因为最近的工作需要写一些SQL,但是之前只学过,没有实地的编过SQL。
在工作中是需要用Hive来写,本地没有环境,所以在牛客网上来进行练习。
本次内容全部来源于牛客网,使用的是SQLite。
第1题:
题目:
查找最晚入职员工的所有信息,为了减轻入门难度,目前所有的数据里员工入职的日期都不是同一天(sqlite里面的注释为--,mysql为comment)
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL, -- '员工编号'
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
程序:
SELECT * FROM employees WHERE hire_date = (SELECT MAX(hire_date) FROM employees);
思路:
对于这样的一个单表查询问题,需要注意的是查询的条件,因此这里使用一个子查询来找出表中的最晚的时间就可以了。
第2题:
题目:
查找入职员工时间排名倒数第三的员工所有信息,为了减轻入门难度,目前所有的数据里员工入职的日期都不是同一天
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
程序:
SELECT * FROM employees WHERE hire_date = (SELECT hire_date FROM employees ORDER BY hire_date DESC limit 2 ,1);
思路:
同样也是单表查询,但是在查询条件中增加了时间上倒数第三个的信息,因此在子查询中使用了将时间降序排列并且使用limit2,1找到倒数第三个时间。
第3题:
题目:
`emp_no` int(11) NOT NULL, -- '员工编号',
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL, -- '部门编号'
`emp_no` int(11) NOT NULL, -- '员工编号'
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
程序:
SELECT a.*, b.dept_no FROM salaries AS a INNER JOIN dept_manager AS b ON a.emp_no = b.emp_no WHERE b.to_date = '9999-01-01' AND a.to_date = '9999-01-01' ORDER BY a.emp_no ASC;
思路:
这道题涉及到两个表,因此需要进行关联,关联的时候要看两个表的主键。使用相同的主键来进行关联,也就是使用emp_no。这道题涉及到三个条件,分别是dept_manager.to_date='9999-01-01'、salaries.to_date='9999-01-01'和salaries.emp_no升序排序。
第4题:
题目:
查找所有已经分配部门的员工的last_name和first_name以及dept_no(请注意输出描述里各个列的前后顺序)
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
程序:
SELECT a.last_name, a.first_name, b.dept_no FROM employees AS a INNER JOIN dept_emp AS b ON a.emp_no = b.emp_no
思路:
题目和第3题很像,但是比第3题简单,只需要按照题目要求进行选择就行。
第5题:
题目:
查找所有员工的last_name和first_name以及对应部门编号dept_no,也包括暂时没有分配具体部门的员工(请注意输出描述里各个列的前后顺序)
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
程序:
SELECT a.last_name, a.first_name, b.dept_no FROM employees AS a LEFT JOIN dept_emp AS b ON a.emp_no = b.emp_no;
思路:
题目里提到结果要包含没有分配具体部门的员工,这时候要想到使用left join,而且将员工的表作为左表。
第6题:
题目:
查找所有员工入职时候的薪水情况,给出emp_no以及salary, 并按照emp_no进行逆序(请注意,一个员工可能有多次涨薪的情况)
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
程序:
SELECT a.emp_no, a.salary FROM salaries AS a INNER JOIN employees AS b ON a.emp_no = b.emp_no WHERE a.from_date = b.hire_date ORDER BY b.emp_no DESC;
思路:
同样是两个表关联的问题,题目中要求注意一个员工可能有多次涨薪的情况,在寻求员工入职时的薪水时,只需要找到两个表的初始时间相同就行。
第7题:
题目:
查找薪水变动超过15次的员工号emp_no以及其对应的变动次数t
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
程序:
SELECT emp_no, COUNT(from_date) AS t FROM salaries GROUP BY emp_no HAVING t > 15
思路:
对于单一表,进行合理的条件设计,统计变动次数大于15使用COUNT()函数,在使用COUNT()函数的时候不能用在WHERE中,要使用HAVING。
第8题:
题目:
找出所有员工当前(to_date='9999-01-01')具体的薪水salary情况,对于相同的薪水只显示一次,并按照逆序显示
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
程序:
SELECT salary FROM salaries WHERE to_date = '9999-01-01' GROUP BY salary ORDER BY salary DESC
思路:
对于薪水只显示一次,使用GROUP BY可以合并。
第9题:
题目:
获取所有部门当前(dept_manager.to_date='9999-01-01')manager的当前(salaries.to_date='9999-01-01')薪水情况,给出dept_no, emp_no以及salary(请注意,同一个人可能有多条薪水情况记录)
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL,
`emp_no` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
程序:
SELECT a.dept_no, a.emp_no, b.salary FROM dept_manager AS a JOIN salaries AS b ON a.emp_no = b.emp_no WHERE a.to_date = '9999-01-01' AND b.to_date = '9999-01-01'
思路:
题目较简单,不进行讲述。
第10题:
题目:
获取所有非manager的员工emp_no
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL,
`emp_no` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
INSERT INTO dept_manager VALUES('d002',10006,'1990-08-05','9999-01-01');
INSERT INTO dept_manager VALUES('d003',10005,'1989-09-12','9999-01-01');
INSERT INTO dept_manager VALUES('d004',10004,'1986-12-01','9999-01-01');
INSERT INTO dept_manager VALUES('d005',10010,'1996-11-24','2000-06-26');
INSERT INTO dept_manager VALUES('d006',10010,'2000-06-26','9999-01-01');
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10003,'1959-12-03','Parto','Bamford','M','1986-08-28');
INSERT INTO employees VALUES(10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01');
INSERT INTO employees VALUES(10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12');
INSERT INTO employees VALUES(10006,'1953-04-20','Anneke','Preusig','F','1989-06-02');
INSERT INTO employees VALUES(10007,'1957-05-23','Tzvetan','Zielinski','F','1989-02-10');
INSERT INTO employees VALUES(10008,'1958-02-19','Saniya','Kalloufi','M','1994-09-15');
INSERT INTO employees VALUES(10009,'1952-04-19','Sumant','Peac','F','1985-02-18');
INSERT INTO employees VALUES(10010,'1963-06-01','Duangkaew','Piveteau','F','1989-08-24');
INSERT INTO employees VALUES(10011,'1953-11-07','Mary','Sluis','F','1990-01-22');
程序:
SELECT a.emp_no
FROM employees AS a LEFT OUTER JOIN dept_manager AS b
ON a.emp_no = b.emp_no
WHERE b.emp_no IS NULL
思路:
这道题使用的是except函数的思路,使用LEFT OUTER JOIN + 字段IS NULL(一般是右表)来实现。
第11题:
题目:
获取所有员工当前的(dept_manager.to_date='9999-01-01')manager,如果员工是manager的话不显示(也就是如果当前的manager是自己的话结果不显示)。输出结果第一列给出当前员工的emp_no,第二列给出其manager对应的emp_no。
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL, -- '所有的员工编号'
`dept_no` char(4) NOT NULL, -- '部门编号'
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL, -- '部门编号'
`emp_no` int(11) NOT NULL, -- '经理编号'
`from_date` date NOT NULL,
`to_date` date NOT NULL,
INSERT INTO dept_emp VALUES(10002,'d001','1996-08-03','9999-01-01');
INSERT INTO dept_emp VALUES(10003,'d004','1995-12-03','9999-01-01');
INSERT INTO dept_emp VALUES(10004,'d004','1986-12-01','9999-01-01');
INSERT INTO dept_emp VALUES(10005,'d003','1989-09-12','9999-01-01');
INSERT INTO dept_emp VALUES(10006,'d002','1990-08-05','9999-01-01');
INSERT INTO dept_emp VALUES(10007,'d005','1989-02-10','9999-01-01');
INSERT INTO dept_emp VALUES(10008,'d005','1998-03-11','2000-07-31');
INSERT INTO dept_emp VALUES(10009,'d006','1985-02-18','9999-01-01');
INSERT INTO dept_emp VALUES(10010,'d005','1996-11-24','2000-06-26');
INSERT INTO dept_emp VALUES(10010,'d006','2000-06-26','9999-01-01');
INSERT INTO dept_manager VALUES('d001',10002,'1996-08-03','9999-01-01');
INSERT INTO dept_manager VALUES('d002',10006,'1990-08-05','9999-01-01');
INSERT INTO dept_manager VALUES('d003',10005,'1989-09-12','9999-01-01');
INSERT INTO dept_manager VALUES('d004',10004,'1986-12-01','9999-01-01');
INSERT INTO dept_manager VALUES('d005',10010,'1996-11-24','2000-06-26');
INSERT INTO dept_manager VALUES('d006',10010,'2000-06-26','9999-01-01');
程序:
SELECT a.emp_no, b.emp_no FROM dept_emp AS a INNER JOIN dept_manager AS b ON a.dept_no = b.dept_no WHERE a.emp_no <> b.emp_no AND b.to_date = '9999-01-01'
思路:
题目中有一个判断条件如果员工是manager的话不显示,则使用<>来处理。
第12题:
题目:
获取所有部门中当前(dept_emp.to_date = '9999-01-01')员工当前(salaries.to_date='9999-01-01')薪水最高的相关信息,给出dept_no, emp_no以及其对应的salary,按照部门编号升序排列。
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
INSERT INTO dept_emp VALUES(10001,'d001','1986-06-26','9999-01-01');
INSERT INTO dept_emp VALUES(10002,'d001','1996-08-03','9999-01-01');
INSERT INTO dept_emp VALUES(10003,'d001','1996-08-03','1997-08-03');
INSERT INTO salaries VALUES(10001,90000,'1986-06-26','1987-06-26');
INSERT INTO salaries VALUES(10001,88958,'2002-06-22','9999-01-01');
INSERT INTO salaries VALUES(10002,72527,'1996-08-03','1997-08-03');
INSERT INTO salaries VALUES(10002,72527,'2000-08-02','2001-08-02');
INSERT INTO salaries VALUES(10002,72527,'2001-08-02','9999-01-01');
INSERT INTO salaries VALUES(10003,90000,'1996-08-03','1997-08-03');
程序:
SELECT a.dept_no, a.emp_no, MAX(b.salary) FROM dept_emp AS a INNER JOIN salaries AS b ON a.emp_no = b.emp_no WHERE a.to_date = '9999-01-01' AND b.to_date = '9999-01-01' GROUP BY a.dept_no ORDER BY a.dept_no ASC
思路:
使用MAX()函数来找到最大的薪水,使用GROUP BY来对部门进行处理,使用ORDER BY进行排序。
第13题:
题目:
从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t。
CREATE TABLE IF NOT EXISTS "titles" (
`emp_no` int(11) NOT NULL,
`title` varchar(50) NOT NULL,
`from_date` date NOT NULL,
INSERT INTO titles VALUES(10001,'Senior Engineer','1986-06-26','9999-01-01');
INSERT INTO titles VALUES(10002,'Staff','1996-08-03','9999-01-01');
INSERT INTO titles VALUES(10003,'Senior Engineer','1995-12-03','9999-01-01');
INSERT INTO titles VALUES(10004,'Engineer','1986-12-01','1995-12-01');
INSERT INTO titles VALUES(10004,'Senior Engineer','1995-12-01','9999-01-01');
INSERT INTO titles VALUES(10005,'Senior Staff','1996-09-12','9999-01-01');
INSERT INTO titles VALUES(10005,'Staff','1989-09-12','1996-09-12');
INSERT INTO titles VALUES(10006,'Senior Engineer','1990-08-05','9999-01-01');
INSERT INTO titles VALUES(10007,'Senior Staff','1996-02-11','9999-01-01');
INSERT INTO titles VALUES(10007,'Staff','1989-02-10','1996-02-11');
INSERT INTO titles VALUES(10008,'Assistant Engineer','1998-03-11','2000-07-31');
INSERT INTO titles VALUES(10009,'Assistant Engineer','1985-02-18','1990-02-18');
INSERT INTO titles VALUES(10009,'Engineer','1990-02-18','1995-02-18');
INSERT INTO titles VALUES(10009,'Senior Engineer','1995-02-18','9999-01-01');
INSERT INTO titles VALUES(10010,'Engineer','1996-11-24','9999-01-01');
INSERT INTO titles VALUES(10010,'Engineer','1996-11-24','9999-01-01');

