日志收集系统应该说是到达一定规模的公司的标配了,一个能满足业务需求、运维成本低、稳定的日志收集系统对于运维的同学和日志使用方的同学都是非常nice的。然而这时理想中的日志收集系统,现实往往不是这样的...本篇的主要内容是:首先吐槽一下公司以前的日志收集和上传;介绍新的实时日志收集系统架构;用go语言实现。澄清一下,并不是用go语言实现全部,比如用到卡夫卡肯定不能重写一个kafka吧...
logagent所有代码已上传到github:https://github.com/zingp/logagent。
1 老系统吐槽
我司以前的日志收集系统概述如下:
日志收集的频率有每小时收集一次、每5分钟收集一次、实时收集三种。大部分情况是每小时收集上传一次。
(1)每5分钟上传一次和每小时上传一次的情况是这样的:
每台机器上都需要部署一个日志收集agengt,部署一个日志上传agent,每台机器都需要挂载hadoop集群的客户端。
日志收集agent负责切割日志,上传agent整点的时候启动利用hadoop客户端,将切割好的前1小时或前5分钟日志打包上传到hadoop集群。
(2)实时传输的情况是这样的
每台机器上部署另一个agent,该agent实时收集日志传输到kafka。
看到这里你可能都看不下去了,这么复杂臃肿费劲的日志收集系统是怎么设计出来的?额...先辩解一下,这套系统有4年以上的历史了,当时的解决方案确实有限。辩解完之后还是得吐槽一下系统存在的问题:
(1)首先部署在每台机器上的agent没有做统一的配置入口,需要根据不同业务到不同机器上配置,运维成本太大;十台机器也就罢了,问题是现在有几万台机器,几千个服务。
(2)最无语的是针对不同的hadoop集群,需要挂载多个hadoop客户端,也就是存在一台机器上部署几个hadoop客户端的情况。运维成本太大...
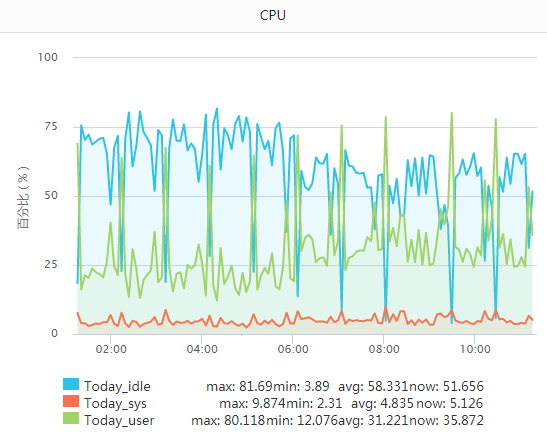
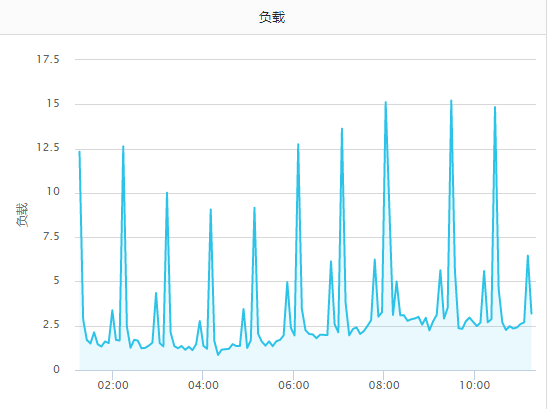
(3)没做限流,整点的时候传输压力变大。某些机器有很多日志,一到整点压力就上来了。无图无真相,我们来看下:
CPU:看绿色的线条
负载:
网卡:
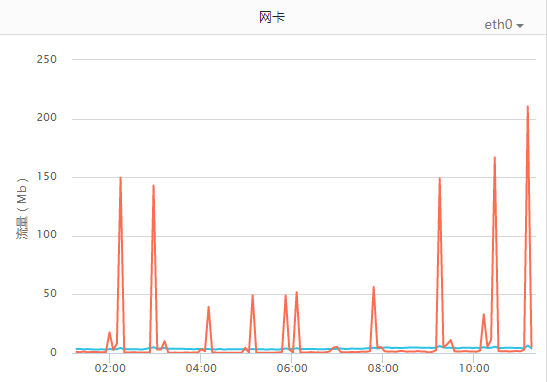
这组机器比较典型(这就是前文说的有多个hadoop客户端的情况),截图是凌晨至上午的时间段,还未到真正的高峰期。不过总体上可看出整点的压力是明显比非正点高很多的,已经到了不能忍的地步。
(4)省略n条吐槽...
