算法对比
二叉树
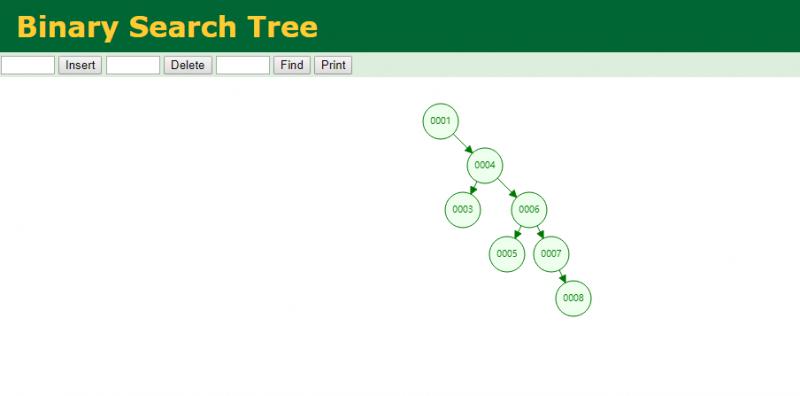
当我查找 8 的时候需要走五步
红黑树
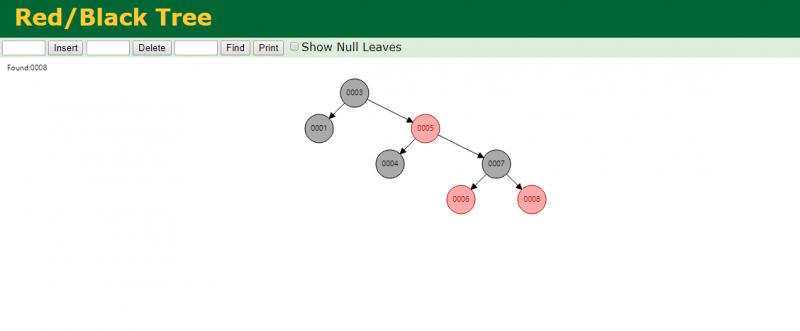
当我查询8的时候需要四次 相对于二叉树有了一些优化 没有无限延伸.红黑树的深度会很深(深度不可控制)
hash
数据量大的话
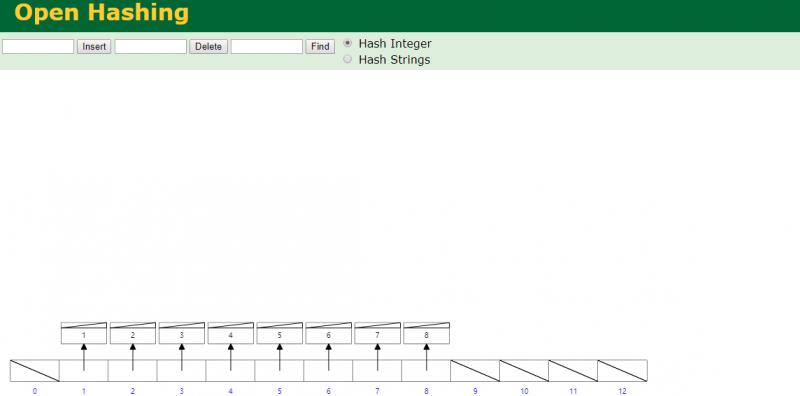
查询很快(不能范围查找)
BTree
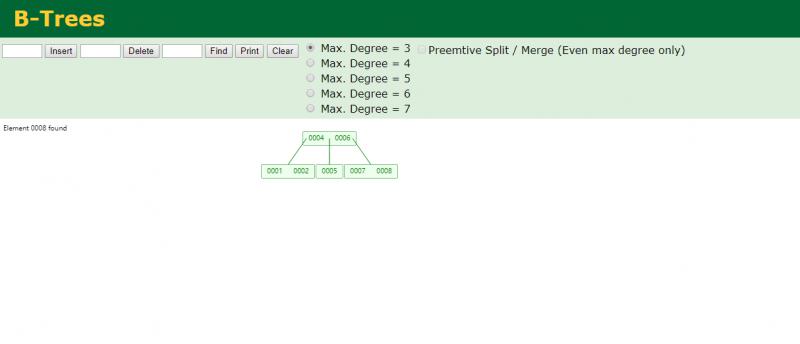
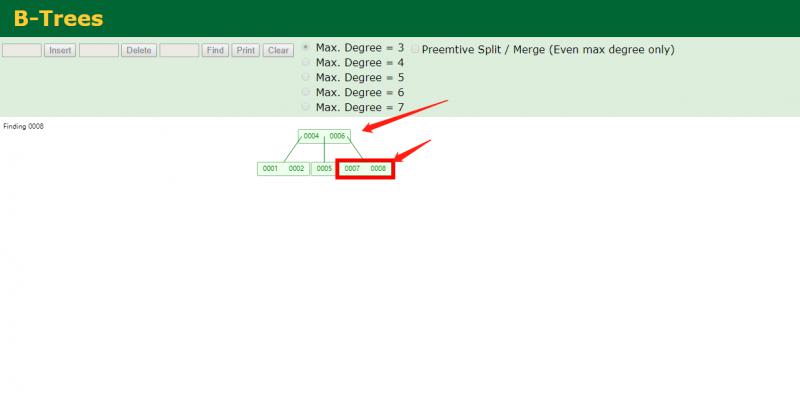
查询只需要查两步就可以找到,缺点携带(data)扩大横向减少纵向深度
ps:java拿取数据一般是这样的:java程序-->CPU--->内存---->硬盘,而内存与硬盘的交互是有大小限制的,是一页数据4k左右,所以不能把所有数据都放在一个节点来获取,一般来说节点会尽量预存4K容量。
B+Tree
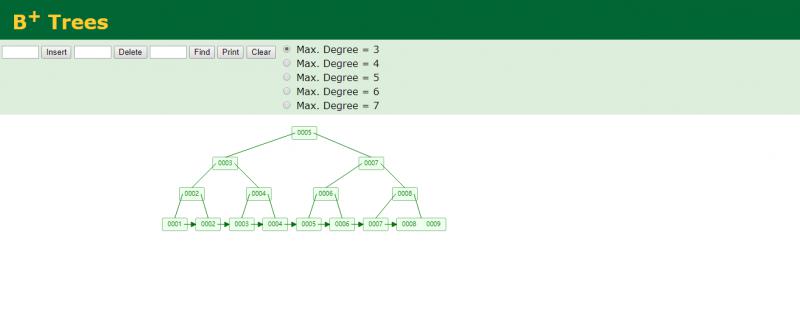
BTree 变种B+Tree
ps:data不放在非叶子节点来增加度(小节点),一般会一百个以上使得深度是3~5,从而减少查询次数。并且,叶子节点之间会有指针,数据又是递增的,这使得我们范围查找可以通过指针连接查找,而不再从上面节点往下一个个找。既减少了查询次数,又提供了范围查询.
所以mysql采用的B+Tree算法