程序:
SELECT title, COUNT(title) AS t FROM titles GROUP BY title HAVING t >= 2
思路:
思路和第7题很像。
第14题:
题目:
从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t。
注意对于重复的emp_no进行忽略(即emp_no重复的title不计算,title对应的数目t不增加)。
CREATE TABLE IF NOT EXISTS `titles` (
`emp_no` int(11) NOT NULL,
`title` varchar(50) NOT NULL,
`from_date` date NOT NULL,
INSERT INTO titles VALUES(10002,'Staff','1996-08-03','9999-01-01');
INSERT INTO titles VALUES(10003,'Senior Engineer','1995-12-03','9999-01-01');
INSERT INTO titles VALUES(10004,'Engineer','1986-12-01','1995-12-01');
INSERT INTO titles VALUES(10004,'Senior Engineer','1995-12-01','9999-01-01');
INSERT INTO titles VALUES(10005,'Senior Staff','1996-09-12','9999-01-01');
INSERT INTO titles VALUES(10005,'Staff','1989-09-12','1996-09-12');
INSERT INTO titles VALUES(10006,'Senior Engineer','1990-08-05','9999-01-01');
INSERT INTO titles VALUES(10007,'Senior Staff','1996-02-11','9999-01-01');
INSERT INTO titles VALUES(10007,'Staff','1989-02-10','1996-02-11');
INSERT INTO titles VALUES(10008,'Assistant Engineer','1998-03-11','2000-07-31');
INSERT INTO titles VALUES(10009,'Assistant Engineer','1985-02-18','1990-02-18');
INSERT INTO titles VALUES(10009,'Engineer','1990-02-18','1995-02-18');
INSERT INTO titles VALUES(10009,'Senior Engineer','1995-02-18','9999-01-01');
INSERT INTO titles VALUES(10010,'Engineer','1996-11-24','9999-01-01');
INSERT INTO titles VALUES(10010,'Engineer','1996-11-24','9999-01-01');
SELECT title, COUNT(DISTINCT emp_no) AS t FROM titles GROUP BY title HAVING t >= 2
思路:
不计算重复的emp_no,使用DISTINCT。
第15题:
题目:
查找employees表所有emp_no为奇数,且last_name不为Mary(注意大小写)的员工信息,并按照hire_date逆序排列(题目不能使用mod函数)
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10003,'1959-12-03','Parto','Bamford','M','1986-08-28');
INSERT INTO employees VALUES(10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01');
INSERT INTO employees VALUES(10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12');
INSERT INTO employees VALUES(10006,'1953-04-20','Anneke','Preusig','F','1989-06-02');
INSERT INTO employees VALUES(10007,'1957-05-23','Tzvetan','Zielinski','F','1989-02-10');
INSERT INTO employees VALUES(10008,'1958-02-19','Saniya','Kalloufi','M','1994-09-15');
INSERT INTO employees VALUES(10009,'1952-04-19','Sumant','Peac','F','1985-02-18');
INSERT INTO employees VALUES(10010,'1963-06-01','Duangkaew','Piveteau','F','1989-08-24');
INSERT INTO employees VALUES(10011,'1953-11-07','Mary','Sluis','F','1990-01-22');

程序:
SELECT * FROM employees WHERE emp_no % 2 = 1 AND last_name != 'Mary' ORDER BY hire_date DESC
思路:
题目中不允许使用mod()函数,使用求余数运算来进行处理。
第16题:
题目:
统计出当前(titles.to_date='9999-01-01')各个title类型对应的员工当前(salaries.to_date='9999-01-01')薪水对应的平均工资。结果给出title以及平均工资avg。
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
CREATE TABLE IF NOT EXISTS "titles" (
`emp_no` int(11) NOT NULL,
`title` varchar(50) NOT NULL,
`from_date` date NOT NULL,
INSERT INTO salaries VALUES(10003,43311,'2001-12-01','9999-01-01');
INSERT INTO salaries VALUES(10004,70698,'1986-12-01','1995-12-01');
INSERT INTO salaries VALUES(10004,74057,'1995-12-01','9999-01-01');
INSERT INTO salaries VALUES(10006,43311,'2001-08-02','9999-01-01');
INSERT INTO salaries VALUES(10007,88070,'2002-02-07','9999-01-01');
INSERT INTO titles VALUES(10001,'Senior Engineer','1986-06-26','9999-01-01');
INSERT INTO titles VALUES(10003,'Senior Engineer','2001-12-01','9999-01-01');
INSERT INTO titles VALUES(10004,'Engineer','1986-12-01','1995-12-01');
INSERT INTO titles VALUES(10004,'Senior Engineer','1995-12-01','9999-01-01');
INSERT INTO titles VALUES(10006,'Senior Engineer','2001-08-02','9999-01-01');
INSERT INTO titles VALUES(10007,'Senior Staff','1996-02-11','9999-01-01');
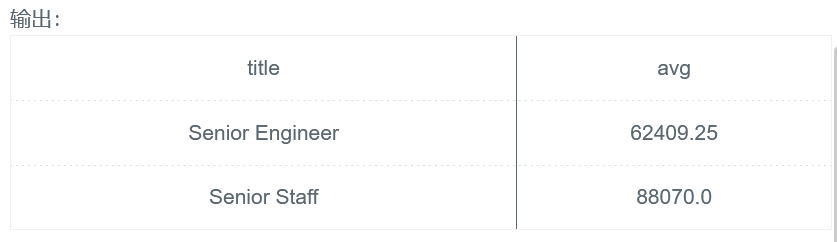
程序:
SELECT a.title,AVG(b.salary) AS avg FROM titles AS a, salaries AS b where a.emp_no = b.emp_no and a.to_date='9999-01-01' and b.to_date='9999-01-01' GROUP BY a.title
思路:
正确使用AVG()函数就行。
第17题:
题目:
获取当前(to_date='9999-01-01')薪水第二多的员工的emp_no以及其对应的薪水salary
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
程序:
SELECT emp_no, salary FROM salaries WHERE to_date = '9999-01-01' ORDER BY salary DESC LIMIT 1,1
思路:
与第2题思路类似。
第18题:
题目:
查找当前薪水(to_date='9999-01-01')排名第二多的员工编号emp_no、薪水salary、last_name以及first_name,你可以不使用order by完成吗
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
程序:
SELECT a.emp_no, MAX(b.salary), a.last_name, a.first_name FROM employees AS a INNER JOIN salaries AS b ON a.emp_no = b.emp_no WHERE b.to_date = '9999-01-01' AND b.salary < (SELECT MAX(salary) FROM salaries WHERE to_date = '9999-01-01')
思路:
由于不允许使用ORDER BY,因此需要使用子查询。在子查询中找到最大的薪水值,在条件查询中设置小于这个值,再去寻找当前情况下的最大薪水就可以得到排名第二多的薪水了。
第19题:
题目:
查找所有员工的last_name和first_name以及对应的dept_name,也包括暂时没有分配部门的员工
CREATE TABLE `departments` (
`dept_no` char(4) NOT NULL,
`dept_name` varchar(40) NOT NULL,
PRIMARY KEY (`dept_no`));
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
INSERT INTO departments VALUES('d002','Finance');
INSERT INTO departments VALUES('d003','Human Resources');
INSERT INTO departments VALUES('d004','Production');
INSERT INTO departments VALUES('d005','Development');
INSERT INTO departments VALUES('d006','Quality Management');
INSERT INTO dept_emp VALUES(10001,'d001','1986-06-26','9999-01-01');
INSERT INTO dept_emp VALUES(10002,'d001','1996-08-03','9999-01-01');
INSERT INTO dept_emp VALUES(10003,'d004','1995-12-03','9999-01-01');
INSERT INTO dept_emp VALUES(10004,'d004','1986-12-01','9999-01-01');
INSERT INTO dept_emp VALUES(10005,'d003','1989-09-12','9999-01-01');
INSERT INTO dept_emp VALUES(10006,'d002','1990-08-05','9999-01-01');
INSERT INTO dept_emp VALUES(10007,'d005','1989-02-10','9999-01-01');
INSERT INTO dept_emp VALUES(10008,'d005','1998-03-11','2000-07-31');
INSERT INTO dept_emp VALUES(10009,'d006','1985-02-18','9999-01-01');
INSERT INTO dept_emp VALUES(10010,'d005','1996-11-24','2000-06-26');
INSERT INTO dept_emp VALUES(10010,'d006','2000-06-26','9999-01-01');
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10003,'1959-12-03','Parto','Bamford','M','1986-08-28');
INSERT INTO employees VALUES(10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01');
INSERT INTO employees VALUES(10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12');
INSERT INTO employees VALUES(10006,'1953-04-20','Anneke','Preusig','F','1989-06-02');
INSERT INTO employees VALUES(10007,'1957-05-23','Tzvetan','Zielinski','F','1989-02-10');
INSERT INTO employees VALUES(10008,'1958-02-19','Saniya','Kalloufi','M','1994-09-15');
INSERT INTO employees VALUES(10009,'1952-04-19','Sumant','Peac','F','1985-02-18');
INSERT INTO employees VALUES(10010,'1963-06-01','Duangkaew','Piveteau','F','1989-08-24');
INSERT INTO employees VALUES(10011,'1953-11-07','Mary','Sluis','F','1990-01-22');
程序:
SELECT c.last_name, c.first_name, a.dept_name FROM employees AS c LEFT JOIN dept_emp AS b ON c.emp_no = b.emp_no LEFT JOIN departments AS a ON b.dept_no = a.dept_no
思路:
三个表的关联,找到对应的主键就行。根据题目的意思还要使用LEFT JOIN。
第20题:
题目:
查找员工编号emp_no为10001其自入职以来的薪水salary涨幅(总共涨了多少)growth(可能有多次涨薪,没有降薪)
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
程序:
SELECT (MAX(salary) - MIN(salary)) AS growth FROM salaries WHERE emp_no = 10001
思路:
由于不存在降薪的情况,所以使用MAX() - MIN()来进行计算。
第21题:
题目:
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL, -- '入职时间'
PRIMARY KEY (`emp_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL, -- '一条薪水记录开始时间'
`to_date` date NOT NULL, -- '一条薪水记录结束时间'
PRIMARY KEY (`emp_no`,`from_date`));