2 新系统架构
首先日志收集大可不必在客户端分为1小时、5分钟、实时这几种频率,只需要实时一种就能满足前面三种需求。
其次可以砍掉在机器上挂载hadoop客户端,放在其他地方做日志上传hadoop流程。
第三,做统一的配置管理系统,提供友好的web界面,用户只需要在web界面上配置一组service需要收集的日志,便可通知该组service下的所有机器上的日志收集agent。
第四,流量削峰。应该说实时收集可以避免旧系统整点负载过大情况,但依旧应该做限流功能,防止高峰期agent过度消耗资源影响业务。
第五,日志补传...
实际上公司有的部门在用flume做日志收集,但觉得太重。经过一段时间调研和结合自身业务特点,利用开源软件在适当做些开发会比较好。go应该擅长做这个事,而且方便运维。好了,附上架构图。

将用go实现logagent,Web,transfer这个三个部分。
logagent主要负责按照配置实时收集日志发送到kafka,此外还需watch etcd中的配置,如改变,需要热更新。
web部分主要用于更新etcd中的配置,etcd已提供接口,我们只需要集成到资源管理系统或CMDB系统的管理界面中去即可。
transfer 做的是消费kafka队列中的日志,发送到es/hadoop/storm中去。
3 实现logagent
3.1 配置设计
首先思考下logagent的配置文件内容:
etcd_addr = 10.134.123.183:2379 # etcd 地址 etcd_timeout = 5 # 连接etcd超时时间 etcd_watch_key = /logagent/%s/logconfig # etcd key 格式 kafka_addr = 10.134.123.183:9092 # 卡夫卡地址 thread_num = 4 # 线程数 log = ./log/logagent.log # agent的日志文件 level = debug # 日志级别 # 监听哪些日志,日志限流大小,发送到卡夫卡的哪个topic 这个部分可以放到etcd中去。
如上所说,监听哪些日志,日志限流大小,发送到卡夫卡的哪个topic 这个部分可以放到etcd中去。etcd中存储的value格式设计如下:
`[
{
"service":"test_service",
"log_path": "/search/nginx/logs/ping-android.shouji.sogou.com_access_log", "topic": "nginx_log",
"send_rate": 1000
},
{
"service":"srv.android.shouji.sogou.com",
"log_path": "/search/nginx/logs/srv.android.shouji.sogou.com_access_log","topic": "nginx_log",
"send_rate": 2000
}
]`
- "service":"服务名称",
- "log_path": "应该监听的日志文件",
- "topic": "kfk topic",
- "send_rate": "日志条数限制"
其实可以将更多的配置放入etcd中,根据自身业务情况可自行定义,本次就做如此设计,接下来可以写解析配置文件的代码了。
config.go
package main
import (
"fmt"
"github.com/astaxie/beego/config"
)
type AppConfig struct {
EtcdAddr string
EtcdTimeOut int
EtcdWatchKey string
KafkaAddr string
ThreadNum int
LogFile string
LogLevel string
}
var appConf = &AppConfig{}
func initConfig(file string) (err error) {
conf, err := config.NewConfig("ini", file)
if err != nil {
fmt.Println("new config failed, err:", err)
return
}
appConf.EtcdAddr = conf.String("etcd_addr")
appConf.EtcdTimeOut = conf.DefaultInt("etcd_timeout", 5)
appConf.EtcdWatchKey = conf.String("etcd_watch_key")
appConf.KafkaAddr = conf.String("kafka_addr")
appConf.ThreadNum = conf.DefaultInt("thread_num", 4)
appConf.LogFile = conf.String("log")
appConf.LogLevel = conf.String("level")
return
}
代码主要定义了一个AppConf结构体,然后读取配置文件,存放到结构体中。
此外,还有部分配置在etcd中,需要做两件事,第一次启动程序时将配置从etcd拉取下来;然后启动一个协程去watch etcd中的配置是否更改,如果更改需要拉取并更新到内存中。代码如下:
etcd.go:
package main
import (
"context"
"fmt"
"sync"
"time"
"github.com/astaxie/beego/logs"
client "github.com/coreos/etcd/clientv3"
)
var (
confChan = make(chan string, 10)
cli *client.Client
waitGroup sync.WaitGroup
)
func initEtcd(addr []string, keyFormat string, timeout time.Duration) (err error) {
// init a global var cli and can not close
cli, err = client.New(client.Config{
Endpoints: addr,
DialTimeout: timeout,
})
if err != nil {
fmt.Println("connect etcd error:", err)
return
}
logs.Debug("init etcd success")
// defer cli.Close() //can not close
var etcdKeys []string
ips, err := getLocalIP()
if err != nil {
fmt.Println("get local ip error:", err)
return
}
for _, ip := range ips {
key := fmt.Sprintf(keyFormat, ip)
etcdKeys = append(etcdKeys, key)
}
// first, pull conf from etcd
for _, key := range etcdKeys {
ctx, cancel := context.WithTimeout(context.Background(), time.Second)
resp, err := cli.Get(ctx, key)
cancel()
if err != nil {
fmt.Println("get etcd key failed, error:", err)
continue
}
for _, ev := range resp.Kvs {
// return result is not string
confChan <- string(ev.Value)
fmt.Printf("etcd key = %s , etcd value = %s", ev.Key, ev.Value)
}
}
waitGroup.Add(1)
