 年龄 | 性别 | 性格 | 成绩 | 爱好 |
+-----------+--------+--------+--------+--------+--------+--------+
| 1 | Baron | 16 | 男 | | 100 | NULL |
| 2 | Amy | 13 | 女 | | 90 | NULL |
| 4 | Ben | 18 | 男 | | 99 | NULL |
| 5 | Emma | 14 | 女 | | 10 | NULL |
| 6 | Jack | 18 | 男 | | 80 | NULL |
| 7 | Ava | 16 | 女 | | 100 | NULL |
+-----------+--------+--------+--------+--------+--------+--------+
6 rows in set (0.00 sec)
mysql> alter table 4班 modify 性格 varchar(64) not null;
Query OK, 0 rows affected (0.04 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> desc 4班;
+-----------+-------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------+-------------------+------+-----+---------+----------------+
| 座位号 | int unsigned | NO | PRI | NULL | auto_increment |
| 姓名 | varchar(32) | NO | | NULL | |
| 年龄 | tinyint | YES | | NULL | |
| 性别 | enum('男','女') | YES | | NULL | |
| 性格 | varchar(64) | NO | | NULL | |
| 成绩 | int | YES | | NULL | |
| 爱好 | varchar(32) | YES | | NULL | |
+-----------+-------------------+------+-----+---------+----------------+
7 rows in set (0.00 sec)
时间类型数据
时间和日期类型
date,datetime和timestamp类型
time类型
年份类型year

时间格式
data:YYYY-MM-DD
time:HH:MM:SS
datetime:YYYY-MM-DD HH:MM:SS
timestamp:YYYY-MM-DD HH:MM:SS
注意
- datetime:以系统时间储存
- timestamp:以标准时间存储但是查看时转换为系统时区,所以表现形式和datetime相同
create table 马拉松 (id int primary key auto_increment,选手 varchar(32),
出生日期 date,报名时间 datetime,成绩 time);
mysql> insert into 马拉松 values(1,'尼古拉斯赵四','1990/5/8','2019-6-8 08:28:6','2:38:36');
Query OK, 1 row affected (0.01 sec)
mysql> select * from 马拉松;
+----+--------------------+--------------+---------------------+----------+
| id | 选手 | 出生日期 | 报名时间 | 成绩 |
+----+--------------------+--------------+---------------------+----------+
| 1 | 尼古拉斯赵四 | 1990-05-08 | 2019-06-08 08:28:06 | 02:38:36 |
+----+--------------------+--------------+---------------------+----------+
1 row in set (0.00 sec)
日期时间函数
- now() 返回服务器当前日期时间,格式对应datetime类型
- curdate() 返回当前日期,格式对应date类型
- curtime() 返回当前时间,格式对应time类型
mysql> select curdate();
+------------+
| curdate() |
+------------+
| 2020-08-26 |
+------------+
1 row in set (0.00 sec)
mysql> select curtime();
+-----------+
| curtime() |
+-----------+
| 19:45:34 |
+-----------+
1 row in set (0.00 sec)
mysql> select now();
+---------------------+
| now() |
+---------------------+
| 2020-08-26 19:48:14 |
+---------------------+
1 row in set (0.00 sec)
时间操作
-
查找操作
mysql> select * from 马拉松; +----+--------------------+--------------+---------------------+----------+ | id | 选手 | 出生日期 | 报名时间 | 成绩 | +----+--------------------+--------------+---------------------+----------+ | 1 | 尼古拉斯赵四 | 1990-05-08 | 2019-06-08 08:28:06 | 02:38:36 | | 2 | 凯奇 | 1988-07-18 | 2019-07-01 16:18:01 | 02:25:40 | | 3 | 约翰 | 1989-08-18 | 2019-07-01 16:18:01 | 02:27:40 | | 4 | 老王 | 1899-12-18 | 2019-06-01 16:18:01 | 02:13:40 | | 5 | 曹操 | 1999-12-28 | 2019-07-01 08:18:01 | 02:01:40 | +----+--------------------+--------------+---------------------+----------+ 5 rows in set (0.00 sec) mysql> select * from 马拉松 where 出生日期 > '1990-01-01'; +----+--------------------+--------------+---------------------+----------+ | id | 选手 | 出生日期 | 报名时间 | 成绩 | +----+--------------------+--------------+---------------------+----------+ | 1 | 尼古拉斯赵四 | 1990-05-08 | 2019-06-08 08:28:06 | 02:38:36 | | 5 | 曹操 | 1999-12-28 | 2019-07-01 08:18:01 | 02:01:40 | +----+--------------------+--------------+---------------------+----------+ 2 rows in set (0.00 sec) mysql> select * from 马拉松 where 成绩 < '2:30:00'; +----+--------+--------------+---------------------+----------+ | id | 选手 | 出生日期 | 报名时间 | 成绩 | +----+--------+--------------+---------------------+----------+ | 2 | 凯奇 | 1988-07-18 | 2019-07-01 16:18:01 | 02:25:40 | | 3 | 约翰 | 1989-08-18 | 2019-07-01 16:18:01 | 02:27:40 | | 4 | 老王 | 1899-12-18 | 2019-06-01 16:18:01 | 02:13:40 | | 5 | 曹操 | 1999-12-28 | 2019-07-01 08:18:01 | 02:01:40 | +----+--------+--------------+---------------------+----------+ 4 rows in set (0.00 sec) -
日期时间运算
- 语法格式
select * from 表名 where 字段名 运算符 (时间 - interval 时间间隔单位); - 时间间隔单位
2 hour | 1 minute | 2 second | 2 year | 3 month | 1 day
mysql> select * from 马拉松 where 报名时间 > (now() - interval 14 month); +----+--------+--------------+---------------------+----------+ | id | 选手 | 出生日期 | 报名时间 | 成绩 | +----+--------+--------------+---------------------+----------+ | 2 | 凯奇 | 1988-07-18 | 2019-07-01 16:18:01 | 02:25:40 | | 3 | 约翰 | 1989-08-18 | 2019-07-01 16:18:01 | 02:27:40 | | 5 | 曹操 | 1999-12-28 | 2019-07-01 08:18:01 | 02:01:40 | +----+--------+--------------+---------------------+----------+ 3 rows in set (0.00 sec) - 语法格式
导入导出
- 导出
mysqldump -uroot -p 数据库名 > 数据库名.sql
- 导入
mysql -uroot
use 数据库名;
source 数据库名.sql;
mysql> create database zjy;
Query OK, 1 row affected (0.00 sec)
mysql> use zjy
Database changed
mysql> source /home/zjy/数据库/zjy.sql;
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.01 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected, 1 warning (0.01 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
mysql> select * from 班级;
+----+--------+--------+--------+--------+
| id | 姓名 | 年龄 | 性别 | 成绩 |
+----+--------+--------+--------+--------+
| 1 | Baron | 16 | 男 | 100 |
| 2 | Amy | 13 | 女 | 90 |
| 3 | Allen | 14 | 男 | NULL |
+----+--------+--------+--------+--------+
3 rows in set (0.00 sec)
高级查询语句
模糊查询和正则查询
like用于在where子句中进行模糊查询,SQL like子句中使用%来表示任意0个或多个字符,下划线_表示任意一个字符
mysql> select * from 4班;
+--------+-------+------+------+------+------+------+
| 座位号 | 姓名 | 年龄 | 性别 | 性格 | 成绩 | 爱好 |
+--------+-------+------+------+------+------+------+
| 1 | Baron | 16 | 男 | | 100 | NULL |
| 2 | Amy | 13 | 女 | | 90 | NULL |
| 4 | Ben | 18 | 男 | | 99 | NULL |
| 5 | Emma | 14 | 女 | | 10 | NULL |
| 6 | Jack | 18 | 男 | | 80 | NULL |
| 7 | Ava | 16 | 女 | | 100 | NULL |
+--------+-------+------+------+------+------+------+
6 rows in set (0.04 sec)
mysql> select * from 4班 where 姓名 like 'B%';
+--------+-------+------+------+------+------+------+
| 座位号 | 姓名 | 年龄 | 性别 | 性格 | 成绩 | 爱好 |
+--------+-------+------+------+------+------+------+
| 1 | Baron | 16 | 男 | | 100 | NULL |
| 4 | Ben | 18 | 男 | | 99 | NULL |
+--------+-------+------+------+------+------+------+