程序:
SELECT b.emp_no, (b.salary - a.salary) AS growth FROM (SELECT c.emp_no, d.salary FROM employees AS c INNER JOIN salaries AS d ON c.emp_no = d.emp_no WHERE c.hire_date = d.from_date) AS a INNER JOIN (SELECT c.emp_no, d.salary FROM employees AS c INNER JOIN salaries AS d ON c.emp_no = d.emp_no WHERE d.to_date = '9999-01-01') AS b ON a.emp_no = b.emp_no ORDER BY growth ASC
思路:
对于这样的问题,使用一个SQL是无法写出来的,因为其中涉及到了两个重要的时间,包括第一次发薪水的时间和最后一次发薪水的时间。在这道题中需要使用两个临时表,一个用于计算第一次发薪水的情况,一个用于计算最近一次发薪水的情况。之后按照相应的条件来进行处理就好了。
第22题:
题目:
统计各个部门的工资记录数,给出部门编码dept_no、部门名称dept_name以及部门在salaries表里面有多少条记录sum
CREATE TABLE `departments` (
`dept_no` char(4) NOT NULL,
`dept_name` varchar(40) NOT NULL,
PRIMARY KEY (`dept_no`));
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));

程序:
SELECT a.dept_no, a.dept_name, COUNT(*) AS sum FROM dept_emp AS b LEFT JOIN departments AS a ON b.dept_no = a.dept_no LEFT JOIN salaries AS c ON b.emp_no = c.emp_no GROUP BY a.dept_no
思路:
思路较简单,就是搞清楚三个表之间的关联关系就行。
第23题:
题目:
对所有员工的当前(to_date='9999-01-01')薪水按照salary进行按照1-N的排名,相同salary并列且按照emp_no升序排列
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
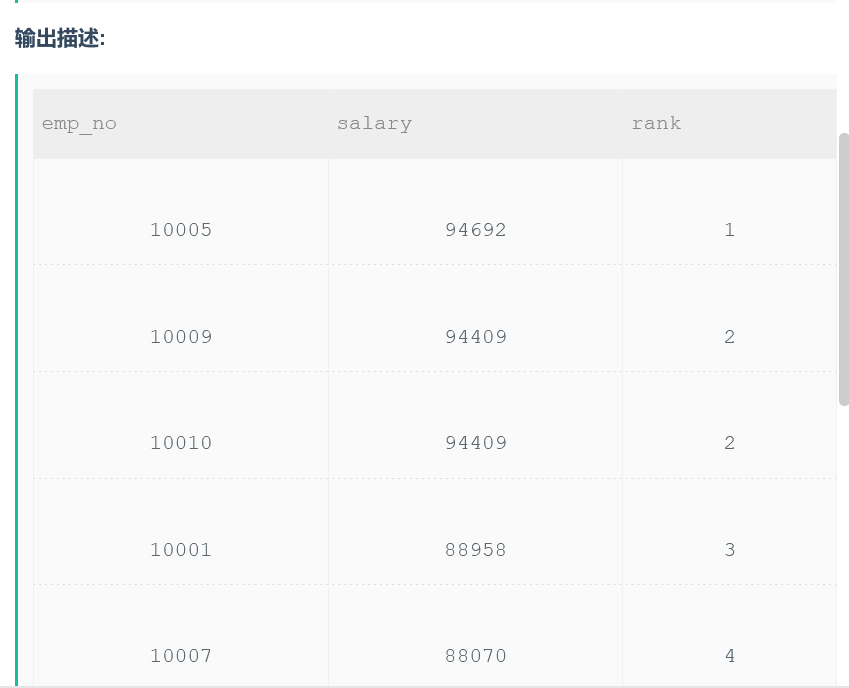
程序:
SELECT emp_no, salary, dense_rank() over(ORDER BY salary DESC) AS rank FROM salaries WHERE to_date = '9999-01-01';
思路:
按照题目的描述需要按照薪水的高低来进行排序,但是遇到相同薪水的情况,需要按照既定的顺序往下排列,在内部按照emp_no进行排列,这时候应该想到排序的一些函数,由于需要连续,所以使用DENSE_RANK() OVER()来实现。
第24题:
题目:
获取所有非manager员工当前的薪水情况,给出dept_no、emp_no以及salary ,当前表示to_date='9999-01-01'
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL,
`emp_no` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
程序:
SELECT a.dept_no, b.emp_no, c.salary FROM dept_emp AS a INNER JOIN employees AS b ON a.emp_no = b.emp_no INNER JOIN salaries AS c ON b.emp_no = c.emp_no WHERE b.emp_no NOT IN (SELECT emp_no FROM dept_manager) AND c.to_date = '9999-01-01'
思路:
多表关联的问题,使用了一个子查询,就是表有点多,题目没有难度。
第25题:
题目:
获取员工其当前的薪水比其manager当前薪水还高的相关信息,当前表示to_date='9999-01-01',
结果第一列给出员工的emp_no,
第二列给出其manager的manager_no,
第三列给出该员工当前的薪水emp_salary,
第四列给该员工对应的manager当前的薪水manager_salary
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL,
`emp_no` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));

程序:
SELECT a.emp_no,b.manager_no,a.emp_salary,b.manager_salary
from (
select de.emp_no,de.dept_no,s1.salary as emp_salary
from dept_emp de,salaries s1
where de.emp_no=s1.emp_no
and s1.to_date='9999-01-01'
and de.to_date='9999-01-01'
)as a
inner join(
select dm.emp_no as manager_no,dm.dept_no,s2.salary as manager_salary
from dept_manager dm,salaries s2
where dm.emp_no=s2.emp_no
and s2.to_date='9999-01-01'
and dm.to_date='9999-01-01'
)as b
on a.dept_no=b.dept_no
where b.manager_salary<a.emp_salary
思路:
与第21题类似,需要创建两个临时表。一个用来寻找员工的薪水情况,一个用来寻找管理者的薪水情况。
第26题:
题目:
CREATE TABLE `departments` (
`dept_no` char(4) NOT NULL,
`dept_name` varchar(40) NOT NULL,
PRIMARY KEY (`dept_no`));
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE IF NOT EXISTS `titles` (
`emp_no` int(11) NOT NULL,
`title` varchar(50) NOT NULL,
`from_date` date NOT NULL,
`to_date` date DEFAULT NULL);
程序:
SELECT d.dept_no, d.dept_name, t.title, COUNT(*) AS count FROM dept_emp de INNER JOIN departments d ON de.dept_no = d.dept_no INNER JOIN titles t ON de.emp_no=t.emp_no WHERE de.to_date = '9999-01-01' AND t.to_date = '9999-01-01' GROUP BY d.dept_no, d.dept_name, t.title
思路:
思路较简单,多个表的关联,注意条件就行。
第27题:
题目:
给出每个员工每年薪水涨幅超过5000的员工编号emp_no、薪水变更开始日期from_date以及薪水涨幅值salary_growth,并按照salary_growth逆序排列。
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
INSERT INTO salaries VALUES(10001,52117,'1986-06-26','1987-06-26');
INSERT INTO salaries VALUES(10001,62102,'1987-06-26','1988-06-25');
INSERT INTO salaries VALUES(10002,72527,'1996-08-03','1997-08-03');
INSERT INTO salaries VALUES(10002,72527,'1997-08-03','1998-08-03');
INSERT INTO salaries VALUES(10002,72527,'1998-08-03','1999-08-03');
INSERT INTO salaries VALUES(10003,43616,'1996-12-02','1997-12-02');
INSERT INTO salaries VALUES(10003,43466,'1997-12-02','1998-12-02');

