Consumer 机制
1 前言
在 Kafka 中,Consumer 的复杂度要比 producer 高出很多,对于 Producer 而言,没有 producer 组的概念的、也不需要 care offset 等问题,而 Consumer 就不一样了,它需要关注的内容很多,需要考虑分布式消费(Consumer Group),为了防止重复消费或者部分数据未消费需要考虑 offset,这些都对 Consumer 的设计以及 Server 对其处理提出了很高的要求。本章介绍一下consumer的机制。
2 使用示例
首先通过一个简单的demo看一下consumer的客户端使用
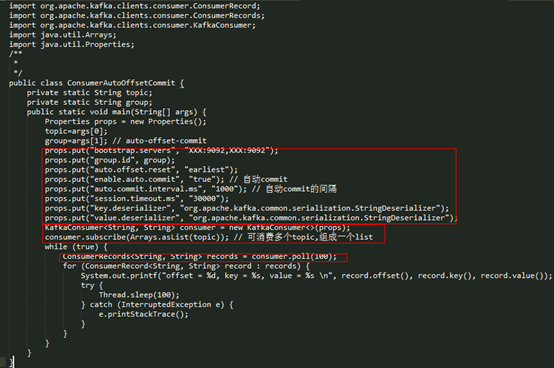
其主要包含一下几个步骤:
- l 构造 Propertity,进行 consumer 相关的配置;
- l 创建 KafkaConsumer 的对象 consumer;
- l 订阅相应的 topic 列表;
- l 调用 consumer 的 poll 方法拉取订阅的消息。
前面两步在 Consumer 底层上只是创建了一个 consumer 对象,第三步只有记录一下订阅的 topic 信息,consumer 实际的操作都是第四步,也就是在 poll 方法中实现的,poll 模型对于理解 consumer 设计非常重要。
3 Consumer 两种订阅模型
在kafka中,正常情况下,同一个group.id下的不同消费者不会消费同样的partition,也即某个partition在任何时刻都只能被具有相同group.id的consumer中的一个消费。 也正是这个机制才能保证kafka的重要特性:
- 1、可以通过增加partitions和consumer来提升吞吐量;
- 2、保证同一份消息不会被消费多次。
在KafkaConsumer类中(官方API),消费者可以通过assign和subscribe两种方式指定要消费的topic-partition。具体的源码可以参考下文,
这两个接口貌似是完成相同的功能,但是还有细微的差别,初次使用的同学可能感到困惑,下面就详细介绍下两者的区别。
在新版的 Consumer 中,subscribe模型现在叫做订阅模式,KafkaConsumer 提供了三种 API,如下:

以上三种 API 都是按照 topic 级别去订阅,可以动态地获取其分配的 topic-partition,这是使用 Group 动态管理,它不能与手动 partition 管理一起使用。当监控到发生下面的事件时,Group 将会触发 rebalance 操作:
- l 订阅的 topic 列表变化;
- l topic 被创建或删除;
- l consumer group 的某个 consumer 实例挂掉;
- l 一个新的 consumer 实例通过 join 方法加入到一个 group 中。
在这种模式下,当 KafkaConsumer 调用 pollOnce 方法时,第一步会首先加入到一个 group 中,并获取其分配的 topic-partition 列表。
这里介绍一下当调用 subscribe() 方法之后,Consumer 所做的事情,分两种情况介绍,一种按 topic 列表订阅,一种是按 pattern 模式订阅:
1.topic 列表订阅
- l 更新 SubscriptionState 中记录的 subscription(记录的是订阅的 topic 列表),将 SubscriptionType 类型设置为 AUTO_TOPICS;
- l 更新 metadata 中的 topic 列表(topics 变量),并请求更新 metadata;
2. pattern 模式订阅
- l 更新 SubscriptionState 中记录的 subscribedPattern,设置为 pattern,将 SubscriptionType 类型设置为 AUTO_PATTERN;
- l 设置 Metadata 的 needMetadataForAllTopics 为 true,即在请求 metadata 时,需要更新所有 topic 的 metadata 信息,设置后再请求更新 metadata;
- l 调用 coordinator.updatePatternSubscription() 方法,遍历所有 topic 的 metadata,找到所有满足 pattern 的 topic 列表,更新到 SubscriptionState 的 subscriptions 和 Metadata 的 topics 中;
- l 通过在 ConsumerCoordinator 中调用 addMetadataListener() 方法在 Metadata 中添加 listener 当每次 metadata update 时就调用第三步的方法更新,但是只有当本地缓存的 topic 列表与现在要订阅的 topic 列表不同时,才会触发 rebalance 操作。
其他部分,两者基本一样,只是 pattern 模型在每次更新 topic-metadata 时,获取全局的 topic 列表,如果发现有新加入的符合条件的 topic,就立马去订阅,其他的地方,包括 Group 管理、topic-partition 的分配都是一样的。
下面来看一下 Consumer 提供的分配模式,当调用 assign() 方法手动分配 topic-partition 列表时,是不会使用 consumer 的 Group 管理机制,也即是当 consumer group member 变化或 topic 的 metadata 信息变化时是不会触发 rebalance 操作的。比如:当 topic 的 partition 增加时,这里是无法感知,需要用户进行相应的处理,Apache Flink 就是使用的这种方式。