2 rows in set (0.00 sec)
mysql> select * from 4班 where 姓名 like '___';
+--------+------+------+------+------+------+------+
| 座位号 | 姓名 | 年龄 | 性别 | 性格 | 成绩 | 爱好 |
+--------+------+------+------+------+------+------+
| 2 | Amy | 13 | 女 | | 90 | NULL |
| 4 | Ben | 18 | 男 | | 99 | NULL |
| 7 | Ava | 16 | 女 | | 100 | NULL |
+--------+------+------+------+------+------+------+
3 rows in set (0.00 sec)
mysql> select * from 4班 where 姓名 like 'B__';
+--------+------+------+------+------+------+------+
| 座位号 | 姓名 | 年龄 | 性别 | 性格 | 成绩 | 爱好 |
+--------+------+------+------+------+------+------+
| 4 | Ben | 18 | 男 | | 99 | NULL |
+--------+------+------+------+------+------+------+
1 row in set (0.00 sec)
MySQL对正则表达式的支持有限,只支持部分元字符
mysql> select * from 4班 where 姓名 regexp 'A.+';
+--------+-------+------+------+------+------+------+
| 座位号 | 姓名 | 年龄 | 性别 | 性格 | 成绩 | 爱好 |
+--------+-------+------+------+------+------+------+
| 1 | Baron | 16 | 男 | | 100 | NULL |
| 2 | Amy | 13 | 女 | | 90 | NULL |
| 6 | Jack | 18 | 男 | | 80 | NULL |
| 7 | Ava | 16 | 女 | | 100 | NULL |
+--------+-------+------+------+------+------+------+
4 rows in set (0.00 sec)
mysql> select * from 4班 where 姓名 regexp '^A.+';
+--------+------+------+------+------+------+------+
| 座位号 | 姓名 | 年龄 | 性别 | 性格 | 成绩 | 爱好 |
+--------+------+------+------+------+------+------+
| 2 | Amy | 13 | 女 | | 90 | NULL |
| 7 | Ava | 16 | 女 | | 100 | NULL |
+--------+------+------+------+------+------+------+
2 rows in set (0.00 sec)
MySQL中的正则表达式不区分大小写
as用法
在SQL语句中用于给字段或表重命名
mysql> select 姓名 as name,年龄 as age from 4班;
+-------+------+
| name | age |
+-------+------+
| Baron | 16 |
| Amy | 13 |
| Ben | 18 |
| Emma | 14 |
| Jack | 18 |
| Ava | 16 |
+-------+------+
6 rows in set (0.00 sec)
mysql> select * from 4班 as c where c.姓名 = 'Amy';
+--------+------+------+------+------+------+------+
| 座位号 | 姓名 | 年龄 | 性别 | 性格 | 成绩 | 爱好 |
+--------+------+------+------+------+------+------+
| 2 | Amy | 13 | 女 | | 90 | NULL |
+--------+------+------+------+------+------+------+
1 row in set (0.00 sec)
排序
order by子句用来设定你想按哪个字段哪种方式来排序,再返回搜索结果
默认情况下asc表示升序,desc表示降序
mysql> select * from 4班 where 性别='男' order by 成绩;
+--------+-------+------+------+------+------+------+
| 座位号 | 姓名 | 年龄 | 性别 | 性格 | 成绩 | 爱好 |
+--------+-------+------+------+------+------+------+
| 6 | Jack | 18 | 男 | | 80 | NULL |
| 4 | Ben | 18 | 男 | | 99 | NULL |
| 1 | Baron | 16 | 男 | | 100 | NULL |
+--------+-------+------+------+------+------+------+
3 rows in set (0.00 sec)
mysql> select * from 4班 where 性别='男' order by 成绩 desc;
+--------+-------+------+------+------+------+------+
| 座位号 | 姓名 | 年龄 | 性别 | 性格 | 成绩 | 爱好 |
+--------+-------+------+------+------+------+------+
| 1 | Baron | 16 | 男 | | 100 | NULL |
| 4 | Ben | 18 | 男 | | 99 | NULL |
| 6 | Jack | 18 | 男 | | 80 | NULL |
+--------+-------+------+------+------+------+------+
3 rows in set (0.00 sec)
mysql> select * from 马拉松 order by 成绩;
+----+--------------+------------+---------------------+----------+
| id | 选手 | 出生日期 | 报名时间 | 成绩 |
+----+--------------+------------+---------------------+----------+