程序:
SELECT s2.emp_no, s2.from_date, (s2.salary - s1.salary) AS salary_growth FROM salaries AS s1 INNER JOIN salaries AS s2 ON s1.emp_no = s2.emp_no WHERE s1.to_date = s2.from_date AND s2.salary - s1.salary > 5000 ORDER BY salary_growth DESC
思路:
这道题有些意思,单表来计算差值,在没有明显可以直接使用的字段的情况下只能将一个表来用两次,自关联,在题目中有提示,将一个表的from_date与另一个表的to_date相等,可以表明一条薪水是发薪起始日,另一条为发薪截止日。
第27题:
题目:
INSERT INTO film VALUES(1,'ACADEMY DINOSAUR','A Epic Drama of a Feminist And a Mad Scientist who must Battle a Teacher in The Canadian Rockies');
INSERT INTO film VALUES(2,'ACE GOLDFINGER','A Astounding
Epistle of a Database Administrator And a Explorer who must Find a Car
in Ancient China');
INSERT INTO film VALUES(3,'ADAPTATION HOLES','A
Astounding Reflection of a Lumberjack And a Car who must Sink a
Lumberjack in A Baloon Factory');
INSERT INTO film VALUES(4,'AFFAIR
PREJUDICE','A Fanciful Documentary of a Frisbee And a Lumberjack who
must Chase a Monkey in A Shark Tank');
INSERT INTO film
VALUES(5,'AFRICAN EGG','A Fast-Paced Documentary of a Pastry Chef And a
Dentist who must Pursue a Forensic Psychologist in The Gulf of Mexico');
INSERT INTO film VALUES(6,'AGENT TRUMAN','A Intrepid Panorama of a
robot And a Boy who must Escape a Sumo Wrestler in Ancient China');
INSERT INTO film VALUES(7,'AIRPLANE SIERRA','A Touching Saga of a Hunter
And a Butler who must Discover a Butler in A Jet Boat');
INSERT INTO film VALUES(8,'AIRPORT POLLOCK','A Epic Tale of a Moose And a Girl who must Confront a Monkey in Ancient India');
INSERT INTO film VALUES(9,'ALABAMA DEVIL','A Thoughtful Panorama of a
Database Administrator And a Mad Scientist who must Outgun a Mad
Scientist in A Jet Boat');
INSERT INTO film VALUES(10,'ALADDIN
CALENDAR','A Action-Packed Tale of a Man And a Lumberjack who must Reach
a Feminist in Ancient China');
INSERT INTO category VALUES(1,'Action','2006-02-14 20:46:27');
INSERT INTO category VALUES(2,'Animation','2006-02-14 20:46:27');
INSERT INTO category VALUES(3,'Children','2006-02-14 20:46:27');
INSERT INTO category VALUES(4,'Classics','2006-02-14 20:46:27');
INSERT INTO category VALUES(5,'Comedy','2006-02-14 20:46:27');
INSERT INTO category VALUES(6,'Documentary','2006-02-14 20:46:27');
INSERT INTO category VALUES(7,'Drama','2006-02-14 20:46:27');
INSERT INTO category VALUES(8,'Family','2006-02-14 20:46:27');
INSERT INTO category VALUES(9,'Foreign','2006-02-14 20:46:27');
INSERT INTO category VALUES(10,'Games','2006-02-14 20:46:27');
INSERT INTO category VALUES(11,'Horror','2006-02-14 20:46:27');
INSERT INTO category VALUES(12,'Music','2006-02-14 20:46:27');
INSERT INTO category VALUES(13,'New','2006-02-14 20:46:27');
INSERT INTO category VALUES(14,'Sci-Fi','2006-02-14 20:46:27');
INSERT INTO category VALUES(15,'Sports','2006-02-14 20:46:27');
INSERT INTO category VALUES(16,'Travel','2006-02-14 20:46:27');
INSERT INTO film_category VALUES(1,6,'2006-02-14 21:07:09');
INSERT INTO film_category VALUES(2,11,'2006-02-14 21:07:09');
INSERT INTO film_category VALUES(3,6,'2006-02-14 21:07:09');
INSERT INTO film_category VALUES(4,11,'2006-02-14 21:07:09');
INSERT INTO film_category VALUES(5,6,'2006-02-14 21:07:09');
INSERT INTO film_category VALUES(6,6,'2006-02-14 21:07:09');
INSERT INTO film_category VALUES(7,5,'2006-02-14 21:07:09');
INSERT INTO film_category VALUES(8,6,'2006-02-14 21:07:09');
INSERT INTO film_category VALUES(9,11,'2006-02-14 21:07:09');
INSERT INTO film_category VALUES(10,15,'2006-02-14 21:07:09');




程序:
SELECT c.name,COUNT(f.film_id) FROM film f JOIN film_category fc ON f.film_id = fc.film_id JOIN category c on fc.category_id = c.category_id WHERE f.description like '%robot%' AND fc.category_id=(SELECT category_id FROM film_category GROUP BY category_id HAVING COUNT(*)>=5) GROUP BY c.name
思路:
使用了一个子查询,注意在使用COUNT时,不能放到WHERE里,这时需要使用HAVING。
第28题:
题目:
INSERT INTO film VALUES(1,'ACADEMY DINOSAUR','A Epic Drama of a Feminist And a Mad Scientist who must Battle a Teacher in The Canadian Rockies');
INSERT INTO film VALUES(2,'ACE GOLDFINGER','A Astounding
Epistle of a Database Administrator And a Explorer who must Find a Car
in Ancient China');
INSERT INTO film VALUES(3,'ADAPTATION HOLES','A
Astounding Reflection of a Lumberjack And a Car who must Sink a
Lumberjack in A Baloon Factory');
INSERT INTO category VALUES(1,'Action','2006-02-14 20:46:27');
INSERT INTO category VALUES(2,'Animation','2006-02-14 20:46:27');
INSERT INTO category VALUES(3,'Children','2006-02-14 20:46:27');
INSERT INTO category VALUES(4,'Classics','2006-02-14 20:46:27');
INSERT INTO category VALUES(5,'Comedy','2006-02-14 20:46:27');
INSERT INTO category VALUES(6,'Documentary','2006-02-14 20:46:27');
INSERT INTO category VALUES(7,'Drama','2006-02-14 20:46:27');
INSERT INTO category VALUES(8,'Family','2006-02-14 20:46:27');
INSERT INTO category VALUES(9,'Foreign','2006-02-14 20:46:27');
INSERT INTO category VALUES(10,'Games','2006-02-14 20:46:27');
INSERT INTO category VALUES(11,'Horror','2006-02-14 20:46:27');
INSERT INTO film_category VALUES(1,6,'2006-02-14 21:07:09');
INSERT INTO film_category VALUES(2,11,'2006-02-14 21:07:09');




程序:
SELECT a.film_id, a.title FROM film as a LEFT JOIN film_category as b ON a.film_id = b.film_id WHERE b.film_id IS NULL
思路:
使用left extract join的思想,需要注意所需要的表,这个题目里不是所有表都需要用到。
第29题:
题目:
INSERT INTO film VALUES(1,'ACADEMY DINOSAUR','A Epic Drama of a
Feminist And a Mad Scientist who must Battle a Teacher in The Canadian
Rockies');
INSERT INTO film VALUES(2,'ACE GOLDFINGER','A Astounding
Epistle of a Database Administrator And a Explorer who must Find a Car
in Ancient China');
INSERT INTO film VALUES(3,'ADAPTATION HOLES','A
Astounding Reflection of a Lumberjack And a Car who must Sink a
Lumberjack in A Baloon Factory');
INSERT INTO category VALUES(1,'Action','2006-02-14 20:46:27');
INSERT INTO category VALUES(2,'Animation','2006-02-14 20:46:27');
INSERT INTO category VALUES(3,'Children','2006-02-14 20:46:27');
INSERT INTO category VALUES(4,'Classics','2006-02-14 20:46:27');
INSERT INTO category VALUES(5,'Comedy','2006-02-14 20:46:27');
INSERT INTO category VALUES(6,'Documentary','2006-02-14 20:46:27');
INSERT INTO film_category VALUES(1,1,'2006-02-14 21:07:09');
INSERT INTO film_category VALUES(2,1,'2006-02-14 21:07:09');
INSERT INTO film_category VALUES(3,6,'2006-02-14 21:07:09');
表结构同上

程序:
SELECT a.title, a.description FROM film AS a, category AS b, film_category AS c WHERE a.film_id = c.film_id AND c.category_id = b.category_id AND b.name = 'Action'
思路:
题目较简单。
第30题:
题目:
CREATE TABLE `employees` ( `emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
程序:
SELECT last_name || ' ' || first_name AS Name FROM employees
思路:
sqlite使用的是'||'来进行连接,有一些sql可以使用CONCAT()函数。
第31题:
题目:
创建一个actor表,包含如下列信息(注:sqlite获取系统默认时间是datetime('now','localtime'))

程序:
CREATE TABLE IF NOT EXISTS actor
(
actor_id smallint(5) NOT NULL,
first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL,
last_update timestamp NOT NULL DEFAULT(datetime('now','localtime')),
PRIMARY KEY(actor_id)
)
思路:
需要注意的点是默认值的处理。
第32题:
题目:
对于表actor批量插入如下数据(不能有2条insert语句哦!)
CREATE TABLE IF NOT EXISTS actor (
actor_id smallint(5) NOT NULL PRIMARY KEY,
first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL,
last_update timestamp NOT NULL DEFAULT (datetime('now','localtime')))

程序:
INSERT INTO actor
VALUES ('1','PENELOPE','GUINESS','2006-02-15 12:34:33'),
('2','NICK','WAHLBERG','2006-02-15 12:34:33')
思路:
题目中不允许使用两条INSERT语句,使用VALUES。
第33题:
题目:
对于表actor批量插入如下数据,如果数据已经存在,请忽略(不支持使用replace操作)
CREATE TABLE IF NOT EXISTS actor (
actor_id smallint(5) NOT NULL PRIMARY KEY,
first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL,
last_update timestamp NOT NULL DEFAULT (datetime('now','localtime')))

