1. 为什么要序列化
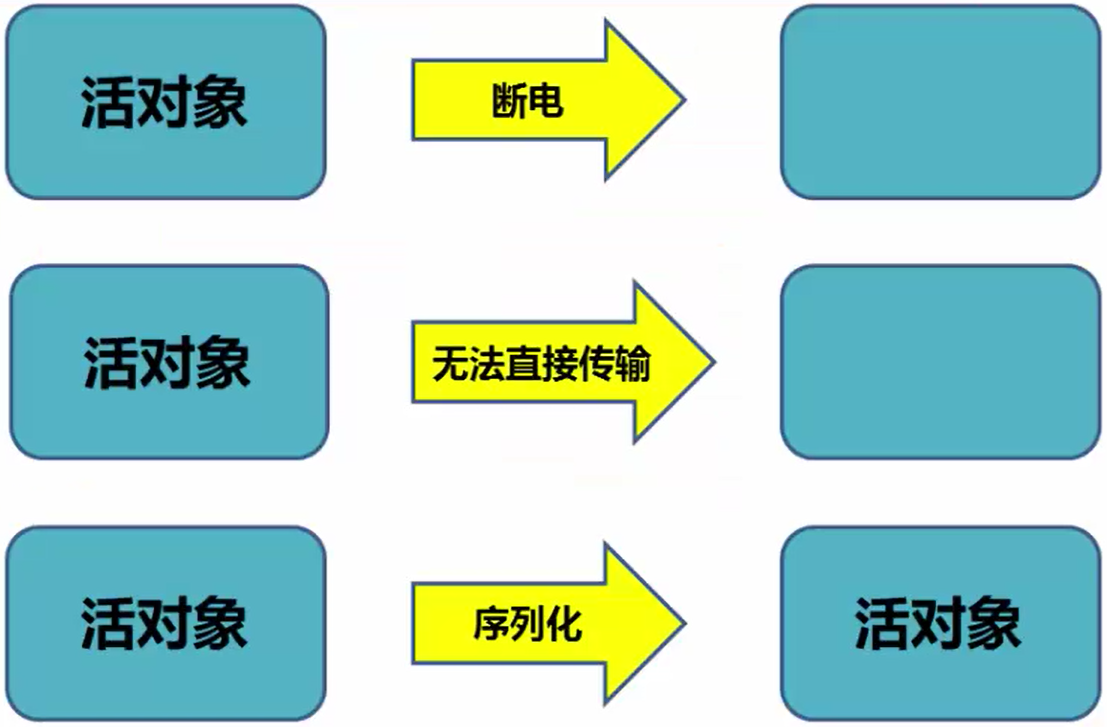
如图,一个活着的对象只存在于内存中,一旦断电就会消失。并且,在正常情况下,一个或者的对象无法直接通过网络发送到其他(远程)机器上。而序列化可以克服上述问题,它能存储对象,并完成其网络传输的任务。
2. 什么是序列化
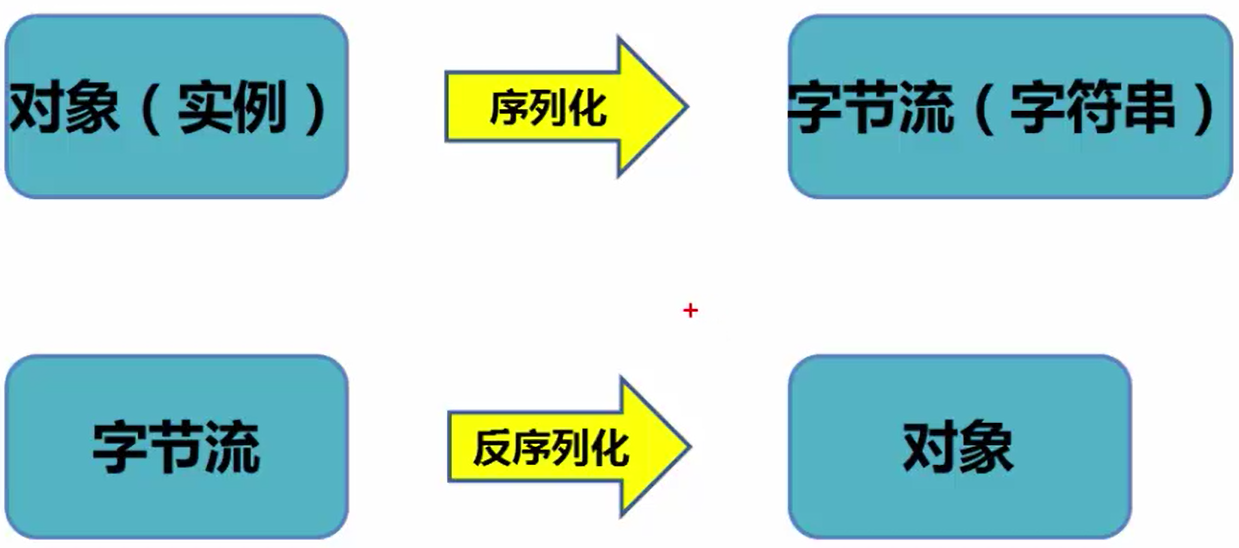
序列化是将对象转化为字节流的方法,或者说用字节流描述对象的方法。与序列化相对的是反序列化,即将字节流转化为对象的方法。
序列化由两个目的:
1)进程间通信;
2)数据持久性存储。
3. 为什么不用Java的序列化机制
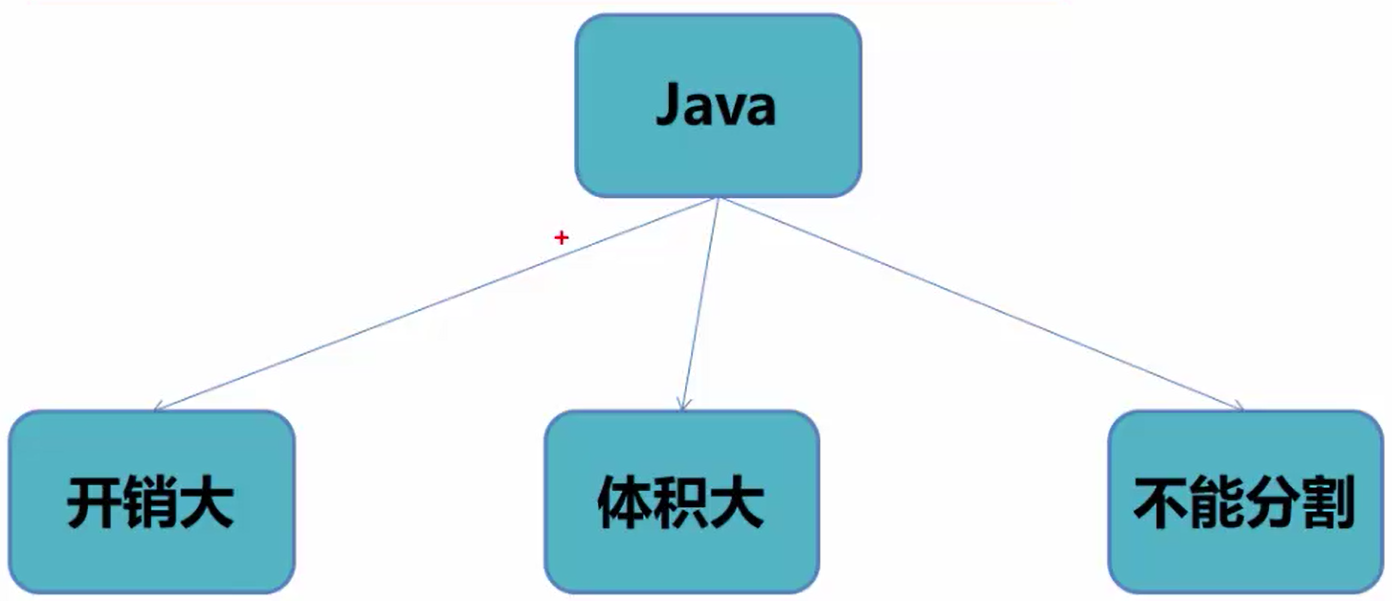
Java的序列化机制存在开销大、体积大和和它的引用机制所导致的大文件不能分割的缺点。因此,Java的序列机制不适合Hadoop,Hadoop设计了自己的序列化机制。
4. Hadoop序列化机制的特点
Hadoop采用RPC来实现进程间通信,RPC的序列化机制具有以下特点:
1)紧凑:紧凑的格式可以充分利用带宽,加快传输速度;
2)快速:能减少序列化和反序列化的开销,这会有效地较少进程间通信的时间;
3)可扩展:可以逐步改变,是客户端与服务器直接相关的,可以随时加入一个新的参数方法调用;
4)互操作性:支持不同语言编写的客户端与服务器交换数据。
5. Hadoop序列化接口
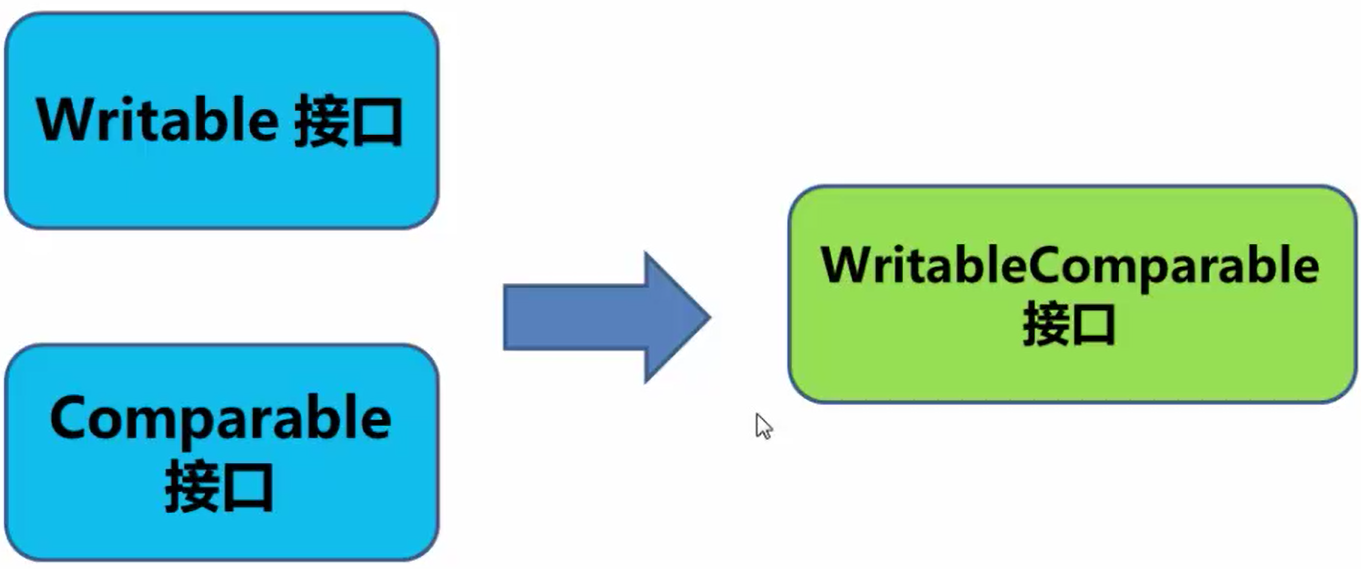
Hadoop的序列化机制定义了两个接口:Writable接口和Comparable接口,它们可以合并为WritableComparable接口。
5.1 Writable类