| 5 | 曹操 | 1999-12-28 | 2019-07-01 08:18:01 | 02:01:40 |
| 4 | 老王 | 1899-12-18 | 2019-06-01 16:18:01 | 02:13:40 |
| 2 | 凯奇 | 1988-07-18 | 2019-07-01 16:18:01 | 02:25:40 |
| 3 | 约翰 | 1989-08-18 | 2019-07-01 16:18:01 | 02:27:40 |
| 1 | 尼古拉斯赵四 | 1990-05-08 | 2019-06-08 08:28:06 | 02:38:36 |
+----+--------------+------------+---------------------+----------+
5 rows in set (0.00 sec)
mysql> select * from 4班 order by 年龄,成绩;
// 此时先按照年龄排序,相同的再按照成绩排序
+--------+-------+------+------+------+------+------+
| 座位号 | 姓名 | 年龄 | 性别 | 性格 | 成绩 | 爱好 |
+--------+-------+------+------+------+------+------+
| 2 | Amy | 13 | 女 | | 90 | NULL |
| 5 | Emma | 14 | 女 | | 10 | NULL |
| 1 | Baron | 16 | 男 | | 100 | NULL |
| 7 | Ava | 16 | 女 | | 100 | NULL |
| 6 | Jack | 18 | 男 | | 80 | NULL |
| 4 | Ben | 18 | 男 | | 99 | NULL |
+--------+-------+------+------+------+------+------+
6 rows in set (0.00 sec)
注意!默认是按照升序排序
分页(限制)
limit子句用于限制select语句返回的数据数量或者update,delete语句的操作数量
mysql> select * from 4班 limit 4;
+--------+-------+------+------+------+------+
| 座位号 | 姓名 | 年龄 | 性别 | 成绩 | 爱好 |
+--------+-------+------+------+------+------+
| 1 | Baron | 16 | 男 | 100 | NULL |
| 2 | Amy | 13 | 女 | 90 | NULL |
| 4 | Ben | 18 | 男 | 99 | NULL |
| 5 | Emma | 14 | 女 | 10 | NULL |
+--------+-------+------+------+------+------+
4 rows in set (0.00 sec)
mysql> select * from 4班 where 性别='男' limit 2;
+--------+-------+------+------+------+------+
| 座位号 | 姓名 | 年龄 | 性别 | 成绩 | 爱好 |
+--------+-------+------+------+------+------+
| 1 | Baron | 16 | 男 | 100 | NULL |
| 4 | Ben | 18 | 男 | 99 | NULL |
+--------+-------+------+------+------+------+
2 rows in set (0.00 sec)
联合查询
union操作符用于连接两个以上的select语句的结果组合到一个结果集合中。多个select语句会删除重复的数据
union all 表示返回所有结果集,包含重复数据
union distinct 默认,表示删除结果集中重复的数据
mysql> select * from 4班 where 性别='女' union all select * from 4班 where 成绩 > 90;
+--------+-------+------+------+------+----------+
| 座位号 | 姓名 | 年龄 | 性别 | 成绩 | 爱好 |
+--------+-------+------+------+------+----------+
| 2 | Amy | 13 | 女 | 90 | 打乒乓球 |
| 5 | Emma | 14 | 女 | 10 | 玩游戏 |
| 7 | Ava | 16 | 女 | 100 | 编程 |
| 1 | Baron | 16 | 男 | 100 | 打篮球 |
| 4 | Ben | 18 | 男 | 99 | 看书 |
| 7 | Ava | 16 | 女 | 100 | 编程 |
+--------+-------+------+------+------+----------+
6 rows in set (0.00 sec)
mysql> select * from 4班 where 性别='女' union select * from 4班 where 成绩 > 90;
+--------+-------+------+------+------+----------+
| 座位号 | 姓名 | 年龄 | 性别 | 成绩 | 爱好 |
+--------+-------+------+------+------+----------+
| 2 | Amy | 13 | 女 | 90 | 打乒乓球 |
| 5 | Emma | 14 | 女 | 10 | 玩游戏 |
| 7 | Ava | 16 | 女 | 100 | 编程 |
| 1 | Baron | 16 | 男 | 100 | 打篮球 |
| 4 | Ben | 18 | 男 | 99 | 看书 |
+--------+-------+------+------+------+----------+
5 rows in set (0.00 sec)
子查询
定义:当一个select语句中包含另一个select查询语句,则称之为有子查询的语句
子查询出现的位置:from之后,此时子查询的内容作为一个新的表内容,再进行外层select查询
-
需要将子查询结果集重命名一下,方便where子句中的引用操作
where子句中,此时select查询到的内容作为外层查询的条件值
-
子句的返回结果需要一个明确值,即需要某个记录的某个元素,不能是多行或多列
mysql> select * from (select * from 4班 where 性别='男') as s where s.成绩 > 90;
+--------+-------+------+------+------+--------+
| 座位号 | 姓名 | 年龄 | 性别 | 成绩 | 爱好 |