程序:
INSERT OR IGNORE INTO actor
VALUES ('3','ED','CHASE','2006-02-15 12:34:33')
思路:
不允许使用repalce函数,使用insert or ignore来解决。
第34题:
题目:
对于如下表actor,其对应的数据为:
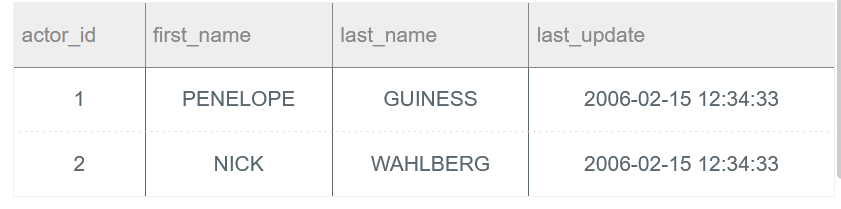

程序:
CREATE TABLE IF NOT EXISTS actor_name AS SELECT first_name, last_name FROM actor
思路:
思路较简单。
第35题:
题目:
actor_id smallint(5) NOT NULL PRIMARY KEY,
first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL,
last_update timestamp NOT NULL DEFAULT (datetime('now','localtime')))
CREATE UNIQUE INDEX uniq_idx_firstname ON actor(first_name); CREATE INDEX idx_lastname ON actor(last_name);
思路:
思路较简单。
第36题:
题目:
针对actor表创建视图actor_name_view,只包含first_name以及last_name两列,并对这两列重新命名,first_name为first_name_v,last_name修改为last_name_v:
CREATE TABLE IF NOT EXISTS actor (
actor_id smallint(5) NOT NULL PRIMARY KEY,
first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL,
last_update timestamp NOT NULL DEFAULT (datetime('now','localtime')))
程序:
CREATE VIEW actor_name_view(first_name_v, last_name_v) AS SELECT first_name, last_name FROM actor
思路:
创建视图的思路较简单。
第37题:
题目:
针对salaries表emp_no字段创建索引idx_emp_no,查询emp_no为10005, 使用强制索引。
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
create index idx_emp_no on salaries(emp_no);
程序:
SELECT * FROM salaries INDEXED BY idx_emp_no WHERE emp_no = 10005;
思路:
思路较简单。
第38题:
题目:
存在actor表,包含如下列信息:
CREATE TABLE IF NOT EXISTS actor (
actor_id smallint(5) NOT NULL PRIMARY KEY,
first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL,
last_update timestamp NOT NULL DEFAULT (datetime('now','localtime')));
现在在last_update后面新增加一列名字为create_date, 类型为datetime, NOT NULL,默认值为'0000-00-00 00:00:00'
程序:
ALTER TABLE actor
ADD create_date datetime NOT NULL DEFAULT('0000-00-00 00:00:00')
思路:
修改表增加列的应用。
第39题:
题目:
构造一个触发器audit_log,在向employees_test表中插入一条数据的时候,触发插入相关的数据到audit中。
CREATE TABLE employees_test(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);
CREATE TABLE audit(
EMP_no INT NOT NULL,
NAME TEXT NOT NULL
);
程序:
CREATE TRIGGER AFTER INSERT ON employees_test BEGIN INSERT INTO audit VALUES (NEW.ID, NEW.NAME); END;
思路:
触发器的设计。
第40题:
题目:
删除emp_no重复的记录,只保留最小的id对应的记录。
CREATE TABLE IF NOT EXISTS titles_test (
id int(11) not null primary key,
emp_no int(11) NOT NULL,
title varchar(50) NOT NULL,
from_date date NOT NULL,
to_date date DEFAULT NULL);
insert into titles_test values ('1', '10001', 'Senior Engineer', '1986-06-26', '9999-01-01'),
('2', '10002', 'Staff', '1996-08-03', '9999-01-01'),
('3', '10003', 'Senior Engineer', '1995-12-03', '9999-01-01'),
('4', '10004', 'Senior Engineer', '1995-12-03', '9999-01-01'),
('5', '10001', 'Senior Engineer', '1986-06-26', '9999-01-01'),
('6', '10002', 'Staff', '1996-08-03', '9999-01-01'),
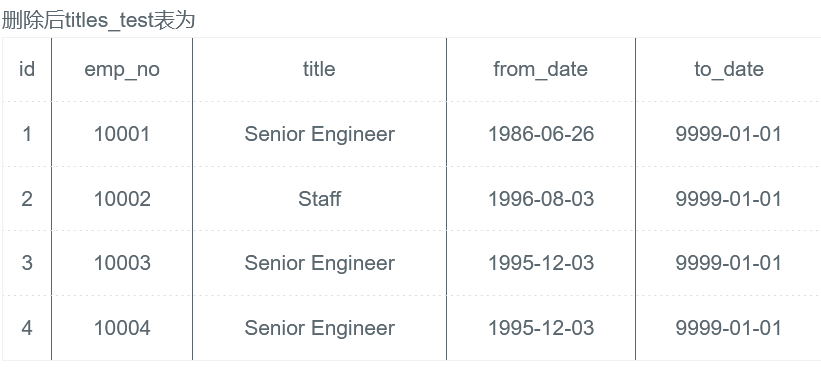
程序:
DELETE FROM titles_test WHERE id NOT IN (SELECT MIN(id) FROM titles_test GROUP BY emp_no);
思路:
删除数据的思路。
第41题:
题目:
将所有to_date为9999-01-01的全部更新为NULL,且 from_date更新为2001-01-01。
CREATE TABLE IF NOT EXISTS titles_test (
id int(11) not null primary key,
emp_no int(11) NOT NULL,
title varchar(50) NOT NULL,
from_date date NOT NULL,
to_date date DEFAULT NULL);
insert into titles_test values ('1', '10001', 'Senior Engineer', '1986-06-26', '9999-01-01'),
('2', '10002', 'Staff', '1996-08-03', '9999-01-01'),
('3', '10003', 'Senior Engineer', '1995-12-03', '9999-01-01'),
('4', '10004', 'Senior Engineer', '1995-12-03', '9999-01-01'),
('5', '10001', 'Senior Engineer', '1986-06-26', '9999-01-01'),
('6', '10002', 'Staff', '1996-08-03', '9999-01-01'),
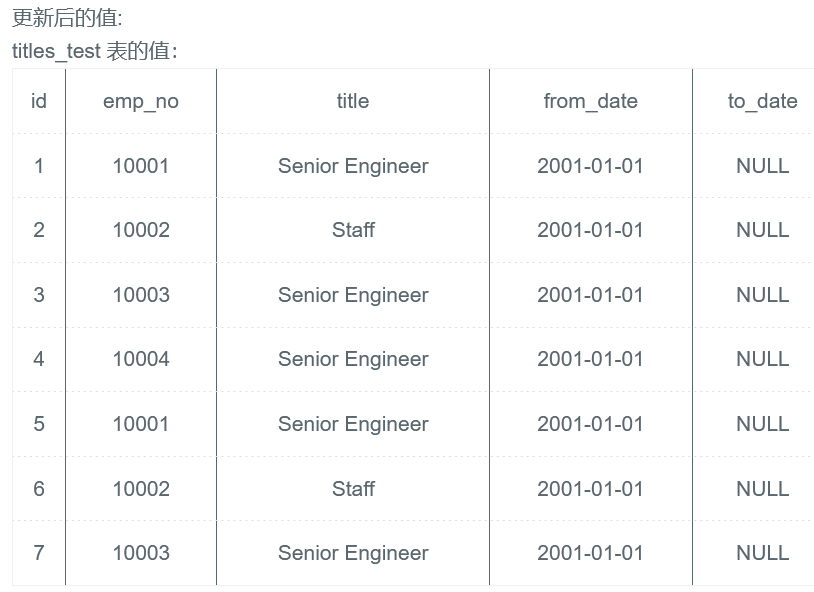
程序:
UPDATE titles_test SET to_date = NULL, from_date = '2001-01-01' WHERE to_date = '9999-01-01'
思路:
更新表。
第42题:
题目:
将id=5以及emp_no=10001的行数据替换成id=5以及emp_no=10005,其他数据保持不变,使用replace实现。
CREATE TABLE IF NOT EXISTS titles_test (
id int(11) not null primary key,
emp_no int(11) NOT NULL,
title varchar(50) NOT NULL,
from_date date NOT NULL,
to_date date DEFAULT NULL);
insert into titles_test values ('1', '10001', 'Senior Engineer', '1986-06-26', '9999-01-01'),
('2', '10002', 'Staff', '1996-08-03', '9999-01-01'),
('3', '10003', 'Senior Engineer', '1995-12-03', '9999-01-01'),
('4', '10004', 'Senior Engineer', '1995-12-03', '9999-01-01'),
('5', '10001', 'Senior Engineer', '1986-06-26', '9999-01-01'),
('6', '10002', 'Staff', '1996-08-03', '9999-01-01'),
('7', '10003', 'Senior Engineer', '1995-12-03', '9999-01-01');
程序:
UPDATE titles_test SET emp_no = REPLACE(emp_no, '10001', '10005') WHERE id = 5;
思路:
使用repalce函数更新数据表。
第43题:
题目:
将titles_test表名修改为titles_2017。
CREATE TABLE IF NOT EXISTS titles_test (
id int(11) not null primary key,
emp_no int(11) NOT NULL,
title varchar(50) NOT NULL,
from_date date NOT NULL,
to_date date DEFAULT NULL);
insert into titles_test values ('1', '10001', 'Senior Engineer', '1986-06-26', '9999-01-01'),
('2', '10002', 'Staff', '1996-08-03', '9999-01-01'),
('3', '10003', 'Senior Engineer', '1995-12-03', '9999-01-01'),
('4', '10004', 'Senior Engineer', '1995-12-03', '9999-01-01'),
('5', '10001', 'Senior Engineer', '1986-06-26', '9999-01-01'),
('6', '10002', 'Staff', '1996-08-03', '9999-01-01'),
('7', '10003', 'Senior Engineer', '1995-12-03', '9999-01-01');
程序:
ALTER TABLE titles_test RENAME TO titles_2017;
思路:
更新数据表的名称。
第44题:
题目:
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);
CREATE TABLE audit(
EMP_no INT NOT NULL,
create_date datetime NOT NULL
程序:
DROP TABLE IF EXISTS audit;
CREATE TABLE IF NOT EXISTS audit
(
EMP_no INT NOT NULL,
create_date datetime NOT NULL,
FOREIGN KEY(EMP_no) REFERENCES employees_test(ID)
);
思路:
创建外键约束的思路。
第45题:
题目:
请你写出更新语句,将所有获取奖金的员工当前的(salaries.to_date='9999-01-01')薪水增加10%。(emp_bonus里面的emp_no都是当前获奖的所有员工)
create table emp_bonus(
emp_no int not null,
btype smallint not null);
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
INSERT INTO salaries VALUES(10001,85097,'2001-06-22','2002-06-22');
INSERT INTO salaries VALUES(10001,88958,'2002-06-22','9999-01-01');

