本文所做的实验是用汇编实现字符串逆向排序的功能。
其实就相当于C语言中的reverse( ) 函数。
简要叙述:
将字符串 ''abcdefghij" 放到指定的内存位置,同时分配一段内存作为栈
然后将字符串入栈再出栈,以此实现字符串逆向排序功能
一下就是代码:

编译:

连接:
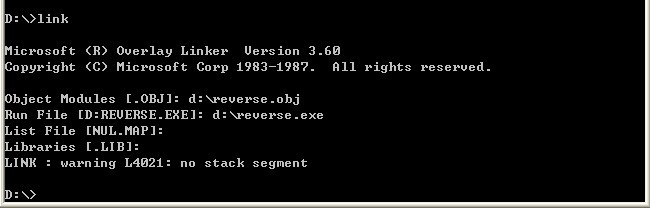
调试:
初始化阶段:
观察右边内存中的数据,

入栈结束:
字符串“abcdefghij” 已经存进内存中
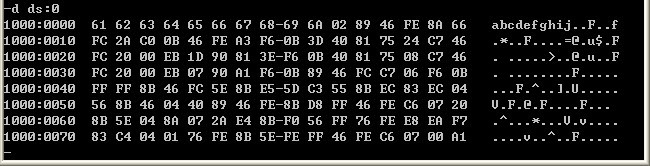
出栈结束:
字符串逆向排序完成。
实现原理:
首先在内存中定义数据段和栈;
将字符串内容放到内存中数据段和栈中;
由于栈的特性是后进先出,所以注意出栈时数据的排位
遇到的问题:
虽然功能是成功了,但是写代码的过程中发现了些问题,实在是搞不懂。
在debug中可以编译 mov [0],ax 这句代码
但是用masm编译工具编译时就报错。报错原因是不能直接给标量赋值。
只能将代码改为
mov bx,0
mov [bx],ax
用寄存器中间过渡就行。为什么在debug中编译就能通过呢?
过了几天看到书本后面的内容,现在终于搞懂了,哈。
原来debug和编译器masm对某些指令有着不同的处理。
看下面的例子
分别用debug和masm编译一下代码:
mov ax,2000
mov ds,ax
mov al,[0]
mov bl,[1]
mov cl,[2]
mov dl,[3]
masm对指令的解释:
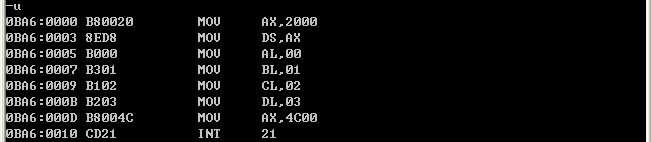
debug对指令的解释:

从它们的机器码可以看出它们对形如 " mov ax,[0] “ 这类指令在解释上的不同。
可以看出debug将它解释为 "[idata]" 是一个内存单元,”idata“ 是内存单元的编译地址;
而编译器将 "[idata]" 解释为 "idata" 。
你敢不敢扫我!!!

原文出处:http://www.cnblogs.com/zhuojun