+--------+-------+------+------+------+--------+
| 1 | Baron | 16 | 男 | 100 | 打篮球 |
| 4 | Ben | 18 | 男 | 99 | 看书 |
+--------+-------+------+------+------+--------+
2 rows in set (0.00 sec)
mysql> select * from 4班 where 姓名=(select 姓名 from 4班 where 性别='男' and 成绩=100);
+--------+-------+------+------+------+------+
| 座位号 | 姓名 | 年龄 | 性别 | 成绩 | 爱好 |
+--------+-------+------+------+------+------+
| 1 | Baron | 16 | 男 | 100 | 编程 |
+--------+-------+------+------+------+------+
1 row in set (0.00 sec)
mysql> select * from 4班 where 年龄=(select 年龄 from 4班 where 姓名='Baron') and 姓名!='Baron';
+--------+------+------+------+------+------+
| 座位号 | 姓名 | 年龄 | 性别 | 成绩 | 爱好 |
+--------+------+------+------+------+------+
| 7 | Ava | 16 | 女 | 100 | 编程 |
+--------+------+------+------+------+------+
1 row in set (0.00 sec)
聚合操作
聚合操作指的是在数据查找基础上对数据的进一步整理筛选行为
- select语句执行顺序
(7) select (8) [distinct] <select_list> (1) from <left_table> (3) <join_type> join <right_table> (2) on <join_condition> (4) where <where_condition> (5) group by <group_by_list> (6) having <having_condition> (9) order by <order_by_condition> (10) limit <limit_number>
聚合函数
| 方法 | 功能 |
|---|---|
| avg(字段名) | 该字段的平均值 |
| max(字段名) | 该字段的最大值 |
| min(字段名) | 该字段的最小值 |
| sum(字段名) | 该字段所有记录的和 |
| count(字段名) | 统计该字段记录个数 |
mysql> select max(年龄) from 4班;
+-----------+
| max(年龄) |
+-----------+
| 18 |
+-----------+
1 row in set (0.04 sec)
mysql> select * from 4班 where 年龄=(select max(年龄) from 4班);
+--------+------+------+------+------+--------+
| 座位号 | 姓名 | 年龄 | 性别 | 成绩 | 爱好 |
+--------+------+------+------+------+--------+
| 4 | Ben | 18 | 男 | 99 | 看书 |
| 6 | Jack | 18 | 男 | 80 | 玩游戏 |
+--------+------+------+------+------+--------+
2 rows in set (0.00 sec)
mysql> select count(姓名) from 4班;
+-------------+
| count(姓名) |
+-------------+
| 6 |
+-------------+
1 row in set (0.00 sec)
mysql> select count(*) from 4班;
+----------+
| count(*) |
+----------+
| 6 |
+----------+
1 row in set (0.00 sec)
mysql> select count(*) from 4班 where 成绩>90;
+----------+
| count(*) |
+----------+
| 3 |
+----------+
1 row in set (0.00 sec)
mysql> select avg(成绩) from 4班;
+-----------+
| avg(成绩) |
+-----------+
| 89.8333 |
+-----------+
1 row in set (0.00 sec)
mysql> select sum(成绩) from 4班;
+-----------+
| sum(成绩) |
+-----------+
| 539 |
+-----------+
1 row in set (0.00 sec)
mysql> select min(年龄) from 4班;
+-----------+
| min(年龄) |
+-----------+
| 13 |
+-----------+
1 row in set (0.00 sec)
聚合分组
- group by
e.g.1 按照爱好进行分组,计算每组成绩平均值
mysql> select 爱好,avg(成绩) from 4班
-> group by 爱好;
+----------+-----------+
| 爱好 | avg(成绩) |
+----------+-----------+
| 编程 | 100.0000 |
| 打乒乓球 | 90.0000 |
| 看书 | 99.0000 |
| 玩游戏 | 75.0000 |
+----------+-----------+
4 rows in set (0.00 sec)
e.g.2 所有男同学中 爱好人数前两名的爱好
mysql> select 爱好,count(座位号) as number from 4班
-> where 性别='男'
-> group by 爱好
-> order by number desc
-> limit 2;
+--------+--------+
| 爱好 | number |
+--------+--------+
| 玩游戏 | 3 |
| 编程 | 1 |
+--------+--------+
2 rows in set (0.00 sec)
group by 后面的字段名必须要为select后的字段
查询字段和group by 后字段不一致,则必须对该字段进行聚合处理(聚合函数)
聚合筛选
-
having语句
对分组聚合后的结果进行进一步筛选e.g.