程序:
UPDATE salaries SET salary = salary * 1.1 WHERE salaries.to_date = '9999-01-01' AND salaries.emp_no IN (SElECT emp_no FROM emp_bonus);
思路:
更新数据表的操作。
第46题:
题目:
emp_bonus

程序:
SELECT 'select count(*) from' || name || ';' AS cnts FROM sqlite_master WHERE type = 'table';
思路:
正确使用连接就好。
第47题:
将employees表中的所有员工的last_name和first_name通过(')连接起来。(sqlite不支持concat,请用||实现,mysql支持concat)
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
输出格式:

程序:
SELECT last_name || "'" || first_name AS name FROM employees;
思路:
思路较简单。
第48题:
题目:
查找字符串'10,A,B' 中逗号','出现的次数cnt。
程序:
SELECT (LENGTH('10,A,B') - LENGTH(REPLACE('10,A,B',',',''))) AS cnt;
思路:
巧用replace函数来实现。
第49题:
题目:
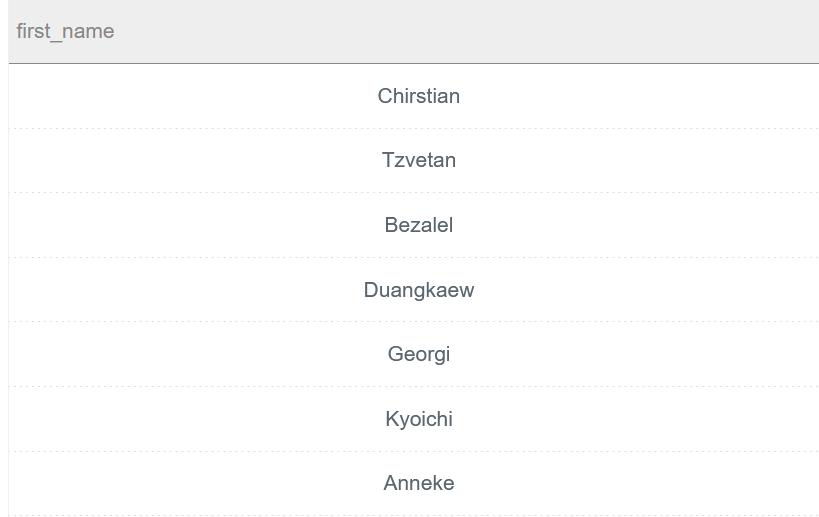
获取Employees中的first_name,查询按照first_name最后两个字母,按照升序进行排列
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
输出格式:
程序:
SELECT first_name FROM employees ORDER BY SUBSTR(first_name, -2) ASC;
思路:
使用SUBSTR函数,最后两个字母使用SUBSTR(XXXX,-2)来实现。
第50题:
题目:
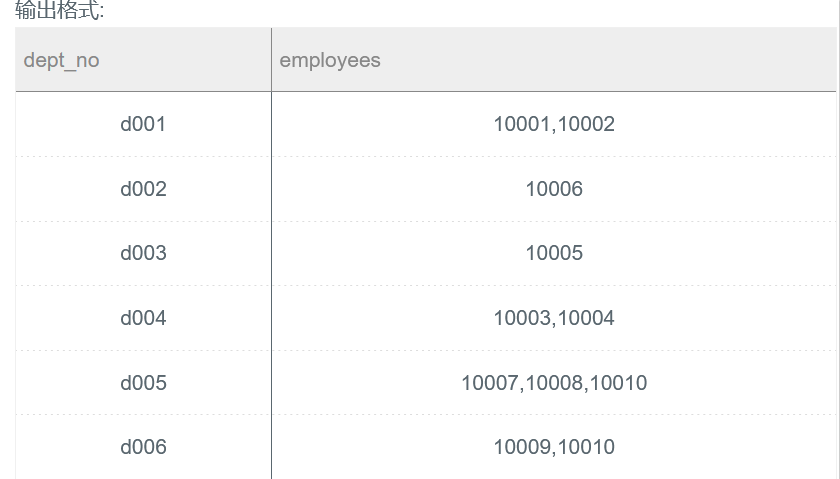
按照dept_no进行汇总,属于同一个部门的emp_no按照逗号进行连接,结果给出dept_no以及连接出的结果employees
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
程序:
SELECT dept_no,group_concat(emp_no,',') AS employees FROM dept_emp GROUP BY dept_no;
思路:
这种情况下使用group_concat()函数。
第51题:
题目:
查找排除最大、最小salary之后的当前(to_date = '9999-01-01' )员工的平均工资avg_salary。
CREATE TABLE `salaries` ( `emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
INSERT INTO salaries VALUES(10001,88958,'2002-06-22','9999-01-01');
INSERT INTO salaries VALUES(10002,72527,'2001-08-02','9999-01-01');
INSERT INTO salaries VALUES(10003,43699,'2000-12-01','2001-12-01');
INSERT INTO salaries VALUES(10003,43311,'2001-12-01','9999-01-01');
INSERT INTO salaries VALUES(10004,70698,'2000-11-27','2001-11-27');
INSERT INTO salaries VALUES(10004,74057,'2001-11-27','9999-01-01');

程序:
SELECT AVG(salary) AS avg_salary FROM salaries WHERE salary != (SELECT MAX(salary) FROM salaries WHERE to_date = '9999-01-01') AND salary != (SELECT MIN(salary) FROM salaries WHERE to_date = '9999-01-01') AND to_date = '9999-01-01';
思路:
多次使用子查询。
第52题:
题目:
分页查询employees表,每5行一页,返回第2页的数据
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
程序:
SELECT * FROM employees LIMIT 5,5;
思路:
使用LIMIT和OFFSET来实现。
第53题:
题目:
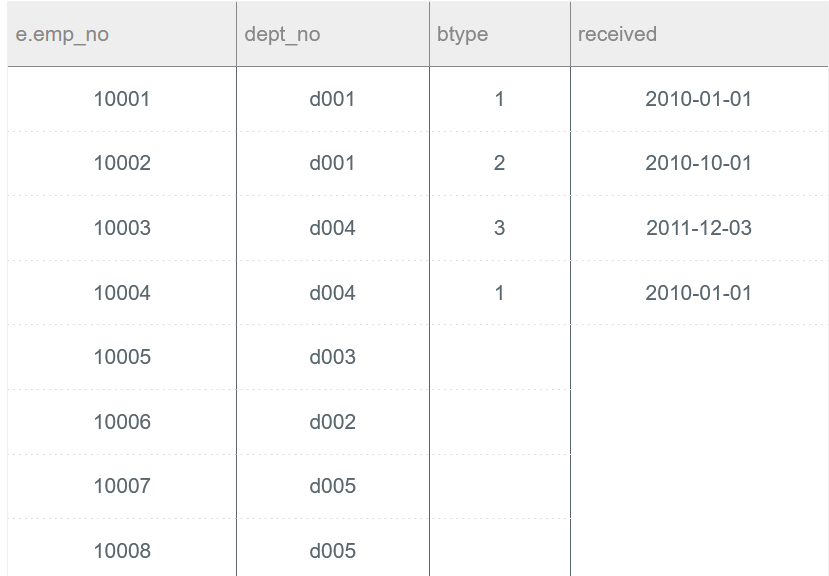
获取所有员工的emp_no、部门编号dept_no以及对应的bonus类型btype和received,没有分配奖金的员工不显示对应的bonus类型btype和received
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
emp_no int(11) NOT NULL,
received datetime NOT NULL,
btype smallint(5) NOT NULL);
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
程序:
SELECT de.emp_no, de.dept_no, eb.btype, eb.received FROM dept_emp AS de LEFT JOIN emp_bonus AS eb ON de.emp_no = eb.emp_no WHERE de.emp_no IN (SELECT e.emp_no FROM employees AS e);
思路:
使用left join和子查询。
第54题:
题目:
使用含有关键字exists查找未分配具体部门的员工的所有信息。
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
输出格式:

程序:
SELECT *
FROM employees
WHERE NOT EXISTS (SELECT emp_no
FROM dept_emp
WHERE employees.emp_no = dept_emp.emp_no);
思路:
在exists关键字中来选择既定的条件。
第55题:
题目:
获取有奖金的员工相关信息。
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
create table emp_bonus(
emp_no int not null,
received datetime not null,
btype smallint not null);
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL, PRIMARY KEY (`emp_no`,`from_date`));
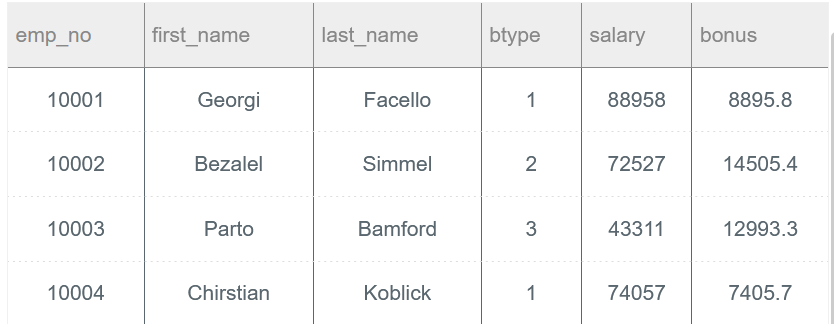
给出emp_no、first_name、last_name、奖金类型btype、对应的当前薪水情况salary以及奖金金额bonus。
bonus类型btype为1其奖金为薪水salary的10%,btype为2其奖金为薪水的20%,其他类型均为薪水的30%。
当前薪水表示to_date='9999-01-01'
输出格式:
程序:
SELECT e.emp_no, e.first_name, e.last_name, b.btype, s.salary, (CASE b.btype WHEN 1 THEN s.salary * 0.1 WHEN 2 THEN s.salary * 0.2 ELSE s.salary * 0.3 END) as bonus FROM employees AS e INNER JOIN emp_bonus AS b ON e.emp_no = b.emp_no INNER JOIN salaries AS s ON e.emp_no = s.emp_no WHERE s.to_date = '9999-01-01';
思路:
这道题的重点是使用CASE...WHEN...ELSE来进行判断。
第56题:
题目:
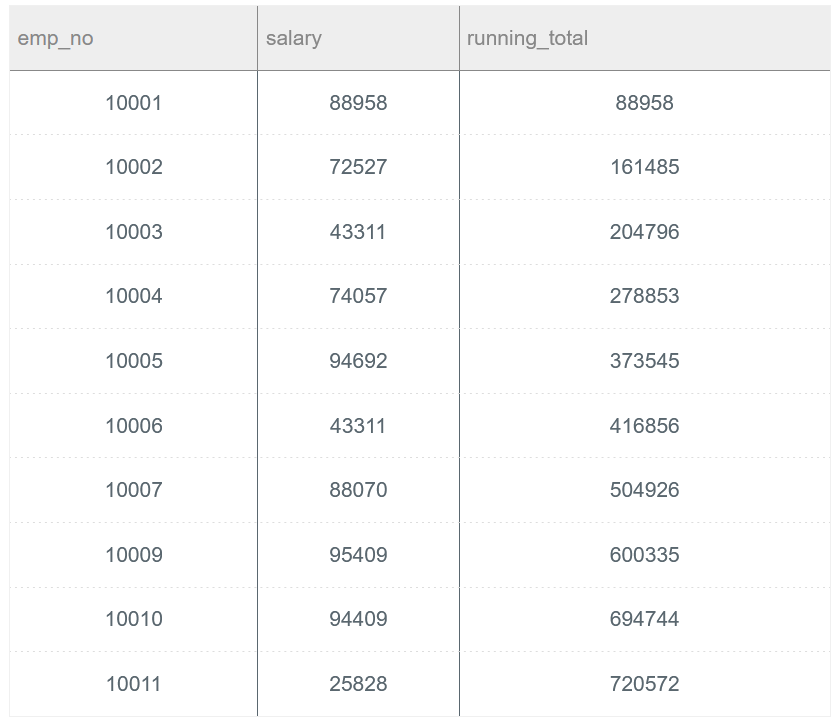
按照salary的累计和running_total,其中running_total为前N个当前( to_date = '9999-01-01')员工的salary累计和,其他以此类推。 具体结果如下Demo展示。。
CREATE TABLE `salaries` ( `emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
输出格式:
程序1:
SELECT a.emp_no, a.salary, (SELECT SUM(b.salary) FROM salaries AS b WHERE b.emp_no <= a.emp_no AND b.to_date = '9999-01-01') AS running_total FROM salaries AS a WHERE a.to_date = '9999-01-01' ORDER BY a.emp_no ASC;
程序2:
SELECT emp_no,salary, SUM(salary) OVER (ORDER BY emp_no) AS running_total FROM salaries WHERE to_date = '9999-01-01';
思路:
遇到这种类似排列求和的问题,第一个思路如程序1所示就是复用一下salaries,使用复用的salaries表进行子查询。第二个思路就是使用窗口函数来实现,使用SUM() OVER()可以实现这个问题。
第57题:
题目:
对于employees表中,输出first_name排名(按first_name升序排序)为奇数的first_name
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12');
INSERT INTO employees VALUES(10006,'1953-04-20','Anneke','Preusig','F','1989-06-02');
输出格式:

程序1:
SELECT a.first_name FROM employees AS a WHERE (SELECT COUNT(*) FROM employees AS b WHERE b.first_name <= a.first_name) % 2 = 1;
程序2:
SELECT a.first_name FROM employees a JOIN ( SELECT first_name, ROW_NUMBER() OVER(ORDER BY first_name ASC) AS r_num FROM employees ) AS t ON a.first_name = t.first_name WHERE t.r_num % 2 = 1;
思路:
思路和56题类似,对于这种涉及到排序的问题,要想到使用表的复用和窗口函数,配合上合理的条件判断就可以完成了。
第58 题:
题目:
在牛客刷题的小伙伴们都有着牛客积分,积分(grade)表简化可以如下:

id为用户主键id,number代表积分情况,让你写一个sql查询,积分表里面出现三次以及三次以上的积分,查询结果如下:

SELECT number FROM grade GROUP BY number HAVING COUNT(number) >= 3;
思路:
使用GROUP BY和COUNT()函数就可以了。
第59题:
题目:

第1行表示id为1的用户通过了4个题目;
.....
第6行表示id为6的用户通过了4个题目;
请你根据上表,输出通过的题目的排名,通过题目个数相同的,排名相同,此时按照id升序排列,数据如下:

id为5的用户通过了5个排名第1,
id为1和id为6的都通过了2个,并列第2
程序:
SELECT id, number, DENSE_RANK() OVER(ORDER BY number DESC) AS t_rank FROM passing_number ORDER BY number DESC, id ASC;
思路:
对于排序问题,如果要求的是排序结果连续,则使用DENSE_RANK() OVER()来实现。
第60题:
题目:


请你找到每个人的任务情况,并且输出出来,没有任务的也要输出,而且输出结果按照person的id升序排序,输出情况如下:

程序:
SELECT a.id, a.name, b.content FROM person AS a LEFT JOIN task AS b ON a.id = b.person_id ORDER BY a.id ASC;
思路:
题目较简单,根据题意需要使用LEFT JOIN。
第61题:
题目:
现在有一个需求,让你统计正常用户发送给正常用户邮件失败的概率:
有一个邮件(email)表,id为主键, type是枚举类型,枚举成员为(completed,no_completed),completed代表邮件发送是成功的,no_completed代表邮件是发送失败的。简况如下:
第1行表示为id为2的用户在2020-01-11成功发送了一封邮件给了id为3的用户;
...
第3行表示为id为1的用户在2020-01-11没有成功发送一封邮件给了id为4的用户;
...
第6行表示为id为4的用户在2020-01-12成功发送了一封邮件给了id为1的用户;
下面是一个用户(user)表,id为主键,is_blacklist为0代表为正常用户,is_blacklist为1代表为黑名单用户,简况如下:
第1行表示id为1的是正常用户;
第2行表示id为2的不是正常用户,是黑名单用户,如果发送大量邮件或者出现各种情况就会容易发送邮件失败的用户
。。。
第4行表示id为4的是正常用户



2020-01-12没有失败的情况,所以概率为0.000.
(注意: sqlite 1/2得到的不是0.5,得到的是0,只有1*1.0/2才会得到0.5,sqlite四舍五入的函数为round)
程序:
SELECT e.date AS a, ROUND(SUM(CASE e.type WHEN 'no_completed' then 1 ELSE 0 END) * 1.0 / COUNT(e.type),3) FROM email AS e INNER JOIN user AS u1 ON (e.send_id = u1.id AND u1.is_blacklist = 0) INNER JOIN user AS u2 ON (e.receive_id = u2.id AND u2.is_blacklist = 0) GROUP BY e.date ORDER BY a;
思路:
题目涉及到计算要设计一下。
第62题:
题目:
牛客每天有很多人登录,请你统计一下牛客每个用户最近登录是哪一天。

第1行表示id为2的用户在2020-10-12使用了客户端id为1的设备登录了牛客网
。。。
第4行表示id为3的用户在2020-10-13使用了客户端id为2的设备登录了牛客网
请你写出一个sql语句查询每个用户最近一天登录的日子,并且按照user_id升序排序,上面的例子查询结果如下:
查询结果表明:
user_id为2的最近的登录日期在2020-10-13
user_id为3的最近的登录日期也是2020-10-13

程序:
SELECT MAX(date) FROM login GROUP BY user_id ORDER BY user_id ASC;
思路:
题目较简单。
第63题:
题目:
牛客每天有很多人登录,请你统计一下牛客每个用户最近登录是哪一天,用的是什么设备.