Writable是Hadoop的核心,Hadoop通过它定义了Hadoop中基本的数据类型及其操作。Writable类定义了两个方法:
package org.apache.hadoop.io;
import java.io.DataOutput;
import java.io.DataInput;
import java.io.IOException;
public interface Writable {
/**
* 将对象转换为字节流并写入到输出流out中
*/
void write(DataOutput out) throws IOException;
/**
* 从输入流in中读取字节流反序列化为对象
*/
void readFields(DataInput in) throws IOException;
}
5.2 Comparable类
所有实现了Comparable的对象都可以和自身相同类型的对象比较大小。该接口定义为:
package java.lang;
import java.util.*;
public interface Comparable
{
/**
* 将this对象和对象o进行比较,约定:返回负数为小于,零为大于,整数为大于
*/
public int compareTo(T o);
}
6. 自定义writable接口
Hadoop 中,并没有使用Java自带的基本类型类(Integer、Float等),而是使用自己开发的序列化类型。Hadoop 自带有很多序列化类型,大致分为以下两种。
6.1 实现了WritableComparable接口的类
* 基础:BooleanWritable | ByteWritable
* 数字:IntWritable | VIntWritable | FloatWritable | LongWritable | VLongWritable | DoubleWritable
* 高级:NullWritable | Text | BytesWritable | MDSHash | ObjectWritable | GenericWritable
6.2 仅实现了Writable接口的类:
* 数组:ArrayWritable | TwoDArrayWritable
* 映射:AbstractMapWritable | MapWritable | SortedMapWritable
为便于理解 Hadoop 自带的 Writable 类型,我们使用以下表格展示Java基本类型和 Writable 的对应关系。

针对上述 Hadoop 中的Writable类型,我们只简单介绍一下 Text。
Text 类是一种 UTF-8 格式的 Writable 类型。可以将它理解为一种与 java.lang.String 类似的 Writable 类型。
Text类型与String类型的主要区别如下:
1)String的长度定义为String包含的字符个数;Text的长度定义为UTF-8编码的字节数。
2)String内的indexOf()方法返回的是char类型字符的索引,比如字符串(1234),字符3的位置就是2(字符1的位置就是0);而Text的find()得到返回得是字节偏移量。
3)String的charAt()方法返回的是指定位置的插入字符;而Text的charAt()方法需要制定偏移量。
另外,Text内定义了一个方法toString(),它用于将Text类型转化为String类型。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。