mysql> select 爱好,avg(成绩) from 4班 -> group by 爱好 -> having avg(成绩) > 90 -> order by avg(成绩) desc; +------+-----------+ | 爱好 | avg(成绩) | +------+-----------+ | 编程 | 100.0000 | | 看书 | 99.0000 | +------+-----------+ 2 rows in set (0.00 sec)注意
having语句常与group by 联合使用
having语句弥补了where关键字不能与聚合函数联合使用的不足
去重操作
-
distinct语句
不显示字段重复值
注意!distinct和from之间所有字段都相同才会去重
distinct不能对任何字段做聚合处理mysql> select distinct 年龄 from 4班 order by 年龄; +------+ | 年龄 | +------+ | 13 | | 14 | | 15 | | 16 | | 18 | | 19 | +------+ 6 rows in set (0.00 sec) mysql> select count(distinct 年龄) from 4班 order by 年龄; +----------------------+ | count(distinct 年龄) | +----------------------+ | 6 | +----------------------+ 1 row in set (0.00 sec)
索引操作
索引概述
- 定义
索引是对数据库表中一列或多列的值进行排序的一种结构(一般是树形结构),使用索引可快速访问数据库表中的特定信息
- 优点
加快数据搜索速度,提高查找效率
- 缺点
占用数据库物理存储空间,降低写入效率
索引分类
- 普通(MUL)
普通索引:字段值无约束,KEY标志为MUL
- 唯一索引(UNI)
唯一索引(unique):字段值不允许重复,但可以为NULL,KEY标志位UNI
- 主键索引(PRI)
一个表中只能有一个主键字段,主键字段不允许重复,且不能为NULL,KEY标志为PRI。通常设置记录编号字段id,能锁定唯一一条记录。
索引创建
主键索引的创建方法和创建表一样,即设定某个字段为主键(PRIMARY KEY)。下面是普通索引和唯一索引的创建方法:
-
创建表时直接创建索引
create table 表名( 字段名 数据类型, 字段名 数据类型, index(字段名), index(字段名), unique(字段名), # 唯一索引 key(字段名) );注意:key(字段名) 创建索引的情况并不常用,主要起约束作用,创建索引一般还是用index
mysql> create table index_tb ( id int auto_increment, name varchar(32), sex char, primary key(id), # 主键索引 unique(name), # 唯一索引 index(sex) # 普通索引 ); Query OK, 0 rows affected (0.16 sec) mysql> desc index_tb; +-------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | name | varchar(32) | YES | UNI | NULL | | | sex | char(1) | YES | MUL | NULL | | +-------+-------------+------+-----+---------+----------------+ 3 rows in set (0.04 sec) -
在已有表中创建索引
create [unique] index 索引名 on 表名(字段名);e.g. mysql> create index name_index on 4班(姓名); Query OK, 0 rows affected (0.04 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc 4班; +--------+-----------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------+-----------------+------+-----+---------+----------------+ | 座位号 | int unsigned | NO | PRI | NULL | auto_increment | | 姓名 | varchar(32) | NO | MUL | NULL | | | 年龄 | tinyint | YES | | NULL | | | 性别 | enum('男','女') | YES | | NULL | | | 成绩 | int | YES | | NULL | | | 爱好 | varchar(32) | YES | | NULL | | +--------+-----------------+------+-----+---------+----------------+ 6 rows in set (0.04 sec) -
查看索引
1. desc 表名; 2. show index from 表名;e.g. mysql> show index from index_tb; +----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+------ ---+---------------+---------+------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comme nt | Index_comment | Visible | Expression | +----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+------ ---+---------------+---------+------------+ | index_tb | 0 | PRIMARY | 1 | id | A | 3 | NULL | NULL | | BTREE | | | YES | NULL | | index_tb | 0 | name | 1 | name | A | 3 | NULL | NULL | YES | BTREE | | | YES | NULL | | index_tb | 1 | sex | 1 | sex | A | 2 | NULL | NULL | YES | BTREE | | | YES | NULL | +----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+------ ---+---------------+---------+------------+ 3 rows in set (0.06 sec) -