第1行表示id为2的用户在2020-10-12使用了客户端id为1的设备登录了牛客网
。。。
第4行表示id为3的用户在2020-10-13使用了客户端id为2的设备登录了牛客网
还有一个用户(user)表,简况如下:
还有一个客户端(client)表,简况如下:
请你写出一个sql语句查询每个用户最近一天登录的日子,用户的名字,以及用户用的设备的名字,并且查询结果按照user的name升序排序,上面的例子查询结果如下:



查询结果表明:
fh最近的登录日期在2020-10-13,而且是使用pc登录的
wangchao最近的登录日期也是2020-10-13,而且是使用ios登录的
程序:
SELECT u.name AS u_n, c.name AS c_n, MAX(l.date) AS d FROM login AS l INNER JOIN user AS u ON l.user_id = u.id INNER JOIN client AS c ON l.client_id = c.id GROUP BY l.user_id ORDER BY u.name;
思路:
题目较简单。
第64题:
题目:
牛客每天有很多人登录,请你统计一下牛客新登录用户的次日成功的留存率,
有一个登录(login)记录表,简况如下:
第1行表示id为2的用户在2020-10-12使用了客户端id为1的设备第一次新登录了牛客网
。。。

请你写出一个sql语句查询新登录用户次日成功的留存率,即第1天登陆之后,第2天再次登陆的概率,保存小数点后面3位(3位之后的四舍五入),上面的例子查询结果如下:

id为2的用户在2020-10-12第一次新登录了,在2020-10-13又登录了,算是成功的留存
固次日成功的留存率为 2/4=0.5
SELECT ROUND(COUNT(l1.user_id) * 1.0 / COUNT(l2.user_id), 3) AS p FROM (SELECT user_id, min(date) AS date FROM login GROUP BY user_id) AS l2 LEFT JOIN login AS l1 ON l1.user_id = l2.user_id AND l1.date = date(l2.date,'+1 day');
思路:
因为只涉及到两天的数据,并且是一张表,因此对于login做一个复用产生一个临时表,来完成本题。
第65题:
题目:
牛客每天有很多人登录,请你统计一下牛客每个日期登录新用户个数,
有一个登录(login)记录表,简况如下:
第1行表示id为2的用户在2020-10-12使用了客户端id为1的设备登录了牛客网,因为是第1次登录,所以是新用户
。。。
第4行表示id为2的用户在2020-10-13使用了客户端id为2的设备登录了牛客网,因为是第2次登录,所以是老用户
。。
最后1行表示id为4的用户在2020-10-15使用了客户端id为1的设备登录了牛客网,因为是第2次登录,所以是老用户
请你写出一个sql语句查询每个日期登录新用户个数,并且查询结果按照日期升序排序,上面的例子查询结果如下:
查询结果表明:
2020-10-12,有3个新用户(id为2,3,1)登录
2020-10-13,没有新用户登录
2020-10-14,有1个新用户(id为4)登录
2020-10-15,没有新用户登录


程序:
SELECT a.date, SUM(CASE day WHEN 1 THEN 1 ELSE 0 END) FROM (SELECT date, row_number() OVER(PARTITION BY user_id ORDER BY date) AS day FROM login) AS a GROUP BY date;
思路:
这道题参考的网上的答案。使用ROW_NUMBER() OVER()来对每个用户按照登录的时间进行排序,每个用户会得到一个第一次登录的日期,通过这个来计算就好。
第66题:
题目:
牛客每天有很多人登录,请你统计一下牛客每个日期新用户的次日留存率。
有一个登录(login)记录表,简况如下:
第1行表示id为2的用户在2020-10-12使用了客户端id为1的设备登录了牛客网,因为是第1次登录,所以是新用户
。。。
第4行表示id为2的用户在2020-10-13使用了客户端id为2的设备登录了牛客网,因为是第2次登录,所以是老用户
。。
最后1行表示id为4的用户在2020-10-15使用了客户端id为1的设备登录了牛客网,因为是第2次登录,所以是老用户
请你写出一个sql语句查询每个日期新用户的次日留存率,结果保留小数点后面3位数(3位之后的四舍五入),并且查询结果按照日期升序排序,上面的例子查询结果如下:
查询结果表明:
2020-10-12登录了3个(id为2,3,1)新用户,2020-10-13,只有2个(id为2,1)登录,故2020-10-12新用户次日留存率为2/3=0.667;
2020-10-13没有新用户登录,输出0.000;
2020-10-14登录了1个(id为4)新用户,2020-10-15,id为4的用户登录,故2020-10-14新用户次日留存率为1/1=1.000;


(注意:sqlite里查找某一天的后一天的用法是:date(yyyy-mm-dd, '+1 day'),sqlite里1/2得到的不是0.5,得到的是0,只有1*1.0/2才会得到0.5)
程序:
SELECT a.date, ROUND(COUNT(b.user_id) * 1.0/COUNT(a.user_id), 3) AS p
FROM (
SELECT user_id, MIN(date) AS date
FROM login
GROUP BY user_id) a
LEFT JOIN login b
ON a.user_id = b.user_id
AND b.date = date(a.date, '+1 day')
GROUP BY a.date
UNION
SELECT date, 0.000 AS p
FROM login
WHERE date NOT IN (
SELECT MIN(date)
FROM login
GROUP BY user_id)
ORDER BY date;
思路:
和64题的思路很像,增加为0的情况。
第67题:
题目:
牛客每天有很多人登录,请你统计一下牛客每个用户查询刷题信息,包括: 用户的名字,以及截止到某天,累计总共通过了多少题。 不存在没有登录却刷题的情况,但是存在登录了没刷题的情况,不会存在刷题表里面,有提交代码没有通过的情况,但是会记录在刷题表里,只不过通过数目是0。
有一个登录(login)记录表,简况如下:
第1行表示id为2的用户在2020-10-12使用了客户端id为1的设备登录了牛客网
。。。
第5行表示id为3的用户在2020-10-13使用了客户端id为2的设备登录了牛客网
有一个刷题(passing_number)表,简况如下:
第1行表示id为2的用户在2020-10-12通过了4个题目。
。。。
第3行表示id为1的用户在2020-10-13提交了代码但是没有通过任何题目。
第4行表示id为4的用户在2020-10-13通过了2个题目
还有一个用户(user)表,简况如下:




查询结果表明:
fh在2020-10-12为止,总共通过了4道题,输出为4
wangchao在2020-10-12为止,总共通过了1道题,总计为1
tm在2020-10-12为止只登陆了没有刷题,故没有显示出来
tm在2020-10-13为止刷了题,但是却没有通过任何题目,总计为0
wangchao在2020-10-13通过2道,但是加上前面2020-10-12通过1道,故在2020-10-13为止总共通过了3道题,总计为3
程序1:
SELECT u.name AS u_n, p1.date AS date, SUM(p2.number) AS ps_num FROM passing_number AS p1 INNER JOIN passing_number AS p2 ON p1.user_id = p2.user_id AND p2.date <= p1.date INNER JOIN user AS u ON u.id = p1.user_id GROUP BY p1.date, u.name ORDER BY p1.date, u.name;
程序2:
FROM
(
SELECT
user_id,
date,
SUM(number) OVER(partition by user_id order by date) AS ps_num
FROM passing_number) p2
INNER JOIN user ON p2.user_id = user.id
ORDER BY p2.date,user.name;
思路:
涉及到排序求和的一般有两种方法。
第68题:
题目:
牛客每次考试完,都会有一个成绩表(grade),如下:

第1行表示用户id为1的用户选择了C++岗位并且考了11001分
。。。
第8行表示用户id为8的用户选择了前端岗位并且考了9999分
请你写一个sql语句查询各个岗位分数的平均数,并且按照分数降序排序,结果保留小数点后面3位(3位之后四舍五入):

(注意: sqlite 1/2得到的不是0.5,得到的是0,只有1*1.0/2才会得到0.5,sqlite四舍五入的函数为round)
程序:
SELECT job, round(AVG(score), 3) AS avg FROM grade GROUP BY job ORDER BY avg DESC;
思路:
题目较简单。
第69题:
题目:
牛客每次考试完,都会有一个成绩表(grade),如下:

第1行表示用户id为1的用户选择了C++岗位并且考了11001分
。。。
第8行表示用户id为8的用户选择了前端岗位并且考了9999分
请你写一个sql语句查询用户分数大于其所在工作(job)分数的平均分的所有grade的属性,并且以id的升序排序,如下:

(注意: sqlite 1/2得到的不是0.5,得到的是0,只有1*1.0/2才会得到0.5,sqlite四舍五入的函数为round)
程序1:
SELECT a.id, a.job, a.score FROM grade AS a WHERE a.score > (SELECT AVG(b.score) FROM grade AS b WHERE a.job = b.job GROUP BY b.job) ORDER BY a.id;
程序2:
SELECT id,job,score FROM(
SELECT id,job,score,AVG(score) OVER (partition by job) AS avg_score
FROM grade) a
WHERE score > a.avg_score
ORDER BY id
思路:
两种思路,使用表的复用和窗口函数。
第70题:
题目:

第1行表示用户id为1的选择了language_id为1岗位的最后考试完的分数为12000,
....
第7行表示用户id为7的选择了language_id为2岗位的最后考试完的分数为11000,
不同的语言岗位(language)表简化如下:

请你找出每个岗位分数排名前2的用户,得到的结果先按照language的name升序排序,再按照积分降序排序,最后按照grade的id升序排序,得到结果如下:

程序:
SELECT id ,name,score FROM (select g.id,l.name,g.score,dense_rank() over(partition by g.language_id order by g.score desc) as rank FROM grade g INNER JOIN language l ON g.language_id=l.id) WHERE rank<=2 ORDER BY name,score DESC,id;
思路:
使用窗口函数来实现。
第71题:
题目:
牛客每次考试完,都会有一个成绩表(grade),如下:

第1行表示用户id为1的用户选择了C++岗位并且考了11001分
。。。
第8行表示用户id为8的用户选择了前端岗位并且考了9999分
请你写一个sql语句查询各个岗位分数升序排列之后的中位数位置的范围,并且按job升序排序,结果如下:

解释:
第1行表示C++岗位的中位数位置范围为[2,2],也就是2。因为C++岗位总共3个人,是奇数,所以中位数位置为2是正确的(即位置为2的10000是中位数)
第2行表示Java岗位的中位数位置范围为[1,2]。因为Java岗位总共2个人,是偶数,所以要知道中位数,需要知道2个位置的数字,而因为只有2个人,所以中位数位置为[1,2]是正确的(即需要知道位置为1的12000与位置为2的13000才能计算出中位数为12500)
第3行表示前端岗位的中位数位置范围为[2,2],也就是2。因为前端岗位总共3个人,是奇数,所以中位数位置为2是正确的(即位置为2的11000是中位数)
(注意: sqlite 1/2得到的不是0.5,得到的是0,只有1*1.0/2才会得到0.5,sqlite四舍五入的函数为round,sqlite不支持floor函数,支持cast(x as integer) 函数,不支持if函数,支持case when ...then ...else ..end函数)
程序:
SELECT job, CASE COUNT(*)%2 WHEN 1 THEN COUNT(*)/2+1 ELSE COUNT(*)/2 END AS s, COUNT(*)/2+1 AS e FROM grade GROUP BY job;
思路:
进行数学分析可以得到结果。
到这里还没有结束,最后一题没有做出来。
此外,在整个过程中出现了题号不对应的现象。
完成了一件事情,纪念一下,2020年11月5日晚23点15分。