离线/在线迁移
自 Liberty 以来,Neutron 维护着两个平行的 Alembic 迁移分支。
第一个称为“扩展”,用于存储仅扩展迁移规则。这些规则是严格附加的,可以在 neutron-server 运行时应用。添加数据库模式更改的示例包括:创建新表、添加新表列、添加新索引等。
第二个分支称为“contract”,用于存储在 neutron-server 运行时应用不安全的迁移规则。这些包括:列或表删除,将数据从数据库的一个部分移动到另一个部分(重命名列,将单个表转换为多个表等),引入或修改约束等。
拆分的目的是允许在 neutron-server 运行时从“扩展”分支调用这些安全迁移,从而减少升级服务所需的停机时间。
开发人员
当您提交对 Neutron 或更改数据库模型定义的子项目的更改时,需要数据库迁移脚本。迁移脚本是一个特殊的 Python 文件,其中包含升级数据库以匹配模型定义中的更改的代码。Alembic 将执行这些脚本以提供修订之间的线性迁移路径。neutron-db-manage 命令可用于生成迁移脚本供您完成。模板中的操作是 Alembic 迁移库支持的操作。
扩展和收缩脚本
迁移脚本的过时“无分支”设计包括它指示模式的特定“版本”,并包括立即将所有必要更改应用于数据库的指令。如果我们查看脚本示例2d2a8a565438_hierarchical_binding.py,我们将看到:
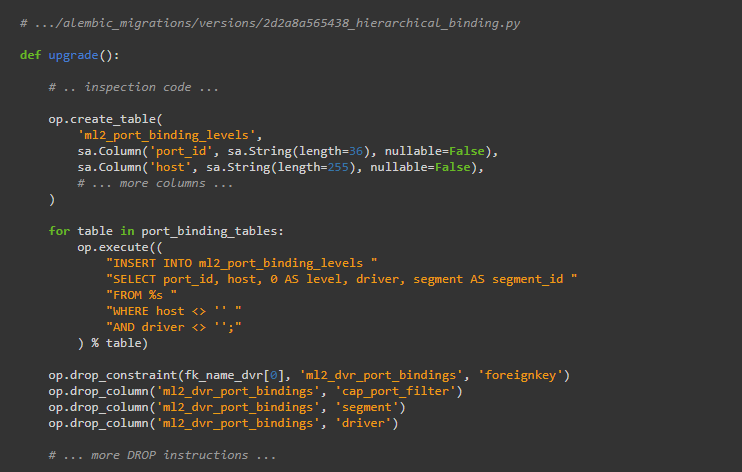
上面的脚本包含在“expand”和“contract”类别下的指令,以及一些数据迁移。该op.create_table 指令是一个“扩展”;当旧版本的应用程序仍在运行时,它可能会安全运行,因为旧代码根本不查找此表。的op.drop_constraint和op.drop_column指令是“合同”指令(在下拉柱如此比下降约束); 至少运行op.drop_column指令意味着旧版本的应用程序将失败,因为它将尝试访问这些不再存在的列。
此脚本中的数据迁移正在向新添加的ml2_port_binding_levels表中添加新行。
在新的迁移脚本目录结构下,上面的脚本会被表述为两个脚本;“扩展”和“合同”脚本:
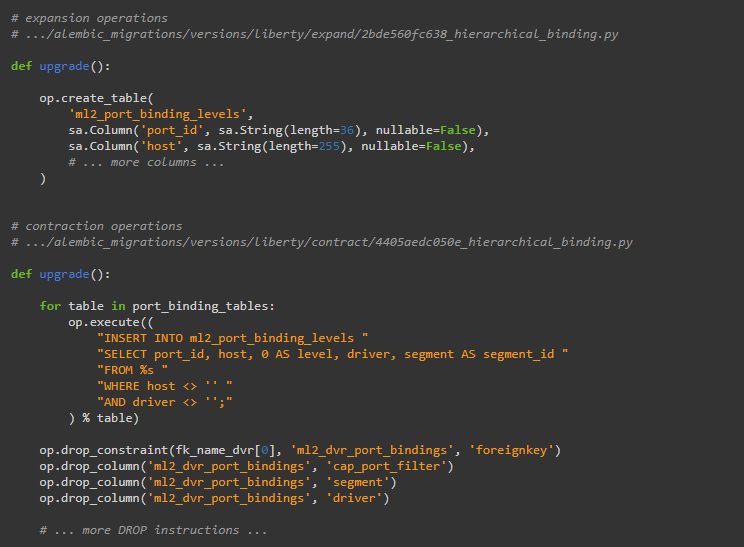
这两个脚本将出现在不同的子目录中,也是完全独立的版本控制流的一部分。“expand”操作在“expand”脚本中,“contract”操作在“contract”脚本中。
目前,数据迁移规则也属于合约分支。人们期望最终实时数据迁移进入中间件,该中间件将意识到要聚合的不同数据库模式元素,但 Neutron 仍然不在那里。
仅包含扩展或收缩规则的脚本不需要分成两部分。
如果收缩脚本依赖于来自扩展流的脚本,则应在收缩脚本中添加以下指令:

扩展和收缩分支异常
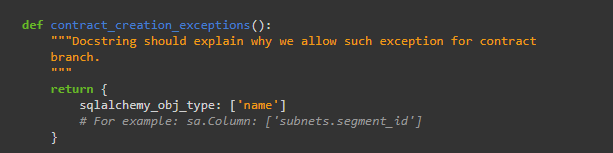
在某些情况下,我们必须在合约迁移中进行“扩展”操作。例如,表'networksegments'在合约迁移中被重命名,因此所有对该表的操作也需要在合约分支中。对于此类情况,我们使用contract_creation_exceptions应作为此类迁移的一部分实施的 。这是获得功能测试通过所必需的。
用法:
用于冲突管理的 HEAD 文件
在目录中neutron/db/migration/alembic_migrations/versions有两个文件,CONTRACT_HEAD和EXPAND_HEAD. 这些文件包含每个分支中主要修订的 ID。这些文件的目的是验证修订时间表并防止非线性更改进入合并队列。
当您通过 neutron-db-manage 创建新的迁移脚本时,这些文件将自动更新。但是,如果在审查您的更改时合并了另一个迁移脚本,您将需要通过更改down_revision迁移脚本中的 来手动解决冲突。
应用数据库迁移规则
要仅应用扩展规则,请执行:

第一步完成后,你可以停止 neutron-server,应用剩余的非扩展迁移规则,如果有的话:
![]()
最后,再次启动您的 neutron-server。
如果您的云中有多个 neutron-server 实例,并且有未应用于数据库的未决合约脚本,则需要在执行“upgrade –contract”之前完全关闭所有这些服务。您可以通过检查以下命令返回的消息来确定是否有任何待处理的合约脚本:
标记里程碑修订
当为 neutron 或子项目完成命名版本(liberty、mitaka 等)时,必须标记该版本每个分支开头的 alembic 修订脚本。这称为里程碑修订标记。
例如,这里有一个补丁标记了 neutron-fwaas 子项目的自由里程碑修订。请注意,每个分支(扩展和收缩)都带有标记。
标记里程碑允许 neutron-db-manage 将架构升级到里程碑版本,例如:

使用当前数据库模式生成可比较的元数据
目录neutron/db/migration/models包含 module head.py,它提供当前 HEAD 的所有数据库模型。其目的是创建与当前数据库模式相当的元数据。数据库模式由 alembic 迁移脚本生成。模型必须匹配,这通过 Neutron 功能测试套件中的模型迁移同步测试进行验证。该测试要求所有包含 DB 模型的模块都由 head.py 导入,以便进行完整的比较。
添加新的数据库模型时,开发人员必须更新此模块,否则更改将无法合并。