// second, start a goroutine to watch etcd
go etcdWatch(etcdKeys)
return
}
// watch etcd
func etcdWatch(keys []string) {
defer waitGroup.Done()
var watchChans []client.WatchChan
for _, key := range keys {
rch := cli.Watch(context.Background(), key)
watchChans = append(watchChans, rch)
}
for {
for _, watchC := range watchChans {
select {
case wresp := <-watchC:
for _, ev := range wresp.Events {
confChan <- string(ev.Kv.Value)
logs.Debug("etcd key = %s , etcd value = %s", ev.Kv.Key, ev.Kv.Value)
}
default:
}
}
time.Sleep(time.Second)
}
}
//GetEtcdConfChan is func get etcd conf add to chan
func GetEtcdConfChan() chan string {
return confChan
}
其中,有一个比较个性化的设计,就是一台主机对应的etcd 中的key我们设置成/logagent/本机ip/logconfig的格式,因此还需要一个获取本机IP的功能,注意一台机器可能存在多个IP。
ip.go:
package main
import (
"fmt"
"net"
)
// var a slice for ip addr
var ipArray []string
func getLocalIP() (ips []string, err error) {
ifaces, err := net.Interfaces()
if err != nil {
fmt.Println("get ip interfaces error:", err)
return
}
for _, i := range ifaces {
addrs, errRet := i.Addrs()
if errRet != nil {
continue
}
for _, addr := range addrs {
var ip net.IP
switch v := addr.(type) {
case *net.IPNet:
ip = v.IP
if ip.IsGlobalUnicast() {
ips = append(ips, ip.String())
}
}
}
}
return
}
3.2 初始化kafka
初始化kafka很简单,就是创建kafka实例,提供发送日志功能。只不过发送是并发的。
package main
import (
"fmt"
"github.com/Shopify/sarama"
"github.com/astaxie/beego/logs"
)
var kafkaSend = &KafkaSend{}
type Message struct {
line string
topic string
}
type KafkaSend struct {
client sarama.SyncProducer
lineChan chan *Message
}
func initKafka(kafkaAddr string, threadNum int) (err error) {
kafkaSend, err = NewKafkaSend(kafkaAddr, threadNum)
return
}
// NewKafkaSend is
func NewKafkaSend(kafkaAddr string, threadNum int) (kafka *KafkaSend, err error) {
kafka = &KafkaSend{
lineChan: make(chan *Message, 10000),
}
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll // wait kafka ack
config.Producer.Partitioner = sarama.NewRandomPartitioner // random partition
config.Producer.Return.Successes = true
client, err := sarama.NewSyncProducer([]string{kafkaAddr}, config)
if err != nil {
logs.Error("init kafka client err: %v", err)
return
}
kafka.client = client
for i := 0; i < threadNum; i++ {
fmt.Println("start to send kfk")
waitGroup.Add(1)
go kafka.sendMsgToKfk()
}
return
}
func (k *KafkaSend) sendMsgToKfk() {
defer waitGroup.Done()
for v := range k.lineChan {
msg := &sarama.ProducerMessage{}
msg.Topic = v.topic
msg.Value = sarama.StringEncoder(v.line)
_, _, err := k.client.SendMessage(msg)
if err != nil {
logs.Error("send massage to kafka error: %v", err)
return
}
}
}
func (k *KafkaSend) addMessage(line string, topic string) (err error) {
k.lineChan <- &Message{line: line, topic: topic}
return
}
3.3 实时读取日志,发送到kafka
package main
import (
"encoding/json"
"fmt"
"strings"
"sync"
"github.com/astaxie/beego/logs"
"github.com/hpcloud/tail"
)
// TailObj is TailMgr's instance
type TailObj struct {
tail *tail.Tail
offset int64
logConf LogConfig
secLimit *SecondLimit
exitChan chan bool
}
var tailMgr *TailMgr
//TailMgr to manage tailObj
type TailMgr struct {
tailObjMap map[string]*TailObj
lock sync.Mutex
}
// NewTailMgr init TailMgr obj
func NewTailMgr() *TailMgr {
return &TailMgr{
tailObjMap: make(map[string]*TailObj, 16),
}
}
//AddLogFile to Add tail obj
func (t *TailMgr) AddLogFile(conf LogConfig) (err error) {
t.lock.Lock()
defer t.lock.Unlock()
_, ok := t.tailObjMap[conf.LogPath]
if ok {
err = fmt.Errorf("duplicate filename:%s", conf.LogPath)
return
}