删除索引
drop index 索引名 on 表名; -
已有表添加主键索引或自增长属性
alter table 表名 add primary key key(字段名); alter table 表名 modify 字段名 数据类型 auto_increment; -
创建主键联合索引
primary key (uid,pid); 此时两个字段只要不都相同即可 -
删除主键索引或自增长属性
alter table 表名 drop primary key; alter table 表名 modify 字段名 数据类型;
外键约束和表关联关系
外键约束
- 约束:约束是一种限制,它通过对表的行或列的数据做出限制。来确保表的数据的完整性、唯一性
- foreign key功能:建立表与表之间的某种约束的关系,由于这种关系的存在能够让表与表之间的数据更加的完整。关联性更强
创建部门
mysql> create table dept (id int primary key auto_increment,dname varchar(50) not null);
Query OK, 0 rows affected (0.06 sec)
mysql> select * from dept;
+----+--------+
| id | dname |
+----+--------+
| 1 | 技术部 |
| 2 | 人事部 |
| 3 | 行政部 |
| 4 | 销售部 |
| 5 | 市场部 |
+----+--------+
5 rows in set (0.00 sec)
创建人员
mysql> create table `person` (
-> `id` int primary key auto_increment,
-> `name` varchar(32) not null,
-> `age` tinyint default 0,
-> `sex` enum('m','w','o') default 'o',
-> `salary` decimal(10,2) default 250.00, # 薪水
-> `hire_date` date not null, # 入职日期
-> `dept_id` int default null # 部门
-> );
Query OK, 0 rows affected (0.09 sec)
上面两个表中的每个人员都应该有指定的部门。但是实际上,在没有约束的情况下人员是可以没有部门的,或者也可以添加一个不存在的部门。这显然是不合理的。不是任意情况都需要建立外键关系。如果没有这种约束时,也可以不建立,但是当表与表之间存在这种约束关系时,最好建立
- 主表和从表:若同一个数据库中,B表的外键与A表的主键相对应,则A表为主表,B表为从表
- foreign key 外键的定义语法:
[constraint symbol] foreign key [id] (index_col_name,...) references tbl_name (index_col_name,...) [on delete {restrict | cascade | set null | no action}] [on update {restrict | cascade | set null | no action}]该语法可以在create table 和alter table 时使用,如果不指定constraint symbol,MySQL会自动生成一个名字,可以通过show create table [tb] 查看
建立表时直接建立外键关联,注意本表的外键列类型与指定的主列表相同,且主表指定列需为主键
create table `person` (
`id` int primary key auto_increment,
`name` varchar(32) not null,
`age` tinyint default 0,
`sex` enum('m','w','o') default 'o',
`salary` decimal(10,2) default 250.00, # 薪水
`hire_date` date not null, # 入职日期
`dept_id` int default null, # 部门
constraint dept_id foreign key(dept_id) references dept(id)
);
此时如果dept_id的值在dept中找不到,就会报错:
mysql> insert into person values(1,'Ben',22,'m',320000,'2018-1-1',666);
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`zjy`.`person`, CONSTRAINT `dept_id` FOREIGN KEY (`dept_id`) REFERENCES `dept` (`id`))
建立表之后增加外键
alter table person add constraint dept_id foreign key(dept_id) references dept(id);
解除外键约束
alter table person drop foreign key dept_id;
- restrict(默认):on delete restrict,on update restrict
- 当主表删除记录时,如果从表中有相关联记录则不允许主表删除
- 当主表更改主键字段值时,如果从表有相关记录则不允许更改
- cascade:数据级联更新on delete cascade,on update cascade
- 当主表删除记录或更改被参照字段的值时,从表会级联更新
- set null:on delete set null,on update set null
- 当主表删除记录时,从表外键字段值变为null
- 当主表更改主键字段值时,从表外键字段值变为null
- no action
- 同restrict,都是立即检查外键限制
mysql> alter table person drop foreign key dept_id;
Query OK, 0 rows affected (0.04 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> drop index dept_id on person;