如果使用的是 assign 模式,也即是非 AUTO_TOPICS 或 AUTO_PATTERN 模式时,Consumer 实例在调用 poll 方法时,是不会向 GroupCoordinator 发送 join-group/sync-group/heartbeat 请求的,也就是说 GroupCoordinator 是拿不到这个 Consumer 实例的相关信息,也不会去维护这个 member 是否存活,这种情况下就需要用户自己管理自己的处理程序。但是在这种模式是可以进行 offset commit的。
简单做一下总结:
|
模式 |
不同之处 |
相同之处 |
|
subscribe() |
使用 Kafka Group 管理,自动进行 rebalance 操作 |
可以在 Kafka 保存 offset |
|
assign() |
用户自己进行相关的处理 |
也可以进行 offset commit,但是尽量保证 group.id 唯一性,如果使用一个与上面模式一样的 group,offset commit 请求将会被拒绝 |
4 consumer poll 模型

consumer poll 方法主要做了以下几件事情:
- l 检查这个 consumer 是否订阅的相应的 topic-partition;
- l 调用 pollOnce() 方法获取相应的 records;
- l 在返回获取的 records 前,发送下一次的 fetch 请求,避免用户在下次请求时线程 block 在 pollOnce() 方法中;
- l 如果在给定的时间(timeout)内获取不到可用的 records,返回空数据。
其过程可以用下面的伪代码表示:
poll(timeout){
根据poll(timeout)参数,估算剩余时间
while(还有剩余时间)
从Fetcher端拉取消费到的消息
if(消息数量不为空)
创建发送请求
立刻将请求发送
else
return
end //if ends
计算剩余时间
end //while ends
}
这里可以看出,poll 方法的真正实现是在 pollOnce 方法中,poll 方法通过 pollOnce 方法获取可用的数据。
Consumer poll 方法的真正实现是在 pollOnce() 方法中,这里直接看下其源码:
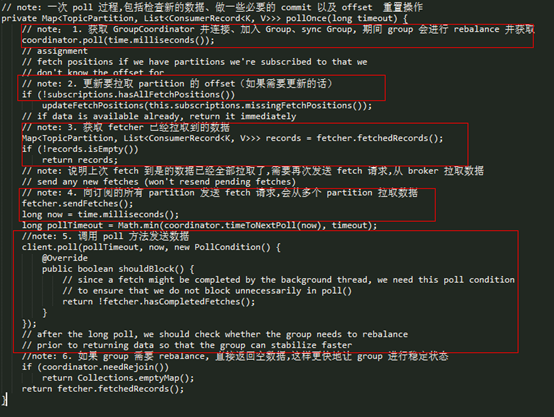
pollOnce 可以简单分为6步来看,其作用分别如下:
- l
coordinator.poll():获取 GroupCoordinator 的地址,并建立相应 tcp 连接,发送 join-group、sync-group,之后才真正加入到了一个 group 中,这时会获取其要消费的 topic-partition 列表,如果设置了自动 commit,也会在这一步进行 commit,总之,对于一个新建的 group,group 状态将会从 Empty –> PreparingRebalance –> AwaiSync –> Stable; - l
updateFetchPositions(): 在上一步中已经获取到了这个 consumer 实例要订阅的 topic-partition list,这一步更新其 fetch-position offset,以便进行拉取; - l
fetcher.sendFetches():返回其 fetched records,并更新其 fetch-position offset,只有在 offset-commit 时(自动 commit 时,是在第一步实现的),才会更新其 committed offset; - l
fetcher.sendFetches():只要订阅的 topic-partition list 没有未处理的 fetch 请求,就发送对这个 topic-partition 的 fetch 请求,在真正发送时,还是会按 node 级别去发送,leader 是同一个 node 的 topic-partition 会合成一个请求去发送; - l
client.poll():调用底层 NetworkClient 提供的接口去发送相应的请求; - l
coordinator.needRejoin():如果当前实例分配的 topic-partition 列表发送了变化,那么这个 consumer group 就需要进行 rebalance。
5 Consumer 加入消费组
这里先简单介绍一下 GroupCoordinator 这个角色,后续有一篇文章进行专门讲述,GroupCoordinator 是运行在 Kafka Broker 上的一个服务,每台 Broker 在运行时都会启动一个这样的服务,但一个 consumer 具体与哪个 Broker 上这个服务交互,就需要先介绍一下 __consumer_offsets 这个 topic。__consumer_offsets 是 Kafka 内部使用的一个 topic,专门用来存储 group 消费的情况,默认情况下有50个 partition,每个 partition 三副本,如下图所示(只列出了30 个 partition):
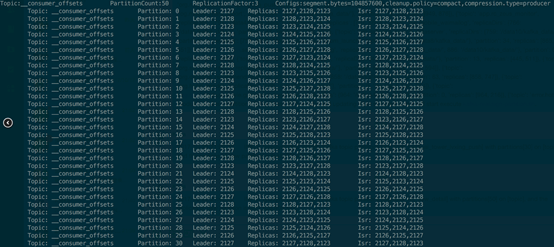
GroupCoordinator 是负责 consumer group member 管理以及 offset 管理。每个 Consumer Group 都有其对应的 GroupCoordinator,但具体是由哪个 GroupCoordinator 负责与 group.id 的 hash 值有关,通过这个 abs(GroupId.hashCode()) % NumPartitions 来计算出一个值(其中,NumPartitions 是 __consumer_offsets 的 partition 数,默认是50个),这个值代表了 __consumer_offsets 的一个 partition,而这个 partition 的 leader 即为这个 Group 要交互的 GroupCoordinator 所在的节点。
6 consumer offset commit
6.1客户端commit请求处理
两种commit机制:一种是同步 commit,一种是异步 commit
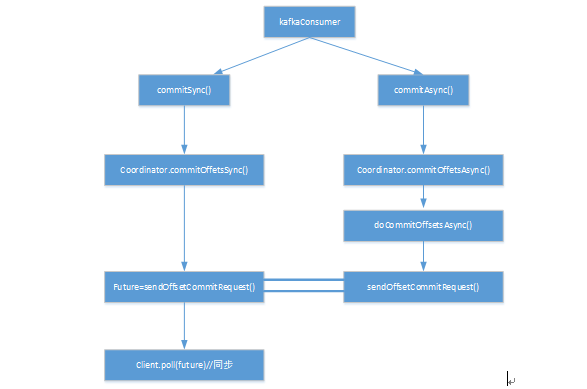