tail, err := tail.TailFile(conf.LogPath, tail.Config{
ReOpen: true,
Follow: true,
Location: &tail.SeekInfo{Offset: 0, Whence: 2}, // read to tail
MustExist: false, //file does not exist, it does not return an error
Poll: true,
})
if err != nil {
fmt.Println("tail file err:", err)
return
}
tailObj := &TailObj{
tail: tail,
offset: 0,
logConf: conf,
secLimit: NewSecondLimit(int32(conf.SendRate)),
exitChan: make(chan bool, 1),
}
t.tailObjMap[conf.LogPath] = tailObj
waitGroup.Add(1)
go tailObj.readLog()
return
}
func (t *TailMgr) reloadConfig(logConfArr []LogConfig) (err error) {
for _, conf := range logConfArr {
tailObj, ok := t.tailObjMap[conf.LogPath]
if !ok {
err = t.AddLogFile(conf)
if err != nil {
logs.Error("add log file failed:%v", err)
continue
}
continue
}
tailObj.logConf = conf
tailObj.secLimit.limit = int32(conf.SendRate)
t.tailObjMap[conf.LogPath] = tailObj
}
for key, tailObj := range t.tailObjMap {
var found = false
for _, newValue := range logConfArr {
if key == newValue.LogPath {
found = true
break
}
}
if found == false {
logs.Warn("log path :%s is remove", key)
tailObj.exitChan <- true
delete(t.tailObjMap, key)
}
}
return
}
// Process hava two func get new log conf and reload conf
func (t *TailMgr) Process() {
for conf := range GetEtcdConfChan() {
logs.Debug("log conf: %v", conf)
var logConfArr []LogConfig
err := json.Unmarshal([]byte(conf), &logConfArr)
if err != nil {
logs.Error("unmarshal failed, err: %v conf :%s", err, conf)
continue
}
err = t.reloadConfig(logConfArr)
if err != nil {
logs.Error("reload config from etcd failed: %v", err)
continue
}
logs.Debug("reload config from etcd success")
}
}
func (t *TailObj) readLog() {
for line := range t.tail.Lines {
if line.Err != nil {
logs.Error("read line error:%v ", line.Err)
continue
}
lineStr := strings.TrimSpace(line.Text)
if len(lineStr) == 0 || lineStr[0] == '
' {
continue
}
kafkaSend.addMessage(line.Text, t.logConf.Topic)
t.secLimit.Add(1)
t.secLimit.Wait()
select {
case <-t.exitChan:
logs.Warn("tail obj is exited: config:", t.logConf)
return
default:
}
}
waitGroup.Done()
}
func runServer() {
tailMgr = NewTailMgr()
tailMgr.Process()
waitGroup.Wait()
}
此处设计了一个限流功能,逻辑大概如下:设置阈值A,如阈值为1000条,如果这秒钟已经发送1000条,那么这一秒剩下的时间就sleep。limit.go代码如下:
package main
import (
"sync/atomic"
"time"
"github.com/astaxie/beego/logs"
)
// SecondLimit to limit num in one second
type SecondLimit struct {
unixSecond int64
curCount int32
limit int32
}
// NewSecondLimit to init a SecondLimit obj
func NewSecondLimit(limit int32) *SecondLimit {
secLimit := &SecondLimit{
unixSecond: time.Now().Unix(),
curCount: 0,
limit: limit,
}
return secLimit
}
// Add is func to
func (s *SecondLimit) Add(count int) {
sec := time.Now().Unix()
if sec == s.unixSecond {
atomic.AddInt32(&s.curCount, int32(count))
return
}
atomic.StoreInt64(&s.unixSecond, sec)
atomic.StoreInt32(&s.curCount, int32(count))
}
// Wait to limit num
func (s *SecondLimit) Wait() bool {
for {
sec := time.Now().Unix()
if (sec == atomic.LoadInt64(&s.unixSecond)) && s.curCount >= s.limit {
time.Sleep(time.Millisecond)
logs.Debug("limit is runing, limit: %d s.curCount:%d", s.limit, s.curCount)
continue
}
if sec != atomic.LoadInt64(&s.unixSecond) {
atomic.StoreInt64(&s.unixSecond, sec)
atomic.StoreInt32(&s.curCount, 0)
}
logs.Debug("limit is exited")
return false
}
}
此外,写日志的代码非主要代码,这里就不介绍了。所有代码均上传到github上,如有兴趣可前去clone,地址已经在文章开头处给出。
transfer将在下一篇文章中介绍。文中涉及kafka,etcd等搭建,可参考官网搭建单机版用于测试。
我的博客即将搬运同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=18j46a3goe9gk