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table person add constraint dept_id foreign key(dept_id) references dept(id) on delete cascade on update cascade;
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from person;
+----+------+------+------+------------+------------+---------+
| id | name | age | sex | salary | hire_date | dept_id |
+----+------+------+------+------------+------------+---------+
| 1 | Ben | 22 | m | 2000000.00 | 2018-09-01 | 0 |
+----+------+------+------+------------+------------+---------+
1 row in set (0.00 sec)
mysql> select * from dept;
+----+--------+
| id | dname |
+----+--------+
| 0 | 技术部 |
| 2 | 人事部 |
| 3 | 行政部 |
| 4 | 销售部 |
| 5 | 市场部 |
+----+--------+
5 rows in set (0.00 sec)
mysql> update dept set id=1 where dname='技术部';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from person;
+----+------+------+------+------------+------------+---------+
| id | name | age | sex | salary | hire_date | dept_id |
+----+------+------+------+------------+------------+---------+
| 1 | Ben | 22 | m | 2000000.00 | 2018-09-01 | 1 |
+----+------+------+------+------------+------------+---------+
1 row in set (0.01 sec)
可以看到当dept中的id修改时,person中的dept_id也会修改为对应的值
表关联设计
当我们应对复杂的数据关系的时候,数据表的设计就显得尤为重要。认识数据之间的依赖关系是更加合理创建数据表关联性的前提
-
一对一关系
一张表的一条记录一定只能与另外一张表的一条记录进行对应,反之亦然
举例:学生信息和学籍档案,一个学生对应一个档案,一个档案也只属于一个学生
mysql> create table student ( -> id int primary key auto_increment, -> name varchar(50) not null -> ); Query OK, 0 rows affected (0.03 sec) mysql> create table record( -> id int primary key auto_increment, -> comment text not null, -> st_id int unique, # 创建唯一索引 -> foreign key(st_id) references student(id) on delete cascade on update cascade -> ); Query OK, 0 rows affected (0.04 sec) -
一对多关系
一张表中有一条记录可以对应另外一张表中的多条记录;但是反过来,另一张表的一条记录,只能对应第一张表的一条记录
举例:一个人可以拥有多辆汽车,每辆车登记的车主只有一人
mysql> create table person( -> id varchar(32) primary key, -> name varchar(30), -> sex char(1), -> age int not null -> ); Query OK, 0 rows affected (0.05 sec) mysql> create table car( -> id varchar(32) primary key, -> name varchar(30), -> price decimal(10,2), -> pid varchar(32), -> constraint car_fk foreign key(pid) references person(id) -> ); Query OK, 0 rows affected (0.04 sec) -
多对多关系
一对表中(A)的一条记录能够对应另外一张表(B)中的多条记录;同时B表中的一条记录也能对应A表中的多条记录
举例:一个运动员可以参加多个运动项目,每个项目也会有多个运动员参加
mysql> create table athlete(id int not null auto_increment,name varchar(32),age tinyint,country varchar(50),description text,primary key(id)); Query OK, 0 rows affected (0.05 sec) mysql> create table item (id int not null auto_increment,rname varchar(32) not null,primary key(id)); Query OK, 0 rows affected (0.06 sec) mysql> create table athlete_item (aid int not null,tid int not null,primary key(aid,tid),constraint athlete_fk foreign key(aid) references athlete(id),constraint item_fk foreign key(tid) references item(id)); Query OK, 0 rows affected (0.07 sec)