同步 commit 的实现方式,client.poll() 方法会阻塞直到这个request 完成或超时才会返回。

对于异步的 commit,最后调用的都是 doCommitOffsetsAsync 方法,其具体实现如下:
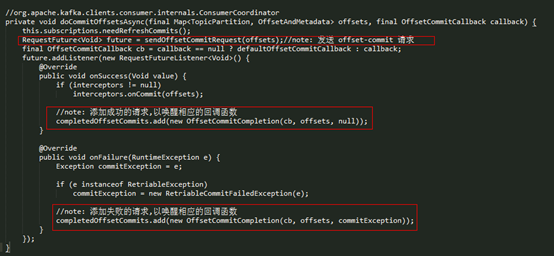
在异步 commit 中,可以添加相应的回调函数,如果 request 处理成功或处理失败,ConsumerCoordinator 会通过 invokeCompletedOffsetCommitCallbacks() 方法唤醒相应的回调函数。
6.2服务端commit offset 请求处理
当 Kafka Serve 端受到来自 client 端的 Offset Commit 请求时,其处理逻辑如下所示,是在 kafka.coordinator.GroupCoordinator 中实现的。

处理过程如下:
- l 如果这个 group 还不存在(groupManager没有这个 group 信息),并且 generation 为 -1(一般情况下应该都是这样),就新建一个 GroupMetadata, 其 Group 状态为 Empty;
- l 现在 group 已经存在,就调用 doCommitOffsets() 提交 offset;
- l 如果是来自 assign 模式的请求,并且其对应的 group 的状态为 Empty(generationId < 0 && group.is(Empty)),那么就记录这个 offset;
- l 如果是来自 assign 模式的请求,但这个 group 的状态不为 Empty(!group.has(memberId)),也就是说,这个 group 已经处在活跃状态,assign 模式下的 group 是不会处于的活跃状态的,可以认为是 assign 模式使用的 group.id 与 subscribe 模式下使用的 group 相同,这种情况下就会拒绝 assign 模式下的这个 offset commit 请求。
7总结
consumer总体流程

7参考资料:
http://matt33.com/2017/11/11/consumer-pollonce/